 夜雨聆风
夜雨聆风这两年,关于企业级 AI 的讨论很多,但真正有用的信息并不多。
一边是各种大会、采访和市场报告都在说企业已经全面拥抱 AI;另一边,又不断有研究在说大部分生成式 AI 试点根本转不了正式项目。
a16z 最近发了一篇《AI Adoption by the Numbers》,用真实数据回答了一个具体的问题:
今天的大公司,真正愿意签合同、做试点、正式上线的 AI,到底集中在哪些地方、哪些行业。
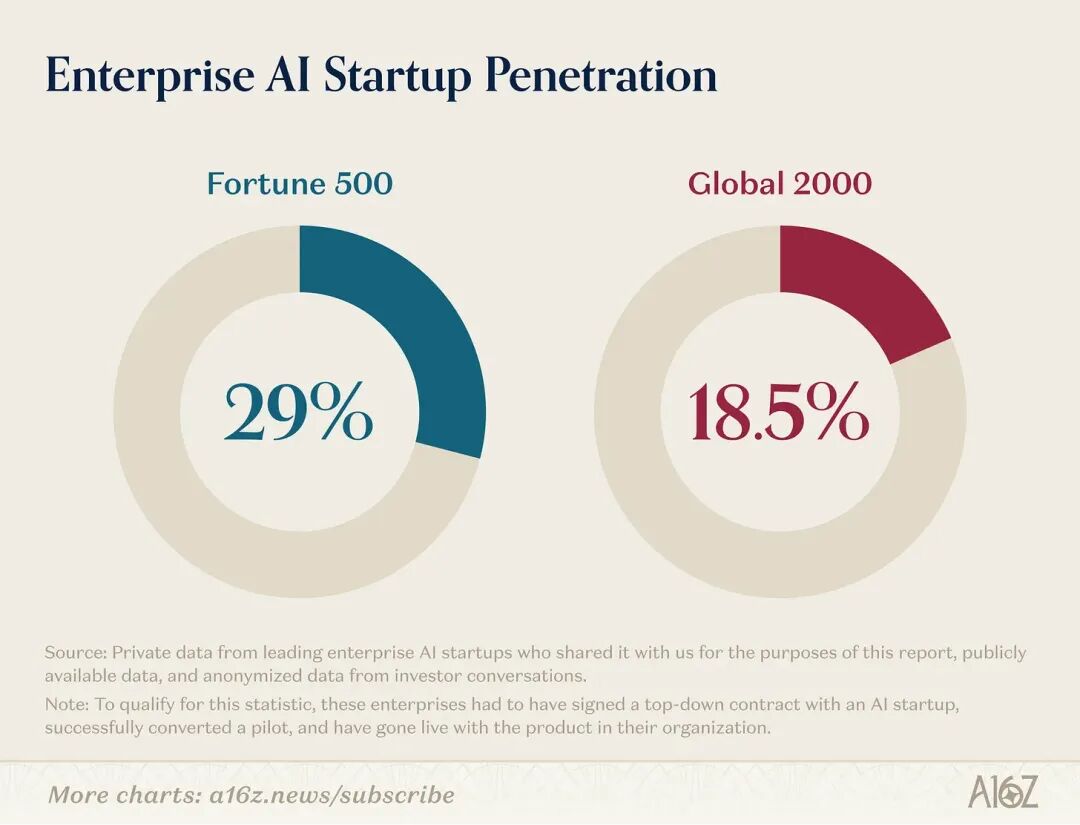
先看个整体数据:按 a16z 的测算,29% 的《财富》500 强、约 19% 的 Global 2000,已经是某家头部 AI 创业公司的正式付费客户。
这个比例放在企业软件史里,其实是很快的。
