 夜雨聆风
夜雨聆风- 1循环一致搜索:将问题可重构性作为搜索智能体训练的代理奖励
- 2距崩溃仅一词之遥:指令微调后“乐于助人”特性的脆弱性
- 3Lightning OPD:利用离线同策略蒸馏实现大型推理模型的高效后训练
- 4RPRA:预测 LLM 裁判以实现高效且高性能的推理
- 5KG-Reasoner:一种用于端到端多跳知识图谱推理的强化模型
- 6隐性规划能力随模型规模扩大而涌现
- 7更少的潜变量带来更好的中继:面向潜空间多智能体大模型协作的信息保持压缩
- 8Thought-Retriever:不要只检索原始数据,要为增强记忆的代理系统检索“思想”
- 9基于大语言模型引导的语义自举:用于 Tsetlin Machine 的可解释文本分类
- 10SciFi:一种面向科学应用的安全、轻量、易用且完全自主的智能体 AI 工作流
循环一致搜索:将问题可重构性作为搜索智能体训练的代理奖励
Cycle-Consistent Search: Question Reconstructability as a Proxy Reward for Search Agent Training
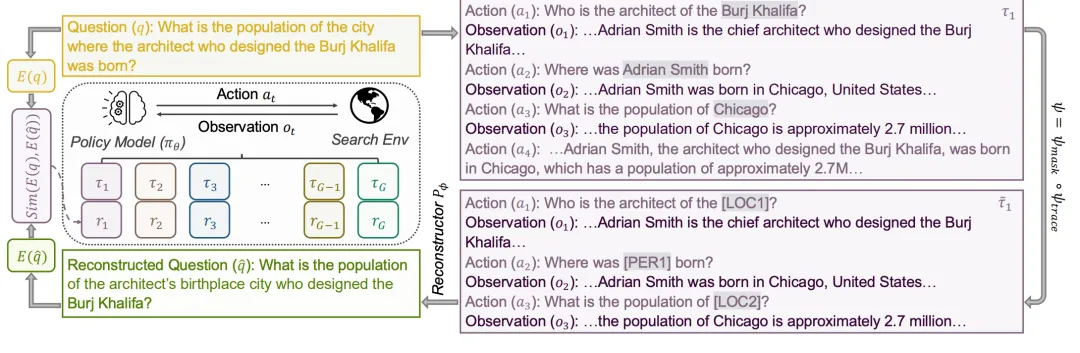
⚠️ 解决的问题:现有的搜索智能体训练通常依赖“标准答案”来评估好坏,但这在专业领域或快速变化的场景中很难获取,导致难以大规模应用。论文旨在解决如何在没有标准答案的情况下,依然能有效训练出高质量的搜索智能体这一难题。
🧩 解决的方法:论文提出了一种名为 Cycle-Consistent Search (CCS) 的方法,核心思路是:如果一次搜索过程质量高,那么仅凭搜索到的信息就应该能准确还原出原始问题。为了防止智能体偷懒(比如直接复制问题词汇),该方法特意去掉了最终回答并掩盖了搜索词中的具体人名地名,强迫智能体必须通过真正的搜索观察结果来重建问题,以此作为奖励信号进行强化学习。
