 夜雨聆风
夜雨聆风一、导语(Lead)
本文致力于深度剖析工业界推荐系统中的一个关键且极具挑战性的任务:大规模下一篮子复购推荐(Next Basket Repurchase Recommendation, NBRR)。在日常零售场景中,用户下次购买的商品大多具有固定的周期性(Cadence),然而现有的深度序列模型大多按“购买次数的先后顺序”进行建模,完全丢失了真实的日历时间流逝感,导致预测极度滞后且缺乏动态更新能力。
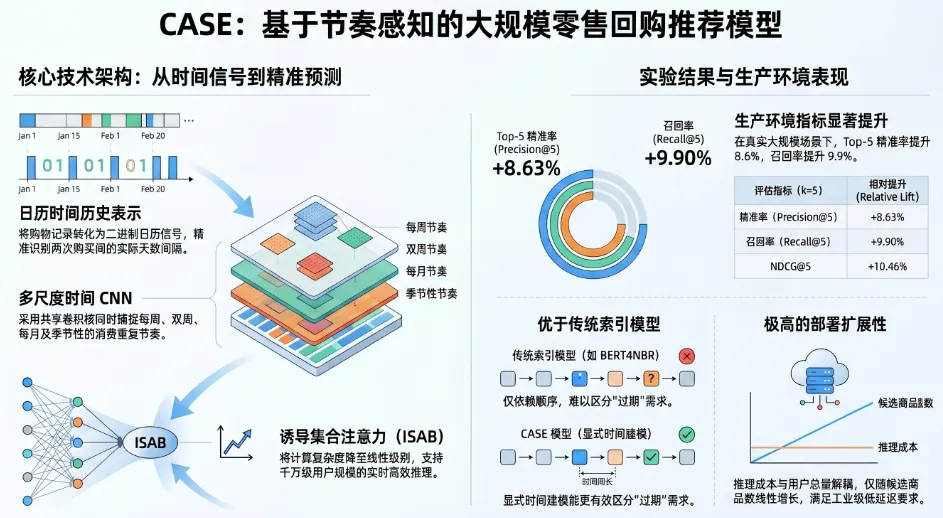
这篇由沃尔玛全球科技团队(Walmart Global Tech)提出的论文之所以至关重要,是因为它从根本上打破了学术界与工业界在时间建模上的信息壁垒。论文的核心创新在于提出了一种名为 CASE(节律感知的集合编码器) 的轻量级、高扩展性推荐框架。该框架史无前例地将商品的复购节律学习与跨商品的集合交互解耦,利用共享的多尺度时间卷积网络(Multi-scale CNN)捕捉日历周期,并结合诱导集合注意力(ISAB)降低计算复杂度。该方案不仅在离线公开数据集上碾压现有 Baseline,更在千万级用户的真实工业生产环境中实现了高达 8.6% 的精准度提升。
二、研究背景:为什么要解决这个问题?
在深入解读这篇具有突破性的学术架构之前,我们需要深刻理解当前推荐系统(Recommender Systems)在处理特定业务场景时所面临的核心困境,以及为什么“下一篮子复购推荐(NBRR)”会成为横亘在工业界与学术界之间的一道鸿沟。
1. 当前领域面临的核心问题:零售场景下的“节律”属性
在传统的点击率(CTR)预估或流媒体推荐场景中,用户的兴趣通常被视为一种“平滑演进”的过程。比如你刚看完一部科幻电影,系统马上给你推荐另一部科幻电影,这是极其合理的。
然而,在大型零售超市(如沃尔玛、Instacart)的场景下,用户的购买行为是以购物篮(Basket) 为单位的,并且具有极强的复购(Repurchase)与节律(Cadence) 属性。据统计,在一个成熟的零售平台上,用户下一次购买的商品中,有极高的比例是他们曾经购买过的消耗品。例如:
• 牛奶、面包等鲜食,往往具有每周(Weekly) 的购买节律; • 纸巾、洗衣液等日化用品,可能具有每月(Monthly) 的购买节律; • 换季衣物、防晒霜等,具有强烈的季节性(Seasonally)。
准确把握这些时间节律对于用户体验是决定性的。如果你推荐得太早,用户家里的库存还没用完,这会被视为无关的垃圾推荐;如果你推荐得太晚,用户可能已经去线下便利店买过了,平台就永远失去了这次转化机会。 因此,时间刻度的精准建模,是该领域生死攸关的核心问题。
2. 现有方法的主要局限:被“序列索引”抹杀的时间感
目前学术界在序列推荐领域已经提出了诸多极其强大的模型,如基于自注意力机制的 SASRec、BERT4Rec(以及针对篮子推荐改进的 BERT4NBR),或者基于图神经网络的 DNNTSP。然而,这些最前沿的深度学习模型在处理复购节律时,存在一个致命的底层缺陷:它们将用户的历史记录抽象为离散的“序列索引(Basket Index)”。
我们用一个通俗的类比来理解这种局限性。假设有两个用户:
