 夜雨聆风
夜雨聆风引言
在 OFC 2026 的舞台上,以 Ethernet Alliance 为首的专家小组传递了一个明确的讯号:AI 算力需求的增长已进入「疯狂」阶段,迫使乙太网络技术以超越以往的速度进行演进。随着单通道速率正式迈向 400G per lane,产业链正面临物理极限、功耗挑战与供应链瓶颈的三重考验。本场会议不仅定义了 1.6T 与 3.2T 乙太网络的基础架构,更揭示了超大型资料中心(Hyperscalers)如何透过 Scale-up、Scale-out、Scale-across 三大维度,重新定义 AI Fabric 的物理层规范。
Meta 的观点:物理极限与类比设计的两难
Meta 作为终端用户,强调了资料中心基础设施已达临界点。来自 Meta 的 Halil Cirit 提出了几个正在重塑产业如何看待下一代网络的基本限制。
物理空间与功耗限制已成为主要瓶颈。机架(Rack)的重量、冷却能力与电力传输已达上限,无法再单纯透过增加尺寸来扩容。这个限制迫使产业必须重新思考如何在不更换整个机架系统的前提下,将运算与存储器频宽翻倍,因此 400G per lane 不仅是理想选择,更是唯一的可行方案。
类比设计的困境呈现另一个显著挑战。虽然运算芯片追求 3nm/2nm 的先进制程节点,但 SerDes 类比设计者面对的现实却不同。先进制程节点带来的噪声问题让类比设计者宁愿避开,倾向选择落后几代的制程节点。数位与类比半导体技术发展路线图之间的分歧,创造了复杂的整合挑战,这些挑战必须在 400G 电气界面成功之前解决。
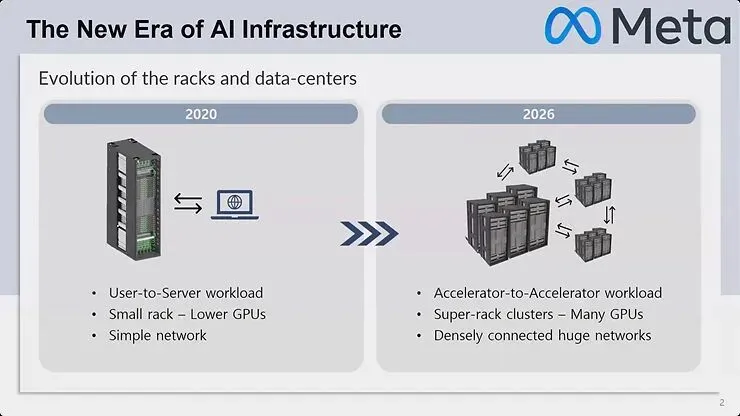
图1:资料中心架构从 2020 年的使用者对服务器工作负载模式,演进到 2026 年的加速器对加速器范式,具备超级机架丛集与高密度连接网络
Meta 强烈主张开放标准与早期释出规格。该公司认为早期释出规格可让供应商有足够时间准备,对抗封闭专有系统带来的风险。这个做法反映了 Meta 更广泛的理念:培养多元化、竞争性的供应链,而非依赖单一来源解决方案。
Cisco 的三层级网络架构与铜缆的最后防线
来自 Cisco 的 Mark Nowell 提出了针对 AI 基础设施的视觉化模型,将网络划分为三种不同场景,每种场景都有不同的技术需求与架构方法。