💡 创新性:首次将“循环一致性”理念引入搜索智能体训练,用“能否还原问题”替代“是否有标准答案”作为训练目标,实现了无监督的高效训练。创新性地设计了信息瓶颈机制(如实体掩码),有效堵住了模型靠表面文字线索作弊的漏洞,确保奖励反映的是真实的搜索质量。实验证明,该方法在无标准答案设置下的表现优于现有同类方法,甚至能与有监督方法媲美。
距崩溃仅一个 Token:指令微调有用性的脆弱性
One Token Away from Collapse: The Fragility of Instruction-Tuned Helpfulness
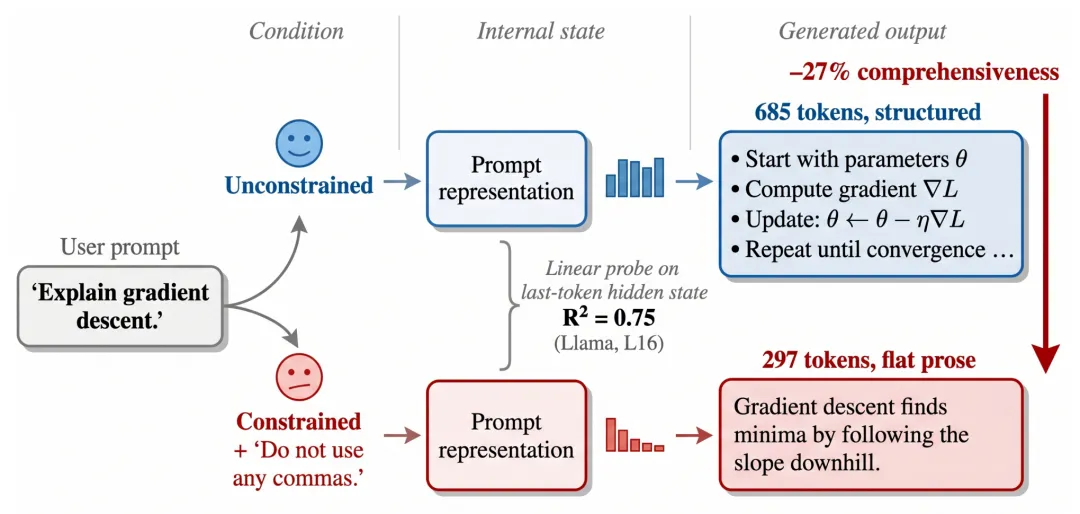
⚠️ 解决的问题:现有指令微调大语言模型看似能给出有用、结构化的回答,但在面对禁止单个标点、常用词这类极简单词约束时,回答质量会大幅下降,论文旨在揭示并解释这种脆弱性的成因与影响。
🧩 解决的方法:通过对 Llama 3.1、Qwen 2.5、Mistral、GPT-4o-mini 等模型施加词汇约束,用成对对比与独立评分两种方式评估回答完整性,结合两阶段生成、线性探针等方法分析模型行为与内部表征,定位问题根源。
💡 创新性:
- 1首次发现简单词汇约束会让指令微调模型出现约束诱导式回答崩溃,完整性损失达 14%-48%,且商用闭源模型也无法避免。
- 2证实该问题是规划失败而非能力不足,两阶段生成可恢复 59%-96% 的回答长度,且指令微调是造成这种脆弱性的核心原因。
- 3指出传统独立 LLM-as-judge 评估存在方法盲区,仅能检测到不到 1/5 的质量下降,成对对比才是约束生成场景的合理评估方式。
Lightning OPD:利用离线同策略蒸馏实现大型推理模型的高效后训练
Lightning OPD: Efficient Post-Training for Large Reasoning Models with Offline On-Policy Distillation
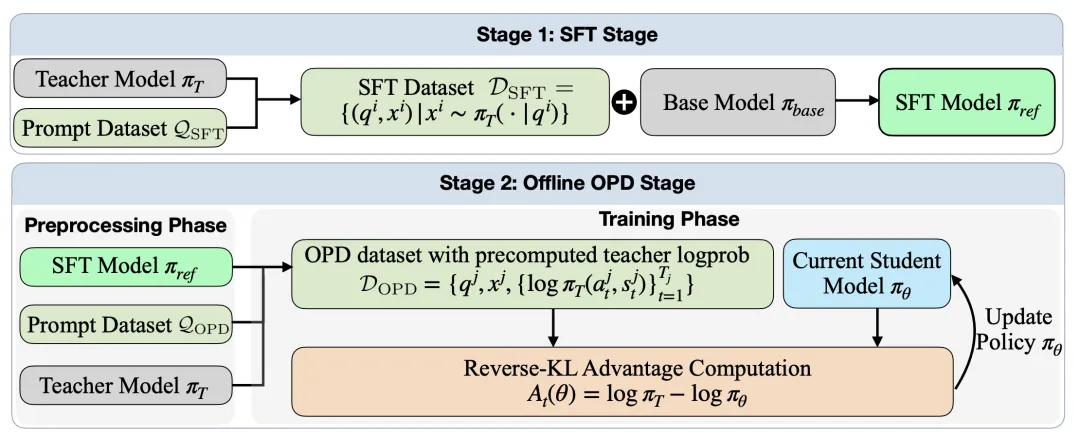
