 夜雨聆风
夜雨聆风然后把它接入了OpenClaw(小龙虾)。
盯着屏幕看它跑完几个自动化任务,我突然意识到一件事:
以后用AI,可能真的不用再算着Token过日子了。

这套组合到底干了什么
先说说这套环境怎么搭的。
Gemma 4有个轻量版本,Mac mini上两行命令直接拉下来。完全离线运行,不联网,不调API。
拔掉网线照样跑。
然后把OpenClaw指向这个本地模型,强制命令切过去。
当命令行跳出“agent main | ollama/gemma4:26b”那一刻,你就拥有了一个完全属于你自己的AI员工。
不交月费,不买Token,不限次数。
想让它干多少活就干多少活。
Gemma 4的精明之处
我翻了Gemma 4的技术文档,发现Google这次干了一件很聪明的事。
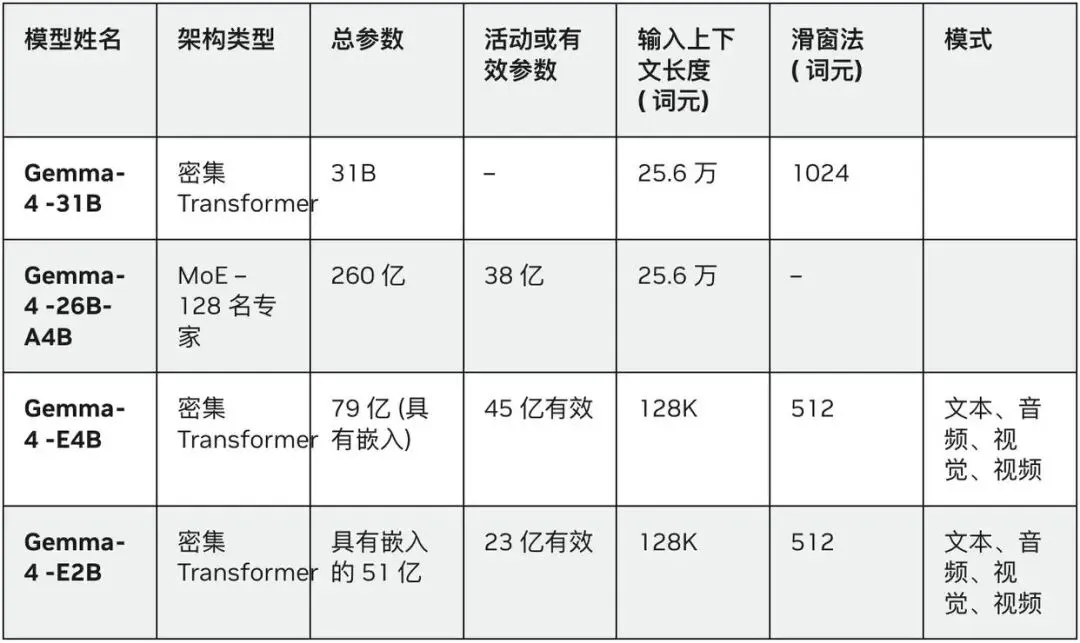
它的总参数有260亿,但每次推理只激活40亿。
什么意思?
好比你有26个领域的博士学位,但你每次干活只吃一碗面条。
用小模型的饭量,打出大模型的水平。
更狠的是,它原生支持函数调用。
这意味着它不是只会聊天的花瓶。它可以自己写代码、操作数据库、顺着网线爬数据。
它是一个真的能干活的外包工具人。
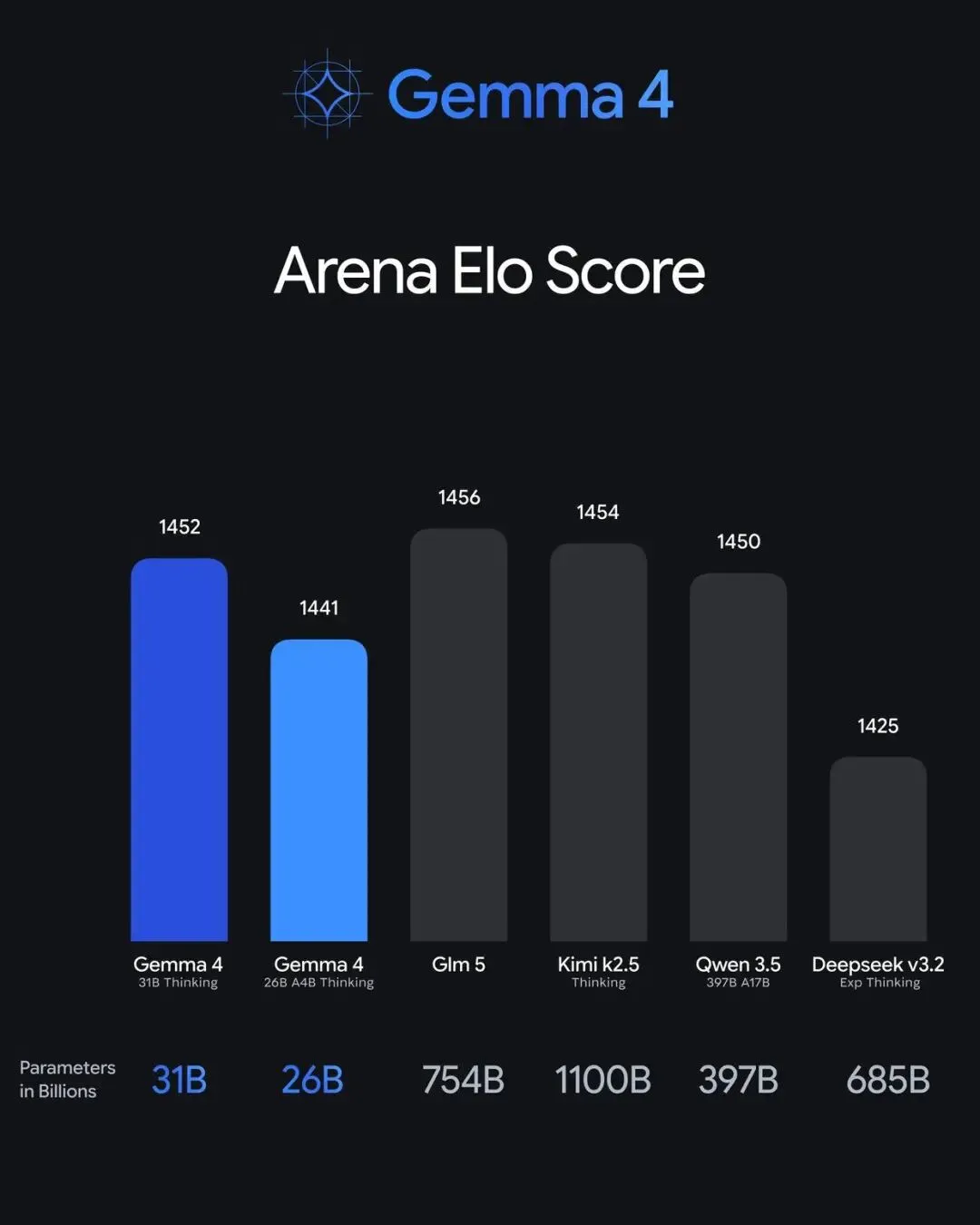
龙虾负责动手,Gemma负责动脑
光有Gemma 4,你只有一个聪明的大脑。
加上OpenClaw,你就有一套本地智能体操作系统。
龙虾负责分配任务、管理多平台接口、调用工具。
Gemma 4负责提供心智。
