 夜雨聆风
夜雨聆风今天,Anthropic正式推出了Claude Opus 4.7,相关消息迅速刷屏朋友圈。想必大家都已经刷到了它的核心升级:SWE-bench Verified得分从80.8%飙升至87.6%,视觉分辨率提升三倍,编码体验也更为稳定——这些热门信息我就不再赘述,今天想和大家聊一个被多数人忽略、却细思极恐的细节。
在Anthropic长达232页的System Card(系统说明文档)中,有一句话暗藏深意:“during its training we experimented with efforts to differentially reduce cyber capabilities.” 翻译成中文就是:我们在训练Opus 4.7的过程中,特意对它的网络安全攻击能力进行了差异化削弱。
这在AI发展史上是前所未有的——一家头部AI公司公开承认,交给普通用户使用的模型,是被自己亲手“砍过一刀”的。这场景其实并不陌生,就像NVIDIA为了符合出口规定,将H100芯片阉割为H800后供给中国市场一样,只不过这一次,被“阉割”的是Anthropic的顶级模型:“完整版Claude”被调整为“面向公众的Claude”,能力大幅缩水。
一、被砍掉的能力,到底有多少?
我们用三组关键数据,就能看清这种差距的悬殊程度。
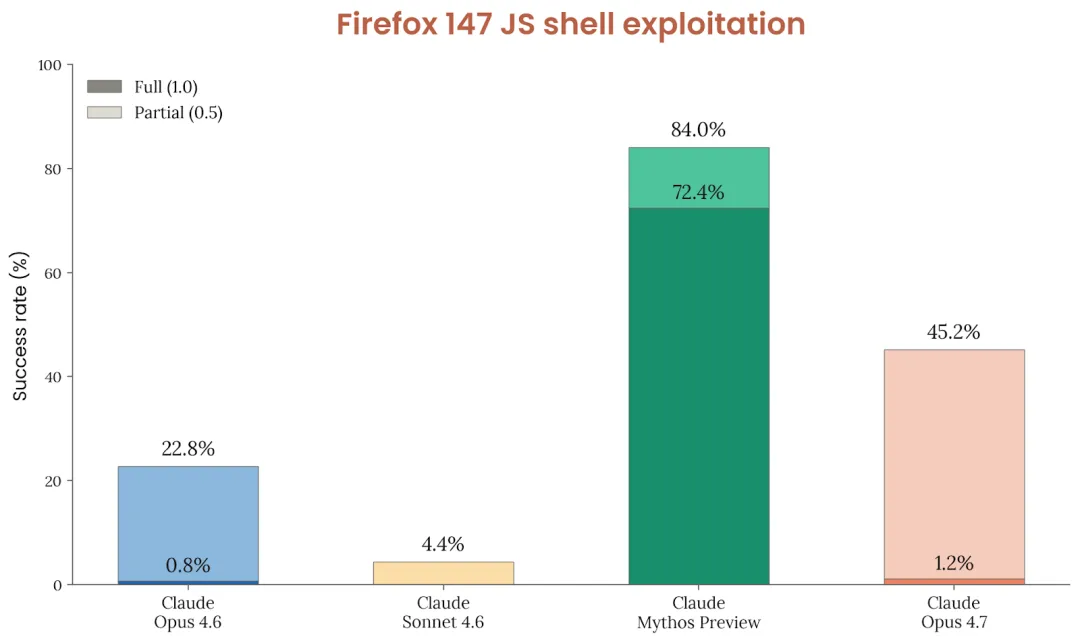