ChatGPT 是 2022 年 11 月发布的,到现在也就三年多一点,企业 AI 的渗透速度已经明显快过前几代软件浪潮。

先跑出来:写代码、客服和搜索
先看写代码。
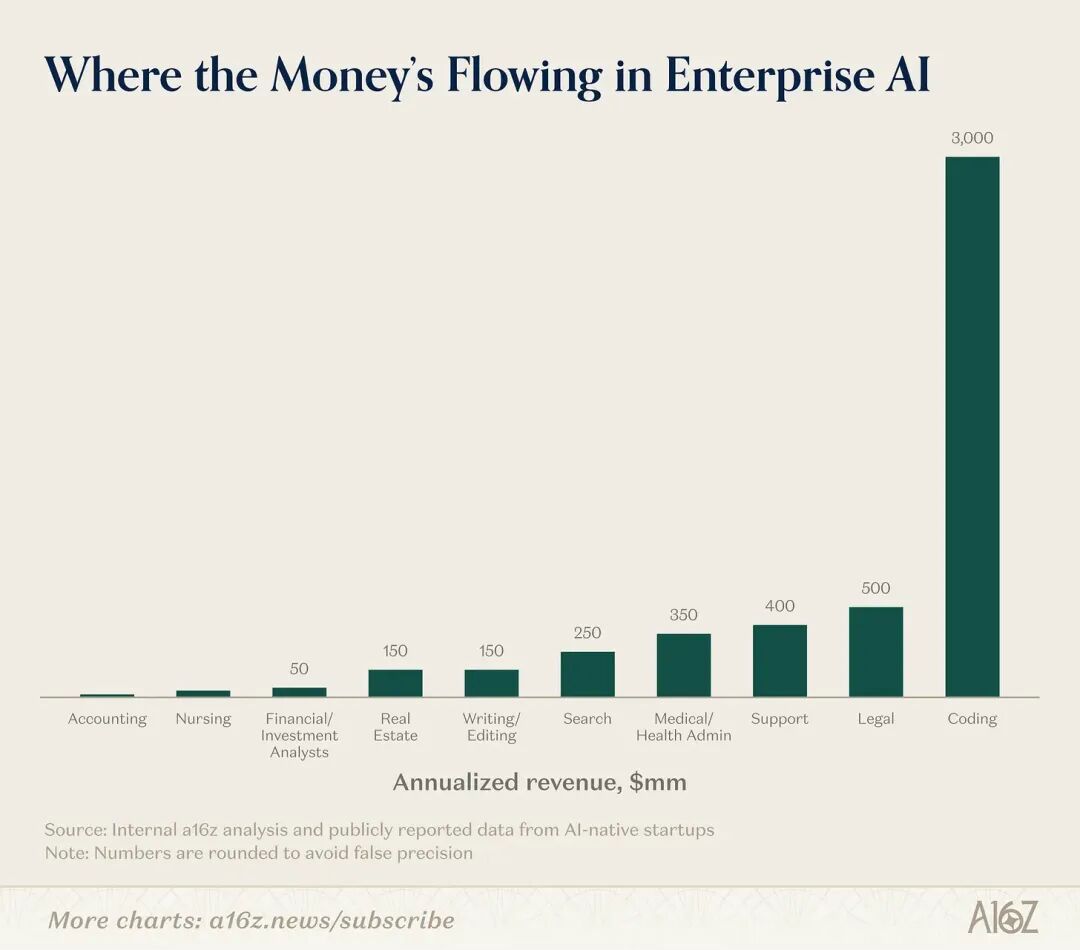
文章里写得很直接:写代码是企业人工智能里最强势的应用场景,几乎比其他方向高出一个量级。
它举了几个已经非常典型的案例,比如 Cursor 的爆发式增长,以及 Claude Code、Codex 这样的工具也都在高速增长,而且这种增速已经超过了很多人之前最乐观的预期。
在《财富》500 强和全球 2000 强这些大公司里,目前绝大多数真正上线的人工智能工具,首先就是落在代码环节。
为什么偏偏是代码先跑出来呢?