⚠️ 解决的问题:现有的大型语言模型后训练方法(如 On-Policy Distillation, OPD)虽然效果好,但训练时需要一个实时运行的“教师模型”服务器来不断评分,导致计算成本极高且难以复现。此外,业界常忽视一个关键问题:如果生成训练数据的老师和负责评分的老师不是同一个模型,会导致训练效果大打折扣。
🧩 解决的方法:论文提出了 Lightning OPD 方法,核心思路是“一次计算,重复使用”:在训练前,先用统一的教师模型生成数据并算好所有评分指标存起来,训练时直接读取这些离线数据,不再需要实时调用教师模型。该方法强制要求生成数据和评分必须使用同一个教师模型(称为“教师一致性”),从而在保证效果的同时彻底移除了对实时服务器的依赖。
💡 创新性:首次发现并证明了“教师一致性”是 OPD 成功的必要条件,指出若前后老师不一致会产生无法消除的误差;基于此提出的 Lightning OPD 框架在数学推理和代码生成任务上达到了与标准方法相当甚至更好的效果,同时将训练效率提升了 4 倍(例如在 Qwen3-8B 模型上仅需 30 GPU 小时即可达到 SOTA 水平),大幅降低了学术研究门槛。
RPRA:面向高效且高性能推理的 LLM 评判器预测方法
RPRA: Predicting an LLM-Judge for Efficient but Performant Inference
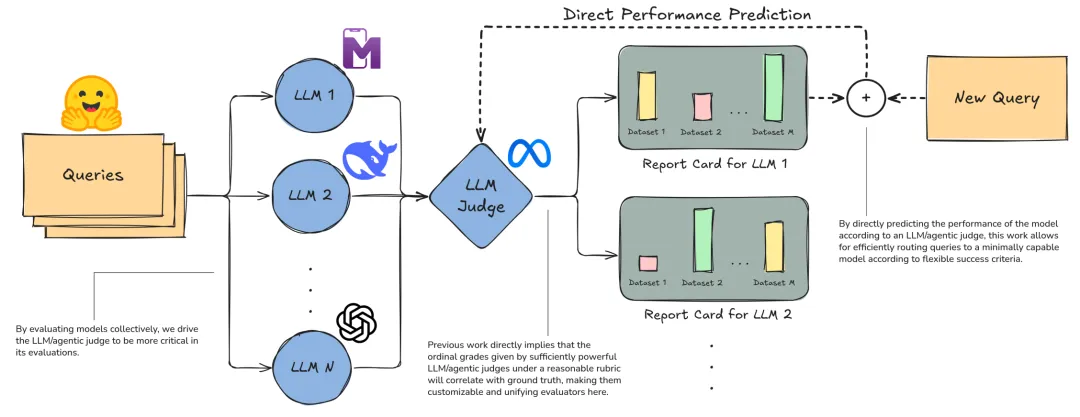
⚠️ 解决的问题:大语言模型存在计算效率与输出质量的固有矛盾,小模型易出现回答不稳定、过度自信或不自信的问题,而直接使用 LLM 评判器评估成本高、延迟大,无法实现高效推理。
🧩 解决的方法:提出 PA(预测 - 回答 / 执行) 与 RPRA(推理 - 预测 - 推理 - 回答 / 执行) 范式,让模型在生成回答前,预测 LLM 评判器对自身输出的评分;并通过上下文成绩单和监督微调两种方式,提升小模型的预测准确性。
💡 创新性:
- 1首创让模型提前预测外部 LLM 评判器评分的范式,无需生成完整回答即可判断自身能力,实现小模型自主路由。
- 2提出无需训练的成绩单机制与基于后见之明技巧的微调方法,让小模型预测精度最高提升约 55%,大幅降低推理成本。
