 夜雨聆风
夜雨聆风本篇讲解 OpenClaw 的上下文引擎机制。上下文引擎决定了 Agent 在每次推理时能「看到」哪些信息——对话历史、系统提示、工具定义、记忆检索结果等。理解上下文引擎,就是理解如何精确控制 Agent 的信息输入。
01
—
什么是上下文引擎
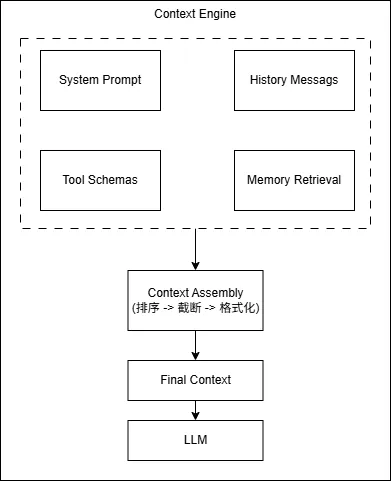
每次 Agent 进行推理(调用 LLM),它需要接收一组输入信息。这组输入信息就是「上下文」,通常包括:
系统提示(System Prompt):定义 Agent 的角色和行为规则
对话历史(Conversation History):当前会话中的历史消息
工具定义(Tool Definitions):Agent 可调用的工具列表
记忆检索(Memory Retrieval):从长期记忆中召回的相关信息
技能内容(Skill Content):当前激活的技能指令
用户上下文(User Context):用户偏好、会话状态等
上下文引擎的职责就是:将这些分散的信息组装成一个有序的、符合模型上下文窗口限制的输入序列。
—
独占插槽机制
上下文引擎是 OpenClaw 的独占插槽——同一时间只有一个上下文引擎处于活跃状态。
系统默认使用内置的 legacy 引擎。如果你想使用自定义引擎,需要在配置中显式指定:
{"plugins": {"slots": {"contextEngine": "my-custom-engine"}}}
切换引擎后需要重启 Gateway:
openclaw gateway restart独占插槽的设计原因是:上下文引擎控制的是全局的上下文构建管道,多个引擎同时活跃会导致行为不可预测。与 Provider 插件(多个可以共存)不同,上下文引擎是「零或一」的关系。
03
—
registerContextEngine
api.registerContextEngine(id, factory) 注册自定义上下文引擎。这个方法在 register(api) 回调中直接可用。第一个参数是引擎 ID(对应配置中的 contextEngine 值),第二个参数是一个工厂函数:api.registerContextEngine("my-custom-engine", (context) => {// context 是引擎运行环境,提供 config、pluginConfig、logger 等// 返回上下文引擎的实现对象return {// 核心方法:构建最终上下文// 每次 Agent 推理前,OpenClaw 核心会调用此方法async buildContext(params) {// params 包含引擎需要的所有输入:// - systemPrompt: 系统提示(定义 Agent 角色)// - history: 对话历史消息数组// - toolDefinitions: Agent 可调用的工具列表// - memoryResults: 记忆系统检索到的相关记忆// - skillContent: 当前激活的技能内容// - maxTokens: 模型的上下文窗口大小限制(token 数)// 自定义组装逻辑——决定各部分信息在上下文中的位置和优先级const sections = [];// 1. 系统提示(优先级最高,放在最前面)sections.push({role: "system",content: params.systemPrompt,priority: 100, // 数字越大,优先级越高});// 2. 记忆召回(高优先级,紧随系统提示)if(params.memoryResults?.length) {sections.push({role: "system",content: formatMemory(params.memoryResults),priority: 80,});}// 3. 技能内容(指导 Agent 行为的 Markdown)if(params.skillContent) {sections.push({role: "system",content: params.skillContent,priority: 70,});}// 4. 对话历史(按时间排序,优先级最低,最先被截断)sections.push(...params.history.map(msg => ({role: msg.role, // "user" | "assistant" | "system"content: msg.content,priority: 50,timestamp: msg.timestamp, // 用于按时间排序})));// 排序(按优先级)→ 截断(超出窗口时丢弃低优先级内容)→ 格式化const ordered = sortAndTruncate(sections, params.maxTokens);return ordered; // 返回最终的消息数组,传递给 Provider},};});
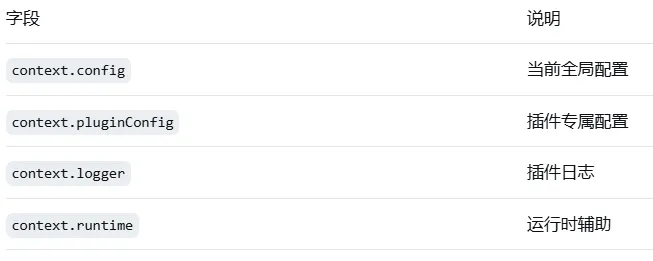
工厂函数参数
registerContextEngine 的第二个参数是一个工厂函数,接收 context 对象。context 提供了引擎运行所需的环境信息:
04
—
上下文构建的核心挑战
开发自定义上下文引擎时,需要解决三个核心问题:
1. 排序
不同的信息片段应该出现在上下文中的什么位置?一般的经验是:
系统提示在最前面
记忆和技能紧随其后
对话历史按时间顺序排列
最新的消息在最后
但你可能有不同的需求——例如,你可能希望将最近 3 轮对话放在记忆之前,以便 Agent 更关注当前语境。
2. 截断
