 夜雨聆风
夜雨聆风多模态是指模型能同时理解和处理多种类型的信息——文本、图像、音频、视频等,而不仅仅是文字。
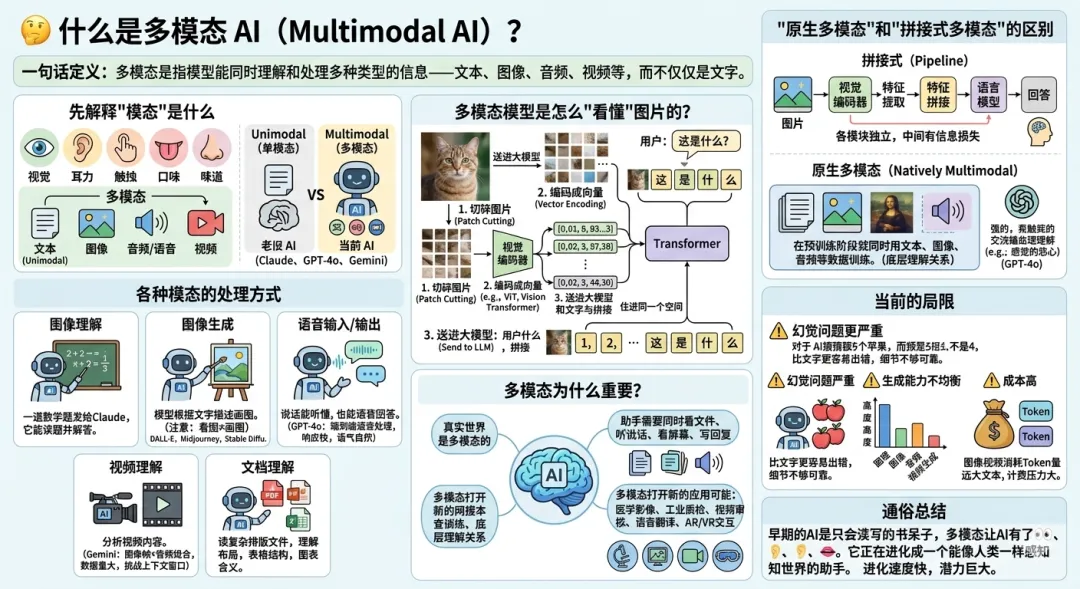
先解释"模态"是什么
"模态"这个词听起来很学术,其实就是"信息的类型"。人类感知世界用五种感官:视觉、听觉、触觉、味觉、嗅觉,每一种感官接收的信息就是一种"模态"。
映射到AI领域:
文本 = 一种模态 图像 = 一种模态 音频/语音 = 一种模态 视频 = 一种模态
只能处理文本的模型叫单模态(Unimodal),能处理多种类型的叫多模态(Multimodal)。
早期的GPT-3、Llama 2都是纯文本模型,你只能打字跟它聊。现在的Claude、GPT-4o、Gemini都是多模态模型,你可以发图片、传文件、甚至语音对话。
多模态模型是怎么"看懂"图片的?
这是很多人好奇的问题。前面讲过,模型只认数字。文字通过Tokenizer变成数字,那图片呢?
核心思路是:把图片也变成一串数字序列,让它和文字Token"住进同一个空间"。
主流方案是这样的:
第一步,用视觉编码器切碎图片。 把一张图片切成很多小方块(比如14×14像素一块),每一块叫一个Patch(图块)。你可以把它理解为图片世界的"Token"。
第二步,把每个Patch编码成向量。 通过一个预训练好的视觉模型(比如ViT,即Vision Transformer),把每个小方块转成一个数字向量。这个向量包含了这个区域的视觉信息——颜色、形状、纹理等。
第三步,和文字Token一起送进大模型。 把这些图片向量和文本Token拼接在一起,送进同一个Transformer模型处理。对模型来说,图片Patch和文字Token在数学上长得一样,都是一串数字,可以统一处理。
所以当你发一张猫的照片问"这是什么",模型看到的其实是:[图片向量1, 图片向量2, ..., 图片向量196, "这", "是", "什", "么"],然后综合所有信息生成回答。
各种模态的处理方式
图像理解(Image Understanding): 模型能看懂图片内容。比如你拍一道数学题发给Claude,它能读题并解答。这是目前最成熟的多模态能力。
图像生成(Image Generation): 模型能根据文字描述画图。比如DALL·E、Midjourney、Stable Diffusion。注意,能看图和能画图是两种不同的能力,很多模型只能看不能画。
语音输入/输出(Speech): GPT-4o的语音模式是典型代表——你说话它能听懂,它也能用自然的语音回答。传统方案是"语音转文字→文本处理→文字转语音"三步走,但GPT-4o实现了端到端的语音处理,响应速度快、语气更自然。
视频理解(Video Understanding): 模型能分析视频内容。本质上视频是一系列图片帧加音频的组合,技术难点在于数据量太大——一分钟视频可能消耗几万Token,对上下文窗口是巨大的挑战。Gemini在这方面走得比较前。
文档理解(Document Understanding): 读PDF、PPT、表格等复杂排版文件。不只是读文字,还要理解布局、表格结构、图表含义。
"原生多模态"和"拼接式多模态"的区别
这是行业里一个重要的分野:
拼接式(Pipeline): 把不同模态的专用模型串起来。比如图片先过一个视觉模型提取特征,再把特征送给语言模型处理。各模块独立,中间有信息损失。早期的多模态方案大多是这种。
原生多模态(Natively Multimodal): 在预训练阶段就同时用文本、图像、音频等数据一起训练。模型从底层就理解不同模态之间的关系。GPT-4o中的"o"就是"omni(全能)"的意思,强调它是原生多模态。
原生多模态的优势在于跨模态理解更深。比如你给它看一张悲伤的画,它不只是识别"画面中有一个人",还能感受到情绪氛围并用恰当的语气回应。拼接式方案很难做到这种细腻的跨模态关联。
多模态为什么重要?
因为真实世界本身就是多模态的。
一个人类助手帮你处理工作时,需要同时看文件(图像+文本)、听你说话(音频)、看屏幕操作(视频)、写回复(文本)。如果AI只能处理文字,它的应用场景就被严重限制了。
多模态打开了大量新的应用可能:医学影像分析、工业质检、视频内容审核、实时语音翻译、AR/VR交互……这些场景都不是纯文本能解决的。
当前的局限
尽管多模态已经很强了,但还有明显短板:
幻觉问题更严重。 模型看图时比读文字更容易"看错"。比如图中有4个苹果,模型可能说是5个。视觉信息的细节准确性仍然不够可靠。
生成能力不均衡。 大多数模型在理解图像方面已经很好,但生成高质量图像、音频、视频的能力还参差不齐,且质量不如专用的生成模型。
成本高。 图像和视频消耗的Token量远大于文本。一张普通照片可能消耗上千Token,一段视频可能消耗几万Token。上下文窗口和计费压力都很大。
通俗总结
早期的AI是"只会读写的书呆子",只能处理文字。多模态让AI有了"眼睛"能看图、有了"耳朵"能听声音、有了"嘴巴"能说话。它正在从一个纯文字工具变成一个能像人类一样用多种感官理解世界的助手。虽然现在有些感官还不太灵敏,但进化速度非常快。
