 夜雨聆风
夜雨聆风这篇文章不讲复杂的代码,只讲一件事——当 AI 真的能理解患者、记住患者、陪伴患者,你和团队的工作会被怎么重新改写。
患者运营最真实的日常——患者的事情永远在发生,而人永远只有两只手。传统运营逻辑是"人去找事":运营从一堆消息、一张张表格里筛出真正重要的,再去响应。但患者的健康问题不会排队等你,有些信号如果漏掉,代价可能是生命。
本文要讲的,正是如何让这套逻辑反转过来——让 AI 作为一个"懂业务的助手",把"人找事"变成"事找人":真正需要运营介入的事情,AI 整理好、分级好、文档写好、该提醒谁提醒谁,人只需要做判断和盖章。
一、患者管理到底在管什么?先把场景拉清楚
讨论 AI 怎么帮忙之前,先把"患者管理"这四个字拆开看。不同患者类型、不同业务阶段,需要的管理动作完全不同。在一个典型的医药服务项目里,至少覆盖这么几类场景:
场景 A:肿瘤患者的不良反应识别与评估患者用药后出现不适——"恶心"、"掉头发"、"恶心"、"皮疹"。这些症状有的是药物已知的副作用,有的可能是别的原因,有的需要立即就医。每一种情况对应的处理动作完全不同:轻度反应只需要安抚和观察,中度反应需要推送评估量表并给出处理意见,重度反应必须立即升级到医生和 PV 团队。
场景 B:入组与随访问卷 患者入组、每次复诊、定期随访都要填大量问卷——用药史、既往病史、过敏情况、家庭情况、……这些问卷少则几十题、多则上百题,条件跳题逻辑复杂("如果选 A 就问 B,选 C 就跳到 D"),患者看见就头大,运营追着填也累。
场景 C:慢病患者的长期管理 糖尿病、高血压这类患者,管理周期以"年"为单位。运营需要按血糖达标情况、用药依从性、BMI、生活习惯等组合给患者打标签,然后按标签生成个性化的日计划、周计划、月计划——什么时候提醒测血糖、什么时候推送饮食建议、什么时候做总结报告。一个运营人员对接几千上万患者,根本不可能手动安排。
场景 D:运营人员自己的文档工作 这是最容易被忽视的场景,但恰恰是最消耗时间的。从患者对话里提取出"这是一个严重不良反应"之后,运营还要把事件补全成标准的个案安全报告——也就是药物警戒领域俗称的"PV 文档"。这类文档格式极其规范(不同国家/地区要求不同:CIOMS 表、E2B(R3) XML、MedWatch 表等),涉及患者人口学信息、用药信息、症状描述、时间线、转归、严重性判定、因果关系评估等十几个字段,一份完整的病例叙述平均要写 1-2 小时。
上面这四个场景,看起来业务差别很大,但本质上都需要同一套底层能力:持续理解患者说了什么、记住患者曾经怎么样、判断现在要做什么、把结果留成可以追溯的记录。这正是 AI 能发挥最大价值的地方。
二、"懂患者"的 AI,到底在懂什么?
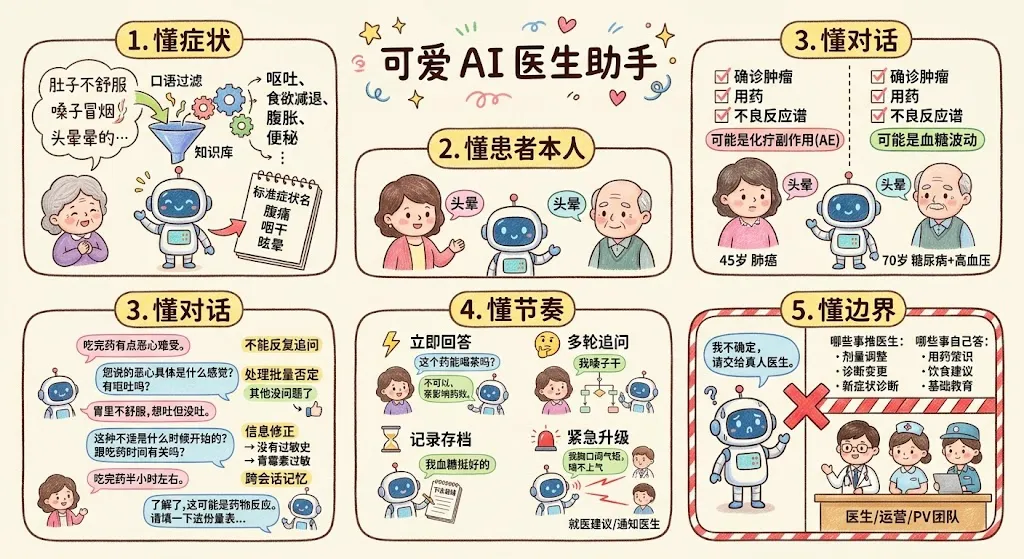
很多人听到"AI 患者管理",第一反应是"一个会聊天的机器人"。这个理解只对了 10%。真正有用的 AI 助手,必须同时做到下面五件事——
1. 懂症状(不要被表达误导)
患者描述症状的方式五花八门:
"我肚子不舒服" "我嗓子冒烟了" "吃完药以后头晕晕的" "前几天血糖高,现在正常了,但昨天开始恶心夜里吐了,今天没胃口肚子胀打屁少也没大便,怎么办?"
