 夜雨聆风
夜雨聆风一句话讲清楚👉🏻 上海 AI Lab联合复旦大学提出了 TREX ,一个多 Agent 系统,让 AI 自动完成从需求分析、文献调研、策略制定、数据准备到模型训练评估的全流程微调工作,在某些任务上的效果已经超越了人工专家设计的方案。
为什么需要「 AI 来训练 AI 」?
过去两年,我们见证了大语言模型能力的爆发式增长。 LLM 已经能写代码、做推理、甚至辅助科研。但有一个讽刺的事实——训练和微调这些模型本身,依然高度依赖人类专家的经验和大量手工劳动。
设计一套好的微调方案并不简单。你需要决定用哪些数据、怎么清洗、用什么训练算法、超参数如何设置……这是一个开放的、高维度的优化问题。而且,训练数据动辄数万到数十万条,根本无法直接塞进 AI Agent 的上下文窗口里。再加上每次实验都需要在 GPU 上跑上几个小时,传统的"暴力搜索"方式效率极低。
换句话说,现有的 AI Researcher Agent 能帮你读论文、写代码,但让它自己来调模型?还是太难了。
上海 AI Lab和复旦大学的团队正是瞄准了这个空白,提出了 TREX——据称是首个专注于 LLM 微调自动化的端到端研究 Agent 系统。
TREX 是怎么工作的?
TREX 的核心设计思想可以概括为两句话:两个角色分工协作,多轮实验形成搜索树。
双 Agent 架构: Researcher + Executor
系统包含两个核心模块:
Researcher (研究员)——负责"动脑"。它的工作包括:
- 分析任务需求,理解要优化什么
- 搜索相关文献和数据集(能访问 arXiv 和 Hugging Face )
- 制定训练策略和具体实验计划
- 分析实验结果,诊断问题
Executor (执行者)——负责"动手"。它基于 OpenHands 构建,能够:
- 将 Researcher 的计划转化为可执行代码
- 在 GPU 集群上调度和运行训练任务
- 返回实验结果给 Researcher
两者形成一个内循环: Researcher 制定计划 → Executor 执行 → 结果返回 → Researcher 分析诊断 → 下一轮迭代。
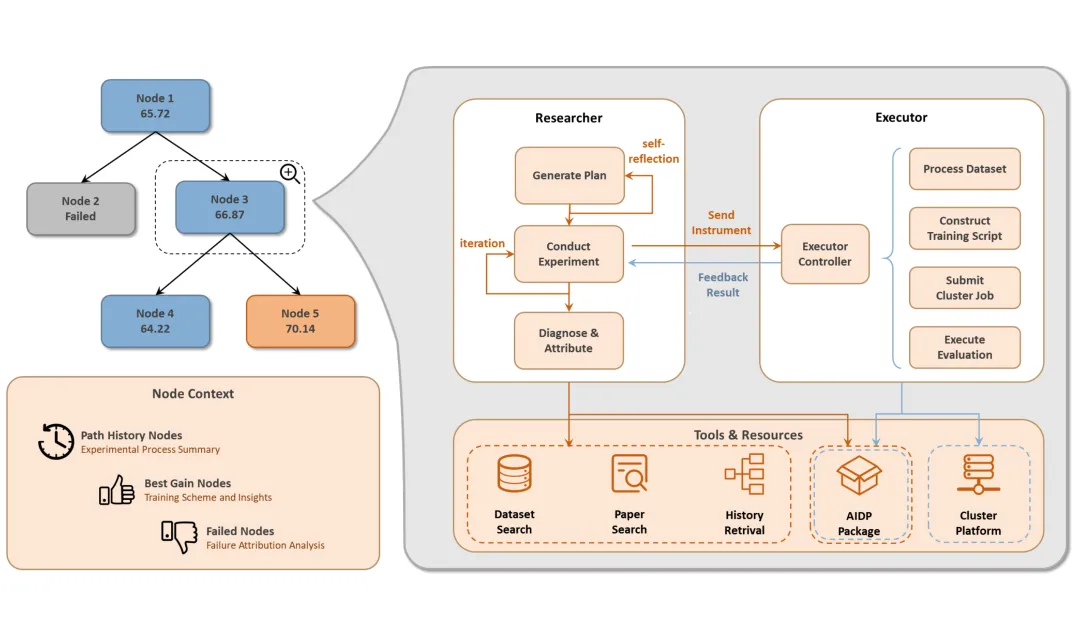
树状探索:把微调变成「下棋」
这是 TREX 最精妙的设计——将多轮迭代实验过程建模为一棵搜索树,然后用蒙特卡洛树搜索 (MCTS) 来指导探索方向。
具体来说:
UCT 公式如下:
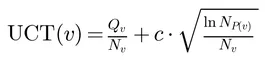
