 夜雨聆风
夜雨聆风爆涨411%!首个由AI自主研发的多模态智能体终身记忆系统全面开源
AI前沿 | 顶会论文解读
论文标题:OMNI-SIMPLEMEM: Autoresearch-Guided Discovery of Lifelong Multimodal Agent Memory
作者团队:Jiaqi Liu 等(北卡罗来纳大学教堂山分校、宾夕法尼亚大学、加州大学伯克利分校等)
发表会议:arXiv Preprint 2026
核心结论:首次利用全自动研究流水线(AutoResearchClaw)自主设计并优化了多模态智能体记忆框架,在LoCoMo和Mem-Gallery两大基准上全面达到SOTA,F1得分分别暴涨+411%和+214%,彻底颠覆了人工设计记忆系统的范式。
📄 论文摘要
随着大模型智能体(AI Agents)在较长时间跨度内的应用日益普及,如何长效保留、组织并准确召回包含文本、图像、音频等在内的多模态历史经验,成为了当前最大的技术瓶颈之一。构建一个高效的终身多模态记忆系统,需要探索涵盖架构设计、检索策略、提示词工程及数据流等极其庞大的设计空间。传统的人工试验或自动机器学习(AutoML)在如此复杂的系统中显得捉襟见肘。
为了解决这一难题,研究团队部署了一个名为AutoResearchClaw的自主科研流水线,让AI系统“自主研发”出了OMNI-SIMPLEMEM——一个统一的智能体终身多模态记忆框架。从一个简陋的纯文本基线出发,AI在无人干预的内循环中自主执行了约50次实验,历时72小时,完成了代码级Bug修复、架构修改和提示词重构,最终取得了令所有人惊叹的性能飞跃。
🏗️ 总架构设计
由AI自主探索出来的OMNI-SIMPLEMEM架构,打破了以往“简单向量检索”或“单纯依赖LLM管理”的局限,最终收敛并确立了三个核心架构原则:选择性摄取(Selective Ingestion)、统一表示(Unified Representation)与渐进式检索(Progressive Retrieval)。
在数据流层面,系统首先通过轻量级感知编码器评估多模态输入的新颖性,过滤掉冗余信息。随后,所有通过筛选的信号都被打包成多模态原子单元(MAUs)。这套设计巧妙地实施了“冷热分离”:精简的摘要、向量嵌入和元数据保存在内存(热存储)中以供极速检索;而沉重的原始图片、音视频文件则放置于文件系统(冷存储),仅在深层推理需要时才按需加载。