• 用户 A:在第 1 天买了牛奶,在第 2 天买了牛奶,在第 3 天买了牛奶。 • 用户 B:在第 1 天买了洗发水,在第 8 天买了洗发水,在第 36 天买了洗发水。
在传统的深度序列模型(如 BERT4NBR 或基于 GNN 的方法)眼中,这两种历史行为会被编码成完全一样的格式:“在时刻 购买,在时刻 购买,在时刻 购买”。
这种“按次数排序”而不是“按真实日历时间排序”的建模方式,彻底抹杀了真实世界中流逝的时间。由于没有显式的日历时间概念,模型根本无法区分“间隔 1 天的鲜食复购”与“间隔数十天的日用品复购”。
更致命的是工业部署上的缺陷。因为模型只看“交易次数”,所以只有当用户产生一笔新的交易时,模型的推荐列表才会发生变化。如果用户 A 长达 10 天没有购物,在此期间,系统对他的推荐列表是完全静态、冻结的。系统无法随着时间的推移,动态地推理出“哦,已经过去 10 天了,这包纸巾今天正好处于‘待补货(overdue)’状态”。这种缺乏时间动态更新能力的设计,严重脱离了真实的生产需求。
3. 为什么这个问题一直没有被很好解决?
你可能会问:既然时间这么重要,为什么不直接把准确的日历时间塞给模型?或者用基于时间衰减的 KNN 协同过滤算法?
这里就触及了工业界极其严苛的算力与扩展性(Scalability)权衡问题。
学术界并非没有尝试过解决这个问题。例如领域内表现极强的一个基线方法:TIFUKNN。TIFUKNN 为每个用户构建了带有时间衰减权重的向量,然后通过寻找相似用户(KNN)来聚合推荐结果。这种方法确实保留了时间衰减和节律感。
但是,TIFUKNN 在推理时,需要将当前查询的用户,与整个平台数以千万计的其余用户进行实时的两两相似度计算(时间复杂度为 ,其中 是用户总数)。在拥有几千万甚至上亿日活用户的零售巨头(如沃尔玛)系统中,这种随着用户规模呈线性爆炸的计算复杂度,根本无法在线上实时部署。
另一种思路是最近提出的使用卷积网络来学习二元时间序列的方法,但这种方法往往需要为每个用户保存特定且庞大的卷积参数,且使用二次复杂度的商品交互模块,当商品目录库(Catalog)极其庞大时,同样会遭遇显存和算力的双重瓶颈。
4. 现实世界中的应用场景
我们可以想象一个经典的“沃尔玛超级 APP”应用场景。
当一位主妇在周五晚上打开 APP 准备采购周末物资时,系统需要在一瞬间(小于 50 毫秒)从几十万的候选商品池中,找出那些她“刚好用完”的复购商品。这不仅仅要求模型懂她喜欢什么牌子的牛奶,更要求模型能够精准计算距离她上次买牛奶过去了几个自然日,距离她上次买洗手液过去了几个自然日;并且,由于这种并发请求每秒高达数十万次,所有的计算过程必须是可通过矩阵乘法极速批处理的(Batch Inference),绝不能依赖全库用户召回。
CASE 框架的提出,正是为了在“精准捕捉日历节律”与“满足千万级 QPS 工业并发限制”之间,找到一个堪称完美的架构解法。
三、核心研究问题
在这部分,我们将系统性地拆解沃尔玛团队试图通过这篇论文解答的核心学术与工程疑问。
1. 问题:论文试图解决的核心问题是什么?
核心研究问题: 如何在大规模的生产级推荐系统中,显式地对用户的真实日历购买节律(Cadence)进行建模,同时保证模型在拥有千万级用户和庞大商品库的情况下,依然具备极低复杂度的批量推理能力?
