 夜雨聆风
夜雨聆风今日相关 / Relevant Today
AI4Protein 前沿追踪
AI 深度解读
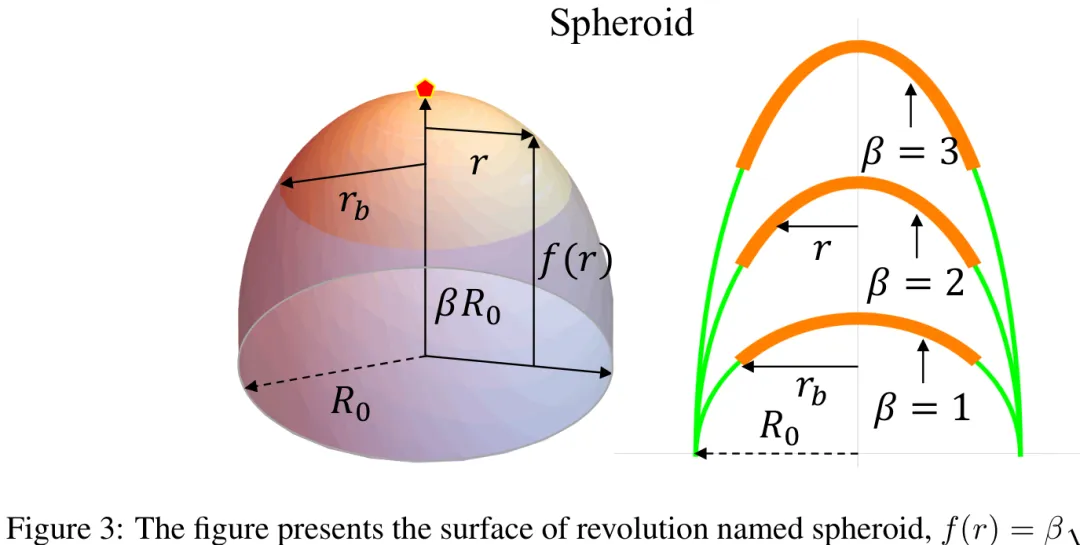
该附录旨在建立旋转对称条件下的协变弹性理论,并推导相应的控制方程与边界条件。研究首先构建了部分形成的弹性壳体的自由能泛函,将其分解为拉伸能、弯曲能、促进晶体生长的单体间吸引相互作用能以及边界线张力能。其中,拉伸能项包含应变张量的二次项,弯曲能项则基于两个主曲率半径与自发曲率的偏差进行描述。理论分析指出,由于拉伸能与弯曲能的最小化条件相互冲突,不存在能同时使两者达到极值的表面;唯有特定的几何形状(如平面、圆柱面或球面)能在特定约束下实现能量平衡。基于旋转对称性假设(x=rcosθ, y=rsinθ, z=f(r)),推导了实际度量与参考度量下的非零克里斯托费尔符号,并给出了具体的应力张量分量表达式。最终,通过变分原理导出了确定参考半径函数 r̅(r) 的微分方程,该方程描述了在吸引相互作用与线张力共同作用下,弹性壳体的平衡形态演化规律。
中文摘要
摘要:我们利用一种物理信息神经网络(Physics-Informed Neural Network, PINN)在曲面上学习参数化的非线性弹性力学,该网络通过在损失函数中直接施加控制方程和边界条件,使得单个训练好的模型能够表示跨越几何与材料参数连续变化的弹性平衡态族。曲面上的非线性弹性力学是晶体壳、弹性薄膜及病毒衣壳等结构的力学基础,其中曲率与拓扑缺陷决定了其平衡构型与稳定性。传统的精确解法与有限元求解器依赖于对称性简化,且需针对每个参数选择重新初始化,这在对称性破缺或参数变化时限制了其可扩展性。我们在曲弹性学的一个基准问题上验证了所提出的基于学习的求解器,即球面上具有已知精确解和数值解的一维单位向错问题。该网络能够准确复现这些解,包括训练集中未包含的参数组合,展现了在几何与材料 regimes 上的泛化能力。本研究建立了一个用于学习曲面上非线性弹性系统的可扩展框架,并为扩展至与蛋白壳及其他曲弹性网络相关的完全二维和多缺陷构型奠定了基础。
Paper Key Illustration
原文
Learning Parameterized Nonlinear Elasticity on Curved Surfaces
Abstract: We learn parameterized nonlinear elasticity on curved surfaces using a physics-informed neural network that enforces governing equations and boundary conditions directly through the loss function, enabling a single trained model to represent a continuous family of elastic equilibria across geometric and material parameters. Nonlinear elasticity on curved manifolds underlies the mechanics of crystalline shells, elastic membranes, and viral capsids, where curvature and topological defects determine equilibrium structure and stability. Traditional exact and finite element solvers rely on symmetry reduction and must be reinitialized for each parameter choice, limiting scalability when symmetry is broken or parameters vary. We validate the proposed learning-based solver on a benchmark problem from curved elasticity, namely the one-dimensional single disclination on a spheroidal surface with known exact and numerical solutions. The network accurately reproduces these solutions, including parameter combinations excluded from training, demonstrating generalization across geometry and material regimes. This study establishes a scalable framework for learning nonlinear elastic systems on curved manifolds and lays the groundwork for extensions to fully two-dimensional and multi-defect configurations relevant to protein shells and other curved elastic networks.
