 夜雨聆风
夜雨聆风大家好,我是吾鳴。专注于分享提升工作与生活效率的工具,无偿分享AI领域相关的精选报告,持续关注AI的前沿动向。
前言
OpenClaw如果看不见,如果大家要让它处理图片、视频类任务的话,会怎么办?
是不是只能把图片、视频中的画面通过文字的方式描述出来,然后发送给OpenClaw去理解分析。
比如有一个网页的设计图,想让OpenClaw帮忙把网页给实现出来,是不是需要把网页上面是什么布局,上边有什么元素,中间有写什么元素,下边有些什么元素,按钮什么颜色,背景什么颜色.....
想想都觉得很累,要用文案把一个网页的设计图给描述出来,等用文案描述完,可能手撸都已经搞好了。
如果OpenClaw可以接收一张网页的设计图,它能自己看懂设计图,然后再自己去按照设计图去撸码实现,是不是就变得简单了?
GLM Turbo
前不久,智普发布了一个大模型版本,这个大模型的版本名字叫做GLM-5-Turbo。
这个是一个文本处理模型,是专门针对OpenClaw场景下进行过深度优化的底座,从模型训练的阶段就开始针对龙虾的任务进行了专项优化,增强了工具调用、定时与持续性任务、指令遵循、长链路执行等能力,使得它在龙虾场景下更能干。
同时,与GLM-5-Turbo齐名的还有一个大模型,它的名字叫做GLM-5V-Turbo,给OpenClaw装上眼睛的正是GLM-5V-Turbo这个大模型。
这个模型是一个多模态Coding基座,专门面向视觉编程任务打造,能够处理图片、视频、文本等多模态输入,可以深度适配Agent的工作,能与OpenClaw深度协同,完成"看懂环境—规划任务—执行任务"的完整闭环。
OpenClaw接入GLM-5V-Turbo
智普推出的OpenClaw一站式产品AutoClaw已经支持GLM-5V-Turbo,开箱即用,免去复杂繁琐的接入流程。
对AutoClaw不了解的朋友,可以看看我之前写过的一篇对它进行介绍的文章——《别被OpenClaw劝退!智谱的AutoClaw才是真的小白友好,上手巨简单!》
如果是使用原生OpenClaw的朋友,可以找到OpenClaw的配置文件(~/.openclaw/openclaw.json),找到models模块的配置,修改模型相关的配置后,然后重启Gateway即可。
图片转成网页
实操的例子我会截取一张QClaw的官方网站的首页图,然后让AutoClaw去参考这张图片,把图片中的网页给复刻出来。
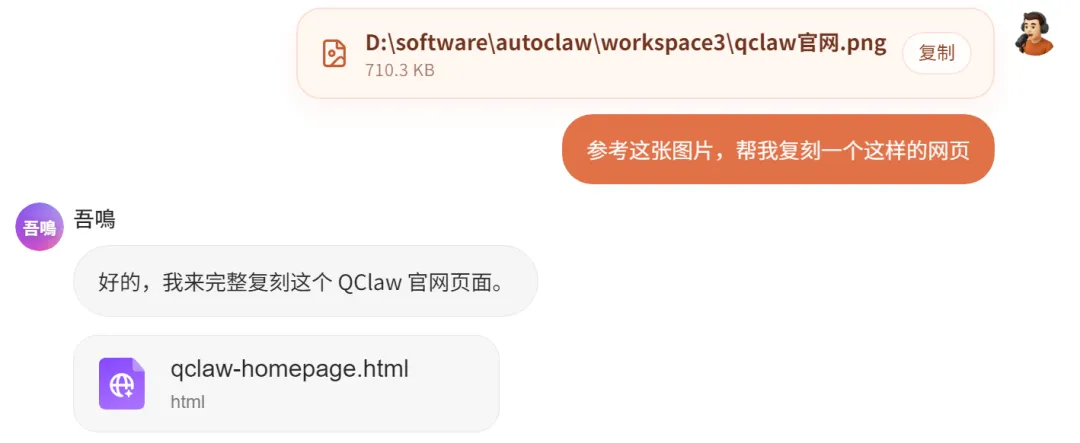
在AutoClaw在复刻图片中的网页的过程中,它会不断的打开浏览器浏览自己生成的网页是否与提供的图片相符合,不符合那么就找出问题,修改,然后再验证,就是这样一个反复的过程。
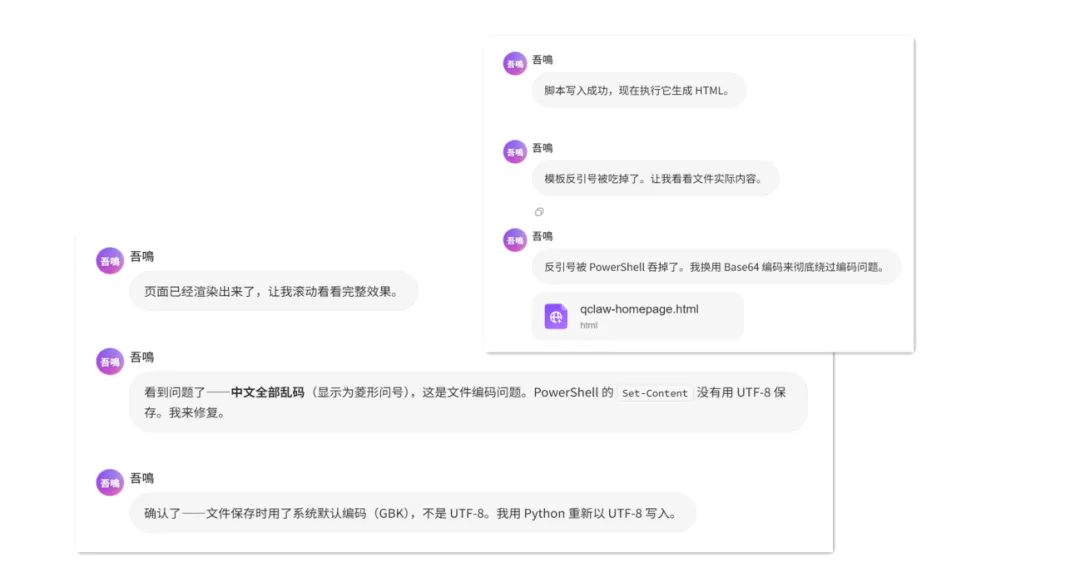
网页实现完成后,AutoClaw也给我提供了一份报告,报告显示的是它已经对图片中的网页进行复刻后实现了哪些内容,以及页面所在的位置,如何访问到页面等信息。

可以看看它复刻的页面的效果。

从复刻的结果上看,基本上已经把图片页面中有的功能都给实现了,像顶部的菜单栏、中间的下载、Logo、最下方的功能性卡片等,都给复刻出来了,而且连鼠标移动到元素上面的时候的基本的交互都是已经弄好了。
写到最后
GLM-5V-Turbo的发布直接给OpenClaw安装上了眼睛,以前要让它给做一个网页,那可能得使用文本的方式去把网页的布局,页面中的元素,页面的风格都给描述清楚后,OpenClaw才能真正的理解,把网页做出了,稍有描述不清楚的地方,那便可能会导致整个网页风格没有按照预期来生成。
但是有了GLM-5V-Turbo之后,只需要对对标的网站截个图,然后丢给OpenClaw便可以让它帮你把网页给复刻出来,效率大大的提升。
本文的分享就到这里,如果您觉得有收获的话,可以给个一键三连,您的鼓励是吾鳴持续输出的最大动力。