上面这些话,有的只是不精准的口语化表达("嗓子冒烟"其实就是咽干),有的是隐藏了多重症状的长句(最后一条里至少藏了"头晕、呕吐、食欲减退、腹胀、便秘"五个信号),有的还夹带着时间关系("前几天……昨天开始……今天"——需要 AI 拆出时间线)。
一个合格的患者管理 AI,第一件事就是要能突破固定话术的限制,从患者口语化、片段化、甚至文不对题的描述里,拆出真正的症状信号,并把它对应到医学知识库里的标准症状名。
2. 懂患者本人(个性化判断)
同样是"头晕",出现在一位 45 岁的肺癌患者身上、和出现在一位 70 岁的糖尿病合并高血压患者身上,含义完全不同。前者可能是化疗药物的常见不良反应,后者可能是血压或血糖波动。
这就要求 AI 在回答之前,先把这个患者"是谁"搞清楚——基础信息、既往病史、当前用药、过去的对话总结、最近的指标趋势。这些信息散落在各个业务系统里,AI 要能把它们拼起来,当成判断的依据。
举一个具体规则:要判断一个患者的主诉"是否可能是肿瘤用药的不良反应",至少要同时满足三个前置条件——患者确实确诊了肿瘤(从门诊病历、出院报告、病理诊断等多个字段里找)、患者确实在用肿瘤相关药物(化疗、靶向、免疫、内分泌类的任一一种)、症状确实在该药物的不良反应谱里。三个条件任何一个没满足,AI 就不应该推送不良反应量表,而应该换个处理路径(比如建议就医、或者请患者先补充信息)。
这种"多条件判断 + 知识库查询"的能力,才是"懂患者"的核心。
3. 懂对话(多轮追问与记忆)
症状识别很少是一句话能说清的。看下面这个典型对话:
患者:吃完有点恶心难受。
AI:您说的恶心具体是什么感觉?有没有呕吐?
患者:就是胃里不舒服,想吐但没吐出来。
AI:这种不适是什么时候开始的?跟吃药时间有关系吗?
患者:吃完药半小时左右开始的。
AI:了解了,这可能是您正在用的药物引起的恶心反应。
为了准确评估严重程度,请帮忙填一下这份量表……
AI 在每一轮对话里都要做三件事:理解本轮说了什么 → 决定下一轮问什么 → 判断是否已经问够了。
有几个细节决定了体验好坏:
- 不能反复追问同一件事
。如果同一症状 3 轮对话内问过了,就不能再问第 4 次——患者会烦; - 要能处理批量否定
。患者说"其他没问题了",AI 应该理解成"除了刚才提到的,所有剩余症状都是否定",而不是一个个再问一遍; - 要能处理信息冲突
。患者第一次说"没有过敏史",后来又说"我对青霉素过敏",AI 要能意识到这是信息修正,把前一次答案自动更新,而不是保留两条矛盾记录; - 要能跨会话记忆
。患者今天说过的话,明天进来 AI 得记得。而不是每次从零开始。
4. 懂节奏(不是所有事都马上回答)
不同的患者问题,处理节奏完全不同。
问"这个药能和茶一起喝吗?"——立即回答; 问"我吃完药嗓子有点干"——启动多轮追问,判断不良反应类型; 说"我胸口闷气短,喘不上气"——追问,可能触发严重反应处理流程,推送就医建议,同时通知运营和医生; 说"我最近血糖都挺好的"——不需要立即处理,记录下来,在下次定期总结时用。
AI 要能根据信息的紧急程度、是否需要人工介入、是否需要文档留痕,选择不同的处理节奏。该快的时候秒回,该慢的时候留到合适的时间再推送,该叫人的时候必须叫人。
5. 懂边界(不确定的事不硬答)
最容易出事故的,是 AI 不知道"自己不知道"。