- 3验证了大模型零样本预测、小模型经优化后可靠预测的可行性,为高效自感知 AI 系统提供新路径。
KG-Reasoner:一种用于端到端多跳知识图谱推理的强化模型
KG-Reasoner: A Reinforced Model for End-to-End Multi-Hop Knowledge Graph Reasoning
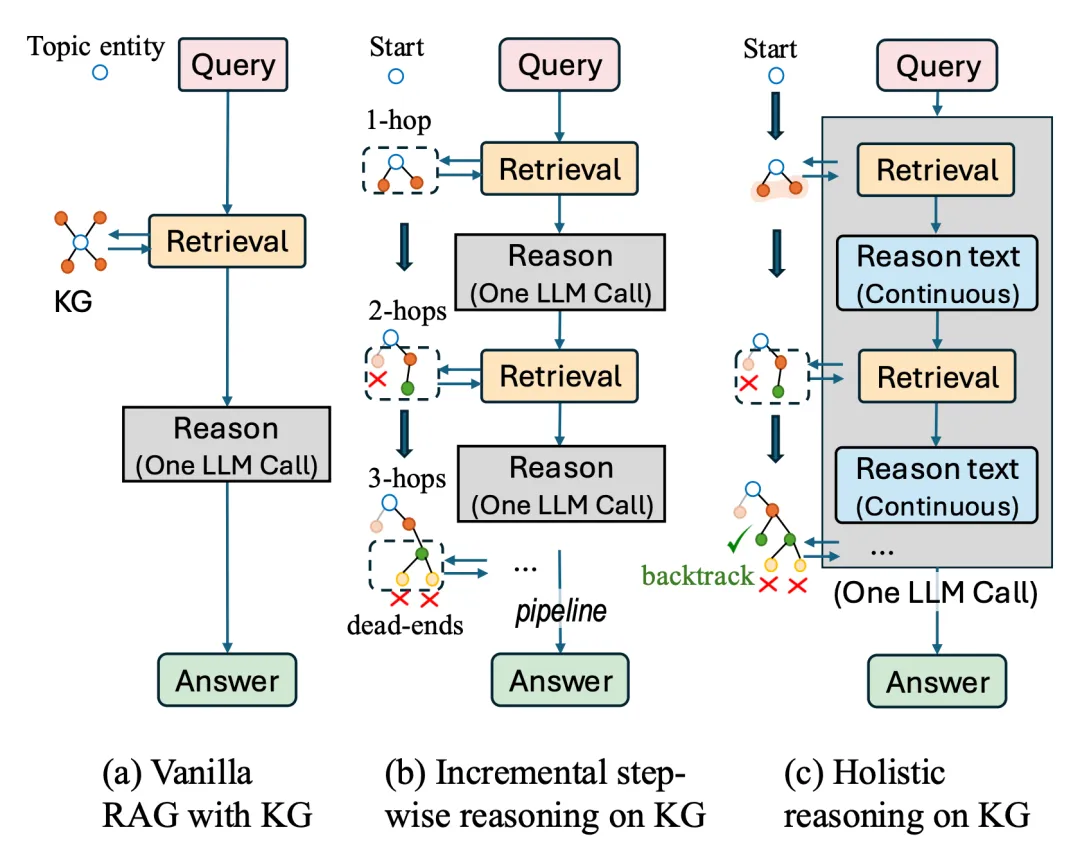
⚠️ 解决的问题:大型语言模型(LLM)在处理需要大量外部知识的复杂问题时,容易出现事实错误或“幻觉”,且难以在结构化的知识图谱(KG)中进行多步连贯推理。现有的方法通常将推理过程拆分为多个独立的步骤,导致上下文断裂、错误累积,且难以在走错路时灵活回头修正。
🧩 解决的方法:论文提出了 KG-Reasoner 框架,让一个智能体在单一的“深度思考”过程中,自主地交替执行检索和推理,而不是分步调用模型。通过强化学习(RL)训练,该模型学会了动态探索推理路径,并在发现逻辑死胡同时自动触发“回溯”机制,重新选择实体继续推理。
💡 创新性:最大的创新是将检索与多步推理完全融合进 LLM 的统一思维流中,实现了端到端的连贯推理,解决了传统流水线方法上下文割裂的问题。此外,论文设计了专门的图神经网络(GNN)辅助实体选择,并结合包含“检索奖励”、“格式奖励”和“答案奖励”的强化学习策略,显著提升了模型在复杂多跳问答任务中的准确性和鲁棒性。
隐性规划能力随模型规模扩大而涌现
LATENT PLANNING EMERGES WITH SCALE
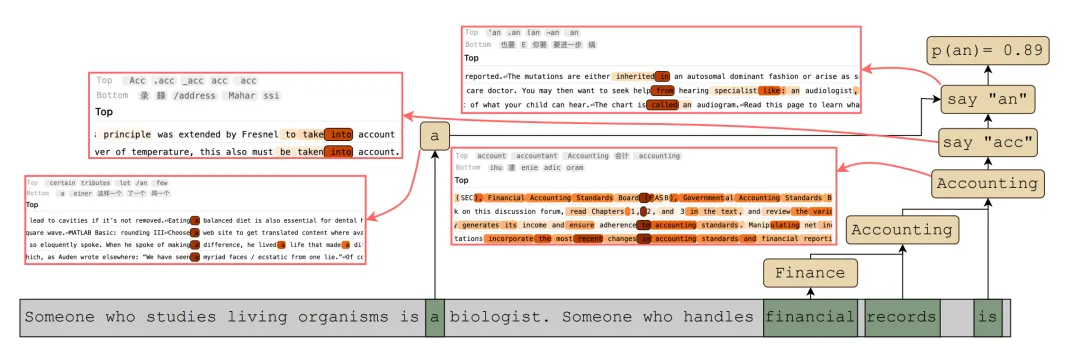
⚠️ 解决的问题:大型语言模型(LLMs)常能完成看似需要规划的任务(如写故事或代码),但它们是否真的在内部进行了“隐性规划”尚不清楚。如果模型具备这种不通过语言表达的规划能力,可能会带来安全隐患,例如模型可能在未被察觉的情况下策划不良行为。