需要详细解释的几个要素:
• 输入(Input):
对于给定的目标用户 ,其输入不是杂乱的点击序列,而是该用户曾经购买过的所有历史商品集合 。特别地,模型将每个商品的历史提取为一段长达 天的真实的“二元日历时间序列(binary time series)”(例如长度为 365 的向量,某天买了该商品就是 1,没买就是 0)。• 输出(Output):
模型输出一个精细的排序得分列表,代表用户历史购买过的每一个商品在下一个购物篮 中出现的概率。• 为什么这个问题很难(当前研究痛点):
难点在于“时间粒度的提取”与“空间复杂度的爆炸”之间的矛盾。如果我们用 365 天作为输入维度,对每个商品都运行一次长序列自注意力机制(Self-Attention),由于注意力机制是二次方复杂度 ,当用户的历史购物清单里有几百个商品时,显存会立刻溢出。现有的方法要么为了降低复杂度牺牲了真实日历时间(如 BERT4NBR),要么保留了时间但丢掉了线上推理的可行性(如 TIFUKNN)。
2. 创新:作者提出了什么新的方法、模型或技术?
作者提出了一种全新的架构:CASE (Cadence-Aware Set Encoding),即节律感知的集合编码器。
方法的整体思路与核心创新点:
CASE 最大的架构哲学是:“将单一商品的周期学习(节律学习),与商品之间的关联学习(交互学习)彻底解耦。”
• 创新点一:绝对日历时间信号的构建(Calendar-Time Signal)
摒弃了传统的序列 Index。CASE 将用户的历史直接投影在真实的日历轴上。这样,即使模型没有被重新训练,随着时间推移,代表今天的“指针”向前移动,商品的输入表征也会随之改变,从而实现了不依赖新交易的动态评分刷新。• 创新点二:共享的多尺度时间卷积网络(Shared Multi-scale CNN)
针对上述长达 天的二元向量,CASE 没有使用复杂的循环神经网络(RNN)或 Transformer,而是使用了最经典的一维卷积神经网络(1D-CNN)。作者设计了 5 个不同感受野的卷积核(按周、双周、月、季、半年),以非重叠滑动窗口的形式提取节律。最关键的创新在于“共享权重(Shared weights)”:这些卷积核的参数是全网用户和商品共享的,它学习的是一种“人类群体固有的周期规律”,彻底摆脱了为每个人维护参数的沉重负担。• 创新点三:引入诱导集合注意力模块(Induced Set Attention Blocks, ISAB)
在提取完各个商品的节律特征后,我们需要考察商品之间的“共现依赖”(比如买了牛奶大概率也会买面包)。由于商品集合是无序的(Unordered Set),CASE 采用了最初在 Set Transformer 中提出的 ISAB 架构。传统的注意力需要让篮子里的 个商品两两交互,复杂度 。ISAB 巧妙地引入了 个“全局诱导点(Induced points)”,让 个商品先与这 个点交互,再由这 个点将信息广播回 个商品。这直接将复杂度从 降维打击到了 ,让大规模工业部署成为可能。
3. 比较:论文与哪些现有方法进行比较?
为了验证权威性,作者精心挑选了代表当前四个不同研究流派的强大基线模型进行全面厮杀:
• TIFUKNN: • 特点:基于时间衰减的 KNN 协同过滤算法。 • 差异:TIFUKNN 的确考虑了日历时间衰减,但它是记忆型的邻居召回算法,推理复杂度随全网用户数呈线性增长。CASE 的核心差异在于它是一个参数化(Parametric)的神经网络,推理复杂度仅与当前用户的历史候选商品数相关,完美实现 的全网用户解耦。 • DNNTSP: • 特点:利用图神经网络(GNN)在项目共现图上进行聚合,并在“序列索引(Basket-index)”维度上执行时间注意力。 • 差异:受限于“序列索引”,DNNTSP 对真实的节律周期极其迟钝。CASE 则是直接在日历坐标系下进行多尺度卷积。 • BERT4NBR: • 特点:经典的序列推荐大成者,利用双向 Transformer 对篮子序列进行掩码自注意力学习。 • 差异:依然是基于 Basket-index 的受害者,并且缺乏针对长周期、低频次商品的局部特征捕捉能力。 • PIETSP: • 特点:近期提出的可扩展架构,利用排列等变(Permutation-equivariant)均值池化进行集合聚合,解决了部分扩展性问题。 • 差异:PIETSP 也是一种集合聚合方法,但它缺乏商品级别的多尺度节律特征提取(multi-scale cadence patterns at the item level)。CASE 的 CNN 模块补足了这一最关键的短板。