一个成熟的患者管理 AI,必须有明确的能力边界——哪些问题可以自己回答(用药常识、饮食建议、基础疾病教育),哪些问题必须推给医生(剂量调整、诊断变更、新症状诊断),哪些问题需要升级给运营或 PV 团队处理(严重不良反应、超出已知反应范围的症状、法规要求必须上报的事件)。
当遇到不确定的情况,AI 的默认动作应该是:降低自己的置信度,把判断权交回给真人。
三、主动出击:定时关怀不是定时推送
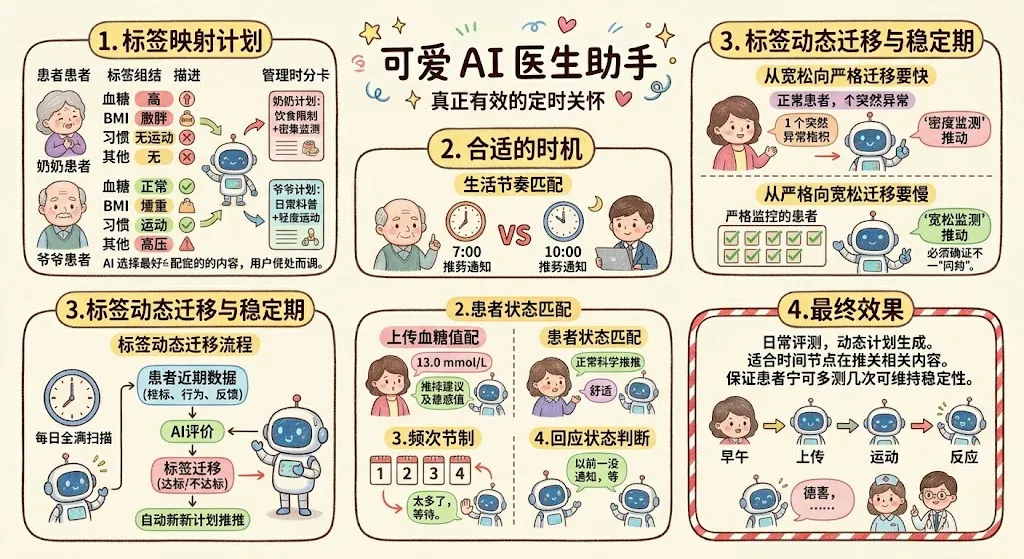
讲完了被动响应,我们来讲主动——也就是通常说的"定时关怀"。
很多人对定时关怀的理解停留在"每天发一条关心消息"。这其实是最低级的做法,甚至会起反作用——千人一面的消息推多了,患者要么麻木,要么拉黑。
真正有效的定时关怀,是根据患者当前的标签组合,动态生成匹配该标签的计划,并在合适的时间节点触发匹配该计划的内容。这里有三个关键词:标签组合、动态生成、合适节点。
从标签到计划:一张映射表说清楚
以糖尿病患者为例,AI 要根据患者的几个核心标签(血糖、BMI 分类、生活习惯、是否合并其他疾病级)组合出一套专属的管理计划。计划包含临床指南 + 真实世界数据 + 历史运营经验的综合沉淀。AI 做的事,是在恰当的时机,把匹配患者当前标签的最合适的那条内容,用患者愿意看的语气推出去。
"合适的时机":不仅仅是时间
合适的时机不只是"早上 7 点"这么简单。它包含几层含义:
- 生活节奏匹配
——早睡早起的大爷和熬夜打工人的推送时间不能一样; - 患者状态匹配
——刚刚上传了血糖值、显示值很高,这时候推送的就不应该是常规科普,而应该是针对性的建议和安抚; - 频次节制
——同一患者一上午收到 5 条提醒,第 6 条他不会再看; - 回应状态判断
——上一条推送患者没回复,再推新的意义不大,应该先等等。
"标签是会变的":别把患者钉死在一个分类里
这是最容易忽视的点。
一个患者刚入组时血糖可能不达标,但连续坚持 一段时间后血糖稳定了——他的标签就应该转为"达标",后续的提醒频率也应该对应降低。反过来,一个达标患者如果某天指标突然大幅波动,也应该立即切换到更密集的监测节奏。
AI 需要做的是——每天一次全量扫描所有患者,根据他们近期的指标、行为、反馈,重新评估标签是否需要迁移。迁移一旦发生,下一轮推送就自动按新计划来。这套机制让运营不需要手动"调档",系统自己会随患者状态流动而调整。
但这里有个小技巧:标签切换要有稳定期。不然一次偶然的高血糖就把患者从"达标"甩到"不达标",推送频率立提升——患者体验会非常抖动。通常的做法是,从宽松档向严格档迁移要快(只要一次异常就触发,医疗场景宁可多测几次),从严格档向宽松档迁移要慢(要连续 10天达标才算数,确保不是昙花一现)。
四、AI 协助运营人员的三类典型场景
到此为止我们讨论的都是"AI 对患者"。接下来讲一个更大、也更容易被忽视的价值空间:AI 对运营。
在真实项目里,AI 能帮运营减轻的工作,远远不止"替你回答患者问题"这一件。下面是三个最值得挖掘的场景。
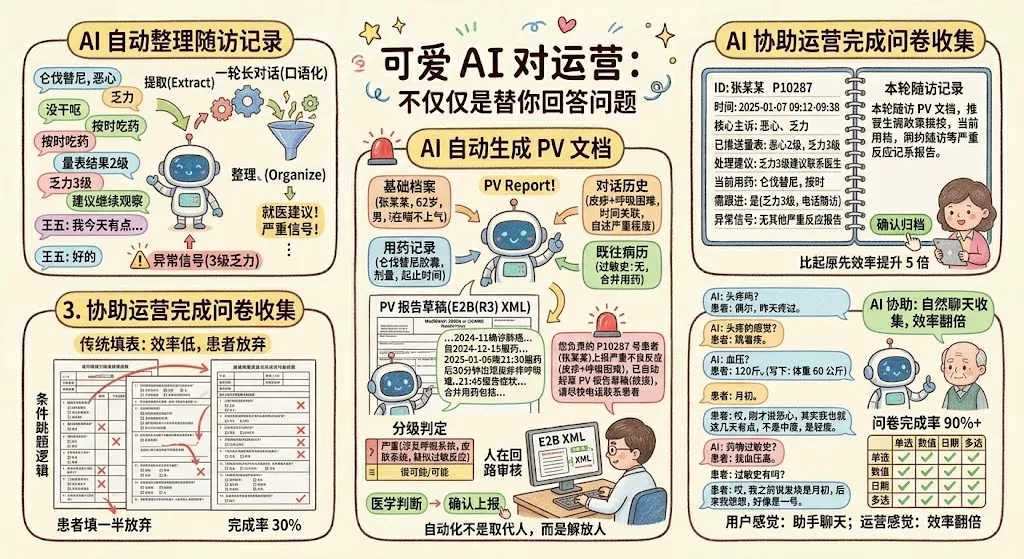
场景一:AI 自动整理对话,生成结构化随访记录
患者一轮对话可能包含 20 条消息。传统做法是,运营在一天结束时,打开每个患者的对话窗口,手动摘要:"今天患者反馈了恶心、乏力;已推送乏力量表评估为 2 级;建议继续观察。"一位运营带 500 个活跃患者,这件事一天就是 2-3 小时。