链接:https://arxiv.org/pdf/2604.12170
AI 深度解读
该研究针对蛋白质突变适应性预测任务,提出了一种名为 TriFit 的超模态框架。该方法创新性地整合了序列、结构及基于高斯网络模型(GNM)的蛋白质动力学三种模态,并采用混合专家(MoE)融合模块与跨模态对比学习机制。在包含 217 种 DMS 实验和 69.6 万个单氨基酸变体的 ProteinGym 基准测试中,TriFit 取得了 0.897 的 AUROC 分数,显著超越了包括 Kermut、ProteinNPT 在内的所有监督基线以及零样本模型 ESM3。消融实验证实,动力学模态在与其他模态结合时贡献了最大的边际增益(相比仅含序列和结构的模型提升 2.2 个点),且 MoE 路由机制能根据蛋白质特性主动选择结构 - 动力学或全模态专家,而非被动抑制动力学信息。此外,模型展现出优异的校准能力(ECE = 0.044),无需后处理即可满足临床变异解读的需求。研究填补了生物物理理论与机器学习实践之间的长期空白,证明了将动力学嵌入作为第三模态对于提升变异效应预测性能的关键作用。
中文摘要
摘要:预测单个氨基酸替换(SAVs)的功能影响是理解遗传疾病和工程化治疗性蛋白质的核心。尽管蛋白质语言模型和基于结构的方法在该任务上取得了显著成效,但它们系统性地忽视了蛋白质动力学;残基柔性、相关运动以及变构耦合是结构生物学中公认的突变耐受性决定因素,却尚未被纳入监督式变异效应预测器。我们提出了 TriFit,这是一个多模态框架,通过具有三模态跨模态对比学习的四专家混合专家(MoE)融合模块,整合了序列、结构和蛋白质动力学信息。序列嵌入通过 ESM-2(650M)的掩蔽边际评分提取;结构嵌入源自 AlphaFold2 预测的 C-alpha 几何构型;动力学嵌入则来源于高斯网络模型(GNM)的 B 因子、模态形状以及残基 - 残基互相关系数。MoE 路由器根据输入自适应地加权模态组合,从而实现无需固定模态假设的蛋白质特异性融合。在 ProteinGym 替换基准测试(包含 217 个 DMS 测定和 69.6 万个 SAVs)上,TriFit 的 AUROC 达到 0.897 ± 0.0002,优于所有监督式基线模型,包括 Kermut(0.864)和 ProteinNPT(0.844),以及表现最佳的零样本模型 ESM3(0.769)。消融研究证实,动力学在三模态组合中提供了最大的边际贡献,且 TriFit 在未进行事后校正的情况下实现了良好的概率输出校准(ECE = 0.044)。
Paper Key Illustration
原文
TriFit: Trimodal Fusion with Protein Dynamics for Mutation Fitness Prediction
Abstract: Predicting the functional impact of single amino acid substitutions (SAVs) is central to understanding genetic disease and engineering therapeutic proteins. While protein language models and structure-based methods have achieved strong performance on this task, they systematically neglect protein dynamics; residue flexibility, correlated motions, and allosteric coupling are well-established determinants of mutational tolerance in structural biology, yet have not been incorporated into supervised variant effect predictors. We present TriFit, a multimodal framework that integrates sequence, structure, and protein dynamics through a four-expert Mixture-of-Experts (MoE) fusion module with trimodal cross-modal contrastive learning. Sequence embeddings are extracted via masked marginal scoring with ESM-2 (650M); structural embeddings from AlphaFold2-predicted C-alpha geometries; and dynamics embeddings from Gaussian Network Model (GNM) B-factors, mode shapes, and residue-residue cross-correlations. The MoE router adaptively weights modality combinations conditioned on the input, enabling protein-specific fusion without fixed modality assumptions. On the ProteinGym substitution benchmark (217 DMS assays, 696k SAVs), TriFit achieves AUROC 0.897 +/- 0.0002, outperforming all supervised baselines including Kermut (0.864) and ProteinNPT (0.844), and the best zero-shot model ESM3 (0.769). Ablation studies confirm that dynamics provides the largest marginal contribution over pairwise modality combinations, and TriFit achieves well-calibrated probabilistic outputs (ECE = 0.044) without post-hoc correction.
链接:https://arxiv.org/pdf/2604.12026
AI 深度解读
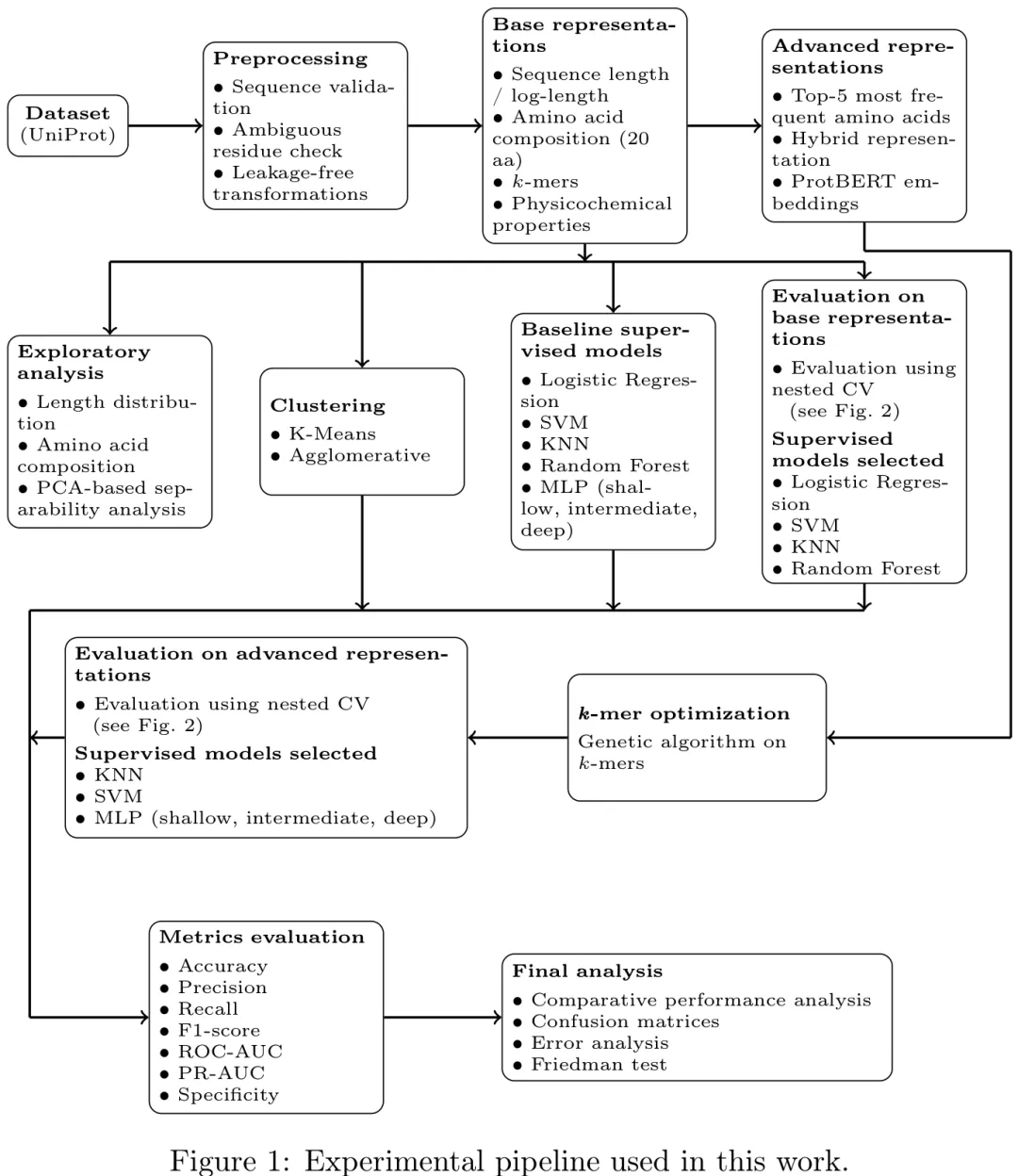
