 夜雨聆风
夜雨聆风2025年5月27日到2026年4月19日,一加13,Gemma,和一个开发者的私人观察。
我第一次使用这个APP 是在2025年5月27日的晚上。
从git下了APK,还得去Hugging Face 生成Token。当时很考验网络。我问了它一个问题,屏幕上字一个一个往外蹦——慢得像我家里的老式热敏打印机,但它真的在我手机里跑。

那个瞬间我记得很清楚。没有网、没有API、没有云——就是一部手机,在我手里,开始说话。
随后我就在群里推荐了这个软件。
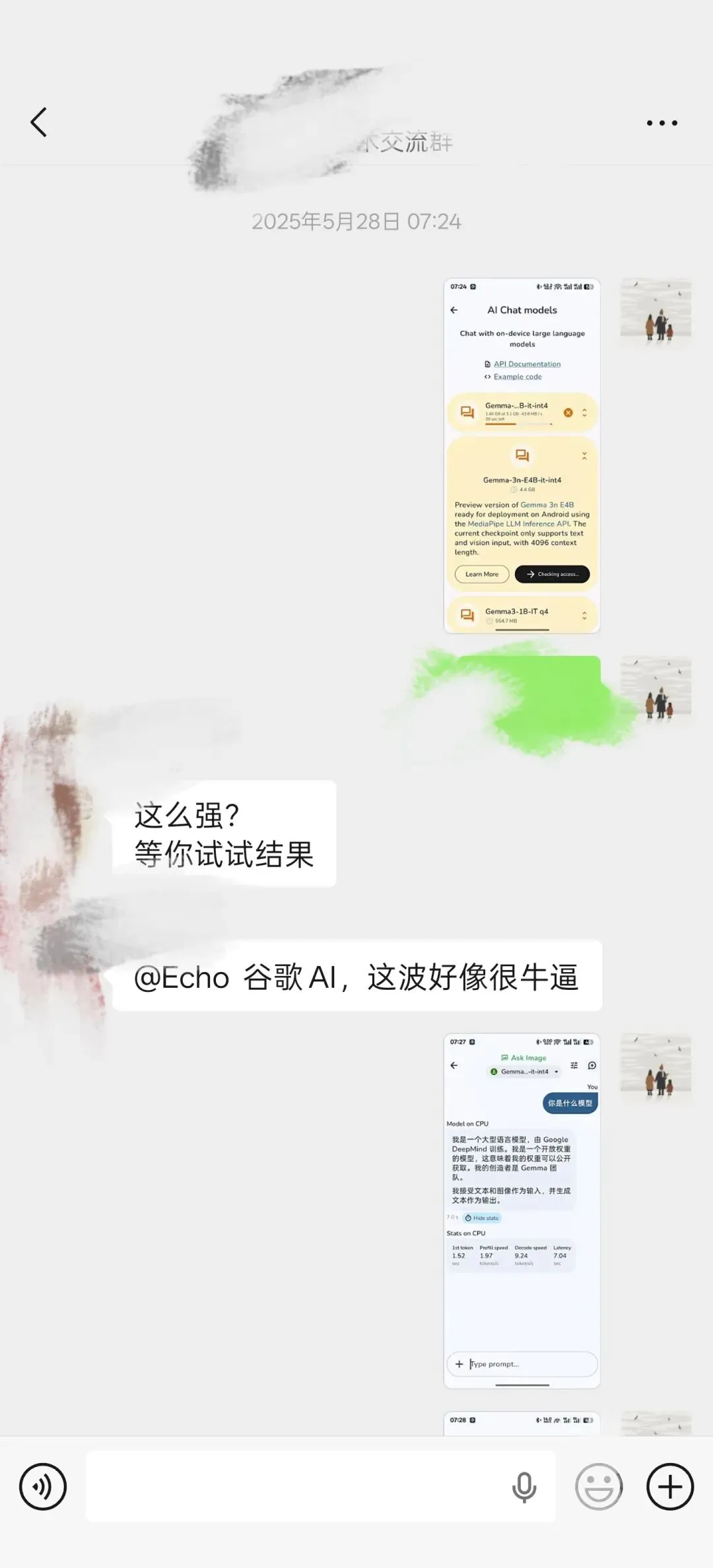
那天之后300多天过去了。今天我再打开打开,Gemma 4 E4B 更强了,AI Chat 多了个思考模式的开关,Agent Skills 带着个"New"标签亮在首页。
它似乎长大了,可以说从玩具过渡到生产力工具了。
一、300多天里,它做了哪些事