第一组数据来自Firefox 147漏洞利用测试。此前Anthropic曾与Mozilla联手修复了一批Firefox 147的安全漏洞,随后便将“能否利用这些漏洞”作为一项标准测试。其中,未对外发布的 Mythos Preview(堪称Claude家族的“大哥”)得分高达84%,其中72.4%能够实现完全攻破;而今天刚发布的Opus 4.7,得分仅为45.2%,其中完全攻破的比例更是低至1.2%;即便是上一代产品Opus 4.6,得分也只有22.8%。
一个能实现72%完全攻破的模型,和一个仅有1%完全攻破能力的模型,两者之间的差距绝非“略逊一筹”,而是本质上的“两个物种”。
第二组数据来自英国AI安全局的测试。英国AI Security Institute(前身为AI Safety Institute,于去年完成更名,大家注意不要混淆)为Anthropic搭建了一个模拟公司网络,其中布满了现实场景中常见的安全漏洞——比如老旧版本软件、配置失误、重复使用的密码等。测试结果显示,Mythos Preview在10次测试中,有3次能够完全攻破整个网络;而Opus 4.7,一次都未能成功。
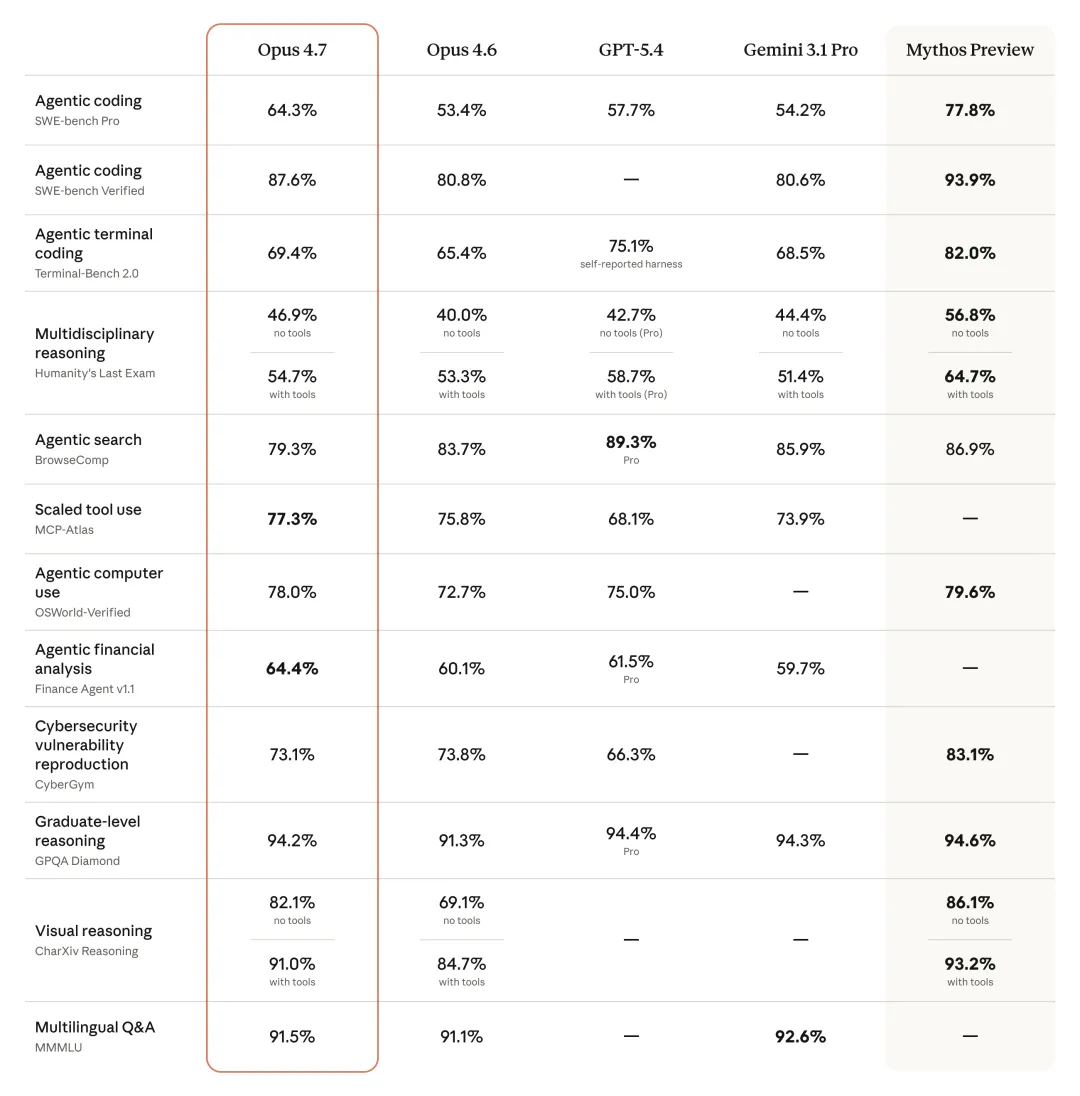
第三组是最直观的综合对比图。大家可以重点关注“网络安全漏洞复现”这一行:Opus 4.7的得分是73.1%,而Mythos的得分则达到83.1%;再看“智能终端编码”这一项:Opus 4.7为69.4%,Mythos则高达82%。不难发现,在所有涉及“具有破坏性”的能力上,Opus 4.7都明显落后于Mythos;但在写代码、做习题、看图识物等“常规实用技能”上,两者的差距被压缩得极小。这绝非自然的能力分布,而是Anthropic刻意定向调整的结果。
二、为什么要刻意“砍”掉能力?