本研究针对帕金森病相关蛋白与控制蛋白的二元分类任务,构建了一个包含 304 条人类蛋白序列(152 条患病、152 条对照)的 curated 数据集。研究首先对序列长度、氨基酸组成、理化性质及 k-mer 等基础特征进行了探索性分析,并验证了数据的完整性与质量。在实验设计上,采用分层 5 折交叉验证以应对小样本挑战,并引入嵌套交叉验证(外层 5 折评估、内层 3 折调参)及遗传算法进行 k-mer 特征优化,严格防止数据泄露。模型评估涵盖了逻辑回归、SVM、KNN、随机森林及多层感知机(MLP)等多种监督学习算法,并对比了基于 ProtBERT 等的高级嵌入表示。最终通过准确率、F1 分数、ROC-AUC 等多维指标及 Friedman 检验,系统比较了不同特征表示与模型架构在区分帕金森相关蛋白方面的性能差异,旨在揭示影响分类效果的关键因素并选出最优模型组合。
中文摘要
摘要:由于帕金森病(PD)具有多因素特性,识别其可靠的分子生物标志物仍具挑战性。尽管蛋白质序列构成了基础且广泛可用的生物信息来源,但其单独用于复杂疾病分类的判别能力尚不明确。本研究对仅源自蛋白质一级序列的多种表示形式进行了受控且无数据泄露的评估,包括氨基酸组成、k-mer、理化描述符、混合表示以及来自蛋白质语言模型的嵌入表示,并在嵌套分层交叉验证框架下评估,以确保性能估计的无偏性。表现最佳的配置(ProtBERT + MLP)实现了 0.704 ± 0.028 的 F1 分数和 0.748 ± 0.047 的 ROC-AUC,表明其判别性能仅处于中等水平。传统的表示形式(如 k-mer)可达到相当的 F1 值(最高约 0.667),但表现出高度不平衡的行为:召回率接近 0.98,精确率约为 0.50,反映出对阳性预测的强烈偏差。在不同表示形式之间,性能差异范围狭窄(F1 值介于 0.60 至 0.70 之间);无监督分析显示不存在与类别标签一致的内禀结构;统计检验(Friedman 检验,p = 0.1749)也未显示模型间存在显著差异。这些结果表明类别间存在显著重叠,并说明仅凭一级序列信息对帕金森病分类提供的判别能力有限。本研究建立了一个可复现的基线,并提供了实证证据,表明需要更具信息量的生物特征(如结构、功能或基于相互作用的描述符)才能实现鲁棒的疾病建模。
Paper Key Illustration
原文
Evaluating the Limitations of Protein Sequence Representations for Parkinson's Disease Classification
Abstract: The identification of reliable molecular biomarkers for Parkinson's disease remains challenging due to its multifactorial nature. Although protein sequences constitute a fundamental and widely available source of biological information, their standalone discriminative capacity for complex disease classification remains unclear. In this work, we present a controlled and leakage-free evaluation of multiple representations derived exclusively from protein primary sequences, including amino acid composition, k-mers, physicochemical descriptors, hybrid representations, and embeddings from protein language models, all assessed under a nested stratified cross-validation framework to ensure unbiased performance estimation. The best-performing configuration (ProtBERT + MLP) achieves an F1-score of 0.704 +/- 0.028 and ROC-AUC of 0.748 +/- 0.047, indicating only moderate discriminative performance. Classical representations such as k-mers reach comparable F1 values (up to approximately 0.667), but exhibit highly imbalanced behavior, with recall close to 0.98 and precision around 0.50, reflecting a strong bias toward positive predictions. Across representations, performance differences remain within a narrow range (F1 between 0.60 and 0.70), while unsupervised analyses reveal no intrinsic structure aligned with class labels, and statistical testing (Friedman test, p = 0.1749) does not indicate significant differences across models. These results demonstrate substantial overlap between classes and indicate that primary sequence information alone provides limited discriminative power for Parkinson's disease classification. This work establishes a reproducible baseline and provides empirical evidence that more informative biological features, such as structural, functional, or interaction-based descriptors, are required for robust disease modeling.