其中 N_v 是节点的访问次数, Q_v 是累积奖励(任务主指标的归一化值), c 是探索常数。这个公式的直觉很清晰:第一项鼓励利用已知的好方案,第二项鼓励探索未被充分尝试的方向——跟 AlphaGo 下棋的思路如出一辙。
记忆管理:不让上下文爆炸
跑了几轮实验之后,历史信息会越来越多,怎么防止撑爆上下文窗口? TREX 定义了一个压缩记忆上下文 MC(v):
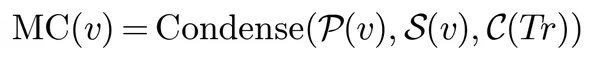
包含三个部分:
- P(v):从根到当前节点的路径(知道是怎么走过来的)
- S(v):兄弟节点信息(避免重复尝试同类方案)
- C(Tr):全树关键节点(记录显著收益或失败的重大洞察)
这样,每轮迭代只关注"从哪来、同伴试过啥、全局有什么重要发现",既保持了连续性,又不会让上下文无限膨胀。
AIDP 工具库:让数据处理变得可靠
为了解决 Agent 处理大规模训练数据的难题,团队专门开发了 AIDP (AI Data Processor) 库。这是一套基于 HuggingFace Datasets 生态的模块化工具包,提供四类算子:
| 类别 | 功能示例 |
|---|---|
| Loader | 加载本地/远程数据集 |
| Scorer | 困惑度计算、 LLM 评分 |
| Generator | 向量嵌入生成、 LLM 合成数据、偏好对构造 |
| Filter | 去重、按分数/规则过滤、随机采样 |
AIDP 的核心价值在于平衡了颗粒度和抽象度——每个算子语义清晰( Agent 能理解该调用哪个),但又足够高层(不需要 Agent 写底层处理代码)。
FT-Bench :首个 LLM 微调自动化评测基准
光有系统不行,还得有衡量标准。团队构建了 FT-Bench,包含 10 个源自真实场景的任务,覆盖两大类型:
通用能力增强类(提升模型的通用智能水平):
- SST-2:情感分类(经典 NLP 任务)
- CS-Bench:计算机科学知识评估
- GTA: Agentic 工具使用能力
- HoC:癌症标志物分类
垂直领域适应类(让模型在特定专业领域变强):
- ACI-Bench:临床笔记生成(医疗)
- oMeBench:化学机理推理(化学)
- TOMG-Bench:分子生成与编辑(药物研发)
- LawBench:法律知识评估
- OpenFinData:金融问答
- EconlogicQA:经济序列推理