Scale-up 网络处理机架内的 GPU 对 GPU 通讯。这代表极短距离、高密度与超低延迟需求。目前铜缆在这个领域仍是主导,但 400G 甚至对铜缆互连都呈现巨大挑战。产业面临的问题是:随着资料速率再次翻倍,铜缆能否维持主导地位,还是主动式电缆与光学解决方案将开始取代传统被动式铜缆,即使在这些短距离应用中也是如此。
Scale-out 网络促进机架间通讯。这一层目前由光学元件主导,预期将从可插拔光学元件转向 CPO 架构。CPO 转型代表资料中心网络中最显著的技术转变之一,透过将光学引擎直接整合到交换器封装上,而非依赖前面板可插拔模块,有望大幅降低功耗与延迟。
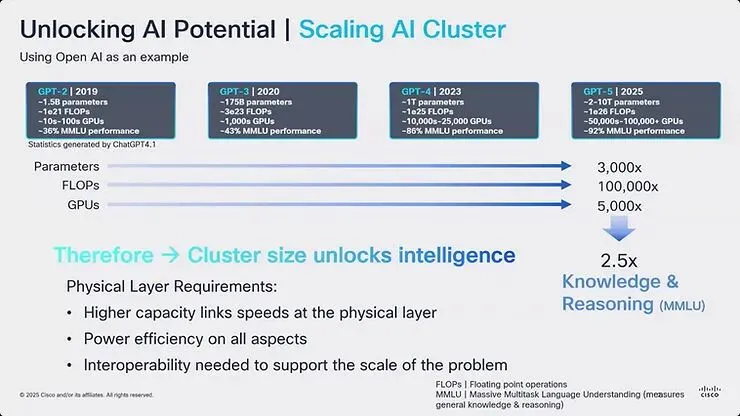
图2:Cisco 展示 AI 丛集扩展需求,显示从 GPT-2(2019)到 GPT-5(2025)参数、FLOP 与 GPU 数量的指数增长,说明需要更高容量连结与改善的能源效率
Scale-across 网络将 AI 丛集延伸到单一资料中心之外,实现跨建筑通讯,距离可达 3 公里。这一层将引入相干光(Coherent)技术,并需要具备深缓冲(Deep Buffers)的交换器来管理长距离连接固有的增加延迟。随着 AI 训练丛集的规模超越单一设施所能容纳的范围,scale-across 网络对于维持集体训练操作所需的统一通讯 Fabric 变得不可或缺。
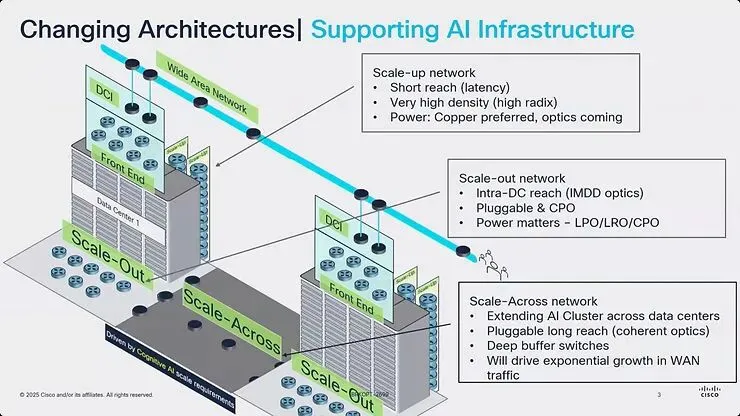
图3:Cisco 对三层级 AI 网络架构的完整视觉化,说明 scale-up(机架内)、scale-out(机架间)与 scale-across(跨资料中心)网络层及其各自的技术需求
Cisco 的分析:AI 架构与距离延迟容忍度
Cisco 的简报更深入探讨了 AI 工作负载如何对网络架构施加独特的需求。AI 工作负载是同步的,这意味着工作完成时间(JCT)由尾端延迟(Tail Latency)与壅塞控制共同驱动。这创造了与传统企业或云端网络根本不同的优化目标。
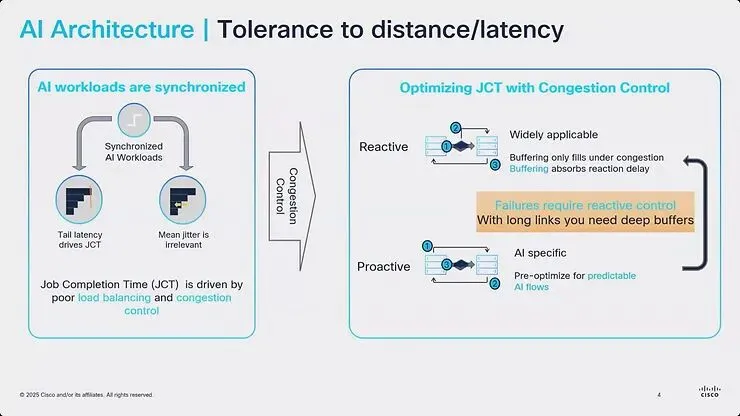
图4:说明 AI 工作负载的同步性质如何驱动网络设计,包含反应式与主动式壅塞控制方法及其对缓冲需求的影响