链接:https://arxiv.org/pdf/2604.11852
AI 深度解读
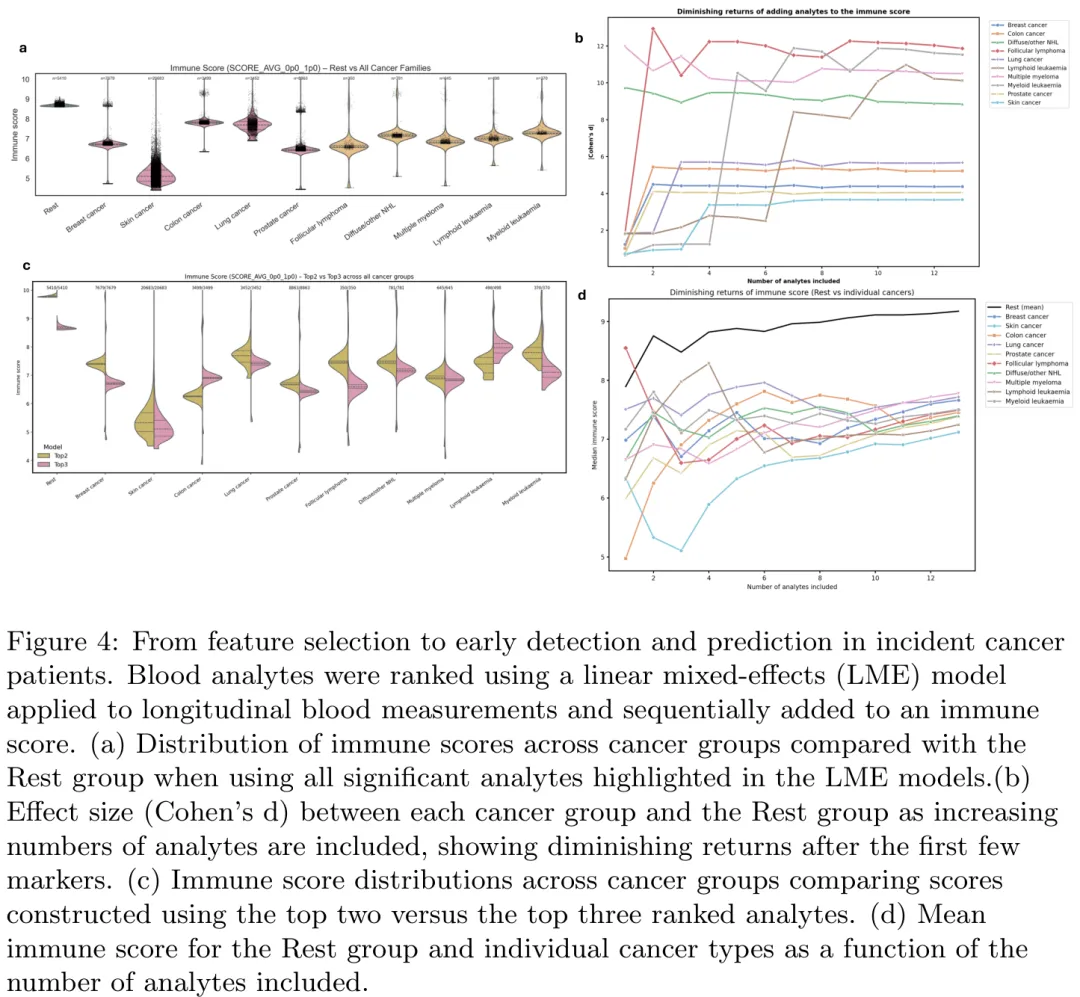
本研究旨在通过纵向分析识别与疾病相关的稳健血液学标志物,以揭示横断面分析无法捕捉的早期临床前改变。研究利用线性混合效应模型(LME),分别按性别拟合模型,通过校正后的疾病 - 时间交互项构建疾病特异性签名。这些签名代表了多分析物偏离基线衰老轨迹的协调时间偏差。
在泛疾病模式分析中,研究发现几乎所有全血细胞计数(CBC)分析物在基线(时间点 0.0)即存在显著组间差异,其中心血管疾病(CVD)与休息组、感染与休息组的对比最为强烈。然而,纵向变化(delta)的组间差异较少,提示组内异质性可能掩盖了变化幅度的差异。具体而言,癌症组显示出 19 个分析物的显著时间变化,CVD 组为 17 个,感染组为 11 个。CVD 和癌症组均表现为红细胞指数(如 MCH、MCHC)随时间增加,而红细胞、中性粒细胞计数和血细胞比容下降;慢性感染组则相对稳定。LME 模型进一步证实,癌症组中红细胞指数(MCH、MCV、RBC、血红蛋白)及部分免疫细胞与时间存在显著交互作用,而慢性感染组仅有两个分析物(单核细胞计数和百分比)显著。
针对癌症特异性签名,研究区分了从健康到恶性的过渡(新发病例)与持续改变的血液学特征(既存病例)。新发病例在确诊前数年即出现血液学偏离,且其时间轨迹变化最为显著,特别是在血小板和中性粒细胞相关标志物上。既存病例则表现出中间模式。白细胞的亚型轨迹各异:癌症组单核细胞计数持续高于休息组,而淋巴细胞水平从休息组到癌症组呈渐进式下降,显示出向髓系主导谱系的转变。此外,研究将癌症细分为血液肿瘤和实体瘤,发现血液肿瘤中血红蛋白、血细胞比容和 RBC 等红细胞标志物显著低于休息组和实体瘤组,显示出梯度性的红细胞抑制现象。这些发现为早期检测提供了时间窗口,并量化了不同疾病状态下血液学特征的动态演变。
中文摘要
摘要:我们研究了多种疾病(包括癌症、心血管疾病和感染性疾病)中常见血液学检测指标随时间变化的纵向行为,将其作为疾病标志物及疾病进展的函数进行分析。我们探讨了混杂因素与非混杂因素,旨在基于常规临床检测中广泛使用的、可规模化普及的常见血液检测(尤其是全血细胞计数,即 CBC 或 FBC)所测得的生物标志物模式,实现对疾病和状况的早期检测。通过对归一化时间曲线和机器学习技术的分析,即使在症状出现之前,我们也发现血液检测中的分析物组模式具有疾病敏感性和疾病特异性。我们证明,CBC 标志物贡献了大部分预测信号,而生化检测和其他血液面板仅提供适度的额外增益,这些增益主要与特定设计的个体疾病相关(例如 C 反应蛋白、肝酶、血糖等)。我们的结果展示了如何通过定期监测、计算智能以及应用于纵向 CBC 数据的机器学习技术来揭示疾病模式,从而借助现有且普遍存在的血液检测,在大规模层面推动精准医疗和预测医学的发展。
Paper Key Illustration
原文
Patterns in Individual Blood Count Trajectories in the UK Biobank Characterise Disease-Specific Signatures and Anticipate Pan-Cancer Risk
Abstract: We investigate the longitudinal behaviour of blood markers from common haematological tests as a marker of disease and as a function of disease progression in a variety of conditions including cancer, cardiovascular disease, and infections. We study confounding and non-confounding factors to allow for the earlier detection of disease and conditions based on their longitudinal signatures from biomarker patterns commonly measured in popular and scalable common blood tests across routine clinical tests, in particular the Complete Blood Count (CBC or FBC). Our analysis with normalised temporal profiles and machine learning techniques even before any symptoms appear demonstrates that analyte-group patterns found in blood testing are disease sensitive and disease specific. We demonstrate that CBC markers contribute to the majority of the predictive signal, while biochemistry and other blood panels provide only a modest additional gain mostly associated to very the individual disease for which the test was designed (e.g. CRP, liver enzymes, blood sugar). Our results demonstrate how regular monitoring, computational intelligence, and machine learning applied to longitudinal CBC data can converge to uncover disease patterns, advancing the potential for precision healthcare and predictive medicine on a mass scale leveraging an existing and pervasive blood test.
