夜雨聆风
夜雨聆风

2026年3月23日,国家数据局正式官宣:人工智能领域的“Token”,中文标准名称定为“词元”。
这一命名不仅终结了“代币”“通证”等跨场景译名的混乱,更标志着AI核心概念从技术“黑盒”走向了标准化的全民表达。今天,我们用五分钟时间,以“词元”为钥匙,读懂大模型最底层的运行逻辑。
作者 : 何颖
单位:中国移动杭州研发中心
专业课程体系化设计,夯实平台应用根基
01
正名:为什么是“词元”?
在此之前,Token 在不同领域译法各异:区块链中常译作 “代币”,网络安全中多称 “令牌”,但在人工智能自然语言处理场景中,这些译法均不适用。
“词元” 的命名精准贴合AI技术本质:
“词”:点明其语言文本属性,是大模型处理语言信息的载体;
“元”:代表基本处理单元,如同计算机的 “字节”、化学的 “元素”,是模型处理语言时的基础计量颗粒。
这一译名,首次用中文清晰定义了 AI 处理语言时的 “基础粒子”,让科研、产业与大众沟通有了统一术语。
02
深潜:词元到底是什么?
要理解词元,首先要打破一个误区:词元≠字,词元≠词。 很多人以为AI是直接读懂汉字的,其实不然。
人类视角:看到的是连贯语句、语义情感与真实需求。
机器视角:无法直接理解文字符号,只能对数字进行运算。
文字转为数字的核心环节,就是词元化(Tokenization)。
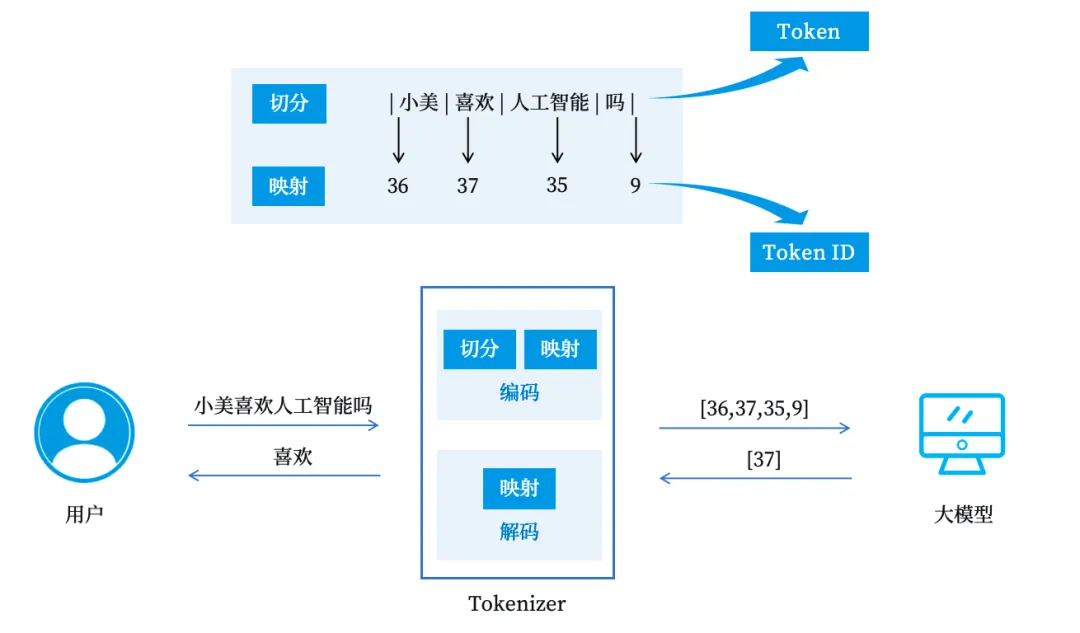
图1 词元化示意图
可以把这个过程比作“过安检”:你输入的文字是待检行李,模型自带的分词器(Tokenizer)是安检机,它会将整段文字按模型预设规则拆分、编码,转换成一个个词元,再映射为数字编号。大模型的所有推理、计算,都基于这些数字编号完成;输出时,再将数字反向还原为文字,呈现到你的屏幕上。
03
纠偏:为什么词元数不等于字数?
这是最令用户困惑的地方:为什么我只发了几百字,系统却提示消耗了上千个词元?
核心逻辑在于:词元的切分是为了计算效率,而非人类语法。
英文中:高频词(如 the)通常是1个词元;而复杂词汇(如 unbreakable)可能会被拆解为 un+break+able 多个词元;
中文中:无天然空格分隔,切分逻辑更灵活。1个汉字通常对应 1–2 个词元,但并非固定对应关系。
简单来说:词元是模型为高效计算 “自定义” 的颗粒。同样的句子,用不同模型处理,生成的词元数量也会有差异。
04
本质:智能时代的“结算单位”
词元是大模型的 “基本运算工时”,也因此成为 AI 产业的价值计量与结算标尺,国家数据局将其定义为 “智能时代的价值锚点”,具备三类核心计量属性:
1、算力计量:直接反映AI算力与资源消耗。我国日均词元调用量已突破140万亿,是衡量AI产业活跃度的核心指标;
2、服务计价:主流模型均以词元计费。你提问、它回答,本质上你买的是“词元加工服务”;
3、性能上限:模型上下文窗口长度、推理速度、对话记忆能力,最终都受限于词元的处理与承载能力。
05
图景:像使用水电一样使用AI
未来的 AI 生态中,词元将成为全民熟知的基础计量单位,如同 “电表的度数、水表的立方”。行业关注点也会从 “模型参数规模”,转向 “词元服务供给能力”。
随着技术成熟与产业规模化,词元的使用成本会持续下降,获取方式将像水电一样便捷普惠。企业与个人无需关心底层模型的训练细节,只需像缴纳水电费一样,按需使用、按量结算 AI 服务。
06
总结
“ Token” 正式定名 “词元”,看似只是一次术语规范,实则是中国AI产业从野蛮生长走向标准化发展的重要里程碑。
它终结了跨场景术语混用的乱象,让科研、教学、商业协作拥有统一语言;更标志着我国在AI领域,逐步掌握核心术语定义权与产业规则话语权。
日均140万亿词元的调用规模背后,是一个以数据为燃料、以词元为度量、以智能为核心的全新数字经济形态,正加速成型。
供稿 | 中国移动杭州研发中心
编辑 | 王思博
初审 | 陈童童
复审 | 边瑞