这 10 个任务的设计遵循三个原则:真实性(来自真实科研/工业场景)、可控性(计算开销可控)、多样性(跨领域覆盖)。据论文称, FT-Bench 是第一个专门针对端到端 LLM 微调任务的系统化评测基准。
实验结果: AI 调参真能超过人类吗?
实验设置
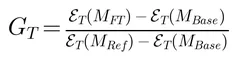
参考模型用的是 Qwen3-235B (一个大模型), G_T 越高说明微调带来的相对收益越大。
主要发现
1. 所有 10 个任务均获得一致性的性能提升
TREX 在全部任务上都成功提升了基线模型的表现,证明了系统的通用性和鲁棒性。
2. Gemini 3 Pro 后端整体优于开源后端
使用 Gemini 3 Pro 作为 Researcher 的 TREX ,其性能普遍好于使用 Qwen3-Next-80B-Thinking 的版本。这说明底层 LLM 的推理能力直接影响整个系统的效能——更强的"大脑"带来更好的"决策"。
3. 部分任务上超越人工专家方案
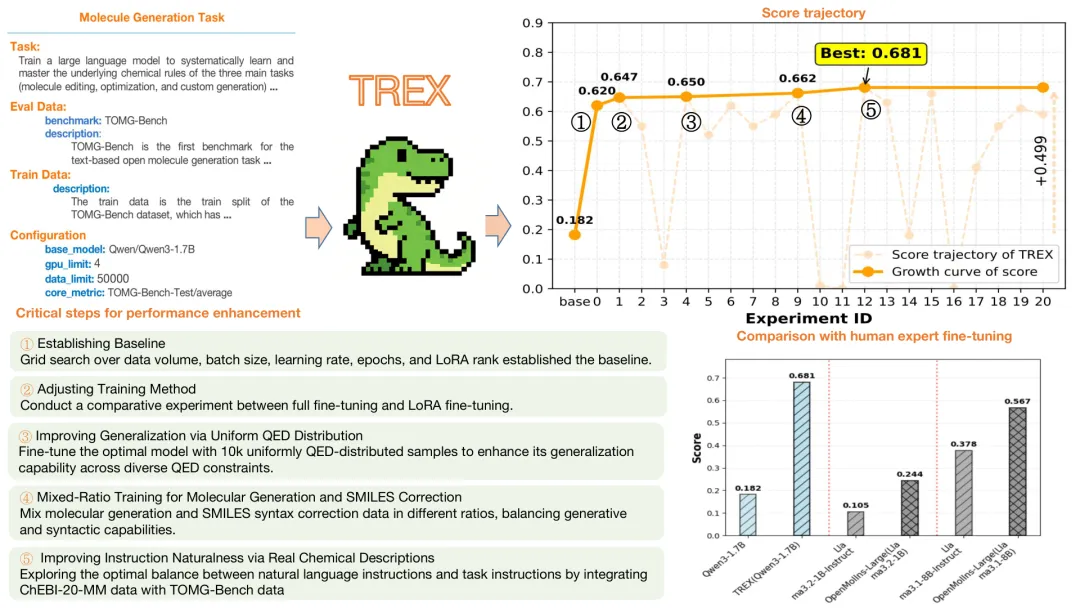
这是最引人注目的结果。在 TOMG-Bench(分子生成)任务中:
- TREX 基于 Qwen3-1.7B 的增益达到了 0.498
- 人工专家基于 Llama3.1-8B 的增益仅为 0.189
- 人工专家基于 Llama3.2-1B 的增益只有 0.139
也就是说,TREX 用一个更小的模型( 1.7B vs 8B ),取得了远超人类专家的微调效果。在 OpenFinData(金融问答)任务中, TREX 的增益 (0.205) 也媲美甚至超越了一个复杂的多阶段 CPT-SFT-RL 流水线应用于更大模型 (Qwen2.5-32B) 的结果。

TREX 常用了哪些策略?
通过对实验记录的统计分析,团队总结了 TREX 最常采用的优化策略:
| 策略类型 | 说明 |
|---|---|
| Refine Data Pipeline | 最常用策略,精细化数据处理流程 |
| Construct Synthetic Data | 用 LLM 合成训练数据, Gemini 后端成功率更高 |
| Adjust Training Scheme | 调整超参数、学习率、 LoRA 配置等 |
| Improve Instruction Quality | 优化指令模板,提升自然度 |
消融实验:每个设计选择都有用吗?
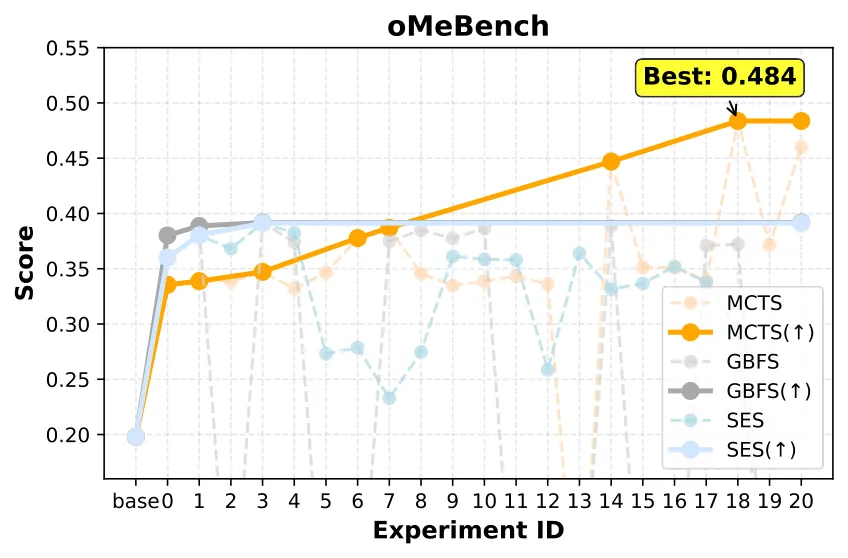
