最近一直在做一件事:基于真实业务场景,从数仓建设到 AI 应用上线,把 Data+AI 整条链路上线。做之前以为最难的是 AI 那层——模型选哪个、prompt 怎么写、Agent 怎么编排。现在讲模型的多,讲数仓的多,讲检索的也不少——但把这三层怎么串起来、数据怎么从原始库一步步流转到最终被 AI 消费,成体系讲完的几乎没有,这也是之前有小伙伴提到过的。今天这篇,把这条链路的关键点拎出来,给你一个全景。数据源(多业务库) ↓篇一 · 数仓建设 —— AI 数据底座 ↓篇二 · 数据流转 —— Flink CDC 实时 + 离线双轨 ↓篇三 · 搜索检索 —— 7 个版本迭代,召回率 50% → 92% ↓篇四 · AI 应用 —— Data Agent + 安全沙箱 + LLM 工程化
篇一 数仓建设到 AI 数据底座
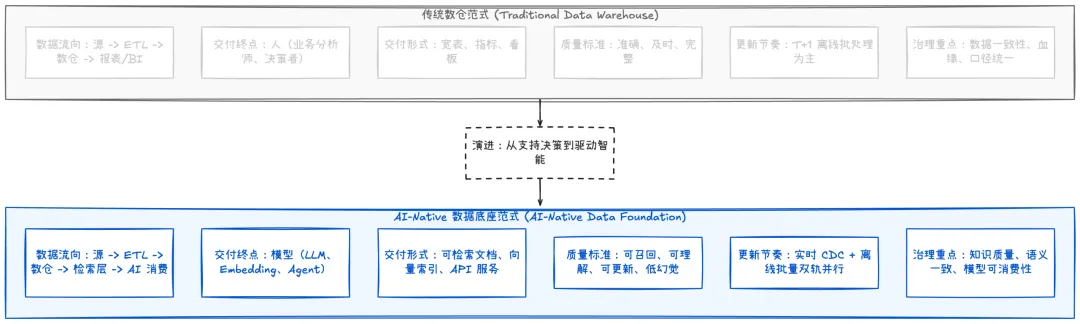
传统数仓的终点是 ADS 层出报表,到这就结束了。但在 Data+AI 场景下,数仓是起点,不是终点。数据从 ADS 出来之后还要经过:搜索引擎索引 → RAG 上下文构建 → Workflow 编排 → Agent 消费。三个范式转变
1. 交付对象从「人」到「模型」
传统数仓产出的是给人看的报表和大盘。AI 底座还需要产出模型可消费的知识单元——搜索字段、Embedding 向量、结构化 API。2.数仓从终点变起点
ODS → DWD → DWM → DWS → ADS → 搜索引擎 → RAG → Agent ↑ 传统数仓在这里就停了
3. 质量标准从「准确完整」到「可召回、低幻觉」
数据不只要对,还要能被 AI 找到、理解、正确引用。如果搜索字段拼得不好,检索层给出的上下文就是噪声,LLM 的回答就是幻觉。
具体怎么做?举两个例子
1.ADS层产出搜索字段
传统数仓不会专门为搜索拼字段。但我们在数仓对数据进行加工,供搜索引擎使用。这个设计有多关键?——搜索召回率从 v3 的 65% 到 v4 的 72%,没换算法,只是重构了搜索的拼接方式,一次跳了 7 个点。数据质量直接决定了 AI 上层的效果。2. 102 列 → 14 列:面向模型消费的瘦身