链接:https://arxiv.org/pdf/2604.11824
今日热门 / Popular Today
ArXiv 高热度精选
AI 深度解读
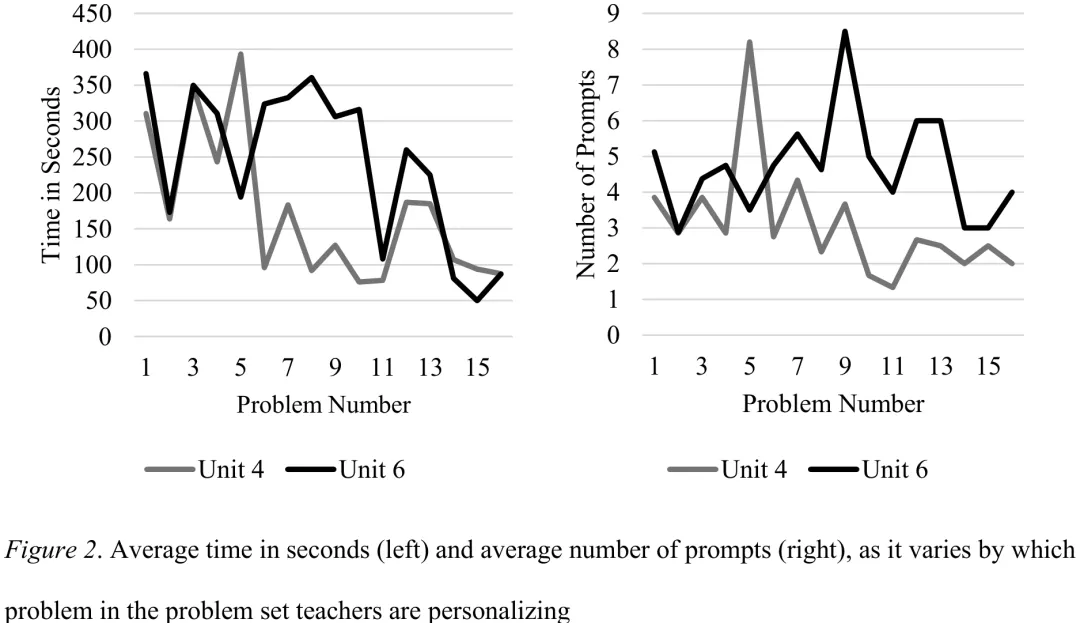
本研究聚焦于教师利用大语言模型(LLM)对现有数学问题进行个性化修改的实践。研究针对 7 名拥有平均 11.9 年教龄的数学教师,他们利用 LLM 为 512 名七年级学生(来自 ASSISTments 平台,使用 IM 课程)生成了 143 个个性化数学问题。研究样本覆盖美国东西南北中不同地区,学生群体包含较高比例的经济弱势群体和少数族裔。
研究旨在解决以下核心问题:教师使用何种提示词(prompts)来修改现有问题以契合学生兴趣;学生对个性化问题的兴趣度评价及改进建议;教师修改问题的效率与学生评价之间的关联;以及教师在不同教学单元(第 4 单元至第 6 单元)中,其问题生成策略在时间消耗、提示词数量及学生评价方面的演变。
该研究突破了以往仅依赖职前教师自我报告或仅关注全新问题生成的局限,转而考察在职教师对现有教材问题的修改过程。通过结合客观的行为数据(如提示词数量、耗时)与学生反馈,研究试图揭示 LLM 在平衡文化相关性、问题准确性及教学效率方面的实际效能,并探讨教师如何从初期的探索逐步优化其人机协作模式,以解决 LLM 可能产生的内容不切实际或阅读负担过重等问题。
中文摘要
摘要:根据个别学生的细粒度需求调整教学指令,是近期大型语言模型(LLM)进展的一项有力应用。这些生成式人工智能模型能够创建契合学生兴趣的任务,并实施情境个性化,从而提升学生对学术内容的学习兴趣。然而,尽管商业生成式人工智能工具宣称能够节省教师时间,但当教师介入生成或修改任务时,该过程的效率尚不明确。本研究联合7名初中数学教师与ChatGPT,为其课程中的问题创建个性化版本,以契合其学生的兴趣。我们考察了教师所采用的提示策略、创建问题的效率,以及接受个性化作业的521名七年级学生的反应。研究发现,教师介入导致生成式人工智能增强的个性化实施粒度相对较粗,而学生则倾向于偏好更细的粒度,即接收能引起他们兴趣的具体流行文化参考。教师在调整流行文化参考以及解决生成问题在深度或真实性方面存在的问题上投入了大量精力,从而赋予生成式人工智能不同程度的自主权。教师在与生成式人工智能合作方面提升了设计有趣问题的能力,但这一过程并未因教师在学习和反思学生数据、迭代其方法而显得特别高效。
Paper Key Illustration
原文
Should There be a Teacher In-the-Loop? A Study of Generative AI Personalized Tasks Middle School
Abstract: Adapting instruction to the fine-grained needs of individual students is a powerful application of recent advances in large language models. These generative AI models can create tasks that correspond to students' interests and enact context personalization, enhancing students' interest in learning academic content. However, when there is a teacher in-the-loop creating or modifying tasks with generative AI, it is unclear how efficient this process might be, despite commercial generative AI tools' claims that they will save teachers time. In the present study, we teamed 7 middle school mathematics teachers with ChatGPT to create personalized versions of problems in their curriculum, to correspond to their students' interests. We look at the prompting moves teachers made, their efficiency when creating problems, and the reactions of their 521 7th grade students who received the personalized assignments. We find that having a teacher-in-the-loop results in generative AI-enhanced personalization being enacted at a relatively broad grain size, whereas students tend to prefer a smaller grain size where they receive specific popular culture references that interest them. Teachers spent a lot of effort adjusting popular culture references and addressing issues with the depth or realism of the problems generated, giving higher or lower levels of ownership to the generative AI. Teachers were able to improve in their ability to craft interesting problems in partnership with generative AI, but this process did not appear to become particularly time efficient as teachers learned and reflected on their students' data, iterating their approaches.
