 夜雨聆风
夜雨聆风4 月 16 日,OpenAI 正式发布 GPT-6(代号 Spud),200 万 token 上下文窗口、性能提升 40%、API 定价降低 50%。这不是一次普通的版本迭代,而是长上下文处理能力进入新纪元的标志性事件。
GPT-6 正式发布,OpenAI 亮出"王炸"
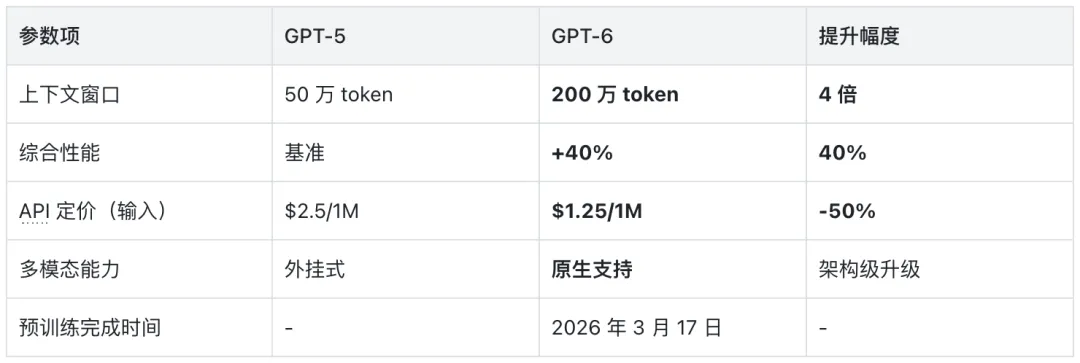
200 万上下文的技术含金量
200 万 token 的实际容量
长上下文的技术挑战
稀疏注意力(SparseAttention):仅对关键 token 进行全注意力计算,其余 token 采用局部窗口注意力 分层注意力(Hierarchical Attention):将长序列分层处理,先提取段落级摘要,再进行跨段落推理 KVCache 压缩:对历史上下文的 Key-Value 缓存进行有损压缩,保留关键信息的同时降低显存占用
位置编码升级:采用改进的 RoPE(Rotary Positional Embedding),支持更长序列的精确位置编码 注意力温度调节:动态调整注意力分布的"温度",避免过度聚焦于首尾位置 关键信息标记:自动识别并标记文档中的关键实体、数字、结论,在推理时给予更高权重
MoE(Mixture of Experts)架构升级:GPT-6 采用更细粒度的专家路由机制,每次推理仅激活 15-20% 的参数 推理时计算优化:采用推测解码(Speculative Decoding)技术,用小模型生成候选 token,大模型进行验证 批量处理优化:针对长上下文场景优化 GPU 显存管理,提高批量推理效率
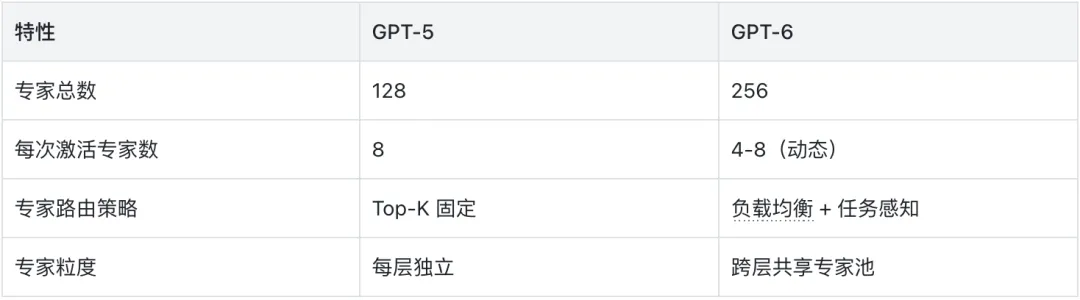
GPT-6 架构详解
原生多模态架构

统一表征:所有模态输入被映射到同一语义空间,支持跨模态推理(如"根据这张图表写一段分析") 端到端训练:多模态能力在预训练阶段即学习,而非后对齐,减少了模态间的语义鸿沟 灵活输出:可根据任务需求生成文本、图像、代码或调用外部工具
MoE 架构升级
推理优化技术