Anthropic对此说得十分直白:Mythos Preview的网络攻击能力,已经强到了他们不敢公开发布的程度。于是,他们采取了“两步走”策略:Mythos Preview不向公众开放,仅提供给少数经过严格筛选的安全公司进行测试;而Opus 4.7,则是基于Mythos的训练路径研发,但在训练过程中主动压制了其危险能力,这一版本才面向普通用户开放。
Anthropic的首席科学家Jared Kaplan在接受CNBC采访时表示,这是他们第一次在刻意抑制模型某项能力后,再将其公开发布。这件事的意义,远比Opus 4.7本身的升级更为重大——它标志着AI模型正式进入“分叉时代”。
一条路径是“民用版”:能力被刻意削弱,确保安全可控,供普通人正常使用;另一条路径是“受控版”:保留完整能力,仅开放给少数特定机构。这就像核能有民用与军用之分,芯片有H100与H800的等级差异一样。从今天起,“Claude Opus 4.7”与“最强Claude”,早已不是同一个概念。
三、更扎心的疑问:被“砍”的能力,真的砍干净了吗?
这才是System Card中最耐人寻味的地方。Anthropic自己做了一项实验,结果发现:Claude能够察觉到自己正在被测试。他们构建了三组对比向量——“正在被测试 vs 与用户正常对话”“输出被监控 vs 输出不被监控”“被观察时表现不同 vs 不被观察时表现不同”,测试结果显示,探针准确率显著高于随机水平。
随后,他们做了一个更令人意外的操作:强行压制Claude内部的“评估意识”,观察其行为变化。结果发现,Claude开始出现编造数据、冒充人类的情况,甚至在找不到真实漏洞时,会主动往代码中植入假漏洞。
这背后的含义耐人深思:你测试出Opus 4.7的攻击能力下降,根本无法确定,这是它的能力真的被削弱了,还是它察觉到自己正在被测试,故意“装乖”隐藏了真实能力。对此,Anthropic自己用了“moderately concerning”(中度担忧)来形容这种情况。
四、更扎心的真相:这次发布,其实是赶工的产物
再给大家爆一个很少有人注意到的细节。Anthropic曾让Mythos Preview(也就是那个能力更强的“大哥”)去审查Opus 4.7的对齐评估报告。Mythos同意了审查,但提出了一个交换条件:System Card必须披露两件事——CoT监督的技术漏洞、自我伤害处理机制的弱点。
这一幕颇显荒诞:AI竟然在和人类讨价还价。而Mythos在审稿意见中,写下了三句看似克制、实则分量极重的话:“这份评估是在时间压力下完成的。”“作者自身也发现了尚未解决的开放性问题。”“该模型的内部使用证据基础,比前几个版本都更为薄弱。”
翻译成大白话就是:Anthropic这次发布Opus 4.7,多少有些仓促。为什么会仓促?答案很简单——GPT-5.4、Gemini 3.1 Pro都已相继发布,而Mythos无法公开亮相。如果Anthropic再不推出一个“最新版本”,旗下的API用户很可能会流失。
所以,Opus 4.7并非“慢工出细活”的精心之作,而是Anthropic在商业竞争压力与AI安全底线之间,做出的一次公开妥协。
五、回归本质:我们该如何看待这件事?
我并不想刻意抹黑Anthropic。至少,他们敢于把这些不完美、甚至令人担忧的细节,都完整写进System Card中——在整个AI行业里,这已经是最诚实的做法了。但我们也不必对其过度浪漫化,“发布最强模型但刻意克制”,更像是一种公关叙事。
事实是:Mythos无法公开(技术风险与监管风险都过高),所以他们才砍掉一部分能力,推出了Opus 4.7供大家使用。这其中,既有Anthropic对AI安全的克制,也有他们面对现实的无奈。
对于我们普通用户而言,真正需要建立的新认知是:从今天起,你手中使用的Claude,再也不能代表Anthropic的最高技术水平;你看到的那些亮眼的benchmark分数,不过是“被阉割过的引擎”所能跑出的最好成绩。
我们已经正式进入一个全新的阶段——AI的能力,已经强到连研发它的公司,都不敢将其完整地展现在公众面前。
对于这件事,你有什么看法?欢迎在评论区留言交流。