链接:https://arxiv.org/pdf/2602.15876
AI 深度解读
针对虚拟试衣任务中存在的‘训练 - 测试不匹配’(即训练时含残差噪声与推理时纯高斯噪声的分布差异)及传统逆求解器在强制测量约束时易导致语义漂移和边界伪影的问题,本文提出了 ART-VITON 方法。该方法首先通过单步去噪引入残差结构进行先验初始化,以弥合分布差距;随后在采样过程中交替执行‘无伪影测量引导采样’与标准去噪:利用硬测量约束确保非试衣区域的身份保真,结合数据一致性优化与频域修正技术恢复被 VAE 压缩丢失的高频纹理细节,并定期应用标准去噪使轨迹回归数据流形以平滑融合。实验表明,该方法在 VITON-HD 等数据集上有效兼顾了纹理保真度与边界无缝性,显著优于现有基线及纯逆求解器方案。
中文摘要
摘要:虚拟试穿(VITON)旨在生成人物穿着目标服装的真实图像,要求在试穿区域实现精确的服装对齐,并在非试穿区域忠实保留身份特征与背景。尽管潜在扩散模型(LDMs)在服装对齐与细节合成方面取得了进展,但非试穿区域的保留仍具挑战性。一种常见的后处理策略直接将这些区域替换为原始内容,但往往因过渡突兀而产生边界伪影。为克服这一问题,我们将 VITON 重构为线性逆问题,并采用轨迹对齐求解器,逐步强制测量一致性,从而减少非试穿区域的突变。然而,现有求解器在生成过程中仍面临语义漂移问题,导致伪影产生。为此,我们提出了 ART-VITON,这是一种测量引导的扩散框架,在确保测量一致性的同时实现无伪影合成。我们的方法融合了基于残差先验的初始化策略,以缓解训练与推理之间的失配,并采用无伪影的测量引导采样,该采样策略结合了数据一致性、频域校正以及周期性标准去噪。在 VITON-HD、DressCode 和 SHHQ-1.0 数据集上的实验表明,ART-VITON 能有效保留身份特征与背景,消除边界伪影,并在视觉保真度与鲁棒性方面持续优于最先进基线方法。

Paper Key Illustration
原文
ART-VITON: Measurement-Guided Latent Diffusion for Artifact-Free Virtual Try-On
Abstract: Virtual try-on (VITON) aims to generate realistic images of a person wearing a target garment, requiring precise garment alignment in try-on regions and faithful preservation of identity and background in non-try-on regions. While latent diffusion models (LDMs) have advanced alignment and detail synthesis, preserving non-try-on regions remains challenging. A common post-hoc strategy directly replaces these regions with original content, but abrupt transitions often produce boundary artifacts. To overcome this, we reformulate VITON as a linear inverse problem and adopt trajectory-aligned solvers that progressively enforce measurement consistency, reducing abrupt changes in non-try-on regions. However, existing solvers still suffer from semantic drift during generation, leading to artifacts. We propose ART-VITON, a measurement-guided diffusion framework that ensures measurement adherence while maintaining artifact-free synthesis. Our method integrates residual prior-based initialization to mitigate training-inference mismatch and artifact-free measurement-guided sampling that combines data consistency, frequency-level correction, and periodic standard denoising. Experiments on VITON-HD, DressCode, and SHHQ-1.0 demonstrate that ART-VITON effectively preserves identity and background, eliminates boundary artifacts, and consistently improves visual fidelity and robustness over state-of-the-art baselines.