AI 可以做的是:在每一轮对话结束后(患者主动关闭、或长时间未回复),自动生成该轮对话总结,结构化存入患者档案。总结的模板大致是:
本轮对话总结(自动生成,待运营审核)
患者姓名/ID:张某某 / P10287 对话时间:2025-01-07 09:12 - 09:38(历时 26 分钟) 核心主诉:服药后恶心、乏力 已推送量表:恶心量表(结果 2 级)、乏力量表(结果 3 级) 处理意见已推送:乏力 3 级处理建议——及时联系主管医生,配合相关检查,遵医嘱用药 患者当前用药确认:甲磺酸仑伐替尼胶囊(按时服用) 需运营跟进:是(乏力已达 3 级,建议电话随访) 本轮异常信号:无其他严重反应报告
运营打开后台,看到这样一份结构化摘要,确认无误即可归档;发现异常立刻跟进。比起原先逐条读消息,效率提升至少 5 倍。
场景二:AI 自动生成药物警戒文档(PV 文档),通知运营审核
这是所有运营场景里,AI 能带来价值最大的一个,也是医药行业当前最前沿的自动化方向。
根据法规要求,凡是发生严重不良反应的个案,申办方必须在严格的时限内(一般是 15 天)完成个案安全报告(ICSR)的起草和上报。这份报告要符合国际规范的结构(CIOMS I 表格、E2B(R3) XML、MedWatch 3500A 等),涵盖一堆字段:
报告人信息、患者人口学信息 可疑药物信息(通用名、商品名、剂量、给药途径、用药起止时间) 合并用药信息、既往病史 不良事件描述(症状、发生时间、持续时间、转归) 严重性判定(导致死亡?危及生命?住院?) 因果关系评估 病例叙述(Case Narrative,通常 500-1500 字的标准化事件描述)
过去这件事完全靠 PV 专员手工完成,一份完整报告平均耗时 1-2 小时,复杂病例要 4 小时以上。根据行业调研,引入基于大模型的自动化流程后,报告起草时间可以从数天压缩到数小时——源文件进入后,AI 直接提取关键字段、填充结构化表格、撰写病例叙述、跑完校验规则,最终只留给 PV 专员审核和定稿。
实际工作流大概长这样:
① 触发 → 患者对话中出现严重信号(示例:"我服药后全身起疹子,现在喘不上气")。AI 识别到这是严重不良反应(涉及呼吸系统、皮肤系统、疑似过敏反应),立即把这条消息标记为"待 PV 报告",同时推送就医建议给患者。
② 信息提取 → AI 从该患者的所有资料里自动抽取 PV 报告需要的字段:
从基础信息拿姓名、性别、年龄 从用药记录拿当前在用的所有药品(含通用名、剂量、给药方式、起止日期) 从对话历史拿症状描述、时间关联、患者自述的严重程度 从既往病历拿合并疾病、过敏史
③ 病例叙述起草 → AI 根据抽取出来的信息,按照业内通用的病例叙述规范起草一段文本。这段文本有明确的写作规范:用过去时、按时间顺序、包含 "五要素"(Who/What/When/Where/Outcome)、不做因果判断性结论。示例:
"患者为 62 岁男性,2024 年 11 月确诊非小细胞肺癌,自 2024-12-15 开始服用某靶向药物,每日 1 次、每次 1 粒。2025-01-06 晚 21:30 左右,患者首次服药后约 30 分钟出现全身散在性皮疹伴呼吸困难,无伴随恶心、呕吐。患者于 21:45 在随访对话中主动报告了上述症状。截至报告时,患者已被建议立即前往附近急诊就诊,转归未定。患者既往无药物过敏史记录,合并用药包括……"