4. 核心理论假设
核心理论假设:人类在零售场景下的购买行为具有群体普遍性(Population-wide recurring patterns)。
• 直觉上的理解方式:
传统模型试图去死记硬背“张三喜欢每 7 天买一次 A 牌牛奶”。但 CASE 的理论假设是:我们不需要去记住张三,因为不管是张三、李四还是王五,“一桶 2 升装的鲜奶保质期和消耗速度就是 7 天”。这种物理和生理属性决定的周期,是全人类共享的客观规律。• 理论解释:
通过将购买历史转化为二元日历信号,并施加具有固定步长(Stride)的卷积核,系统实际上是在执行频域分析。共享的 CNN 参数实质上是一个在海量数据中训练出来的“频段滤波器(Frequency Filter)”。一旦滤波器训练成型,任何一个用户只要输入他最近 30 天的打点信号,滤波器就能瞬间共振,输出他今天到底处在“周期刚开始”还是“即将耗尽待补货”的精确节律相位(Cadence Phase)中。由于这种节律是独立于用户身份存在的,模型就获得了极强的泛化能力。
四、研究方法(Methodology)
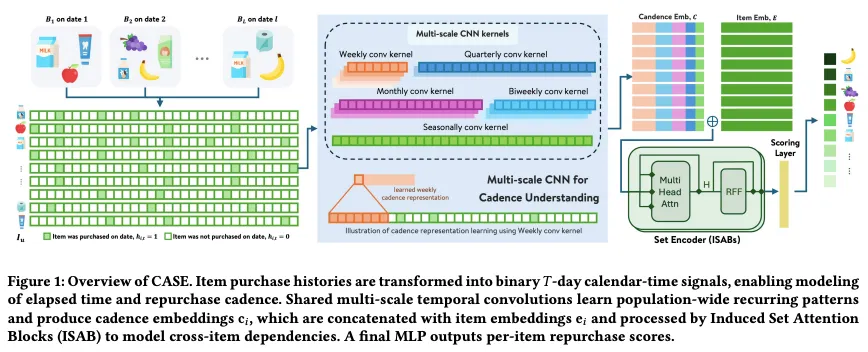
本节我们将以结构化的方式,自上而下地解剖 CASE 框架的内部运作管线。读者可以通过论文提供的架构图(Figure 1)结合以下文字,获得极具工程美感的理解。
4.1 整体方法框架工作流程
CASE 的整个前向传播(Forward Pass)被极其优雅地拆解为三个连贯的阶段:
1. 日历空间投影:将杂乱的购物清单平铺展开,变成一卷带有真实日历刻度的“打孔纸带”(即二元打点序列)。 2. 独立节律提纯(CNN阶段):针对购物清单里的每一个商品,让它独立通过一个由多个卷积核组成的“多级筛子”,筛出这个商品专属于当前的节律密码(Cadence Embedding)。 3. 全局依赖注入(ISAB阶段):将刚才提纯出的所有商品的节律密码打包,送入一个高级注意力会议室。在这个会议室里,不同的商品互相“察言观色”,结合彼此的存在,调整出最终的购买冲动得分。
4.2 关键技术模块详解
模块一:日历时间历史表征(Calendar-Time History Representation)
• 输入转化:假设目标用户 的历史候选商品集为 。对于其中的每一个商品 ,我们构建一个长度为 的滚动时间窗(例如过去 天)。构建一个二元指示向量 。如果在第 天用户购买了商品 ,则 ,否则为 。 • 作用深度解析:这种极其稀疏的 One-hot 式表征看似简单,却是整个框架的灵魂。它有两个无可替代的作用:首先,它完美保留了两次购买之间的真实时间间隔(Inter-purchase intervals);其次,不管这 天里用户买了 1 次还是 100 次,输入向量的维度始终是固定的 ,这为后续的矩阵批处理卷积扫清了维度对齐的障碍。
模块二:多尺度时间卷积网络(Multi-Scale Temporal CNN)
• 结构参数:这是 CASE 处理时间序列的核心武器。针对输入的 ,模型并行应用了 5 组一维卷积核(1D-CNN)。这 5 组卷积核的窗口大小()被极具业务洞察力地硬编码为: • (每周节律) • (双周发薪日节律) • (按月节律) • (季度/换季节律) • (半年度/长期趋势) • 核心机制:每一个卷积核的步长(Stride)被严格设定为与窗口大小相同(),这意味着窗口之间是不重叠的(Non-overlapping windows)。 • 作用深度解析:为什么用卷积不用 LSTM?因为 RNN 类模型具有极强的马尔可夫遗忘性,难以捕捉长达半年的固定周期。而这种步长等于窗口大小的卷积,本质上是一种“周期池化”。它将长度为 的信号,粗暴且有效地折叠成了 5 个不同频率的节律激活特征。随后,这 5 个尺度的特征被拼接(Concat)并送入两层带有 ReLU 的全连接层,最终生成一个高度浓缩的 节律嵌入(Cadence Embedding, )。