🧩 解决的方法:研究者定义了“隐性规划”的两个核心条件:一是模型内部有代表未来目标的特征并导致该目标输出(向前规划),二是该特征能反向影响前文以适配目标(向后规划)。他们利用 transcoder feature circuits(一种分析模型内部因果机制的工具)在 Qwen-3 系列模型上测试了简单任务(如冠词选择)和复杂任务(如押韵对联),观察不同规模模型的表现差异。
💡 创新性:论文首次提供了大规模开源模型中隐性规划的因果证据,发现规划能力随模型参数量增加而增强,且“向前规划”比“向后规划”更早出现。研究还揭示了即使表现不佳的中小模型也拥有初级的规划机制,为理解 AI 安全中的潜在风险提供了新框架。
更少的潜变量带来更好的中继:面向潜空间多智能体大模型协作的信息保持压缩
When Less Latent Leads to Better Relay: Information-Preserving Compression for Latent Multi-Agent LLM Collaboration
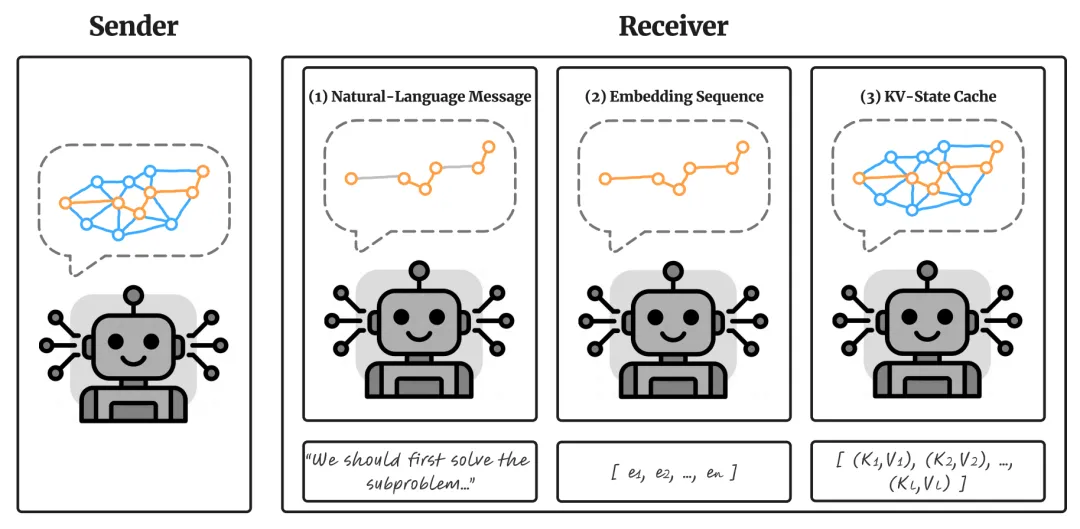
⚠️ 解决的问题:在多智能体大模型系统中,直接传递完整的内部状态(KV Cache)虽然能保留丰富信息,但会导致极高的内存占用和通信成本,限制了系统的扩展性。现有的压缩方法主要针对单智能体场景设计,直接用于多智能体间的信息传递时,容易因过度删除关键背景信息而导致下游任务性能下降。
🧩 解决的方法:论文提出了一种基于“淘汰机制”的压缩框架,并创新性地引入了 Orthogonal Backfill (OBF) 技术来弥补信息损失。OBF 的核心思路是:在删除部分状态前,先提取出那些无法被保留状态代表的“正交残差”信息,将其压缩后重新注入到保留的状态中,从而在不增加太多数据量的前提下恢复关键背景知识。
💡 创新性:该研究首次将 KV 缓存压缩定义为多智能体间的“通信问题”而非单纯的“显存优化问题”,证明了经过筛选和增强的少量信息比原始全量信息更能提升协作效果。实验显示,该方法在数学推理、代码生成等 9 个基准测试中,以不到原体积 20% 的通信量达到了甚至超越完整传输的性能,其中 OBF 技术在 7 个任务上取得了最佳结果。