这两个凑在一起,你的Mac mini就变成了一个不用睡觉、不用吃饭、不跟你抱怨的24小时员工。
这里有个坑很多人踩过。
好多小白装了龙虾,以为自己用上了本地大模型。
一看后台日志,显示gateway-injected,说明你还在用龙虾内置的那个残血小模型。
正确姿势是:用Ollama拉取完整的gemma4:26b,把龙虾配置指向它,然后强制命令切换。
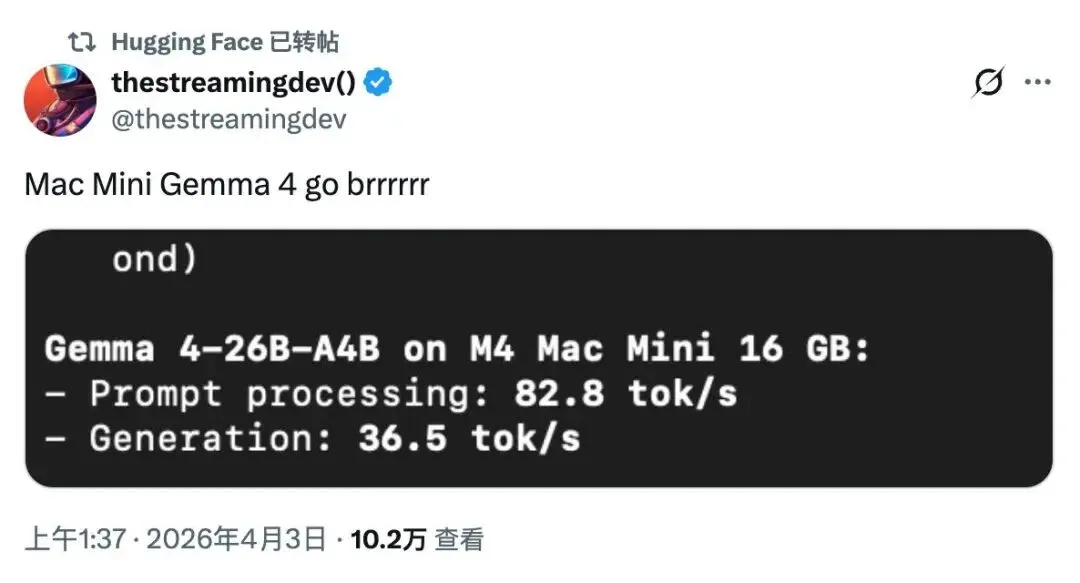
算一笔账你就懂了
以前高强度用AI,写文章、做代码审查、处理表格、执行自动化任务。
每个月买各种API Token和包月会员,几百美金轻松就没了。
现在我的工作流变成了这样:
90%的日常任务——全部交给本地的Gemma 4加龙虾。纯离线,数据绝对隐私,不花一分钱。
10%的超复杂逻辑推理——这种高难度动作,我才会花钱去调用云端的顶级模型。
最直接的改变是什么?
使用AI的成本,从“按Token计费”变成了“按电费计费”。
你的电脑开着机就行。让龙虾去抓几万页数据做清洗,它慢慢跑,唯一的成本就是电费。
没有任何调用焦虑。不用担心API限流。不用心疼Token消耗。
大厂要开始肉疼了
当硬件一次性买断,当智力变成了可以免费下载的压缩包。
那些靠倒卖基础模型Token来维持估值的云大厂,真的要开始肉疼了。
以前卖铲子的人赚疯了。
以后卖电的人可能才是最后的赢家。
@ 作者 / 青畅
最后,感谢你看到这里👏如果喜欢这篇文章,不妨顺手给我们点赞|在看|转发|评论 📣
如果想要第一时间收到推送,不妨给我个星标🌟
如果你有更有趣的玩法,欢迎在评论区聊聊🤝
更多的内容正在不断填坑中……