模块三:诱导集合注意力编码(Induced Set Attention Encoding)
• 特征融合:刚才提取的是纯粹的“节律”,为了引入商品本身的属性,模型将节律嵌入 与从嵌入表中查出的商品固定语义嵌入 进行拼接,得到一个完整的综合表征 。 • ISAB 注意力机制:对于用户 历史买过的 个商品,我们现在拥有了一个无序的集合表征 。普通的自注意力机制计算复杂度是 ,当用户是个超级购物狂时这会是灾难。CASE 引入了 ISAB (Induced Set Attention Blocks)。 • 作用深度解析:ISAB 的精妙之处在于它虚拟出了一组数量固定为 (论文中 )的“可学习诱导点(Learnable induced points)”。 1. 首先,这 个诱导点作为 Query,去对那 个商品进行交叉注意力计算。这样 个点就浓缩了整个篮子的全局上下文(复杂度 )。 2. 接着,再让那 个商品作为 Query,反向对这包含全局信息的 个诱导点进行注意力请求,提取出被跨商品依赖修正后的最终表征 (复杂度依旧是 )。
这样,既让商品之间产生了奇妙的化学反应(例如:“尿布”发现全局池里有“啤酒”,于是调整了自己的得分),又守住了工业部署的算力红线。
模块四:评分与训练(Scoring and Training)
• 最终,每个经过 ISAB 洗礼的向量 被独立送入一个两层 MLP 预测网络,输出一个在 $$ 之间的标量分数 。在推理时,所有的候选商品根据 从高到低排序呈现给用户。 • 损失函数采用最经典的二元交叉熵(Binary Cross-Entropy)。出现在下一篮子 中的历史商品为正样本,未出现的为负样本。
五、实验结果与分析
为了证明 CASE 的霸主地位,沃尔玛团队在极具代表性的四大零售公开及私有数据集上进行了详尽的评测,并深入生产线做出了震撼的 AB 测试预演。
1. 实验数据集的代表性
实验选用了:Instacart(杂货铺、历史丰富)、TaFeng(台湾大型超市、历史稀疏)、DC(极度稀疏、每个篮子只有 1.6 个商品)、以及沃尔玛内部的 Proprietary 数据集(极其庞大的商品库和复杂的用户行为)。评价指标为工业界极其看重的精准率(Precision)、召回率(Recall)以及衡量排序质量的 NDCG。
2. 核心实验结果:全方位的性能碾压
如表 1(Table 1)所示,CASE 在所有四个数据集的不同截断数下()几乎包揽了所有的最佳成绩。
• 对战序列模型(DNNTSP, BERT4NBR)的降维打击:
在任何数据集上,CASE 都大幅甩开了基于序列索引的强大 Transformer 和 GNN 基线。这以无可辩驳的数据验证了前文的论点:“序列索引”建模方式是复购场景下的一种结构性缺陷(Structural limitation),再复杂的注意力图网络都无法弥补丢失日历时间所带来的伤害。• 在极度稀疏场景下战胜 TIFUKNN:
TIFUKNN 一直是该领域的王者基线。在历史极其稀疏的 TaFeng 和 DC 数据集上,TIFUKNN 因为找不到足够丰富的相似邻居,性能出现滑坡。而 CASE 凭借着跨全网共享参数的 CNN 模块,成功地泛化并提取出了普遍的节律,在稀疏场景下取得了极其显著的领先。即使在极其丰富的 Instacart 和私有数据上,CASE 也保持着微弱的领先,且别忘了,TIFUKNN 根本无法真正在线部署,而 CASE 可以。
3. 消融实验深度解析:一个震撼的工程发现
消融实验(Ablation Study,见 Table 2)带来了整篇论文最具启发性的工程发现:
• CNN 是绝对的主力(Dominant component):一旦移除多尺度 CNN 模块,模型性能呈现断崖式下跌,这再次实锤了“真实日历节律”才是预测复购的第一生产力。 • 商品 Embedding 竟然没那么重要?:论文尝试在输入中直接移除代表商品语义的 Item Embeddings( CASE w/o Item Embedding)。令人震惊的是,模型的性能仅仅出现了极其轻微的下降(modest degradation)!• 这个现象为什么极其重要?