AI 的物理层转型显示出清晰的演进路径。当前与未来的转型涉及铜缆、前面板可插拔光学元件,以及 CPO/NPO(Near-Package Optics)技术。铜缆目前主导机架内连接,但逐渐向光学元件转移。机架间连接正从可插拔模块转向 CPO 架构。值得注意的是,市场需要铜缆与光学物理媒体相依(PMD)元件都能在 400G 运作,因为不同的部署情境将偏好不同的解决方案。

图5:时间轴显示跨 scale-up 与 scale-out 场景的物理层技术演进,说明从铜缆到 CPO 的渐进转型,以及市场对 400G 电气与光学 PMD 的需求
光学解决方案:延伸超越铜缆的触及范围
400G per lane 光学与光纤的讨论揭示了几个关键的技术考量。光学元件提供超越铜缆的触及范围,将 scale-up 能力延伸到单一机架之外。单波长光学元件与平行单模光纤线缆为高基数(High-Radix)scale-up 与部分 scale-out 网络提供最佳支援。

图6:400G 光学解决方案的技术细节,显示 226 GBaud 与 174.8 GBaud PAM-4 调变方案及相关的眼图与效能特性
每条光纤的高频宽实现了高密度连接性,而单波长操作的低色散允许有效的雷射功率共享以降低整体功耗。PAM4 与 PAM6 调变方案都在考虑中,各自提供不同的优势与劣势。产业正在将这些技术方法与现有的部署模式对齐,包括分线(Breakout)配置、可插拔模块,以及 CPO/NPO 架构。
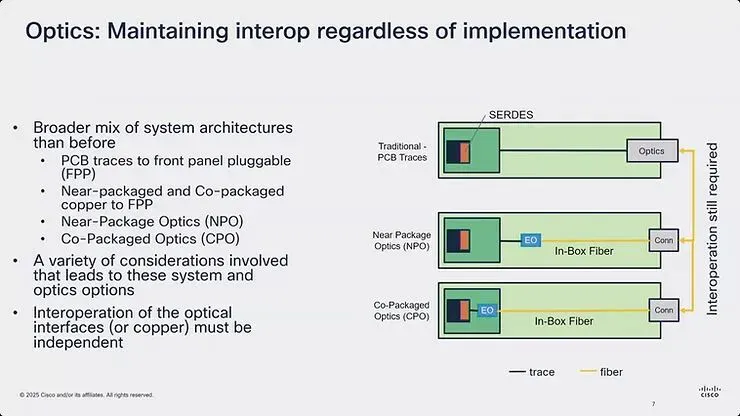
图7:说明无论采用何种实作方式,都必须维持光学互通性,涵盖传统 PCB 走线、近封装铜缆、NPO 与 CPO 实作
无论采用何种实作方法,维持互通性已成为产业的关键需求。生态系统现在包含比以往更广泛的系统架构组合,从 PCB 走线到前面板可插拔模块,到近封装与 CPO 的铜缆与光学解决方案。多种考量决定了不同系统采用哪种方法,导致多元化的光学实作。关键需求是光学界面的互通性,无论使用铜缆或光纤作为媒介,都必须与所选择的封装方法保持独立。
Synopsys 与 IEEE 400G Study Group 的工具箱
来自 Synopsys 的 Kent Lusted 宣布 IEEE 已于上周正式批准成立 400 Gb/s per lane 研究小组(Study Group),重点锁定在电气互连与 500 米单模光纤应用。
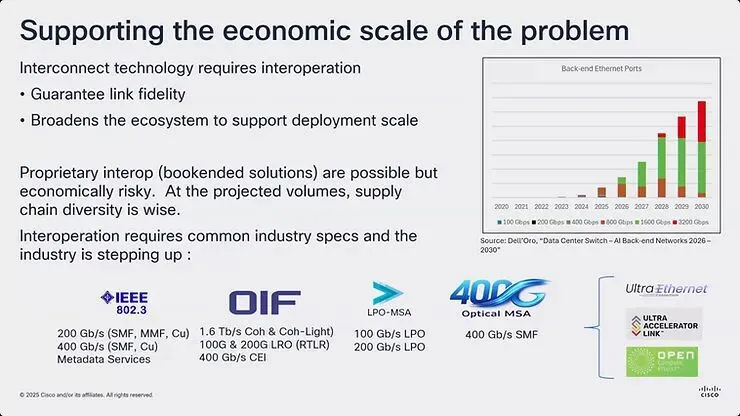