第一,代码天然适合模型。
它是高密度数据,有大量高质量公开样本;
它又是文本,模型处理起来比图片、视频和线下流程都更直接;
更重要的是,代码的语法严格、结果明确,能不能运行、有没有报错,很快就知道。
这对模型来说意味着反馈闭环很强,对企业来说则意味着更容易判断值不值得买。
第二,代码这件事非常容易算账。
这篇文章里提到:最优秀的工程师,在接入人工智能编程工具之后,生产效率有时能提升 10 到 20 倍。
这个数字当然不该机械理解,但方向很清楚:企业里最贵的人群之一,就是工程师;工程师招人难、成本高,只要工具能让他们多产出一点,回报就已经很明确。
第三,工程师本来就是企业里最愿意主动换工具的一群人。
很多部门上新系统,真正难的是培训、协调、审批和跨部门推动;
而写代码这件事相对更像个人任务,工程师只要觉得工具更好用,就有很强的动力自己先用起来。
再加上写代码并不要求人工智能一开始就把整件事从头做到尾,它哪怕只是帮你找错误、写模板代码、加快重复劳动,也已经是实际价值。
所以,代码之所以先跑出来,因为它正好同时满足了几个条件:模型擅长、企业能算账、用户愿意用、组织阻力又小。
再看客服。
如果说写代码是企业里最贵、最核心的人群先被人工智能增强,那么客服就是另一端。
客服通常属于后台、基础、重复度很高的工作,很多公司本来就把它外包给海外服务商或者业务流程外包公司,因为内部自己做这件事很琐碎,也不好管理。
恰恰是这种工作,特别适合人工智能先接手。因为大部分客服任务都有明确边界。
比如退款、查询、改地址、处理简单投诉,这些任务往往时长有限、意图清晰、输出也很明确。
而且客服团队本来就高度依赖标准操作流程,员工流动率又高,所以企业通常会把流程写得很细。
这种标准化、规则化的工作,正好给人工智能提供了一个很好的模仿对象。
和很多持续时间长、牵涉部门多、边界模糊的企业工作相比,客服的任务定义是少数相对清楚的。
更关键的是,客服很容易证明投资回报。
处理了多少工单、客户满意度怎么样、解决率有没有提高、成本有没有下降,这些都能量化。
只要把现状和人工智能客服做一次对照测试,结果往往都对人工智能有利:它可以处理更多工单,提高解决率,改善客户满意度,而且成本更低。
还有一点,因为很多客服原本就已经外包,所以公司引入人工智能客服时,内部变革成本反而没那么高。
再加上客服本来就有天然的人类兜底机制,比如“我帮你升级给主管”,它不需要一开始做到 100% 准确,也已经能创造价值。
最差的情况也不过是全部转给人工处理,风险相对可控。