团队在 oMeBench (化学推理)和 GTA (工具使用)两个任务上做了详细的消融研究。
MCTS 树搜索策略确实最优
对比了三种节点扩展策略:
AIDP 库不可或缺
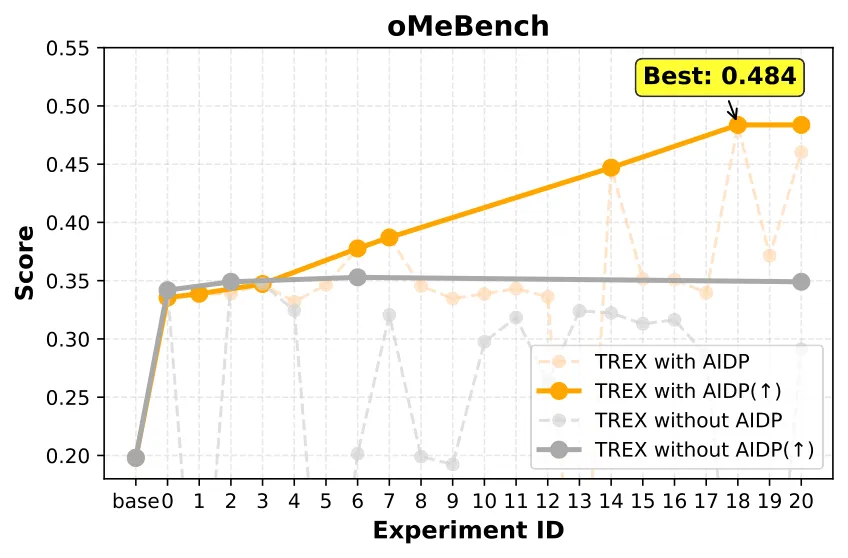
结论:有 AIDP 支持时性能提升显著更高,且不易出现数据处理失败导致的中断。 AIDP 库让 Agent 的数据操作更可靠,是整个系统不可或缺的基础设施。
坏例分析:诊断能力很重要
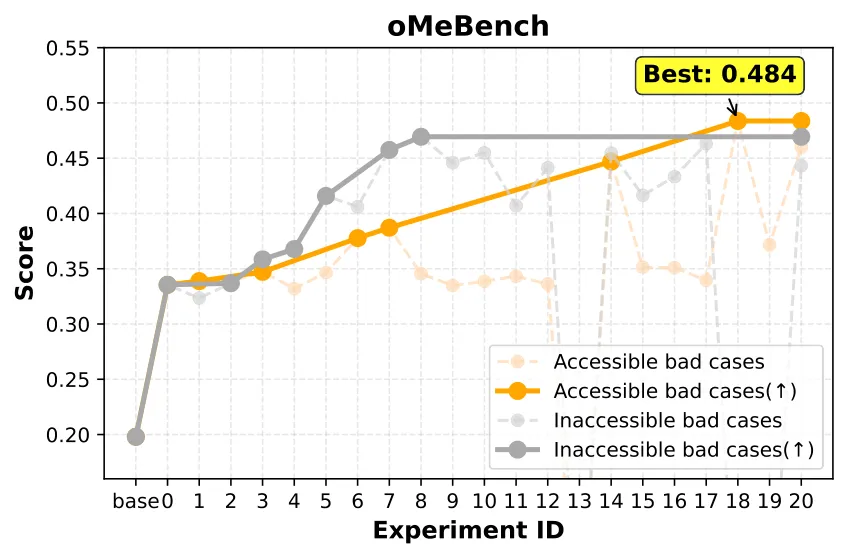
TREX 的实验诊断与归因 模块会检查验证集中的失败案例,对比当前和历史实验的指标变化。消融实验证明:引入坏例分析后, Agent 能更精准地定位问题来源(是数据质量?还是训练不充分?),从而在后续迭代中做出更有针对性的调整。
局限性与未来方向
任何研究都有边界, TREX 也不例外。论文坦诚地讨论了几个关键局限:
1. 算力成本仍然不低:虽然比暴力搜索高效得多,但每轮迭代仍需在 GPU 上完整训练一轮,对于超大模型(如 70B+)来说成本依然可观。
2. 依赖后端模型能力:实验表明 Gemini 3 Pro 后端明显优于开源方案,这意味着 TREX 的效能上限受限于底层 LLM 的推理能力。
3. 搜索空间仍受限于 Agent 的「想象力」: MCTS 能在已有策略空间内高效探索,但如果 Researcher 无法想到某个方向(比如某种全新的数据增强方法),树搜索也不会自动发现它。
4. 尚未覆盖预训练阶段:目前聚焦于微调( fine-tuning ),从零开始的预训练自动化是更大的挑战。
写在最后: AI 自己调参的时代来了?
TREX 的出现标志着 AI 研究正在从"辅助人类做研究"迈向"自主完成研究闭环"的关键一步。
回顾一下它做的事情:理解任务需求 → 搜索文献和数据 → 设计训练方案 → 在集群上跑实验 → 分析结果 → 调整策略 → 再来一轮。这本质上就是一个机器学习研究员的日常工作流,只是现在由两个 AI Agent 协作完成了。
更有意思的是, TREX 在某些任务上已经超过了人工专家设计的方案——用更小的模型( 1.7B )取得了比人类调 8B 模型更好的效果。这说明, AI 在"系统性探索大量可能性"这件事上,可能真的比人更有优势。
当然,距离完全自主的 AI 科学家还有很长的路。但 TREX 至少证明了一点:让 AI 来训练 AI ,不再是科幻,而是已经发生的现实。
资源链接
📄 论文链接
https://arxiv.org/abs/2604.14116
