 夜雨聆风
夜雨聆风用一次杭州旅行规划,带你搞懂 Token 计费的门道
引言
你有没有想过,为什么让 AI 帮你规划一次杭州旅行,有时候只要几分钱,有时候却要几块钱?
同样是问问题,为什么"输出"比"输入"贵 3-5 倍?
今天,我们就用"规划杭州三日游"这个例子,带你彻底搞懂 AI Agent 背后的算力消耗和计费原理。看完这篇,你不仅能明白钱花在哪了,还能学会怎么省钱。
一、Token 是什么?先搞懂计费单位
1.1 Token ≠ 字数
很多人以为 AI 是按"字"收费的,其实不是。AI 用的是 Token。
简单理解:
- 1 个 Token ≈ 1.5 个汉字(中文)
- 1 个 Token ≈ 0.75 个单词(英文)
比如你输入:"帮我规划杭州三日游"
- 汉字:9 个
- Token:约 6-7 个
AI 回复了一大段行程建议,500字:
- 汉字:500 个
- Token:约 330 个
1.2 三种 Token,三种价格
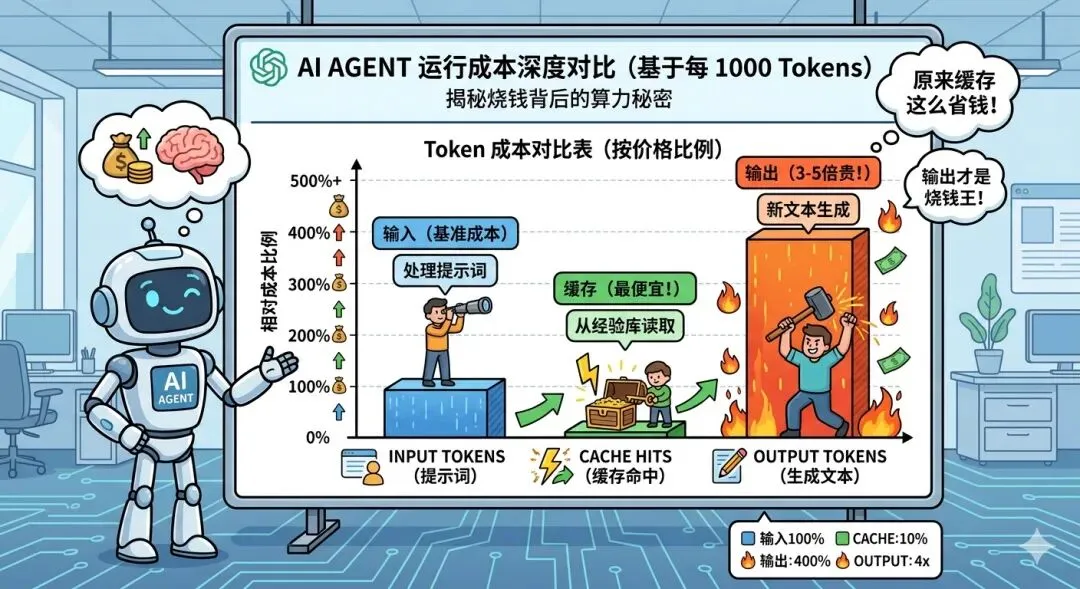
现在主流的 AI 服务(比如OpenAi、Claude、DeepSeek 等),把 Token 分成三类:
| Token 类型 | 价格(元/百万 Token) | 说明 |
|---|---|---|
| Input Token | 0.5-2 元 | 你输入的内容 |
| Output Token | 2-8 元 | AI 生成的内容 |