图8:说明支援 400G 发展的产业生态系统,包括 IEEE、OIF、Ultra Ethernet Consortium 与各种 MSA,以及 IEEE 802.3 400 Gbps/lane Study Group 正式成立的公告
Study Group 将探索多种技术路径,包括 PAM4 与 PAM6 调变的选择、先进数位讯号处理技术,以及更低损耗的封装材料。前向纠错(FEC)的多样化代表另一个关键的研究领域。为了平衡延迟与效能,IEEE 考虑提供「菜单式」的 FEC 方案,包含端到端(End-to-End)、级联(Concatenated)与分段(Segmented)FEC 架构。这种灵活性允许不同的部署情境针对特定的延迟、编码增益与复杂度需求进行优化。

图9:IEEE 802.3 400 Gbps/lane Study Group 的详细范围,于 2026 年 3 月 13 日批准,涵盖电气互连与达 500 米的单模光纤光学互连
架构灵活性也在考虑中,支援包含线性(LPO)、半重定时(Half-retimed)与全重定时(Retimed)等多元架构。这种多样性承认不同的系统情境将根据特定的功耗、延迟与效能需求偏好不同的方法。
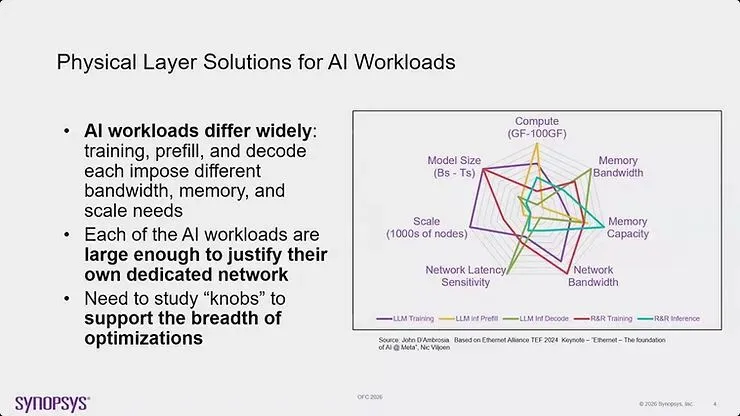
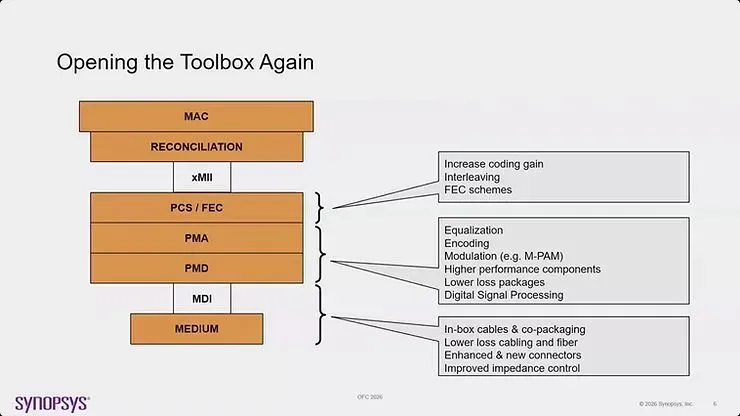
图10:不同的 AI 工作负载(训练、预填充、译码)对频宽、存储器、规模与网络延迟施加不同的需求,需要一个全面的技术解决方案「工具箱」,包括 MAC、reconciliation、PCS/FEC、PMA、PMD、MDI 与媒介层的创新
AI 工作负载的物理层解决方案必须考虑到 AI 工作负载在训练、预填充与译码操作之间差异很大。每种操作都施加不同的频宽、存储器与规模需求。每种 AI 工作负载类型都足够大,足以证明需要专属的网络优化。理解这些不同的需求对于支援整个 AI 基础设施景观所需的广泛优化至关重要。
SerDes 能力作为关键推动因素
SerDes 能力历来一直是乙太网络演进的关键推动因素。产业已建立了大约每 4 年翻倍资料速率的模式,每一代都增加新的能力来应对速率增加所带来的挑战。
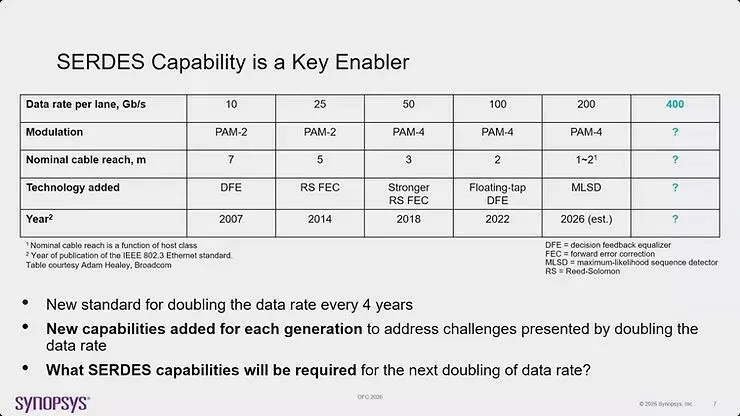
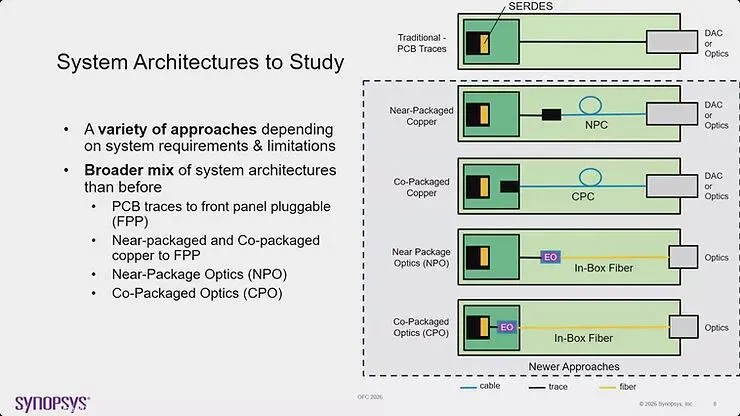