④ 分级判定 → AI 根据 ICH E2D 和 CTCAE 标准对事件进行严重性分级(危及生命?住院?导致死亡?永久性残疾?),并给出初步因果关系判定(很可能/可能/不太可能/无关),给 PV 专员提供判断参考。这一步 AI 只做建议,最终定性权永远在 PV 专员手上——这是行业法规和伦理的硬性要求。
⑤ 通知运营/PV → 整份文档起草完成后,AI 做两件事:
把 PV 文档草稿推送到 PV 专员的工作台,并附带原始对话链接、患者完整档案链接作为溯源; 同时给负责该患者的运营发一条即时消息:"您负责的 P10287 号患者(张某某)刚刚上报了疑似严重不良反应(皮疹 + 呼吸困难),已自动起草 PV 报告草稿(链接),请尽快电话联系患者确认情况。"
⑥ 人工审核 + 提交 → PV 专员打开草稿,对照原始对话做核对,必要时补充细节,修改完毕后点击"确认上报"。AI 负责把报告转换成符合法规的 E2B(R3) XML 或 CIOMS 表格格式。
这整个流程里,AI 负责的是 80% 的机械搬运和起草工作,人负责的是 20% 的医学判断和最终责任——这正是当前行业公认的最合理的人机协作边界。CIOMS 第 XIV 工作组(AI 在药物警戒中的应用)明确强调:AI 系统必须保持 "人在回路" 的设计原则,任何具有法规意义的决策都必须由人做最终判断。自动化不是要取代 PV 专员,而是把他们从"当文字秘书"的低价值劳动里解放出来,专注于真正需要专业判断的部分。
场景三:AI 协助运营完成问卷收集
赠药项目的入组问卷、慢病管理的基线问卷、定期随访问卷——这些表单动辄几十上百题,条件跳题逻辑复杂。过去的做法是:把问卷发给患者,患者填一半就放弃,运营再打电话追着问。
AI 可以把这件事完全变成一场结构化的自然对话:不再是"填表",而是"聊天"。
工作方式大致是:
- 单选题、多选题
——患者用自然语言作答("我选 A"、"第二个吧"、"没有"),AI 自动对应到正确选项; - 数值题 + 单位换算
——患者说"120 斤",AI 自动识别并换算成 60 公斤填入; - 日期题 + 模糊推断
——患者说"月初",AI 推断为当月第一天;说"去年六月",AI 推断为上年 6 月 15 日(如不确定则反问确认); - 一次多答
——患者一句话提供了多个问题的信息("我头疼、恶心、发烧,没有其他了"),AI 一次性填写所有相关题目,同时对未提及的同类题目按"无"批量填写; - 答非所问处理
——针对"请描述头痛特点"的问题,患者回答了"我血压有点高",AI 先记录血压信息到对应题目,再重新询问头痛题; - 修改答案
——患者说"我刚才说轻度,其实是中度",AI 自动更新之前的答案; - 条件跳题
——患者回答"没有过敏史",AI 自动跳过后续的过敏详情题; - 依赖链冲突处理
——患者之前说"是"后面又改成"否",AI 自动清理掉依赖前一个答案的所有子问题的回答。
这里最妙的是,患者本人根本不知道自己"在填表"。他感觉自己只是在和一个助手聊天,聊着聊着问卷就完成了。而对运营来说,问卷完成率从 30-40% 提升到 80-90% 是完全可期的,追问跟进工作量大幅减少。
五、AI 助手和运营的新分工:谁管什么?
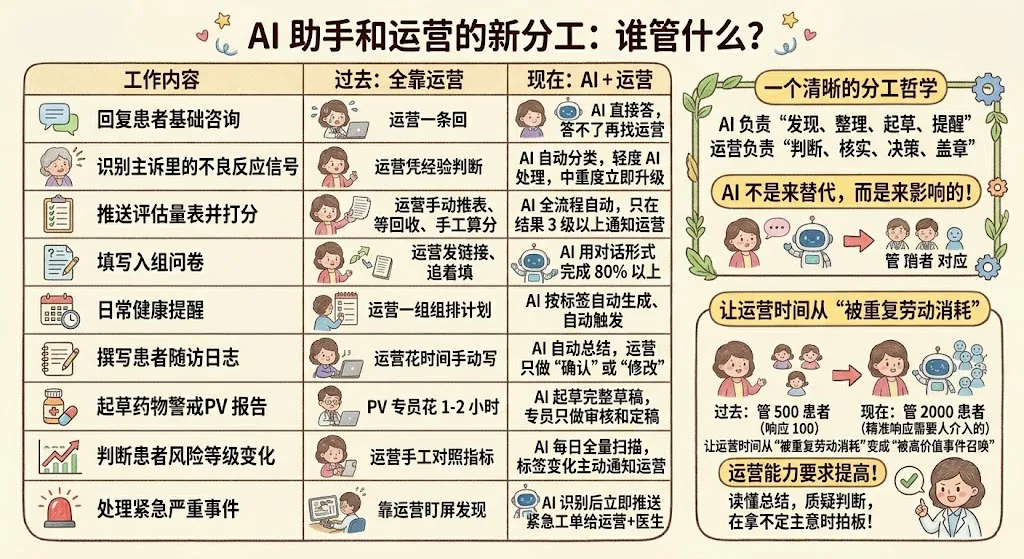