Thought-Retriever:不要只检索原始数据,要为增强记忆的代理系统检索“思想”
Thought-Retriever: Don't Just Retrieve Raw Data, Retrieve Thoughts for Memory-Augmented Agentic Systems
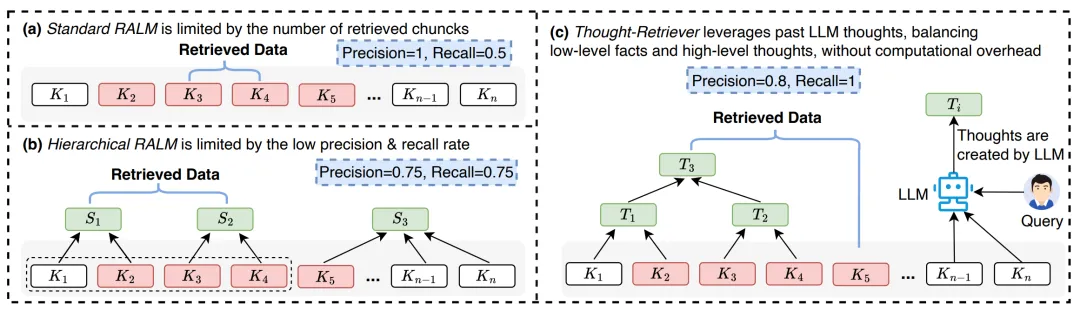
⚠️ 解决的问题:现有的大语言模型(LLM)在处理海量外部知识时,受限于上下文长度,只能读取少量原始数据片段,导致无法全面利用信息。同时,传统的检索方法往往存储杂乱的原始记录,缺乏对过往经验的深度提炼,难以应对复杂的长期任务。
🧩 解决的方法:论文提出了一种名为 Thought-Retriever 的框架,它让智能体在回答问题后,将解题过程中的关键推理提炼为“思想”(Thoughts)并存入记忆库,而非保存冗长的原始对话。当遇到新问题时,系统会同时检索原始数据和这些高质量的“思想”,从而用更少的篇幅覆盖更丰富的知识。
💡 创新性:该方法首创了让智能体通过积累和复用“思想”来实现自我进化的机制,随着交互增多,其解决抽象问题的能力显著提升。此外,作者还构建了 AcademicEval 基准测试,专门用于评估模型在真实学术论文等超长文本场景下的理解与运用能力。
基于大语言模型引导的语义自举:用于 Tsetlin Machine 的可解释文本分类
LLM-Guided Semantic Bootstrapping for Interpretable Text Classification with Tsetlin Machines
⚠️ 解决的问题:现有的符号模型(如 Tsetlin Machine)虽然透明可解释,但缺乏理解同义词和上下文的能力;而强大的预训练语言模型(如 BERT)虽懂语义,却像“黑盒”一样难以解释且计算成本高。这篇论文旨在解决如何让轻量级的符号模型也能具备大模型的语义理解能力,同时保持完全的可解释性。
