 夜雨聆风
夜雨聆风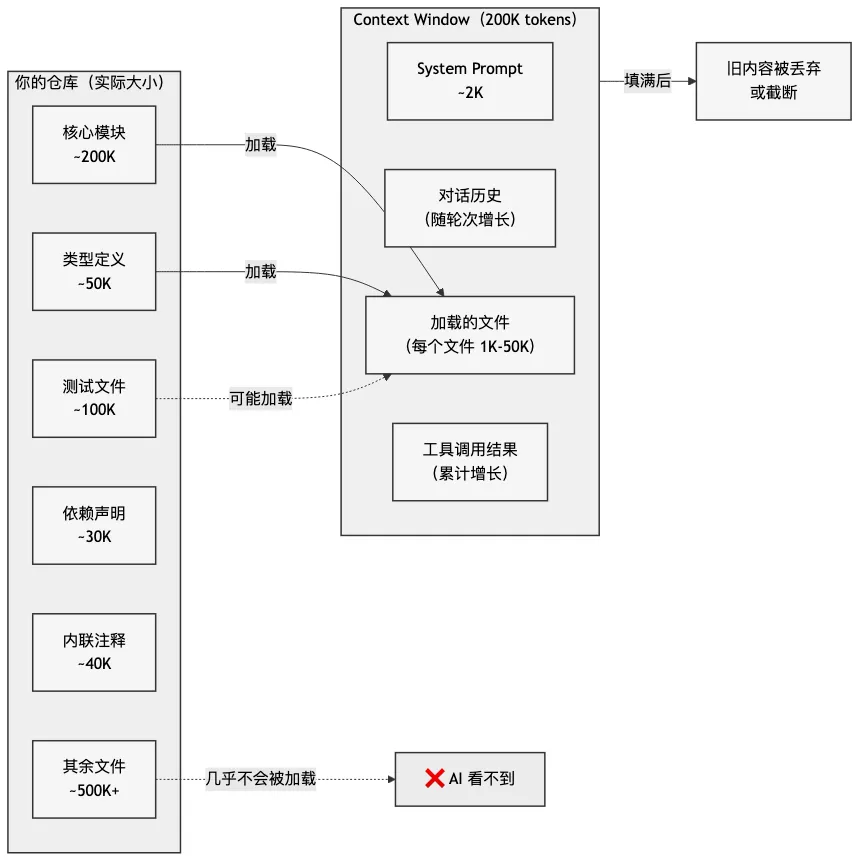
即使是 200K tokens 的大 context window,面对一个真实的中型仓库,能同时装进去的也只是一部分。被装进去的决定了 AI 能看到什么,没被装进去的决定了 AI 会在哪里会犯错——它不知道自己没看到的东西。
一个真实的失败场景
你的项目用了一套自定义的分页工具,封装在 src/utils/pagination.ts 里。这个文件 150 行,大量地方用到。
你向 Claude Code 提了个需求:"给订单列表页加分页"。
Claude Code 读了 orders.controller.ts、orders.service.ts、orders.entity.ts,开始实现——但 src/utils/pagination.ts 没有被读到(它的路径里不包含 "order",grep 和 glob 都没命中)。
结果:Claude Code 实现了一套自己的分页逻辑,从头写了 PaginationResult interface 和 paginate() 函数。代码没有问题,逻辑也正确,就是和你已有的工具完全重复,风格也不一样。
这个失败不是 AI 不够聪明,而是它不知道 pagination.ts 的存在。没有任何迹象告诉它需要去看那个文件。
这是 context window 问题的核心:AI 不知道它不知道什么。
Context window 的数字是什么意思
1 个 token 大约等于 0.75 个英文单词,或者 1-2 个中文字符。
一个中等规模的 TypeScript 项目(10 万行代码):大约 250K-400K tokens,超出了 GPT-4o 和 Claude 3.7 的窗口上限。
但这还不是全部。在 Agent 模式里,context window 要装:系统提示(约 2K)、对话历史(随轮数线性增长)、工具调用结果(每次 Bash 的输出、每次 Read 的文件内容)、当前任务的推理过程。实际上,一个跑了 20 轮工具调用的 Agent 任务,光对话历史就能吃掉 50K+ tokens。可用于装文件 context 的预算远比 context window 上限小。
各工具的应对策略
没有人真正解决了这个问题,只有不同的绕法:
Cursor:把仓库压缩成向量索引
把代码切块、向量化,再通过语义检索按需加载最相关的片段。优势是无需手动指定,劣势是检索精度依赖嵌入质量,语义不相关但逻辑必要的文件(比如命名特殊的工具函数)容易漏掉。
Claude Code:让 AI 自己扩展 context
通过 Read/Grep/Glob 让 AI 主动找相关文件。优势是 AI 的判断往往比向量检索更准(它能推理"实现分页我应该看看有没有现成的分页工具");劣势是它不知道什么时候需要去看——上面的失败案例就是它没有触发这个推理。
Cursor + Claude Code 共同的逃生出口:CLAUDE.md / .cursorrules
这是目前所有工具里最被低估的功能。你可以在项目根目录建一个说明文件,告诉 AI "项目里有哪些重要的工具函数、在哪里":
# CLAUDE.md
## 重要工具
- 分页工具:src/utils/pagination.ts,所有分页逻辑统一走这里
- HTTP 响应:src/utils/response.ts,不要自己写 ApiResponse