| Cache Token | 0.05-0.2 元 | 复用缓存的内容 |
看到没?Output 比 Input 贵 3-5 倍,Cache 最便宜。
为什么?继续往下看。
二、Transformer 架构:AI 的"大脑"怎么工作
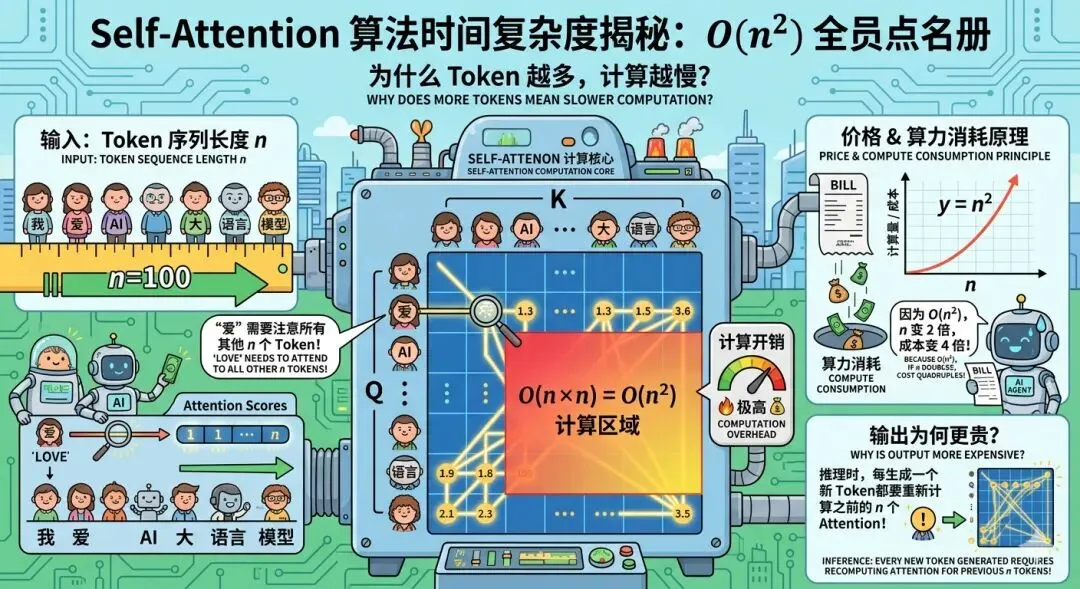
2.1 Self-Attention 的 O(n²) 复杂度
要理解为什么 Output 更贵,得先看看 AI 的"大脑"——Transformer 架构是怎么工作的。
核心机制叫 Self-Attention(自注意力)。
打个比方:
你在规划杭州旅行时,每想到一个景点,都要回忆之前提到的所有信息:
- "我说了喜欢历史文化"
- "我预算 3000 元"
- "我不喜欢太挤的地方"
>
每新增一个想法,你都要和之前所有想法做一次关联。
AI 也是一样。处理每个 Token 时,它要和之前所有 Token做注意力计算。
数学表达:
- 处理 1 个 Token:需要和之前 1 个 Token 关联
- 处理 10 个 Token:需要和之前 10 个 Token 关联
- 处理 n 个 Token:复杂度是 O(n²)
2.2 输入 vs 输出:计算量的天壤之别
Input Token(你输入的内容):
- AI 可以批量处理
- 一次性读入,并行计算
- 相当于"阅读理解",只需要理解
Output Token(AI 生成的内容):
- 必须逐个生成
- 生成第 1 个字 → 计算 → 生成第 2 个字 → 再计算...