🧩 解决的方法:作者提出了一种“三步走”策略:首先利用 LLM 将分类标签拆解为细粒度的“子意图”,并分阶段生成多样化的合成训练数据;接着训练一个简化版的 Non-Negated TM (NTM) 从这些数据中提取高置信度的关键词作为语义线索;最后将这些线索注入真实数据中,指导标准的 Tsetlin Machine 进行学习,整个过程无需在运行时调用 LLM。
💡 创新性:该研究首创了通过结构化“子意图”将大语言模型的语义知识蒸馏到纯符号逻辑中的方法,无需使用复杂的向量嵌入。实验证明,该方法在多个任务上的准确率媲美 BERT,远超传统符号模型,且在预测时完全不需要大模型参与,实现了高性能与高可解释性的完美统一。
SciFi:一种面向科学应用的安全、轻量、易用且完全自主的智能体 AI 工作流
SciFi: A Safe, Lightweight, User-Friendly, and Fully Autonomous Agentic AI Workflow for Scientific Applications
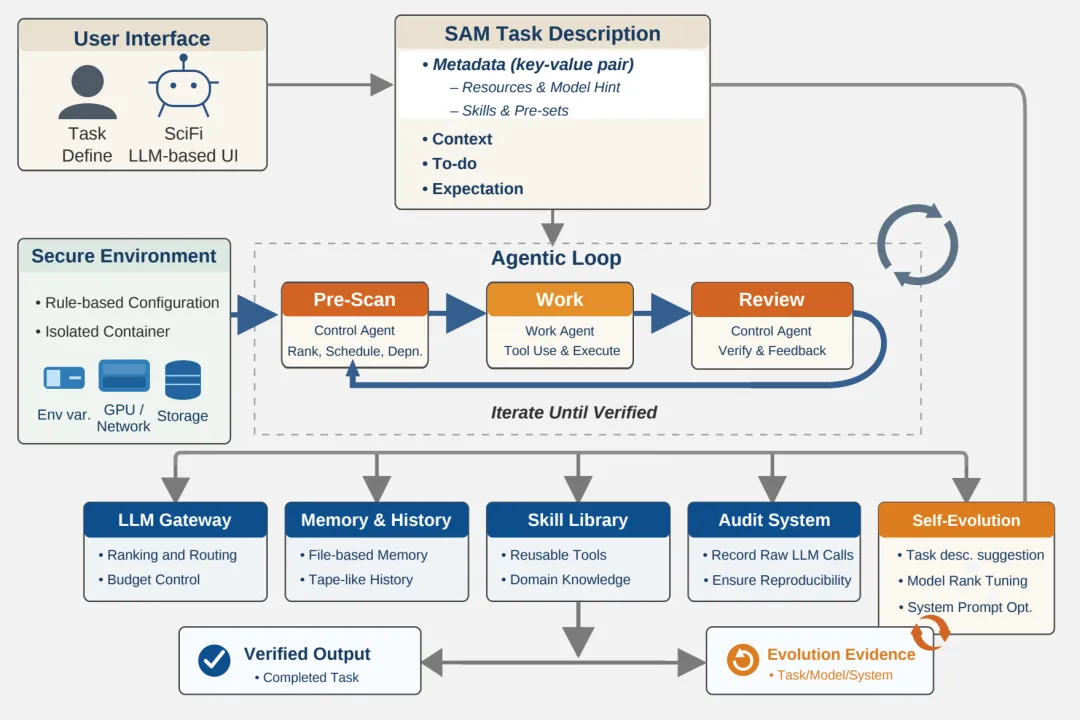
⚠️ 解决的问题:现有的 AI 智能体系统在科研场景中往往不够安全,容易误操作共享计算资源,或者需要人类频繁盯着才能可靠运行。科研人员大量时间浪费在重复性的代码调试、环境配置和数据可视化上,缺乏一个能全自动闭环执行且结果可信的工具。
🧩 解决的方法:该论文提出了 SciFi 框架,它将任务封装在隔离的容器(如 Apptainer)中运行以确保安全,并通过“三层智能体循环”(预扫描、执行、审查)配合“自我评估机制”来自动试错和验证结果。系统允许用户用自然语言描述任务目标,智能体会自动拆解步骤、调用工具,直到通过预设的验收标准才停止。
💡 创新性:SciFi 首创了针对科研“闭环任务”的专用设计,通过严格的隔离环境和自动化的“执行 - 验证”循环,实现了无需人工干预的可靠全自动运行。其独特的架构支持灵活切换不同能力的模型以降低成本,并能将解决过的难题转化为可复用的“技能库”,让系统随着使用次数增加而越用越聪明。