v1 核心事实表 102 列,字段语义混乱,下游没法用。v2 重新梳理实体关系,将混乱的来源字段拆成三个独立维度,表瘦身到 14 列。不是砍字段,是让数据对模型来说更"可理解"。
篇二 数据流转:实时 + 离线双轨
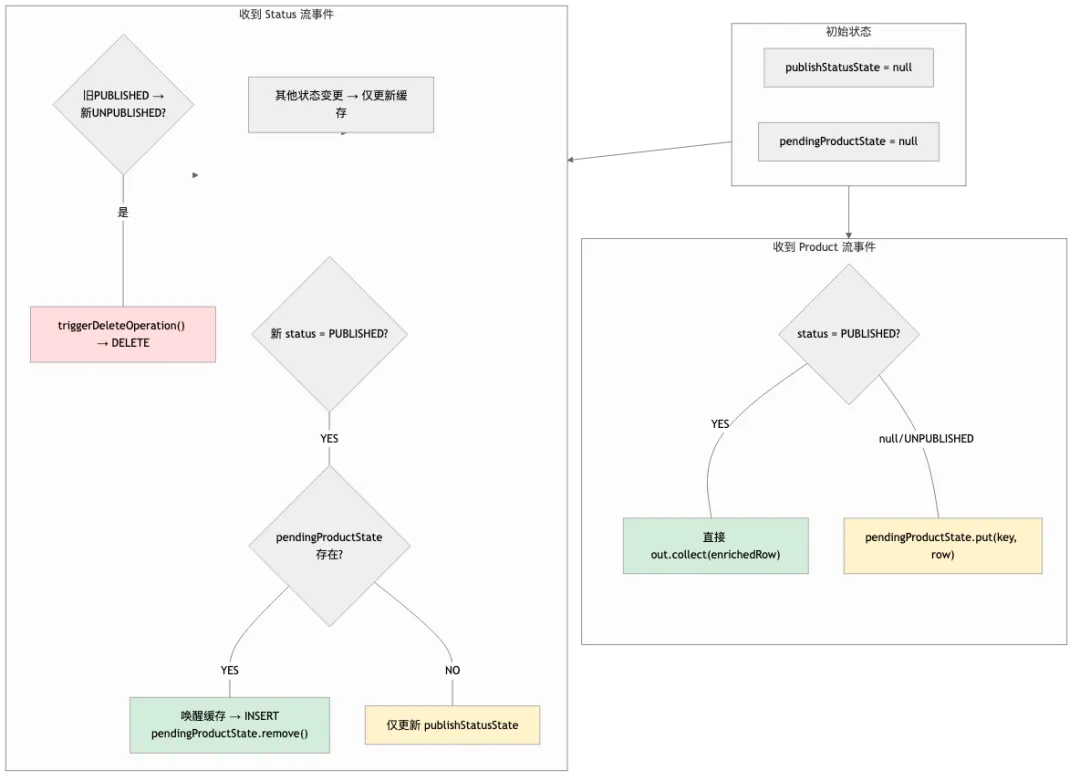
数仓建好了,数据怎么流到下游搜索引擎和 AI 系统?Flink CDC 毫秒级同步,P99 < 500ms直连 PostgreSQL WAL,变更从捕获到写入下游延迟在 500ms 以内。但 CDC 真正的难度不在"接上",在生产环境的边界情况:发布状态门控:业务上只有"已发布"的数据才应该进入搜索。我们用 Flink ConnectedStreams + MapState 实现状态关联——数据先缓存,等发布状态到达后才放行写入。Sink 端数据补全:状态触发的写入,在 Sink 端回查数据库补全完整文档。这样 Process 流和 Status 流就不需要严格时序对齐——解耦了两条流的时序依赖。
离线全量同步
百万级文档全量同步约 3 小时,采用分批并发 + Bulk 写入。实时和离线双轨并行,互为兜底。
篇三 数据检索:7 个版本,召回从 50% 到 92%
这一篇迭代次数最多,搜索索引从 v1 做到了 v7。演进路线
版本 | 核心改动 | 召回率 |
|---|
v1 | 纯 BM25 | <50% |
v2 | 字段加权 + 过滤条件 | 58% |
v3 | 分词器优化 | 65% |
v4 | 数据质量重构 | 72% |
v5 | 向量检索 | 78% |
v6 | BM25 + 向量混合 + 去重 | 86% |
v7 | 权重优化 + 分层策略 | 92% |
关键发现:v1→v3 换算法,每次提升几个点。v4 没换算法,只重构了搜索字段的数据拼接方式,一次跳了 7 个点。
Embedding 领域微调
训练数据:9,500+ 查询,95,000+ 语料,每个 query 10 个负例(随机 + hard negatives)。8 种搜索策略体系(S1-S8)