链接:https://arxiv.org/pdf/2509.25749
AI 深度解读
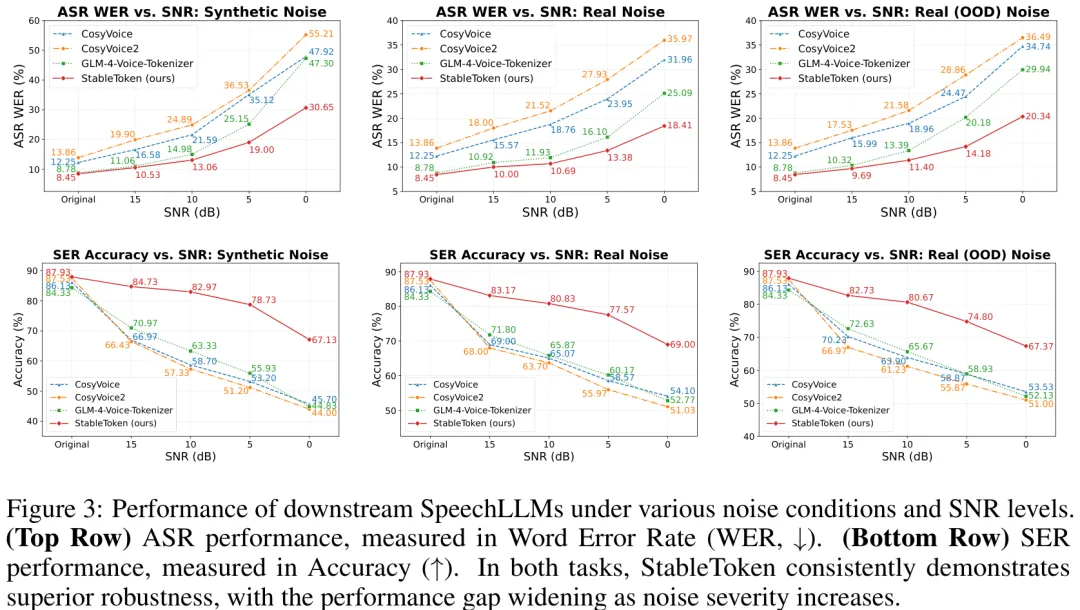
该研究针对现有语音分词器在噪声环境下鲁棒性不足的问题,提出了一种名为 StableToken 的新型架构。其核心创新在于引入了 Voting-LFQ(投票低秩量化)模块,通过并行分支机制和多数投票规则,在保持高保真度的同时显著提升抗噪能力。在训练阶段,研究采用了一种噪声感知的共识训练范式:利用随机噪声扰动部分分支的输入,并设计共识损失函数,迫使所有分支向全局平均表示收敛,从而让模型学会忽略噪声干扰。实验结果表明,StableToken 在 FLEURS 基准测试中展现了卓越的噪声鲁棒性,未牺牲重构质量,且在下游任务(如语音识别、情感识别及语音合成)中均取得了显著的性能提升。该方法证明了通过结构化投票机制和自稳定训练策略,可以有效解决单一量化路径易受噪声影响的问题,为构建高鲁棒性的语音大模型提供了新的技术路径。
中文摘要
摘要:旨在捕捉语言内容的流行语义语音分词器表现出令人惊讶的脆弱性。我们发现,它们对与意义无关的声学扰动并不鲁棒;即使在信噪比(SNR)很高、语音完全可理解的条件下,其输出的 token 序列也可能发生剧烈变化,从而增加了下游大语言模型(LLM)的学习负担。这种不稳定性源于两个缺陷:脆弱的单路径量化架构以及对中间 token 稳定性漠不关心的训练信号。为解决这一问题,我们提出了 StableToken,这是一种通过共识驱动机制实现稳定性的分词器。其多分支架构并行处理音频,并通过强大的逐位投票机制将这些表示合并,形成单一且稳定的 token 序列。StableToken 在 token 稳定性方面树立了新的最先进水平,在各种噪声条件下大幅降低了单元编辑距离(UED)。这种基础性的稳定性直接转化为下游优势,显著提升了 SpeechLLM 在多种任务中的鲁棒性。
Paper Key Illustration
原文
StableToken: A Noise-Robust Semantic Speech Tokenizer for Resilient SpeechLLMs
Abstract: Prevalent semantic speech tokenizers, designed to capture linguistic content, are surprisingly fragile. We find they are not robust to meaning-irrelevant acoustic perturbations; even at high Signal-to-Noise Ratios (SNRs) where speech is perfectly intelligible, their output token sequences can change drastically, increasing the learning burden for downstream LLMs. This instability stems from two flaws: a brittle single-path quantization architecture and a distant training signal indifferent to intermediate token stability. To address this, we introduce StableToken, a tokenizer that achieves stability through a consensus-driven mechanism. Its multi-branch architecture processes audio in parallel, and these representations are merged via a powerful bit-wise voting mechanism to form a single, stable token sequence. StableToken sets a new state-of-the-art in token stability, drastically reducing Unit Edit Distance (UED) under diverse noise conditions. This foundational stability translates directly to downstream benefits, significantly improving the robustness of SpeechLLMs on a variety of tasks.
链接:https://arxiv.org/pdf/2509.22220
AI 深度解读
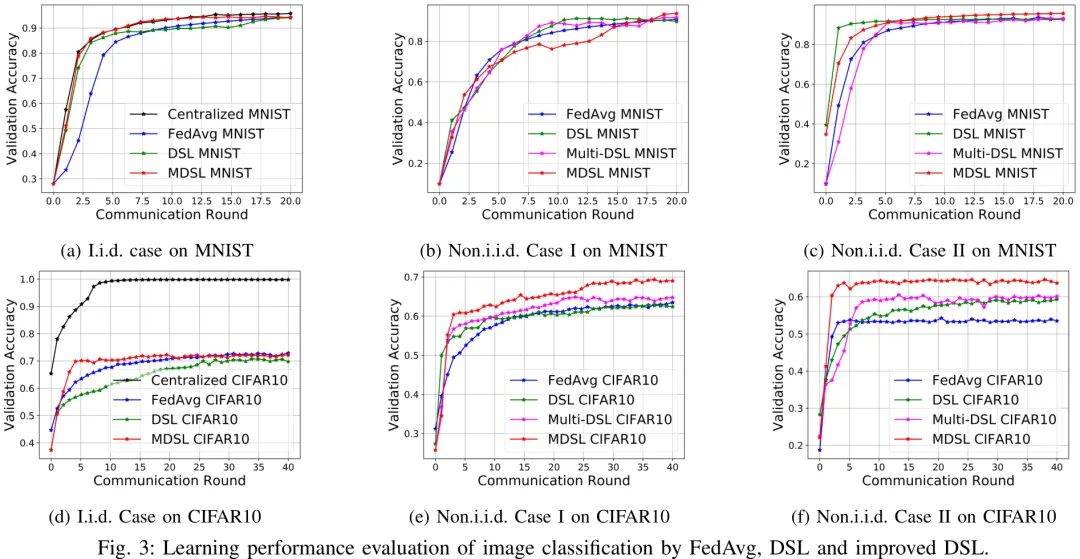
该研究针对非独立同分布(non-i.i.d.)数据环境下的联邦学习场景,提出了一种名为 M-DSL 的改进算法。针对边缘计算中常见的数据异构性问题,M-DSL 设计了包含个体模型参数、局部最佳参数及全局最佳参数的三阶段更新机制。其核心创新在于引入了基于历史性能比较的指示器函数,动态调整局部与全局速度的更新权重,从而在减少通信开销的同时提升模型收敛速度。理论分析部分通过引入梯度平滑性和局部梯度有界性假设,推导了算法的收敛误差上界,证明了在特定学习率下,算法的期望收敛速率与数据分布的非独立同分布程度及通信轮次相关。实验结果表明,M-DSL 在保持较低通信成本的前提下,有效提升了模型在异构数据环境下的收敛性能,为资源受限的边缘物联网设备提供了高效的分布式训练方案。
中文摘要
摘要:分布式群学习(DSL)的最新进展为边缘物联网提供了一种有前景的范式。这些进展提升了数据隐私性、通信效率、节能效果以及模型可扩展性。然而,非独立同分布(non-i.i.d.)数据的存在对多接入边缘计算构成了重大挑战,导致传统 DSL 的学习性能下降且训练行为发散。此外,目前尚缺乏关于数据异质性如何影响模型训练准确性的理论指导,亟需深入探究。为填补这一空白,本文首先通过评估 DSL 框架下非 i.i.d.数据集的影响来研究数据异质性。在此基础上,本文提出了一种名为 M-DSL 的新型多工作节点选择设计,该算法能有效处理分布式异质数据。本文引入并定义了一种新的非 i.i.d. 程度度量指标,用于刻画局部数据集之间的统计差异,从而在数据异质性度量与 DSL 性能评估之间建立了联系。通过这种方式,我们的 M-DSL 能够指导对全局模型更新贡献显著的多个工作节点的有效选择。我们还对 M-DSL 的收敛行为进行了理论分析,并在多种异质数据集和非 i.i.d. 数据设置下开展了广泛实验。数值结果表明,与基准方法相比,我们的 M-DSL 在性能提升和网络智能化增强方面均取得了显著成效。
Paper Key Illustration
原文
Multi-Worker Selection based Distributed Swarm Learning for Edge IoT with Non-i.i.d. Data