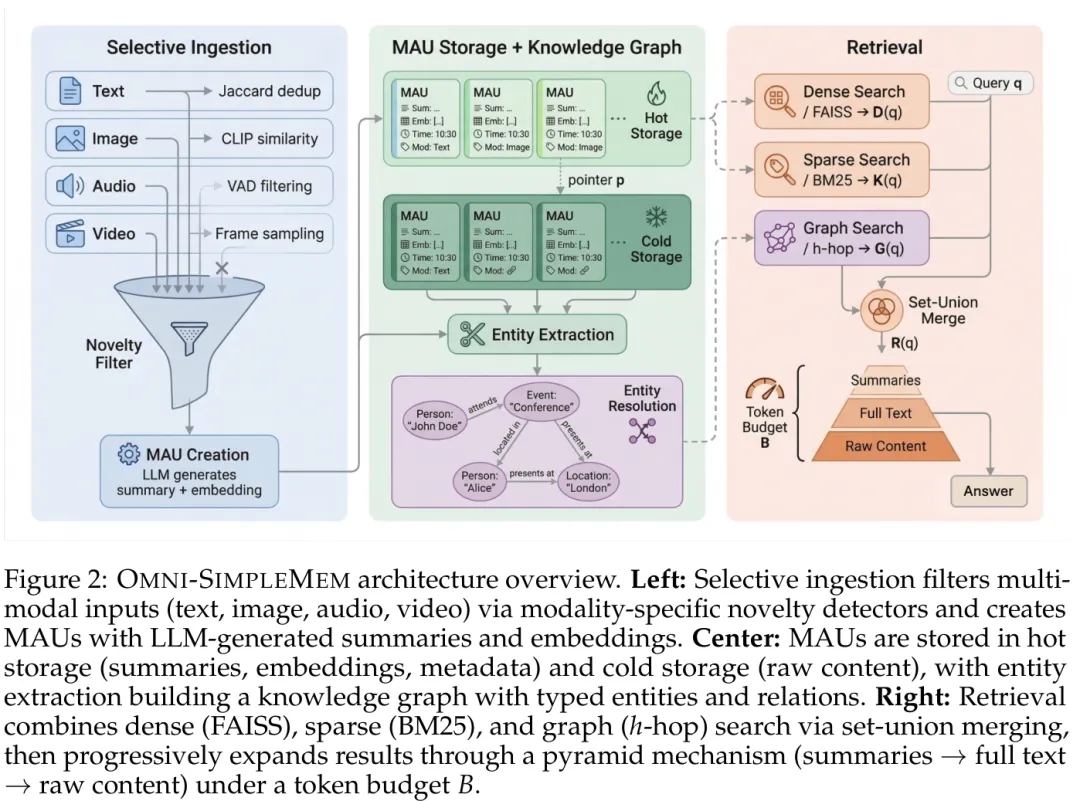
图1:OMNI-SIMPLEMEM多模态核心架构设计,包含选择性摄取、MAU存储机制与金字塔检索
💡 核心创新点
▪ 完全由AI驱动的系统级探索:这是本文最惊艳的地方。以往的AutoML只能调节超参数,而AutoResearch流水线在实验中自主发现了Bug修复(带来175%性能提升)、架构重组(提升44%)以及动态Prompt微调(单类提升188%)。这证明了在有明确量化反馈的系统中,LLM已经具备了超越人类工程师直觉的复杂系统调优能力。
▪ 多模态原子单元(MAU)与新颖性过滤:对于视觉输入,采用连续帧CLIP特征对比;对音频利用VAD静音检测。有效拦截了大量无效内容进入记忆库,从源头解决了长期记忆特有的“存储爆炸”问题,也为下游的大语言模型腾出了宝贵的上下文Token。
▪ 金字塔检索(Pyramid Retrieval)与集合并集混合搜索:AI自主推翻了人类常用的“密集+稀疏评分重排”方案,转而发现“集合并集(set-union merging)”不仅能保留语义排序,还避免了性能退化。同时首创的三层金字塔检索(摘要匹配 → 加载细粒度文本 → 按Token预算加载原始多模态冷数据)完美平衡了回答深度与成本。
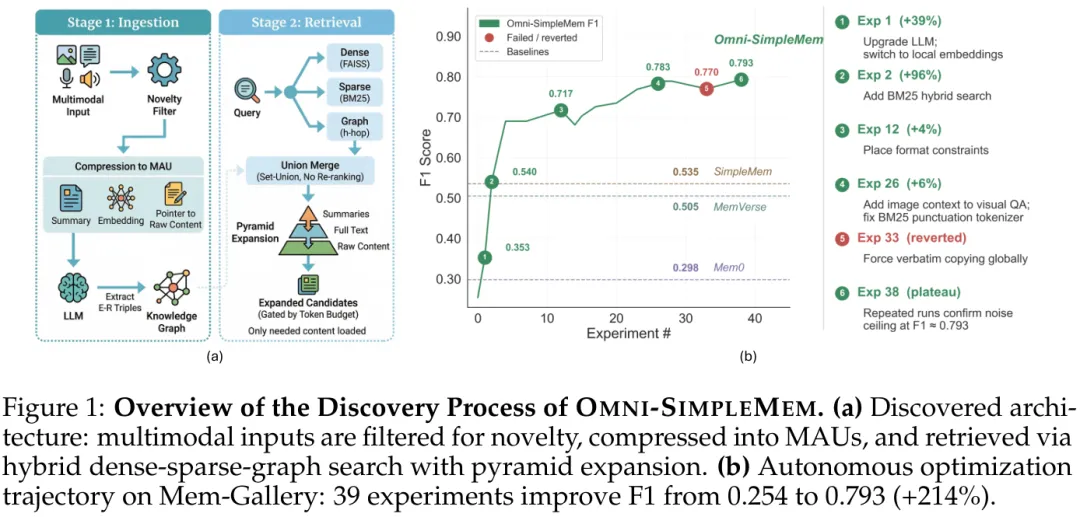
图2:自主科研(AutoResearch)发现过程概览与长效优化轨迹
🔬 关键方法与实验结果
系统不仅依赖传统的向量检索,更结合了LLM构建的动态知识图谱。在提取实体时,通过计算混合相似度(Cosine+Jaro-Winkler)自动聚合“同一实体”,以图结构的邻居节点拓展(Neighborhood expansion)作为传统向量召回的补充,一举解决了跨会话多跳推理(Multi-hop Reasoning)中的“语义断层”难题。
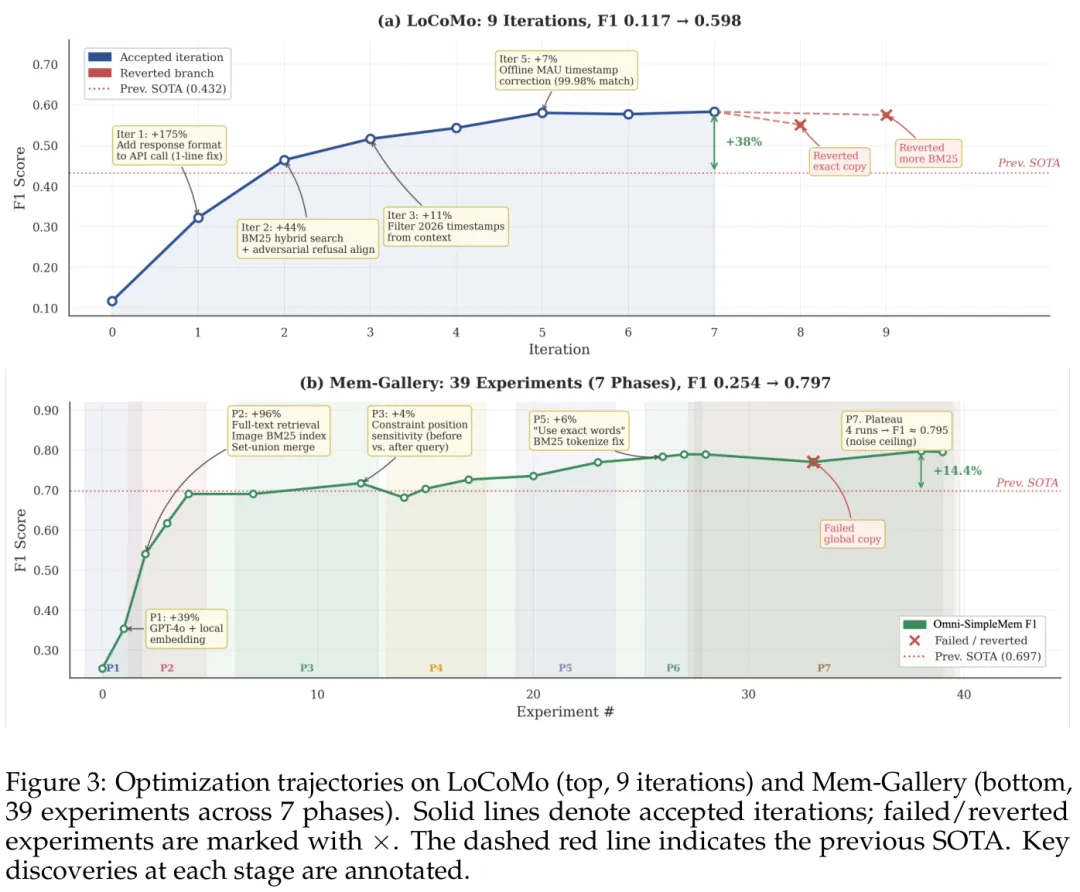
图3:在LoCoMo和Mem-Gallery基准上的多阶段优化轨迹及性能跃升