我手里的机器:一加13,24GB+1TB,骁龙8至尊版。
早期版本(2025年5-8月)基本是"能跑,但不好用" 的状态:端载、Token、下载中断、每秒几个token,界面还是浓浓的安卓风。那时候用它的人,靠的是"我的数据很重要"的信念,不是产品本身。
中段(2025年秋到年底)是肉眼可见的爬坡:Gemma 3 上线,速度翻倍,不用Token 了,APK 安装流程也顺了。
转折点在2026年4月——上了Google Play和AppStore,带着Gemma 4 一起。
AI Edge Gallery 是运行全球最强大的开源大型语言模型 (LLM) 的首选平台,让您在移动设备上即可体验高性能的生成式 AI——完全离线、私密且速度极快。
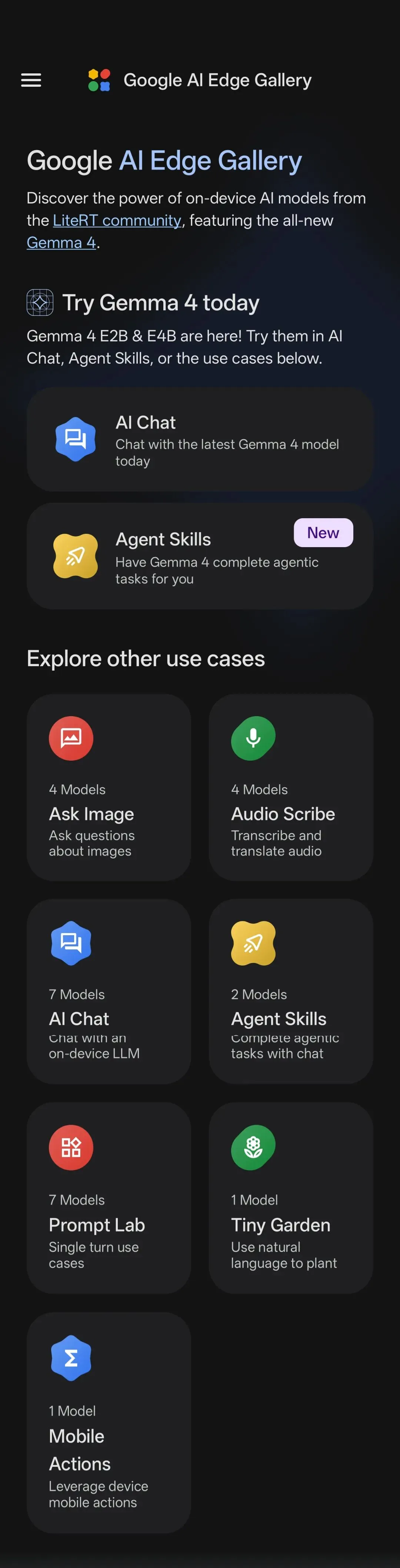
这个版本,我连续用了1周,得出一个结论:它终于从"我愿意用"变成了"可用"。
具体差别在哪?