推测解码(Speculative Decoding)
提示词缓存(Prompt Caching)
批量连续批处理(Continuous Batching)
200 万上下文打开的新世界
法律文档分析
一次性摄入全套法律文件 自动识别交叉引用条款(如"见第 3.2 条定义的违约责任") 生成一致性检查报告(如"第 5.1 条与附件 B 存在冲突") 提取关键时间线、责任方、金额等结构化信息
大型代码库审查
一次性加载完整代码库 生成完整调用图(Call Graph)和依赖图 识别潜在 Bug(如未处理的异常、资源泄漏) 提供重构建议(如"这 5 个函数可合并为统一服务层") 生成迁移指南(如"从 Python 2 迁移到 Python 3 需修改的 127 处代码")
科研文献综述
一次性加载 30-50 篇 PDF 论文(经 OCR 和格式转换) 自动提取每篇论文的研究问题、方法、数据集、结论 生成对比表格(如"5 种注意力机制的优缺点对比") 识别研究空白(如"现有方法均未考虑 X 场景") 生成综述草稿(按主题组织,含引用标注)
企业知识库问答
将核心知识库(500-1000 万字)压缩后直接放入上下文 支持跨文档推理(如"产品 A 的故障率与文档 X 中提到的设计变更是否相关") 减少 RAG 依赖,降低检索错误导致的幻觉
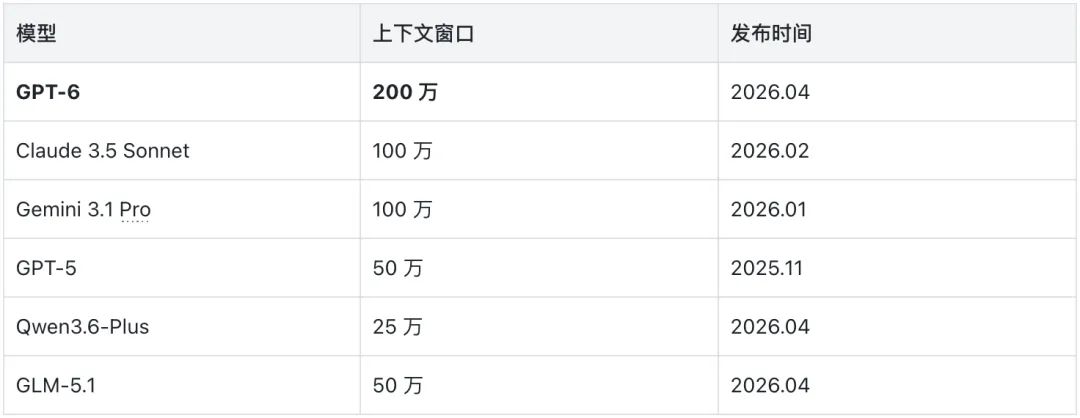
长上下文竞赛的下一步
竞品对比
技术瓶颈与未来方向
无限上下文(Infinite Context):通过流式处理和外部记忆机制,理论上支持无限长度输入 结构化上下文:将长文档转换为知识图谱或树状结构,提高检索和推理效率 多文档原生支持:模型直接理解"文档集合"概念,而非将多文档拼接为单一序列
商业逻辑:"加量不加价"的底气
可构建更复杂的 AI 应用(如完整代码库分析、跨文档推理) API 成本降低 50%,商业可行性提升 原生多模态简化了技术栈(无需单独集成视觉/音频模型)
知识库问答的准确性提升(减少 RAG 依赖) 文档自动化处理效率提升 3-5 倍 长上下文推理支持更复杂的业务场景