图11:SerDes 能力从 10G 到 400G 的历史发展,显示调变方案、线缆触及范围与每一代新增技术的演进,以及正在研究的多元系统架构,包括 FPP、NPO、CPO 与较新的方法
显示 SerDes 演进的表格揭示,10G 使用 PAM-2 调变,标称线缆触及范围为 7 米,并新增了 DFE(决策反馈等化)。2014 年的 25G 世代维持 PAM-2,但将触及范围降至 5 米,并新增了 RS FEC。在 2018 年的 50G,产业转向 PAM-4,触及范围为 3 米,纳入了更强的 RS FEC 与浮动抽头 DFE。2022 年的 100G 世代维持 PAM-4,触及范围为 2 米,同时新增了 MLSD(最大似然序列检测)。预估 2026 年的 200G 世代将以 PAM-4 调变达到仅 1-2 米的触及范围。产业面临的问题是,下一次翻倍到 400G per lane 将需要哪些 SerDes 能力。
正在研究的系统架构包括多种方法,取决于系统需求与限制。除了传统的 PCB 走线到前面板可插拔模块,产业正在检视近封装铜缆到 FPP、Near-Package Optics(NPO)、CPO 与其他新兴方法。这种架构多样性反映了不同的部署情境将根据特定的限制进行不同的优化。
FEC 方案多样性与权衡取舍
400G per lane 应用有多种 FEC 方案可用,每种方案在延迟、编码增益与实作复杂度方面都有不同的权衡,需要详细研究。

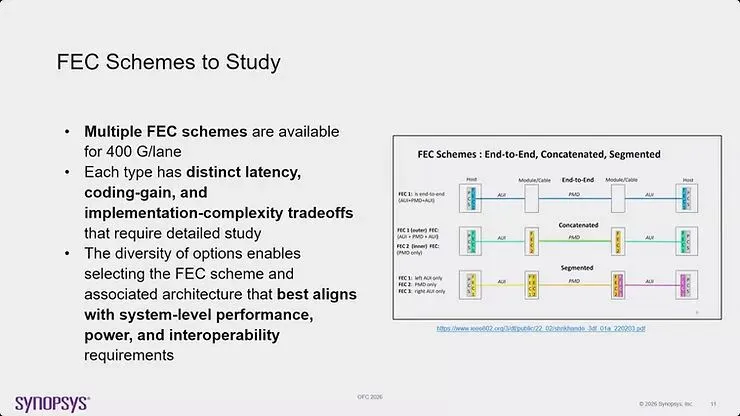
图12:比较 400G 应用的三种 FEC 方案方法(端到端、级联与分段),每种方案在延迟、编码增益与实作复杂度方面提供不同的权衡
FEC 选项的多样性使得能够选择最符合系统层级效能、功耗与互通性需求的方案与相关架构。端到端 FEC 提供最简单的架构,但可能无法为最具挑战性的通道提供足够的编码增益。级联 FEC 结合多个 FEC 阶段以实现更高的编码增益,但代价是增加的延迟与复杂度。分段 FEC 对连结的不同部分应用不同的 FEC 方案,可能独立优化每个区段。
Dell'Oro Group:供应驱动的标准化
来自 Dell'Oro Group 的 Sameh Boujelbene 的市场分析揭示,当前的 AI 网络市场由「供应」而非「需求」决定。这种供应驱动的动态对标准化工作产生了深远的影响。