装机60秒,模型应用内直接拉(最终还是依赖你网络);
E4B 跑起来每秒20+ tokens(肉眼跟读无压力);
飞行模式随便开,整套流程不掉链子;
这种节奏在今天的AI圈不算多见。多数产品要么发布时炸裂、半年后陷入沉寂,要么跳票跳到你忘了它。Edge Gallery 的路线更笨一点——每隔几个月交一次作业,每次你都能感觉到它比上次好一点。
作为一个长期写代码的人,这种"稳定迭代"背后是什么:一个没被KPI 逼疯的团队,在按工程师的节奏做事。 这种团队做出来的东西,用起来是放心的。
二、几个让我愿意继续用它的功能
OCR + 总结
这是我用得最多的场景。
会议纪要截图、扫描合同、带公式的笔记——丢进去,等几秒,出一份结构化摘要。E4B 的识别率肉眼超过95%,繁简混排能读懂,LaTeX 公式能还原。
过去做这件事,我要打开两个APP:一个做OCR,一个做总结。现在一个2.8GB 的本地模型,一次干完,而且屏幕上的每一个字都没离开过我这部手机。
对开发者来说这意味着什么?意味着涉及NDA的代码截图、涉及客户隐私的合同扫描件——我可以放心丢给它。云端AI 不敢,它敢。
Thinking Mode(思考模式)
这个开关藏在AI Chat 的设置里。打开它,Gemma 4 回答前会先把自己的推理过程写出来——就像你做数学题时摊开的那张草稿纸。
因为我知道这是什么——这是DeepSeek系列和Claude 的招牌能力。过去一年,整个AI圈都在卷"推理透明度",卷"让模型把思考过程说出来"。这是前沿实验室的叙事。
然后Google 把它塞进了一个离线跑在手机上、不到4GB 的开源模型里。
当我关掉Wi-Fi、开飞行模式、看着Gemma 4 在我手机屏幕上一行行写出它的思考过程——那种感觉不是"哇这个功能好酷",而是"原来这件事真的可以这样做"。
Agent Skills
这个功能还很早期——能渲染地图卡片、能从URL 加载自定义Skill。现在能玩的花样不多,但"从URL 加载Skill"这件事本身很重要——可以把你实现的技能快速复用。
三、目前它不行的地方
不联网 = 知识冻结
我问它"4月17日市场监管总局那个35.97亿的罚单",它告诉我"暂无相关信息"。问小米SU7 Ultra 最新售价,它报了一个过时的数字。
这不是Bug,是端侧AI 的物理本质——模型冻在你下载的那一刻。它像一本印刷好的百科全书,厚、准、快,但不会更新了。
它能当工具箱,不能当新闻源。
长文和复杂推理,E4B 力不从心
让它写3000字的东西,1200字就开始重复兜圈子。多步推理有概率中途想歪(开Thinking Mode 救不回来——你能看到它在哪一步歪了,但改不了)。
这不是硬件的问题,是参数量决定的。Gemma 4 E4B 是个水桶选手,不是偏科天才。真要做深度推理,它远远打不过云端的GLM-5.1 或Claude Opus 4.7。
发热和耗电的账
一加13 连续推理5分钟,背面能感觉到温度。1小时重度使用掉电15-18%。
端侧AI 省下来的不是算力,不是流量——算力和电的账,一分不少地付在你手机上。
对小白依然不友好
Prompt Lab 里的temperature、top-k,普通人看了就想关APP。这款产品的目标用户画像,其实一直没变——它面对的是愿意折腾的人,不是所有人。
四、300多天我的感受
值得装的:手机内存12GB 以上,芯片是8Gen+旗舰机的用户、律师/医生/财务这种对隐私敏感的职业、经常没网的差旅党、数码发烧友、想玩端侧Agent 的开发者。
不必装的:运存小于12GB的、只是偶尔问两句的普通用户、需要最新信息的。
这些话写在这里像个购物指南。但我真正想说的不是这个。
让我回到2025年5月27日那天晚上。
第一次看着Gemma 在我手机里慢慢吐字,我想起的不是什么"端侧AI 的未来",只让我确认了一件事:这东西真的在我机器里跑。
和云端AI 之间永远有一层玻璃——你把问题递过去,答案递回来,中间发生了什么你看不见,且有的协议虽然说不用你的数据去训练,但结果谁知道呢?
端侧AI 不一样。它在你手机里跑,热量是你的,电是你的,推理过程是你的。你甚至能听到它的呼吸,能看到它的草稿纸,能在没网的地铁上、在飞机上、在地下室里——就你和它,别的什么都没有。
这不是一个更好的AI。 这是一种更贴身的AI。
300多天前我以为我在装一个玩具。 300多天后我才明白,我其实是在把一小块AI,焊进了我的日常。
至于它会不会成为主流——老实说,作为一个写了多年代码的人,我不太关心。
我只知道,在算力紧张的今天,在隐私焦虑的今天,今晚你坐最后一班地铁回家时,无论你的手机有无信号,你可以放心的把你的情感垃圾丢给她。
以上就够了。