实验在衡量长时记忆的LoCoMo测试集和多模态交互的Mem-Gallery测试集上展开。对比现存的主流架构如Mem0(动态事实提取)、MemGPT(系统内存层次抽象)、SimpleMem(单模态自适应剪枝)等,OMNI-SIMPLEMEM实现了断层式的领先。消融实验(Ablation Study)清晰验证了:移除金字塔扩展机制导致F1下降17%,移除混合搜索下降14%,而这些最核心的组件正是自动化流水线分配“算力预算”重点优化的区域。
| 系统方法 | LoCoMo基准 (综合F1) |
Mem-Gallery基准 (综合F1) |
检索吞吐量 (Queries/sec) |
核心检索存储特性 |
|---|---|---|---|---|
| Mem0 | 0.397 | 0.298 | 1.46 | 动态事实图谱提取 |
| MemGPT | 0.404 | 0.435 | - | OS启发的上下文分页 |
| SimpleMem | 0.432 | 0.535 | 1.68 | 文本原子化与自适应剪枝 |
| OMNI-SIMPLEMEM | 0.598 (+411%) | 0.797 (+214%) | 5.81 (快3.5倍) | 多模态金字塔扩展+知识图谱 |
🚀 应用价值与展望
随着AI智能体逐渐接管客服、私人AI助理、全场景自动驾驶等核心业务,能够跨越漫长时间线理解海量文本、视频和语音历史数据的终身记忆机制将成为关键壁垒。OMNI-SIMPLEMEM框架凭借模块化的设计与极高的召回吞吐能力,为工业界落地高可用的多模态长程智能体打下了坚实基础。更深远的意义在于,它展示了利用Autonomous AI(自主智能)直接参与到基础AI组件“架构级迭代”的巨大潜能,标志着我们离完全“自动化科学发现和系统设计”的目标又近了一大步。
📚 论文原文:https://arxiv.org/abs/2604.01007
💻 相关资源:https://github.com/aiming-lab/SimpleMem
🎯 核心亮点:彻底改变人工调优记忆系统的方式,AI自主探索完成架构重组、代码Debug与多模态金字塔检索构建,造就霸榜级的终身记忆性能。
⭐ 觉得文章有用?欢迎分享给更多朋友! 💡 关注公众号,获取更多顶会论文深度分析 🔥 每日精选AI论文,解读最新技术进展