模型的上下文窗口是有限的。当信息总量超过窗口大小时,需要决定丢弃什么。常见的策略:
保留系统提示:系统提示通常不应被截断
截断旧历史:优先保留最近的对话
压缩记忆:对记忆检索结果进行摘要
动态调整:根据当前任务类型调整各部分的占比
function sortAndTruncate(sections: ContextSection[],maxTokens: number): ContextSection[] {// 按 priority 分组const systemSections = sections.filter(s => s.priority >= 70);const historySections = sections.filter(s => s.priority < 70);// 计算系统部分占用的 token 数const systemTokens = estimateTokens(systemSections);// 剩余空间留给历史const historyBudget = maxTokens - systemTokens;// 从最新的历史开始,倒序填充const sortedHistory = [...historySections].sort((a, b) => b.timestamp - a.timestamp);const selectedHistory: ContextSection[] = [];let usedTokens = 0;for (const section of sortedHistory) {const sectionTokens = estimateTokens([section]);if (usedTokens + sectionTokens > historyBudget) break;selectedHistory.push(section);usedTokens += sectionTokens;}// 按时间正序排列selectedHistory.sort((a, b) => a.timestamp - b.timestamp);return [...systemSections, ...selectedHistory];}function estimateTokens(sections: ContextSection[]): number {// 粗略估算:1 token ≈ 4 个英文字符 或 2 个中文字符const totalChars = sections.reduce((sum, s) => sum + String(s.content).length, 0);return Math.ceil(totalChars / 3); // 保守估算}
3. 格式化
不同的模型对输入格式有不同的要求。上下文引擎需要确保输出格式与目标模型兼容:
OpenAI 格式:
messages数组,每条消息有role和contentAnthropic 格式:
system单独传递,messages只包含 user/assistant自定义格式:某些模型可能有特殊的格式要求
上下文引擎可以根据当前的 Provider 类型调整输出格式。
05
—
上下文引擎与 Provider 的协作
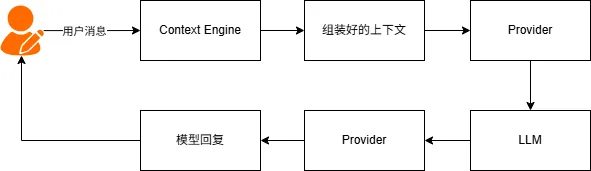
上下文引擎不直接与 LLM 通信。它只负责组装输入,然后将结果传递给 Provider,由 Provider 实际调用 LLM API。
这种分离意味着:
切换上下文引擎不影响 Provider 的实现
切换 Provider 不影响上下文引擎的逻辑
两者可以独立开发和测试
06
—
内置的 legacy 引擎
OpenClaw 默认的 legacy 引擎提供了基础的上下文构建功能:
按固定顺序组装各部分
对历史消息进行 token 计数和截断
保留系统提示和工具定义的完整性
对于大多数使用场景,默认引擎已经足够。当你有以下需求时,才需要考虑自定义引擎:
需要特殊的上下文排序策略
需要对特定类型的信息进行动态调整
需要在上下文中注入自定义的元信息
需要与特定的模型格式深度适配
07
—
实战:基于主题的上下文优先级引擎
以下示例展示了一个根据消息主题动态调整上下文优先级的引擎:
import { definePluginEntry } from "openclaw/plugin-sdk/plugin-entry";export default definePluginEntry({id: "smart-context-engine",name: "Smart Context Engine",version: "1.0.0",register(api) {api.registerContextEngine("smart-context", (context) => {const config = api.pluginConfig as {codingHistoryWeight?: number;chatHistoryWeight?: number;};return {async buildContext(params) {const sections: Array<{role: string;content: string;priority: number;timestamp?: number;tokens: number;}> = [];// 系统提示(最高优先级,不可截断)if (params.systemPrompt) {sections.push({role: "system",content: params.systemPrompt,priority: 