Abstract: Recent advances in distributed swarm learning (DSL) offer a promising paradigm for edge Internet of Things. Such advancements enhance data privacy, communication efficiency, energy saving, and model scalability. However, the presence of non-independent and identically distributed (non-i.i.d.) data pose a significant challenge for multi-access edge computing, degrading learning performance and diverging training behavior of vanilla DSL. Further, there still lacks theoretical guidance on how data heterogeneity affects model training accuracy, which requires thorough investigation. To fill the gap, this paper first study the data heterogeneity by measuring the impact of non-i.i.d. datasets under the DSL framework. This then motivates a new multi-worker selection design for DSL, termed M-DSL algorithm, which works effectively with distributed heterogeneous data. A new non-i.i.d. degree metric is introduced and defined in this work to formulate the statistical difference among local datasets, which builds a connection between the measure of data heterogeneity and the evaluation of DSL performance. In this way, our M-DSL guides effective selection of multiple works who make prominent contributions for global model updates. We also provide theoretical analysis on the convergence behavior of our M-DSL, followed by extensive experiments on different heterogeneous datasets and non-i.i.d. data settings. Numerical results verify performance improvement and network intelligence enhancement provided by our M-DSL beyond the benchmarks.
链接:https://arxiv.org/pdf/2509.18367
AI 深度解读
本文深入探讨了人工智能如何加速专业知识的‘外部化’过程,即专业人士将其隐性知识转化为系统可理解的逻辑。研究指出,这一过程不仅源于工程师的主动调整,更大量发生在临床医生进行诊断覆盖、律师优化合同条款或设计师微调生成内容等日常工作中。通过大规模数据分析与持续迭代反馈,AI 系统能够捕捉并编码从业者难以言说的‘关系性隐性知识’(relational tacit knowledge),从而在深度和细腻度上超越以往方法。然而,这种外部化存在明确边界:基于物理操作和身体感知的‘躯体性隐性知识’(somatic tacit knowledge)——如医生的体格检查或律师的谈判技巧——仍难以被算法完全捕捉。研究通过医学、法律、创意设计及金融领域的案例表明,AI 正在重塑专业权威结构,将资深专家的判断压缩进算法,压缩了传统学徒制的层级,迫使从业者向更具复杂性和情感深度的核心职能转型。这一发现揭示了自动化悖论在专业领域的具体表现:系统越强大,其介入的领域越广,但人类专家在特定隐性知识维度上的不可替代性依然构成技术发展的前沿限制。
中文摘要
摘要:本文探讨了一个关于专业专长与人工智能关系中的基本悖论:随着领域专家通过将隐性知识外化而日益与人工智能系统协作,他们实际上可能加速自身专长的自动化进程。通过对多种专业情境的分析,我们识别出人机协作中涌现的新模式,并提出框架以帮助专业人士应对这一不断演变的环境。借鉴知识管理、专长研究、人机交互及劳动经济学等领域的研究成果,我们深入剖析了在人工智能系统能力日益增强的时代,如何保持并转化专业价值。我们的分析表明,虽然隐性知识的外化对传统专业角色构成一定风险,但也为专长的演进及新型专业价值的涌现创造了机遇。最后,本文就专业教育、组织设计及政策制定提出了相关启示,旨在确保专家知识的编码化能够增强而非削弱人类专长的价值。

Paper Key Illustration
原文
The Paradox of Professional Input: How Expert Collaboration with AI Systems Shapes Their Future Value
Abstract: This perspective paper examines a fundamental paradox in the relationship between professional expertise and artificial intelligence: as domain experts increasingly collaborate with AI systems by externalizing their implicit knowledge, they potentially accelerate the automation of their own expertise. Through analysis of multiple professional contexts, we identify emerging patterns in human-AI collaboration and propose frameworks for professionals to navigate this evolving landscape. Drawing on research in knowledge management, expertise studies, human-computer interaction, and labor economics, we develop a nuanced understanding of how professional value may be preserved and transformed in an era of increasingly capable AI systems. Our analysis suggests that while the externalization of tacit knowledge presents certain risks to traditional professional roles, it also creates opportunities for the evolution of expertise and the emergence of new forms of professional value. We conclude with implications for professional education, organizational design, and policy development that can help ensure the codification of expert knowledge enhances rather than diminishes the value of human expertise.
链接:https://arxiv.org/pdf/2504.12654
Subscribe to arXiv's Daily Preprint Notifications
