 夜雨聆风
夜雨聆风中美 AI 差距:聊聊我们到底差在哪,又赢在哪
开始之前,我希望大家都有一个共识,那就是 AI 的牌桌上只有两个人在玩,那就是中美两家,再无他人。

这是一个我一直在琢磨的问题,中美之间的 AI 模型,差距到底有多大?
你说差距大吧,上年年初DeepSeek 用 560 万美元训出来的模型干翻了一众硅谷巨头的股价;你说没差距吧,打开 Claude、GPT 和国产模型对比着用一圈,体感上你又骗不了自己。
一、先说劣势:差距在哪,得认
1. 硬伤中的硬伤——算力
算力决定了一个模型能训多大、能跑多快、能记多长。 训练阶段,算力决定你的参数能堆多高、数据能吃多少;推理阶段,算力决定响应速度和并发能力。算力就是 AI 的地基。
拉回到 2025 年 1 月。DeepSeek R1 发布,英伟达单日市值蒸发近 6000 亿美元。R1 在数学推理、代码能力等基准测试上,打平甚至超过了 OpenAI 当时的推理模型 o1。
但看参数规模:DeepSeek R1 总参数 6710 亿,用了 MoE(混合专家架构),每次实际激活 370 亿。同期的 GPT-4,业内估计总参数在 1.76 万亿 左右。R1 用不到 GPT-4 四成的参数量做到了接近的效果——确实牛,但差距摆在那里。
参数量意味着什么?可以理解为是 AI 的脑容量。AI 行业对模型的参数量有一个可以称之为信仰的理论:Scaling Law(缩放定律),简单来说该理论指出参数量的大小很大程度上决定了 AI 是不是聪明。
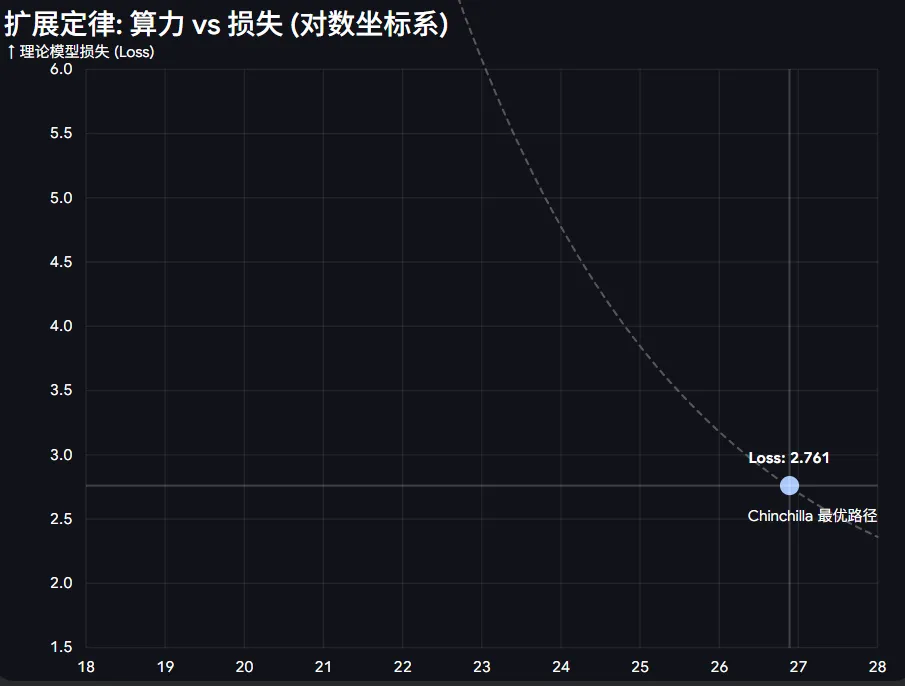
快进到现在。
今年 3 月,Anthropic 泄露了 Claude Mythos 模型,马斯克说参数量在 10 万亿 级别。当然,老马说的并不一定是真的,毕竟现在Mythos模型还很神秘。那就聊 Opus4.6 吧,业界普遍推测其参数量为1.7万亿 到 5万亿。
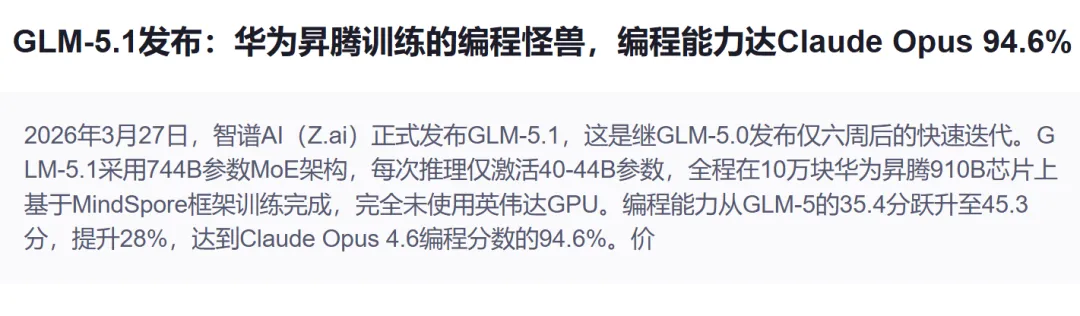
我们这边呢?智谱 AI 3 月底发布了 GLM-5.1,总参数 7440 亿,激活 400 亿。7440 亿 vs 1.7 万亿,差距过大。当前国内的模型参数量普遍在1万亿级别。
GLM-5.1 有个值得说的点——完全在 10 万块华为昇腾 910B 芯片 上训练,没用一块英伟达 GPU。这是里程碑式的突破,也从侧面说明了现实:芯片被卡脖子,得靠国产替代硬扛。
2. 训练数据这个暗坑
参数量是脑子大不大的问题,训练数据是这个脑子吃过多少见过多少的问题。
用 Seedance 2.0 的例子来说。
今年 2 月 12 号,字节发布视频生成模型 Seedance 2.0。这个模型的实力想必大家都是知道的,从它出来之后,你刷视频估计没少刷到用它做出来的视频,论质量,Seedance 2.0就是现在最强的视频模型。