100,tokens: estimateTokens(params.systemPrompt),});}// 记忆(根据相关性动态调整优先级)if (params.memoryResults?.length) {for (const memory of params.memoryResults) {const relevanceBoost = Math.round(memory.score * 10);sections.push({role: "system",content: `[Memory] ${memory.content}`,priority: 70 + relevanceBoost,tokens: estimateTokens(memory.content),});}}// 工具定义if (params.toolDefinitions) {const toolDefs = JSON.stringify(params.toolDefinitions);sections.push({role: "system",content: toolDefs,priority: 90,tokens: estimateTokens(toolDefs),});}// 对话历史if (params.history) {for (const msg of params.history) {const isCoding = isCodingMessage(msg.content);const weight = isCoding? (config.codingHistoryWeight ?? 1.5): (config.chatHistoryWeight ?? 1.0);sections.push({role: msg.role,content: msg.content,priority: 50,timestamp: msg.timestamp,tokens: Math.ceil(estimateTokens(msg.content) * weight),});}}// 智能截断return smartTruncate(sections, params.maxTokens);},};});},});function isCodingMessage(content: string): boolean {const codingIndicators = ["```", "function", "class ", "import ", "const ", "async ","error:", "Exception", "TODO:", "FIXME:",];return codingIndicators.some(ind => content.includes(ind));}function estimateTokens(text: string): number {return Math.ceil(text.length / 3);}function smartTruncate(sections: Array<{ role: string; content: string; priority: number; timestamp?: number; tokens: number }>,maxTokens: number): Array<{ role: string; content: string }> {const fixed = sections.filter(s => s.priority >= 90).sort((a, b) => b.priority - a.priority);const flexible = sections.filter(s => s.priority < 90).sort((a, b) => (b.timestamp ?? 0) - (a.timestamp ?? 0));const fixedTokens = fixed.reduce((sum, s) => sum + s.tokens, 0);const budget = maxTokens - fixedTokens;const selected: typeof flexible = [];let used = 0;for (const section of flexible) {if (used + section.tokens > budget) break;selected.push(section);used += section.tokens;}// 按时间正序selected.sort((a, b) => (a.timestamp ?? 0) - (b.timestamp ?? 0));return [...fixed, ...selected].map(s => ({role: s.role,content: s.content,}));}
这个引擎的特点:
编码消息加权:检测到编码相关内容时,增加其 token 权重,在有限空间内保留更多编码上下文
记忆相关性排序:记忆检索结果的 score 越高,在上下文中的位置越靠前
灵活的权重配置:通过插件配置调整编码/聊天历史的权重比例
08
—
小结
本篇覆盖了 OpenClaw 上下文引擎的核心机制:
上下文引擎负责组装 Agent 推理所需的输入信息
独占插槽机制保证同时只有一个引擎活跃
registerContextEngine注册自定义引擎核心挑战:排序、截断、格式化
上下文引擎与 Provider 解耦,独立协作
下一篇:记忆系统 — 让 Agent 拥有长期记忆。我们将学习如何通过 Memory Plugin 为 Agent 添加跨会话的持久化记忆能力。