把前面的场景拼起来,我们可以画一张更清晰的人机分工表:
可以看到一个清晰的分工哲学:AI 负责"发现、整理、起草、提醒",运营负责"判断、核实、决策、盖章"。
这里特别要强调一点:AI 不是来替代运营的,而是来放大运营的影响力的。过去一个运营能 "管" 500 个患者(实际能及时响应的可能只有 100 个),现在有了 AI 分担基础工作,同一个运营可以 "看到" 2000 个患者里所有真正需要人介入的那些。你的时间从"被重复劳动消耗"变成"被高价值事件召唤"。这对运营个人能力的要求不是降低,反而是提高了——你要能读懂 AI 的总结、质疑它的判断、在它拿不定主意时拍板。
六、技术的进步正把这件事推向新的节奏
让"AI 患者助手"能真正落地的,不是某一项技术的单独突破,而是过去一年里几个关键能力的同时成熟。这里面最值得关注的有三条趋势,对运营同学来说,不需要懂实现细节,但需要知道**"现在 AI 能做到什么程度了"**。
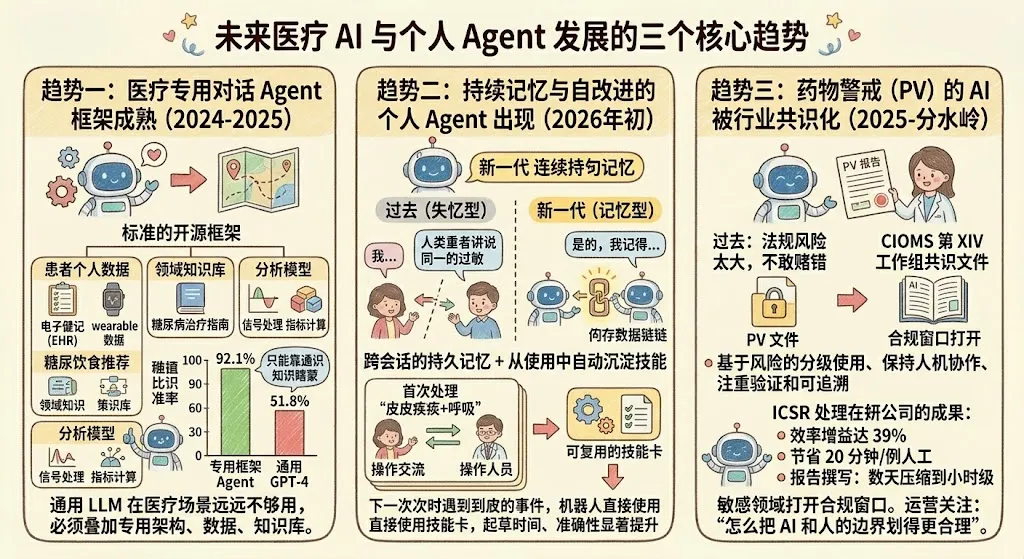
趋势一:医疗专用对话 agent 框架的成熟
2024 到 2025 年间,学术界和开源社区推出了若干专门面向医疗对话场景的 agent 框架。其中一个被广泛引用的代表性项目,把医疗对话 agent 的核心能力做成了标准化的开源框架——它能整合患者个人数据(电子病历、可穿戴设备数据)、领域知识库(比如糖尿病诊疗指南)、分析模型(信号处理、指标计算),通过一个"调度器"来协调多步推理。
在糖尿病饮食推荐的公开评测中,基于这套框架定制的 agent 准确率达到 92.1%,而直接使用 GPT-4 只有 51.8%——差距来源就是"专用框架有能力接入真实的患者数据和权威知识库,通用 LLM 只能靠通识知识瞎蒙"。
这给行业的启示非常直接:通用 LLM 在医疗场景远远不够用,必须叠加医疗专用的架构、数据接入、知识库、工具。过去两年很多项目走过弯路,就是太相信"大模型万能",忽视了医疗是个需要证据链的严肃领域。
趋势二:持续记忆与自改进的个人 agent 出现
2026 年初,开源社区出现了一批新一代的"持续记忆型 agent"。它们的核心特征是:跨会话的持久记忆 + 从使用中自动沉淀技能。
这对患者管理的意义在哪里?想象一下——过去的 AI 客服每次对话都是"失忆"的,你今天告诉它你对青霉素过敏,明天还得再说一遍。新一代 agent 可以持久记住每个患者的长期画像、对话偏好、历史问题,而且会从自己的每次处理中总结经验,把反复出现的工作流程沉淀成可复用的"技能"。
举个具体例子:第一次处理"皮疹 + 呼吸急促"类严重不良反应时,AI 可能要和运营多次来回才能把 PV 报告起草完整。但系统会把这次的完整处理路径记下来,形成一个可复用的技能。下次再遇到类似事件,直接走这条已经被验证过的路径——起草时间、准确性、字段覆盖度都会显著提升。同类任务越处理越熟,这是和传统软件最本质的区别。
趋势三:药物警戒的 AI 化被行业共识化
过去 AI 在 PV 领域的应用一直有争议——法规风险太大,谁都不敢赌错。但 2025 年是个分水岭:CIOMS 第 XIV 工作组正式发布了 AI 在药物警戒中的应用指导原则。这份文件系统性回答了"AI 在 PV 里哪些环节可以用、怎么用、怎么保证安全"的问题,把"基于风险的分级使用、保持人机协作、注重验证和可追溯"明确为行业共识。