- 错误处理:src/exceptions/,继承 BaseException
- 数据库:TypeORM,不要用原生 SQL
这个文件会被加载进每次会话的 system prompt,相当于给 AI 一份项目导游图。这是目前最有效的大型仓库适配手段,不依赖任何检索算法,直接命中。
opencode 的 context budget 可视化
opencode 的 TUI 界面会显示当前 session 的 token 消耗,让你感知到 context 什么时候快满了。这不解决 context window 的物理限制,但让你能在 context 太长、质量下降之前主动 /new 开新会话、手动压缩历史。
长任务为什么比大仓库更难
大仓库的问题是空间——context 装不下。长任务的问题是时间——对话历史越积越长,最早的内容被截断或权重稀释。
在 Claude Code 里跑一个复杂任务,经历了 40 轮工具调用之后,你会发现它开始忘记早期建立的约定:它第 5 轮时决定"这个模块用 Strategy Pattern",到了第 38 轮它开始用另一种方式实现——不是因为它改变了主意,而是第 5 轮的内容在 context 里被挤到了遥远的地方,权重不够了。
应对方法:
- 任务分解
:把一个大任务拆成有清晰边界的子任务,每个子任务开新会话 - 显式阶段 checkpoint
:每完成一个阶段,让 AI 写一份简短的决定记录,下个会话带着这份记录进来(这比让新会话继承上一个会话的几千条工具调用结果要干净得多) - CLAUDE.md 记录项目约定
:所有架构决定、规范、约定写进 CLAUDE.md,它每次都会被加载,不会随对话历史稀释
还没有人解决的问题
当前所有 AI 编程工具,在以下场景都无法令人满意:
- 跨模块的语义一致性
:AI 不知道"这个函数应该和另一个模块的命名风格保持一致",因为它没见过那个模块 - 增量理解大型项目
:每次新会话都从零开始理解项目,没有跨 session 的真正记忆(CLAUDE.md 是补丁,不是记忆) - 依赖链推理
:当改动 A 会影响 B、C、D 时,AI 只能发现它看到的依赖,看不到的依赖它无法推理
这些问题的解法方向是有的:更长的 context window(Gemini 的 1M 方向),更好的记忆机制(持久化的项目图谱),更精准的检索(代码 AST 级别的索引而不是文本相似度)。但截至 2026 年,没有哪个工具把这几件事做成了真正可用的产品。
代码编辑器里的 AI 是当前最成熟的 AI 辅助工具形态,但它面对的这个问题——如何让 AI 真正理解一个有历史积累的复杂系统——也是所有领域的 AI 辅助工具共同的下一个战场。
延伸阅读
Anthropic: CLAUDE.md best practices — CLAUDE.md 写法的官方指南,这是目前最有效的大型项目适配手段 Simon Willison: The problem with context windows — 对 context window 局限性的清醒分析 Cursor: Rules for AI — .cursorrules 文件的用法,和 CLAUDE.md 同一个方向的解法 TreeSitter: AST-based code analysis — 代码语法树级别的索引方向,下一代 context 工程的基础技术之一