不是一套参数吃遍所有场景。按业务场景分了 8 种策略,各有独立的阈值、字段权重和匹配逻辑。高难度场景走Hard-case Pipeline:LLM 改写多查询 → 每查询独立 BM25 → 向量重排 → 按唯一标识 max-pooling 聚合。配合 Latin Hypercube 采样 200 + 100 组的离线权重网格搜索,参数优化全自动。
篇四 AI 应用:从检索到智能
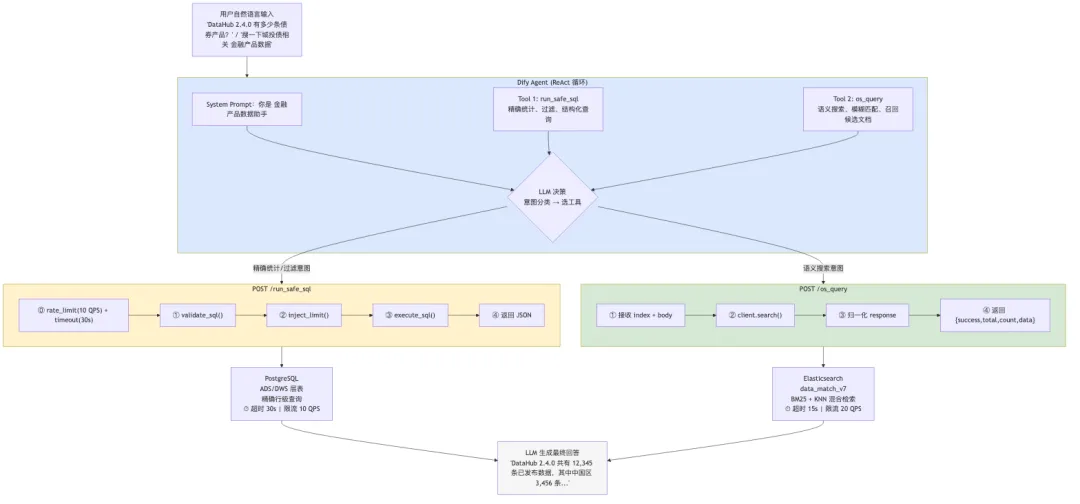
有了前三层数据底座和检索能力,AI 应用才有地基可用。双数据源 Data Agent
同一个 Agent 同时对接 SQL 查询和搜索引擎——Agent 按意图自动路由。五层 SQL 安全沙箱
AI 生成的 SQL 要跑在生产库上,安全不是可选项:层级 | 防御 |
|---|
第 1 层 | SELECT-only 白名单 |
第 2 层 | 11 个危险关键字的词边界正则检测 |
第 3 层 | 去引号后分号检测(防 SQL 注入) |
第 4 层 | 注释注入拦截(-- 和 /*) |
第 5 层 | 自动 LIMIT 注入(默认 200,最大 1000) |
同时做了Prompt 注入防御的三类攻击分析:语法层直接注入、语义层绕过约束、间接注入(检索文档里埋恶意指令)。每类都有对应的防御策略。
LLM 工程化
AI 应用上线只是开始。要在生产环境持续跑,需要:Prompt 版本管理:每次修改可回溯、可对比
模型可替换:今天用 A 模型,明天换 B,接口不变
输出校验:LLM 返回不符合预期时的降级策略
成本追踪:token 用了多少、每个请求花了多少
行为可观测:调用链路全程可追踪
做到这一步,AI 才从"功能插件"变成业务工程能力。
写在最后
以上只是每篇挑了几个点,完整还涵盖技术选型决策、生产踩坑速查表、环境搭建指南。当前 v1.0,持续更新。
如果你大数据/AI 感兴趣,欢迎关注「小友Data+AI」,持续分享数据 × AI 的工程实践
 夜雨聆风
夜雨聆风