在这份指导原则的背书下,一些先行企业已经把 AI 用到了 ICSR 处理的主流程里:有报道显示,通过 AI 自动化提取 + RPA 辅助,PV 报告撰写时间从数天压缩到小时级;试点研究显示 AI 做数据提取的效率增益达 39%,平均每例节省 20 分钟人工。
这一切意味着,运营同学过去看起来"这件事太敏感、AI 不敢碰"的领域,现在已经打开了合规的窗口。作为运营,你要关注的不是"要不要引入 AI",而是"怎么把 AI 和人的边界划得更合理"。
七、
趋势一:医疗专用对话 agent 框架的成熟
2024 到 2025 年间,学术界和开源社区推出了若干专门面向医疗对话场景的 agent 框架。其中一个被广泛引用的代表性项目,把医疗对话 agent 的核心能力做成了标准化的开源框架——它能整合患者个人数据(电子病历、可穿戴设备数据)、领域知识库(比如糖尿病诊疗指南)、分析模型(信号处理、指标计算),通过一个"调度器"来协调多步推理。
在糖尿病饮食推荐的公开评测中,基于这套框架定制的 agent 准确率达到 92.1%,而直接使用 GPT-4 只有 51.8%——差距来源就是"专用框架有能力接入真实的患者数据和权威知识库,通用 LLM 只能靠通识知识瞎蒙"。
这给行业的启示非常直接:通用 LLM 在医疗场景远远不够用,必须叠加医疗专用的架构、数据接入、知识库、工具。过去两年很多项目走过弯路,就是太相信"大模型万能",忽视了医疗是个需要证据链的严肃领域。
趋势二:持续记忆与自改进的个人 agent 出现
2026 年初,开源社区出现了一批新一代的"持续记忆型 agent"。它们的核心特征是:跨会话的持久记忆 + 从使用中自动沉淀技能。
这对患者管理的意义在哪里?想象一下——过去的 AI 客服每次对话都是"失忆"的,你今天告诉它你对青霉素过敏,明天还得再说一遍。新一代 agent 可以持久记住每个患者的长期画像、对话偏好、历史问题,而且会从自己的每次处理中总结经验,把反复出现的工作流程沉淀成可复用的"技能"。
举个具体例子:第一次处理"皮疹 + 呼吸急促"类严重不良反应时,AI 可能要和运营多次来回才能把 PV 报告起草完整。但系统会把这次的完整处理路径记下来,形成一个可复用的技能。下次再遇到类似事件,直接走这条已经被验证过的路径——起草时间、准确性、字段覆盖度都会显著提升。同类任务越处理越熟,这是和传统软件最本质的区别。
趋势三:药物警戒的 AI 化被行业共识化
过去 AI 在 PV 领域的应用一直有争议——法规风险太大,谁都不敢赌错。但 2025 年是个分水岭:CIOMS 第 XIV 工作组正式发布了 AI 在药物警戒中的应用指导原则。这份文件系统性回答了"AI 在 PV 里哪些环节可以用、怎么用、怎么保证安全"的问题,把"基于风险的分级使用、保持人机协作、注重验证和可追溯"明确为行业共识。
在这份指导原则的背书下,一些先行企业已经把 AI 用到了 ICSR 处理的主流程里:有报道显示,通过 AI 自动化提取 + RPA 辅助,PV 报告撰写时间从数天压缩到小时级;试点研究显示 AI 做数据提取的效率增益达 39%,平均每例节省 20 分钟人工。
这一切意味着,运营同学过去看起来"这件事太敏感、AI 不敢碰"的领域,现在已经打开了合规的窗口。作为运营,你要关注的不是"要不要引入 AI",而是"怎么把 AI 和人的边界划得更合理"。