客服这个方向跑出来,不是偶然,而是因为它既符合模型能力,也符合企业采购逻辑。
第三类是搜索。
搜索这件事表面看起来并不新鲜,但在企业内部,它反而是人工智能最容易形成持续需求的方向之一。
企业内部的真实问题不是没有信息,而是信息太散。
员工每天面对的是邮箱、文档库、即时通讯、客户系统、工单系统、内部知识库等一堆分散系统,大家知道答案可能就在某个地方,但很难高效找出来。
这正是 Glean 这种公司能快速做大的原因。
它不是发明了“搜索”这件事,而是在企业内部信息高度碎片化的环境里,把“找到正确的信息并提取出来”做成了一个明确的产品。
每天一个 FUN AI|Glean: 不仅是企业版 Google
而在很多大行业里,搜索又不是通用搜索,而是专业搜索。
比如,Harvey 最早就是从法律搜索切进去的,OpenEvidence 最早是从医疗搜索切进去的。
它们不是在做一个通用问答框,而是在做特定行业的信息入口。
对法律和医疗这类文本密度极高、专业知识极深的行业来说,这种能力比普通办公自动化更容易直接创造价值。

真正积极买单的行业:科技、医疗和法律
行业上,科技公司当然还是最先动起来的。
文章提到,聊天生成器自己的数据里,27% 的企业用户来自科技行业;同时,Cursor、Decagon、Glean 这类公司的早期客户,很多也都是科技企业。
这一点并不意外,科技行业一直是新工具最早的采用者,也是这轮人工智能浪潮本身的发源地。
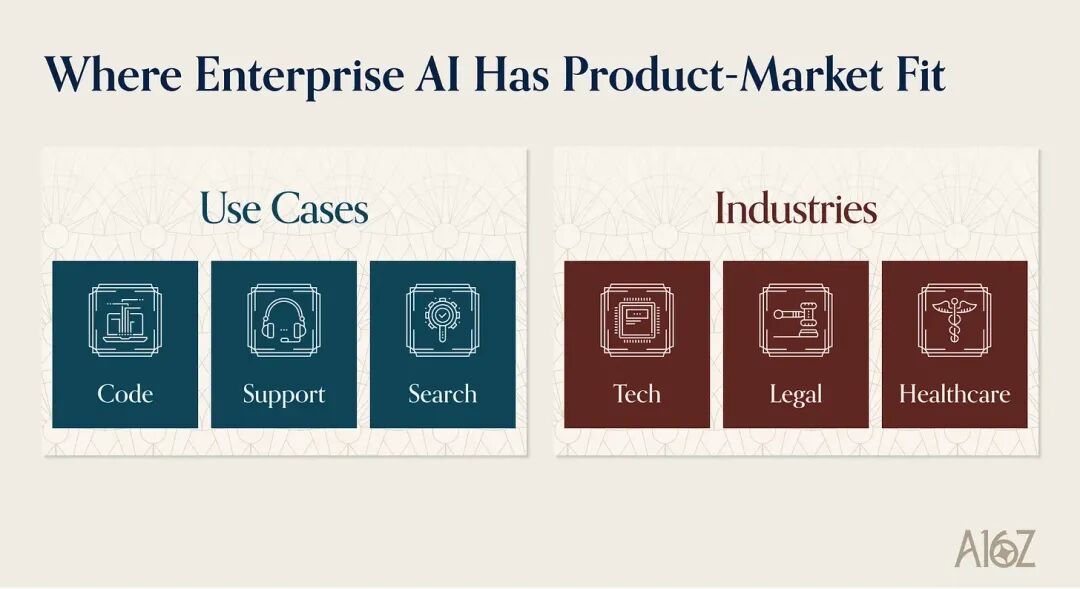
真正值得注意的是另外两个行业:法律和医疗。
先看法律。
这篇文章里有一个很有意思的判断:法律其实是这轮人工智能里最早动起来的行业之一。
这件事过去并不直观,因为法律行业长期以来一直被看作软件不太好卖的行业。
采购周期长,客户不算特别“科技化”,而且律师的大量工作都很复杂、很细腻,传统流程软件并没有真正帮助他们提效。
人工智能之所以改变了这件事,是因为它第一次真正切中了律师工作的核心劳动。
律师平时做的很多事,本来就是解析密集文本、理解大量材料、做归纳、起草、改写、总结,这些正是目前模型最擅长的能力之一。
人工智能现在常常先以 copilot 的方式提升单个律师的效率,但它已经不止是提效工具了;
在一些场景里,它甚至可以变成增收工具,因为它让律所能处理更多案件。
Harvey 在成立三年内,就做到了约 2 亿美元的年度经常性收入;
做原告侧法律服务的 Eve 拥有超过 450 个客户,并在 2025 年秋天达到 10 亿美元估值。
每天一个 FUN AI|Harvey: AI 不会替代你,但会用 AI 的人会