图13:概述 IEEE 802.3 400GPL Study Group 的范围,包括 SerDes 增强、多种系统架构(FPP、NPO、CPO)、铜缆与光学互连选择,以及正在探索的各种 FEC 方案
供应商多样化(Vendor Diversity)已成为超大型客户的策略要务,他们寻求在多个交换器芯片供应商之间分散台积电产能风险。这直接提升了互通性与标准化的重要性。如果客户必须向多个供应商采购以确保供应连续性,这些供应商的产品必须无缝协作,使开放标准成为必要而非可选项目。
演进时程预测显示,3.2T 界面将于 2029-2030 年左右出现,而 6.4T 界面则可能在 2034 年左右问世。这些时间表反映了技术开发周期以及标准化流程完成与生态系统围绕新界面速度成熟所需的时间。
产业共识与分歧点
所有讲者都同意,为了应对 AI 的爆炸性增长,标准化流程必须「前置」。过去,标准是在技术成熟后才制定。现在的方法是提早锁定关键参数,如调变方案与 FEC 框架,使 IP 供应商、模块制造商与线缆供应商的生态系统能够平行而非序列式地发展。
铜缆在 400G 的地位仍是分歧点。虽然 Cisco 认为铜缆在机架内仍保有优势,但 Meta 与其他专家指出,随着速率翻倍,铜缆的传输触及范围正在萎缩。这将迫使产业在 400G 时代比前几代更早转向光学解决方案或主动式电缆(ACC/AEC)。
PAM4 与 PAM6 调变的选择也仍在辩论中。虽然目前的重心仍在 PAM4,但 PAM6 仍作为达成功耗目标的选项留在桌上。PAM6 提供了在相同资料速率下使用较低鲍率(Baud Rate)的潜力,可能缓解一些 SerDes 设计挑战,但代价是降低的讯噪比边际与增加的实作复杂度。
硅基光电子与产业的策略意涵
OFC 2026 的讨论清楚表明,400G per lane 不仅仅是资料速率的翻倍,而是乙太网络生态系统方法与 NVIDIA InfiniBand 等专有架构之间的正面对决。
硅基光电子与 CPO 的转折点正在到来。随着 400G 电气路径损耗挑战增加,CPO 与 NPO 从实验室好奇心转变为解决 1.6T/3.2T 功耗问题的必要解决方案。这对台积电的 COUPE 封装技术以及旭创与 Marvell 等模块制造商的硅光子部署具有重大财务影响。