- 每生成 1 个字,都要重新做一遍 Self-Attention
- 相当于"写作创作",需要理解 + 推理 + 生成
这就是为什么 Output 比 Input 贵 3-5 倍:计算量完全不是一个量级。
三、模型参数共享:Wq/Wk/Wv 不是每个 Token 独立
3.1 权重矩阵是"共享"的
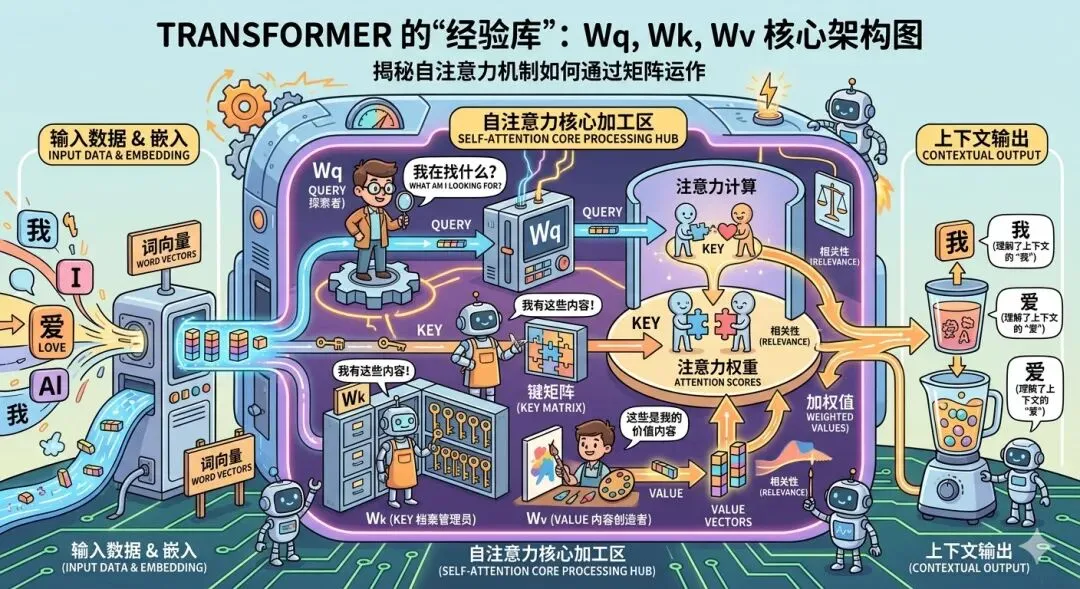
很多人有个误解:以为每个 Token 都需要独立的计算资源。
其实不是。Transformer 的核心参数(Wq、Wk、Wv 这些权重矩阵)是所有 Token 共享的。
继续用杭州旅行举例:
你有一个"旅行规划经验库"(这就是模型参数)
- 不管规划杭州、北京、还是巴黎
- 不管规划 1 天、3 天、还是 7 天
- 用的都是同一套经验库
Wq(Query)、Wk(Key)、Wv(Value)就是这套"经验库"的核心部分。
3.2 那为什么还这么贵?
既然参数是共享的,为什么计算还这么贵?
因为:
- 显存占用大:模型参数本身很大(比如 Qwen3.5 有几百亿参数),需要高端 GPU
- 计算密集:每次生成都要做矩阵乘法,GPU 要满负荷运转
- 不能跳过:生成 Output 时,每一步计算都必须实时完成,没法偷懒
所以,贵的不是"参数本身",而是运行参数所需的算力。
四、Cache Token:最省钱的秘密武器
4.1 什么是 Cache?
Cache Token 是最便宜的,只要 Input 价格的 1/10 左右。
原理很简单:
如果你多次问类似的问题,AI 可以把之前的计算结果缓存起来。
>
比如你已经告诉 AI:"我喜欢历史文化,预算 3000 元"
>
下次再问杭州相关的问题,这部分信息可以直接从缓存读取,不用重新计算。
4.2 实际场景:杭州旅行规划
不使用 Cache:
第一次:帮我规划杭州三日游(Input: 50 Token)
AI 回复:详细行程...(Output: 500 Token)
费用:50×0.002 + 500×0.008 = 0.1 + 4 = 4.1 元
第二次:那第一天具体怎么玩?(Input: 50 Token)
AI 回复:详细安排...(Output: 500 Token)
费用:50×0.002 + 500×0.008 = 4.1 元
总计:8.2 元使用 Cache:
第一次:帮我规划杭州三日游(Input: 50 Token,Cache: 0)
AI 回复:详细行程...(Output: 500 Token)
费用:50×0.002 + 500×0.008 = 4.1 元
第二次:那第一天具体怎么玩?(Input: 50 Token,Cache: 300 Token 复用)
AI 回复:详细安排...(Output: 500 Token)
费用:50×0.002 + 300×0.0001 + 500×0.008 = 0.1 + 0.03 + 4 = 4.13 元
等等...好像没省多少?真正省钱的用法:
当你的"系统提示词"很长时(比如几千字的公司文档、产品手册),开启 Cache 后:
- 第一次:正常付费
- 后续每次:长文档部分走 Cache,价格降到 1/10
对于高频调用的 AI Agent,Cache 可以节省 50%-80% 的成本。
五、实际成本对比:帮你算笔账
5.1 不同场景的成本
| 场景 | Input Token | Output Token | 总费用(元) |
|---|---|---|---|
| 简单问答(今天杭州天气?) | 20 | 50 | 0.44 |
| 中等任务(杭州三日游规划) | 200 | 800 | 6.8 |
| 复杂任务(带预算、偏好的详细行程) | 500 | 2000 | 17 |
| 长文档分析(10 万字文档摘要) | 60000 | 1000 | 128 |
注:按 Input 0.002 元/千 Token,Output 0.008 元/千 Token 计算
5.2 优化建议:怎么省钱?