再看医疗。
文章对医疗的判断也很明确:医疗对人工智能的反应,明显快过它过去对传统软件的反应。
它点名了几家公司:Abridge、Ambience Healthcare、OpenEvidence、Tennr。
从 ChatGPT 到 OpenEvidence:AI 医疗的正确打开方式
它们做的事情也都不是泛泛的“医疗智能化”,而是很具体的工作,比如病历转写、医疗搜索、后台规则处理,以及那些与医疗服务交付和支付相关、极其复杂的行政流程自动化。
为什么医疗过去上软件慢,这次却对人工智能反应快?文章给了两个原因。
第一,医疗里的很多工作技能门槛高、流程复杂,传统流程软件其实很难真正匹配这些问题;
第二,像 Epic 这样的电子病历系统长期占据核心记录层,新进入者很难正面替代。
人工智能这次能进去,不是因为它重建了整个医疗系统,而是因为它绕开了“替换核心系统”这件最难的事,先从具体的人力劳动切进去。
比如替代行政记录工作、做医疗书记员,或者增强医生原本就在做的高价值工作。
由于这些任务足够独立,它们不需要先把原有系统全部推翻重做,也就更容易快速放大。

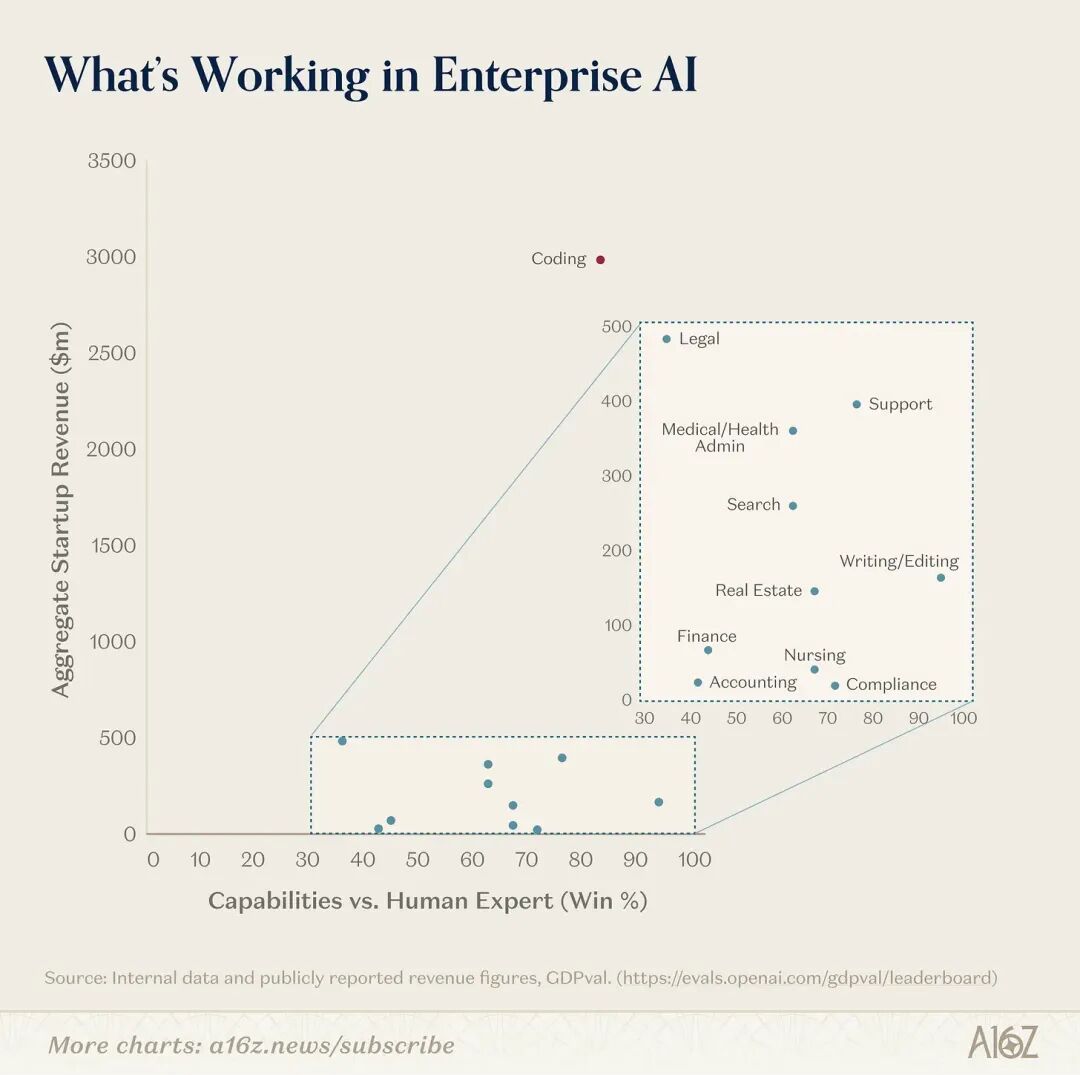
模型能力和商业价值不是一回事
我们应该怎么看企业级 AI?
简单来说,就是一边看模型理论上能做什么,一边看市场上有没有已经做出收入的公司。
企业里的工作往往不是一个完整、标准、可以一步自动化的任务,而是一串很长、很碎、边界不清的工作集合。
如果人工智能只能完成一个人 50% 的任务,并不意味着企业就获得了 50% 的价值。
相反,那些剩下 50% 不能自动化的部分,反而会变成新的瓶颈,它们的相对价值会被放大。
这就解释了为什么现在最先跑出来的,是那些只做局部自动化(剩下的 50%)也已经有价值的方向。
写代码不需要人工智能一上来就从需求到上线全部完成,哪怕只是帮你找错误、补模板,也值钱。
客服也不需要它次次都答对,答错了可以转人工。
搜索更是这样,它不需要替你做完整决策,只要把信息找对,就已经解决了一大半问题。
这篇文章里也提到,未来能力还会继续往上走。
近四个月里,在会计审计、警务侦查这类经济任务上的模型能力提升很快;
而几家实验室现在也都明显在往表格处理、金融工作流、电脑操作、长时任务这些方向继续推进。
意思很明确:今天企业人工智能的落地还很集中,但这不代表它只会停在这几类场景。
只是从商业化节奏上看,先跑出来的,永远是那些模型能力和采购逻辑重叠度最高的地方。
以上,祝你今天开心。