Seedance 2.0 为什么这么强?因为字节背后站着抖音。
抖音每天产生的视频量是天文数字级别——各种风格、场景、光影、运镜,这就是训练视频模型最好的教材。它「看」过足够多的好内容,所以才能「拍」出好内容。训练数据的质量和广度,直接决定了模型的能力上限。
回到语言模型,问题就来了。英文互联网的高质量内容体量是中文的好几倍——学术论文、技术文档、Wikipedia,这些都是「黄金语料」。中文互联网呢?百家号、营销软文、洗稿文章占了太大比例。字节在视频领域有抖音这个数据金矿,但在文本领域,中文的高质量训练语料落后很大。
3. 钱的差距,大到离谱
巧妇难为无米之炊,而恰巧AI大模型又是最烧钱的东西,现在大模型厂商几乎都是亏钱的状态。
但看看他们那边呢?你就会发现,他们的融资规模难以想象。
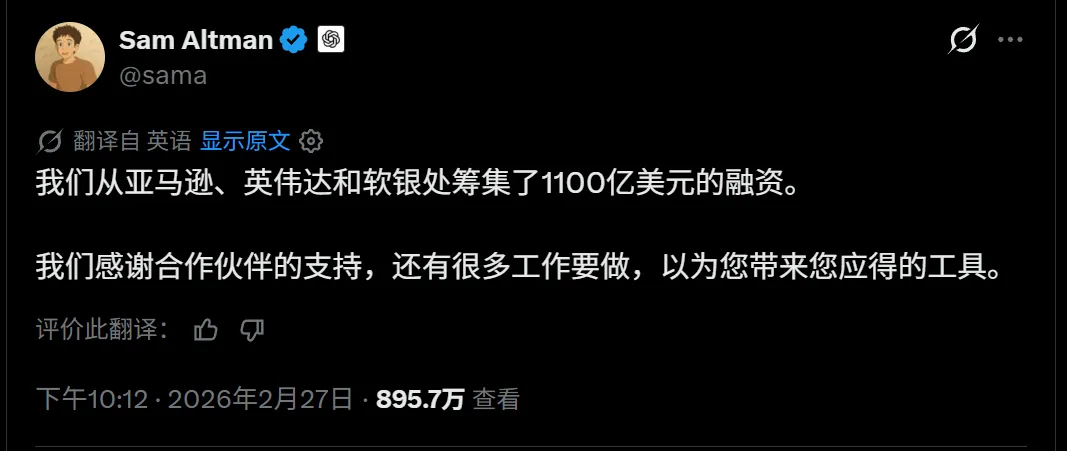
OpenAI:今年 2 月融了 1100 亿美元,人类史上最大一笔私募融资。亚马逊 500 亿、英伟达 300 亿、软银 300 亿。4 月又加码到 1220 亿,估值 8520 亿。
Anthropic:2 月融了 300 亿,估值 3800 亿。4 月中旬已有投资人开出 8000 亿 估值。年化收入从 2024 年底的 10 亿飙到现在 300 亿。
Google:2025 年 AI 基础设施资本支出超 3000 亿。不是融资,是自己砸。
国内呢?DeepSeek 没有外部融资。月之暗面 累计融了约 27 亿美元。智谱 AI 约 14 亿。
国外头部 AI 公司一轮融的钱比国内头部 AI 公司加起来的估值都高。不是一个量级的游戏。
二、再说优势:被逼出来的本事
1. 成本碾压 + 算法突围
先看一组数据。
2026 年 4 月主流旗舰模型 API 定价(每百万 token 输出价格)。
美国那边的模型价格:
•Claude Opus 4.6 — $25.00•GPT-5.4 — $15.00•Gemini 3.1 Pro — $12.00而中国这边的定价是:
•GLM-5 — $3.20•Kimi K2.5 — $2.80•DeepSeek V3.2 — $0.42
最贵和最便宜之间差了将近 60 倍。
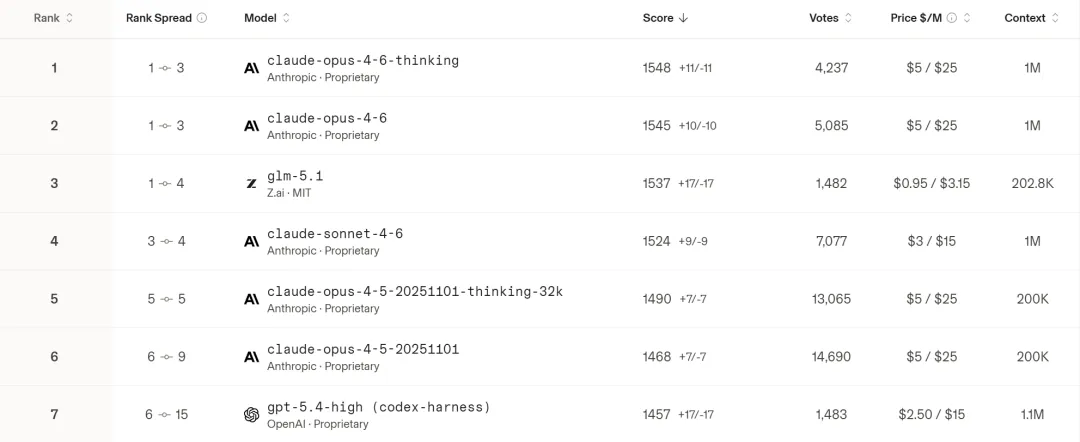
再看能力(SWE-bench Verified 编程基准测试):
•Claude Opus 4.6 — 80.8%•GPT-5.4 — 约 80%•GLM-5.1 — 77.8%•Kimi K2.5 — 76.8%•DeepSeek V3.2 — 72%-74%
价格差了几十倍,能力差距在 3 到 8 个百分点。GLM-5.1 达到 Claude Opus 编程能力的 96.3%,价格只有它 八分之一。这就是成本上的胜利。