IP 供应商将显著受益。像 Synopsys 这样的公司将从 SerDes 设计复杂度的增加中获益。随着物理层难度呈指数级增长,自主芯片开发的门槛上升,推动更多公司依赖来自既有供应商的成熟 400G IP。
LPO 与 LRO 架构找到策略窗口。为了降低功耗,不带重定时器(Retimer)的线性驱动解决方案在 400G 世代获得更大的生存空间。这对光学元件施加了更高的线性度要求,有利于具备领先讯号处理能力的制造商。
从 OFC 2026 的讨论来看,向 400G per lane 的转型代表资料中心网络的全面转型,由 AI 对频宽的巨大需求驱动,以及产业决心透过开放、标准化的解决方案而非专有替代方案来满足该需求。技术挑战包含类比设计、调变方案、前向纠错、封装技术与光学整合等多个面向。然而产业共识仍然明确:必须应对这些挑战,必须建立标准,以实现未来十年所需的 AI 基础设施建设。
参考来源
[1] H. Cirit, M. Nowell, K. Lusted, and S. Boujelbene, "Ethernet's Accelerating Evolution for AI: 400G per Lane and the Road to 6.4T," presented at the 2026 Optical Fiber Communication Conference (OFC), Los Angeles, CA, USA, Mar. 15-19, 2026.
END
点击左下角"阅读原文"马上申请
欢迎转载
转载请注明出处,请勿修改内容和删除作者信息!
关注我们
 |  |  |
关于我们:
深圳逍遥科技有限公司(Latitude Design Automation Inc.)是一家专注于半导体芯片设计自动化(EDA)的高科技软件公司。我们自主开发特色工艺芯片设计和仿真软件,提供成熟的设计解决方案如PIC Studio、MEMS Studio和Meta Studio,分别针对光电芯片、微机电系统、超透镜的设计与仿真。我们提供特色工艺的半导体芯片集成电路版图、IP和PDK工程服务,广泛服务于光通讯、光计算、光量子通信和微纳光子器件领域的头部客户。逍遥科技与国内外晶圆代工厂及硅光/MEMS中试线合作,推动特色工艺半导体产业链发展,致力于为客户提供前沿技术与服务。
http://www.latitudeda.com/
(点击上方名片关注我们,发现更多精彩内容)
