 夜雨聆风
夜雨聆风SOD 评分总打平均分?AI 四维评分给你一份 PFMEA 体检报告
AI 质量文件审核官 · Day 2 :昨天讲三级标注——挑出单条问题;今天讲四维评分——给整份文件打分。
一、"你这份 PFMEA 整体怎么样?"
上周陪客户做内部评审,部长翻了翻 PFMEA 问了一句:
"你这份 PFMEA 整体怎么样?我时间有限,给我一个判断。"
工程师愣了两秒,说:"还行吧……该有的都有。"
部长又问:"那你 RPN 普遍打多少?"
"大部分在 60-100 之间。"
部长合上文件:"这文件你回去重做。"
为什么?
因为"大部分在 60-100 之间"这句话,已经把病根全暴露了——SOD 评分全是 4-5-5 这种平均分,RPN 算出来落在一个中间带,看起来没问题,其实一个真问题都没分析出来。
今天讲两件事:
怎么评估一份 PFMEA 的整体质量(而不是逐条挑错) SOD 评分最容易踩的坑——为什么会打出平均分
然后再看 AI 怎么把这件事自动化。
二、知识篇:一份 PFMEA 好不好,看三个维度
挑单条错误是"点"的视角,评估整体质量是"面"的视角。老法师看一份 PFMEA 好不好,心里在打三个分:
维度 1:完整性——该有的都有吗?
不是看字数多少,是看 失效链是否完整:
每一道工序都有对应失效模式吗? 每个失效模式都写了失效影响吗? 每个失效原因都有对应的预防措施 + 探测措施吗? 高风险项都标了 AP 并给了行动计划吗? 特殊特性(CC/SC)在分析中是否都体现了?
常见坑:焊接、检验、包装、物流这些环节经常漏;辅助工序(上料、搬运)默认不分析,但客户要求时就是不符合项。
维度 2:合规性——SOD 评分站得住脚吗?
这是最容易暴露水平的地方。先把三个字母的本质讲清:
S(Severity)回答"后果多严重",与"发生率"无关。
S=10 不是"经常出安全事故",而是"一旦发生就涉及安全或法规违反"。哪怕发生概率是百万分之一,S 就是 10。这是 S 最容易被搞错的地方——把"不常发生"当成"后果不严重"。
O(Occurrence)回答"这个原因发生的概率",不是"这个失效模式出现的频率"。
同一个失效模式可能有 3 个失效原因,每个原因的 O 要分别打分。把失效模式的 O 直接复制给所有原因——这是 80% 的 PFMEA 都在犯的错。
D(Detection)回答"当前控制措施能不能在流出前发现",看的是探测能力、不是信心。
D=3 意味着你有非常可靠的自动化探测手段(如在线 SPC + 报警停线)。如果你写的控制是"过程抽检"、"目视检查",D 评成 3 就是撒谎,审核员一看就知道。
平均分怎么来的?就这三个坑:
把"我觉得还好"当 S,不看后果本身 把"这种问题不常见"当 O,不看原因发生率 把"我们一直在检"当 D,不看探测能力
结果就是——S、O、D 都在 4-5 之间徘徊,RPN 落在 60-125 这个"看起来有点风险但也不太严重"的中间带,审核员一眼就知道你没真分析。
维度 3:逻辑性——失效链通不通?
失效链的标准形式是:

审核员会顺着这条链往下推:
失效模式是不是功能的"反面"?(如"定位销功能=准确定位",模式就该是"定位偏移/脱落",不是"操作不当") 失效影响有没有传到顾客端?(只写"内部返工"是不够的,要推到下道工序/总装/客户/终端使用) 失效原因能不能直接对应控制措施?(原因是"扭矩枪老化",控制却是"加强培训"——驴唇不对马嘴) AP-H 的行动计划是不是真能降 S/O/D?(写"加强培训"既不降 S 也不降 O,这是虚化)
这三个维度加起来,就是一份 PFMEA 的"体检报告"——完整性看骨架、合规性看血肉、逻辑性看神经。