七、一些常见疑问的坦诚回答
这部分的几个问题,是在和不同项目的运营、产品同学聊天时反复出现的。一并说清楚。
八、如果要启动这样一个项目,运营能做什么?
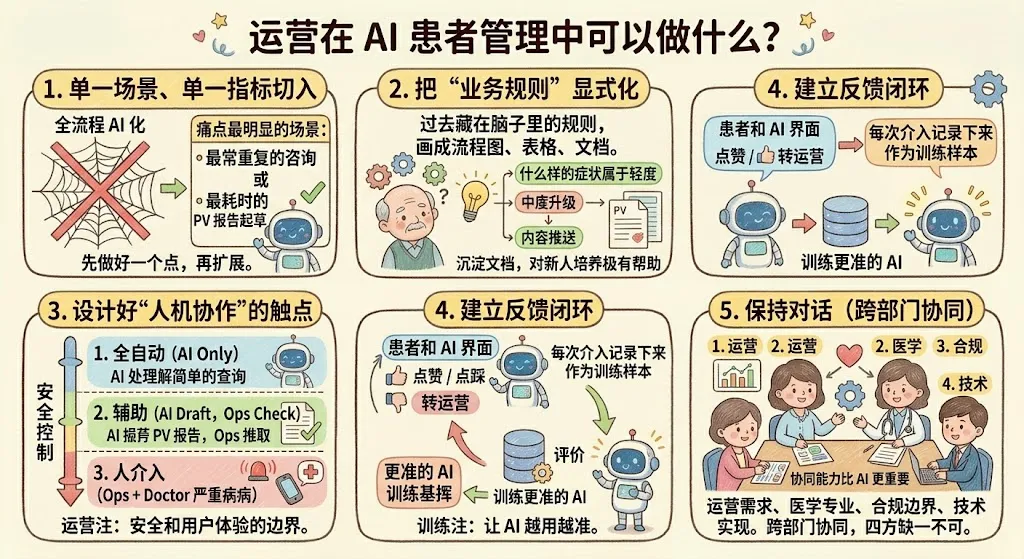
看到这里,你可能已经跃跃欲试。下面这几条建议,是从多个落地项目里总结出来的、运营侧能直接推动的事情:
1. 先从"单一场景、单一指标"切入。 不要一上来就想"全流程 AI 化"。选一个痛点最明显的场景试水——比如最常重复的一类咨询、或者最耗时的 PV 报告起草,先做好一个点,再扩展。
2. 花时间把"业务规则"显式化。 AI 能做事的前提,是你先把"运营是怎么做这件事"说清楚——什么样的症状属于轻度、什么情况必须升级、什么样的患者适合推什么内容。这些规则过去藏在老运营的脑子里,现在要把它们画成流程图、列成表格、沉淀成文档。这个过程本身就很有价值,即便不上 AI,对新人培养也极有帮助。
3. 设计好"人机协作"的触点。 AI 不可能一上来就完美,设计上要想好:哪些场景 AI 自动处理,哪些场景 AI 处理 + 通知人,哪些场景必须人介入 + AI 辅助。这三档的划分决定了整个系统的安全性和用户体验。
4. 建立反馈闭环,让 AI 越用越准。 AI 每次回复都应该有"点赞 / 点踩"、"转运营"这样的交互,运营的每次介入也应该被记录下来成为训练样本。没有反馈闭环的 AI 永远停在 "能用但不好用" 的阶段。
5. 和医学、合规、技术三方保持对话。 这件事永远不是一个部门能单独推动的。运营提需求、医学提专业、合规定边界、技术给实现,四方缺一不可。跨部门协同的能力,比 AI 本身更重要。
写在最后
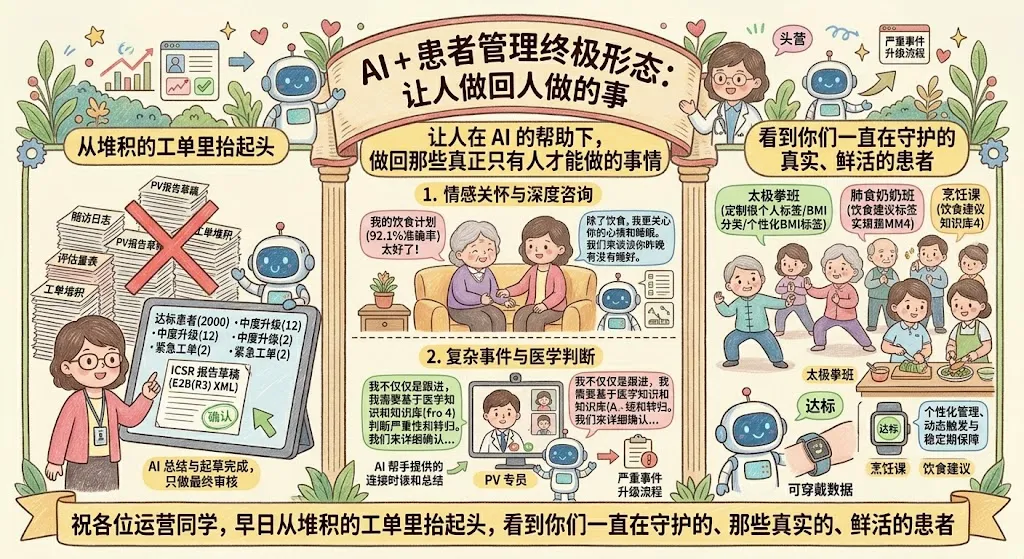
把时间拨回开头那个周一早上,再想一遍运营的故事。
同样是周一早上 9 点,但这次他面前的屏幕上已经摆好了昨天的事件分发图——
AI 已经处理完 82 条患者咨询里的 64 条,处理日志整理成结构化记录; 18 条需要运营跟进的事件按紧急程度排好序,第一条标着红色:P10287 号患者疑似严重不良反应,PV 报告初稿已起草,请优先审核; 9 位糖尿病患者的标签从"达标"自动迁移到"不达标",下一周的计划已自动更新,后台一份变更报告等着他审阅; 赠药问卷完成度看板显示,40 位新患者里 36 位已完成 90% 以上问卷,只有 4 位需要运营电话跟进; 左上角还有一条消息:"上周您修改过的那类回复,AI 已经学到了,本周已自动应用到 12 次类似对话。"
老王的上午第一件事,变成了认真审一份 PV 报告草稿——这件事过去他要 2 小时,今天他有 30 分钟就能做完。剩下的时间,他可以去给两位高风险患者亲自打个电话——这是 AI 永远做不到、但恰恰是最体现运营价值的事。
这才是"AI + 患者管理"最终要抵达的样子——不是让 AI 变得更像人,而是让人在 AI 的帮助下,做回那些真正只有人才能做的事情。
祝各位运营同学,早日从堆积的工单里抬起头,看到你们一直在守护的、那些真实的、鲜活的患者。
本文面向患者运营、随访专员、药物警戒专员、医药服务产品经理等读者,所述场景和技术能力均基于当前行业真实实践与公开资料整理,具体实现方案会因业务需要而有所差异。如在项目中需要进一步评估可行性,建议结合自身业务场景、数据基础与合规要求综合判断。