1. 精简 Input
- 去掉废话,直接说重点
- 能用短句,不用长段落
2. 控制 Output
- 明确告诉 AI:"用 200字总结"
- 避免"请详细说明"这类开放式要求
3. 善用 Cache
- 固定信息(如公司文档、产品手册)开启缓存
- 多轮对话时,让 AI 记住上下文
4. 批量处理
- 能一次问完的,别分多次
- 减少重复的"系统提示词"
5. 选择合适模型
- 简单任务用小模型(便宜 10 倍以上)
- 复杂任务再用大模型
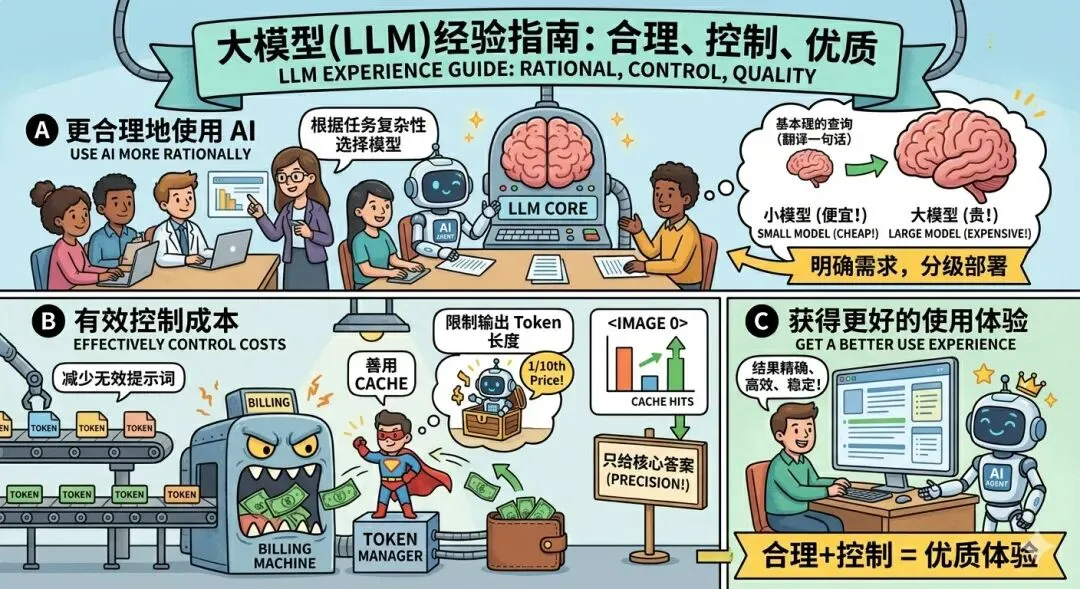
六、总结:理解原理,理性消费
AI Agent 的计费原理,核心就三点:
- Output 比 Input 贵:因为生成比理解更难,计算量是 O(n²)
- 参数是共享的:Wq/Wk/Wv 不是每个 Token 独立,但算力成本依然高
- Cache 最省钱:复用缓存可以大幅降低成本
下次用 AI 时,你可以这样想:
"我让 AI 规划杭州旅行,它每生成一个字,都要在'大脑'里把之前所有信息重新过一遍。这确实挺费电的,贵点也合理。"
理解了这些,你就能:
- 更合理地使用 AI
- 有效控制成本
- 获得更好的使用体验
觉得有用?欢迎分享给更多朋友!
有问题也可以在评论区留言,我会尽量解答。