问题是——人工从这三个维度评一份 100 行的 PFMEA,要花 2 小时。
这就是 AI 四维评分要解决的事。
三、功能篇:AI 四维评分,30 秒出"体检报告"
上传 PFMEA 后,除了昨天讲的三级标注,页面顶部还会出现一张四维评分卡:
┌─────────────────────────────────────────────┐│ 四维评分 │├─────────────────────────────────────────────┤│ 完整性 ████████░░ 82 / 100 ││ 合规性 █████░░░░░ 54 / 100 ⚠️ ││ 逻辑性 ███████░░░ 71 / 100 │├─────────────────────────────────────────────┤│ 总分 ████████░░ 69 / 100 │└─────────────────────────────────────────────┘点击每个维度,展开扣分明细:
完整性(82 分)
✅ 失效模式覆盖:47 / 50 工序 有对应模式 ⚠️ 遗漏工序:包装(OP-80)、运输(OP-90)无分析 ⚠️ 特殊特性覆盖:SCL 清单共 12 项 CC/SC,PFMEA 中仅分析了 10 项
合规性(54 分)⚠️ 重点关注
⚠️ SOD 评分分布异常:87% 的行 S/O/D 落在 4-6 之间,疑似平均分 ⚠️ S=10 项(涉及安全)共 3 处,其中 2 处 O 评分为 2(需核实依据) ⚠️ D 评分为 3 的 8 条记录,对应控制措施均为"目视检查"(D=3 与控制能力不匹配) ⚠️ AP-H 项 5 处,其中 2 处行动计划为"加强培训"(不可执行)
逻辑性(71 分)
✅ 失效模式 → 失效影响 传递:96% 通顺 ⚠️ 失效原因 → 控制措施 对应:3 处不匹配(如原因"设备磨损"对应"人员培训") ⚠️ AP-H 行动计划降 S/O/D 逻辑:2 处行动无法真正降低风险
每一条扣分都告诉你"在哪一行、为什么扣、怎么加回来"。
这份体检报告最有价值的不是分数本身,而是——让你的部长、客户、审核员 10 秒钟读完,就知道这份 PFMEA 大概是什么水平。
四、对比:靠手感 vs 靠数据
部长当年靠 10 年经验,扫一眼 RPN 分布就能判断"这份是真分析还是凑数的"。
现在 AI 把老法师的这种直觉变成了三组数据:
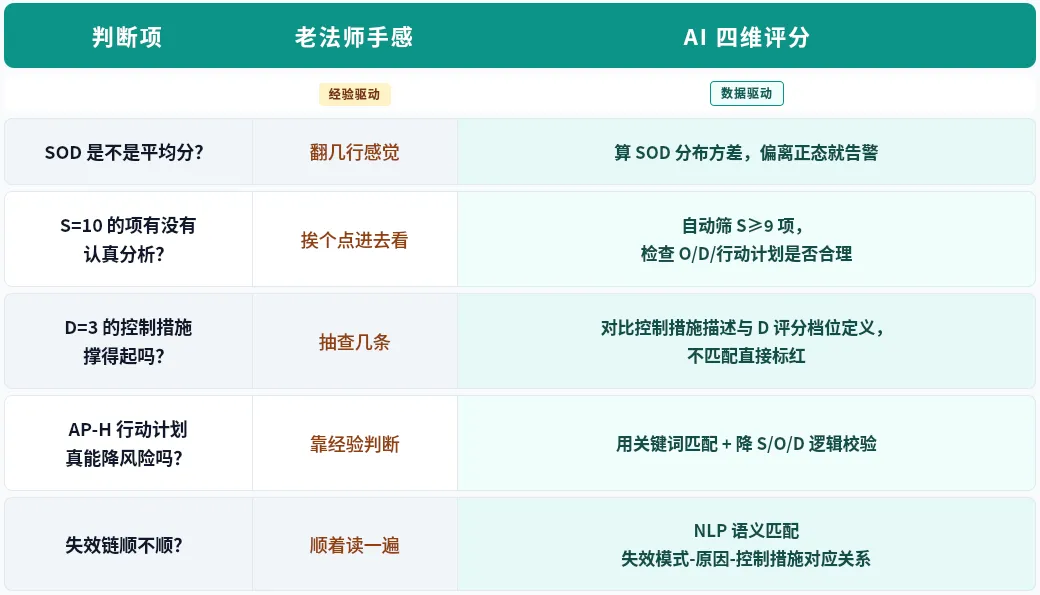
不是 AI 比老法师聪明——是 AI 把老法师的判断规则翻译成了可计算的指标。
老法师走了、换人了,这份"体检标准"还在。
五、一个真实用法:部长评审前 5 分钟
推荐一个已经有客户在用的场景:
部长周五下午 2 点要评审,你 1:50 把 PFMEA 传到 AI 审核官。
1:55,AI 输出四维评分 + 前 5 条严重问题。
1:58,你把"合规性 54 分"的扣分清单打印出来,带进会议室。
2:00,部长开口"你这份 PFMEA 整体怎么样",你直接把报告递过去:"总分 69,合规性偏低,主要问题在 SOD 评分分布和 AP-H 行动计划,我想听您的意见重点改这两块。"
这个姿势比"还行吧……该有的都有"专业 100 倍。
六、明天预告 & 试用
Day 3 讲 AP-H 项不会写行动计划?AI 改进建议分阶段给你写好——延续今天的合规性话题,直接把 AP-H 虚化的坑填上。
想先看看自己现在手上那份 PFMEA,AI 四维评分会给打多少分?
如果你带团队,想知道整个部门的 PFMEA 水平分布(A/B/C/D 分级)。

昆豆 AI · 让工程师专注判断,把重复交给机器