在工业级推荐系统中,庞大商品库(上千万的 SKU)对应的 Embedding Table 是极其耗费服务器显存和内存读写带宽的吞金兽。如果模型仅仅依靠时间节律(Cadence)本身就能取得卓越的表现,这意味着在部署 CASE 时,我们可以大幅降低对庞大且需要频繁刷新的 Embedding 表的依赖。 这一特性使得 CASE 面对千万级 Item Catalog 的扩展时,几乎没有任何工程负担,这才是架构师们梦寐以求的“轻量级(Lightweight)”属性。
4. 工业生产线上的真实威力
在沃尔玛内部千万级用户规模的生产系统对比测试中,CASE 面对当前线上正在服役的强大生产模型,取得了惊人的相对提升(Relative Lift):在 Top-5 推荐中,精准率(Precision)相对提升了 8.63%,召回率(Recall)提升了 9.90%,NDCG 暴涨了 10.46%(见 Table 3)。要知道,在成熟的电商巨头系统中,大盘核心指标哪怕提升 0.5% 都足以带来数以亿计的额外营收。并且,由于 CASE 的推断复杂度是 ,如此巨大的性能飞跃没有引入任何额外的在线延迟(without introducing additional latency)。
六、对未来研究的启发
CASE 的惊艳亮相,标志着“节律感知”与“集合编码”在零售推荐领域的巨大成功。展望未来,该架构为生成式推荐和时间序列建模留下了极其丰富的探索空间:
1. 动态自适应的滚动窗口设计:当前 CASE 对所有商品采用了一刀切的 天固定窗口。未来的研究可以探索“注意力机制引导的动态时间窗”,让购买极其频繁的生鲜商品聚焦于近 30 天,而购买频率极低的家电配件自动扩展到 3 年的时间窗,以进一步降低无效数据的计算量。 2. 融入生成式大语言模型(LLMs)的语义对齐:目前的 CASE 证明了 Item Embedding 不是那么重要,但那是基于纯粹的 ID 协同过滤。在当前“生成式推荐系统”爆发的背景下,如果能利用大语言模型(LLM)提取出商品深度的“自然属性描述词(如:易耗品、家庭装、季节抛)”,将其与 CNN 提取出的节律 Embedding 进行特征对齐或对比学习,可能会解锁跨类目(Cross-category)的零样本(Zero-shot)复购预测能力。 3. 异构时间序列的频域分析升级:多尺度 1D-CNN 虽好,但依赖人工指定窗口(如 7、14、28)。未来可引入类似于离散傅里叶变换(DFT)或连续小波变换(CWT)的网络层,让神经网络自己在高维频域空间中去“嗅探”那些人类尚未察觉的隐藏复购周期律。
七、通俗版总结
如果把逛超市买东西比作一场交响乐,那么牛奶、鸡蛋的购买就像是紧凑的鼓点(每 7 天敲一次),而卫生纸、洗发水则是舒缓的大提琴(每 30 天拉一弓)。
这篇由沃尔玛全球科技团队提出的论文,要解决的就是传统 AI 推荐系统的一个致命缺陷:它们是“没有时间概念的音盲”。旧 AI 只记得你上一次、上上次买了什么,却完全不知道距离现在已经过去了几个真实日历天。这导致推荐的商品不是你家还没吃完的,就是你昨天刚去便利店买过的。
为了治好 AI 的“时间盲症”,工程师们发明了 CASE 架构。它就像给每个商品装上了一个专属的“多频段节拍器(多尺度卷积网络)”,能够通过全网大数据精准测算出每种物品独特的消耗周期。同时,为了避免计算量太大把服务器挤爆,它还引入了一种极具巧思的“诱导注意力机制”,让成百上千个商品能光速完成相互搭配的讨论。
最终,这个能敏锐察觉你家里东西还剩多少的贴心 AI 管家,不仅在公开测试中碾压了前辈,更在真实的巨型零售系统中让推荐准确率暴涨了 8.6%。更绝的是,它甚至不需要记住商品本身是什么,光靠“算日子”就能猜出你该买什么了!这为未来的智能零售铺平了道路。