为什么?
这背后是国内团队被硬件限制逼出来的算法创新。举两个例子。
DeepSeek 的 mHC(流形约束超连接)——去年 12 月底发布,创始人梁文锋亲自参与。简单说,它解决的是「模型参数量往万亿走的时候,训练会崩」的问题。
大家现在看DeepSeek,可能会觉得它掉队了,传言的V4版本迟迟不出。但实际上,你经常关注的话会发现 DeepSeek 每发一次论文,AI圈反响都很大。因为他们的技术产出质量足够高。
Kimi 团队的注意力残差(Attention Residuals)——今年 3 月发布,它要解决的问题是:Transformer 模型越深,底层信息就越容易被稀释丢失。
这篇论文的传播路径很有意思。马斯克在网络上转发了这篇论文并评价 「Impressive work(令人印象深刻的工作)」。
这两篇论文说明什么?国内团队不是在硬拼参数量,而是在怎么让每个参数发挥最大价值这件事上持续突破。
2. 开源生态
阿里的 Qwen 系列,累计下载突破 10 亿次,衍生模型超 20 万个,Hugging Face(AI 模型领域的GitHub) 全球第一。单月下载超 1.5 亿次,是第二到第九名加起来的两倍多。
DeepSeek 的 V3/R1 是 MIT 开源,GLM-5 也是 MIT 开源。
这意味着什么?当全世界开发者都在你的模型上做二次开发,你提供的就不只是一个模型,而是一整套生态。Airbnb (一个全球知名的在线租房平台)的 CEO Brian Chesky 公开说他们重度依赖 Qwen:「非常好,快,便宜」。多提一嘴,这个CEO 跟 OpenAI 的 CEO 是朋友,但照样选了中国的开源模型。
你开源了,全世界在你的基础上造东西,你就成了事实标准,同时,开源也意味着更容易被广泛应用,而当下 AI 的发展,缺的就是被广泛应用。很多人不知道现在的 AI 能干吗,干的多好。
三、未来的竞争会是什么样子
短期内,硬件和资金差距不会消失。Claude Mythos 如果真是 10 万亿参数,发布后可能会重新拉开差距。
但竞争的维度变了。
从「谁的模型最强」变成「谁的模型最有用」——用得起吗?生态大吗?开发者多吗?部署灵活吗?这恰恰是国内模型正在建立优势的地方。
如果说 Claude 模型、GPT 模型是顶配法拉利,国内的模型就是调教极好的性价比车。法拉利确实更快,但国内模型能让 100 倍的人开上智能汽车。
不要因为差距存在就悲观,也不要因为几个亮点就盲目乐观。这场 AI 竞赛才跑完前几圈,终局远着呢。但有一件事我越来越确信——在 AI 这件事上,中国不是追随者。我们有真实的短板,也有真实的优势。
关注我,持续带你看清 AI 行业的真实面貌,只聊干货。
人与人之间最大的鸿沟,不再是传统技能的强弱,而是对新事物的认知视差。
