 夜雨聆风
夜雨聆风喜欢你就关注我


在很早之前我就写过Prompt Caching的优化,感兴趣的同学可以查看下面的链接:
从原理到实践:Prompt Caching 命中率提升全攻略
今天我来讲讲Anthropic 封禁 OpenClaw 的真相
AI 智能体每执行一步操作,都需要将完整的对话历史重新发送给大语言模型(LLM)。
这其中包含了系统指令、工具定义,以及三轮对话前就已经处理过的项目上下文。所有这些内容,在每一轮对话中都会被重新读取、重新处理,并且重新计费。
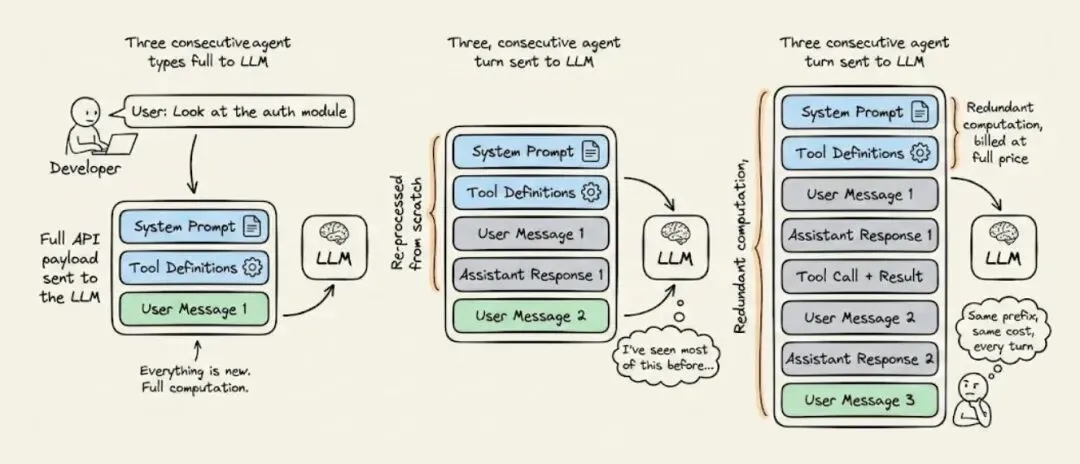
对于长时间运行的智能体工作流来说,这种冗余计算,往往是整个 AI 基础设施中成本最高的支出项。
一条包含 20000 个Token的系统提示词(system prompt ),在 50 轮对话中重复使用,就会产生 100 万个Token的冗余计算 —— 这些计算按全价计费,却没有产生任何新价值。而这样的成本,还会随着每一位用户、每一次会话成倍增长。
解决这个问题的方案,就是提示词缓存。但想要用好它,你必须先理解它底层的运行逻辑。
Prompt Caching(提示词缓存)是 Anthropic 控制算力成本、保障平台服务稳定性的核心底层技术,其核心约束为静态前缀精确匹配,任何前缀改动都会直接导致缓存完全失效。
OpenClaw 的核心架构设计完全违背了 Prompt Caching 的底层规范,其「每次操作重新组织全量历史信息、动态修改 Prompt 前缀」的模式,导致每轮请求的缓存命中率恒为 0,无法复用 KV 缓存,必须执行全量预填充计算。
该架构缺陷导致 OpenClaw 的单轮算力消耗是合规应用的数十倍至上百倍,造成 Anthropic 算力资源的严重浪费、商业成本与收入严重倒挂,同时挤压优质付费客户的服务资源,最终触发平台封禁。
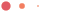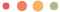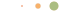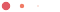

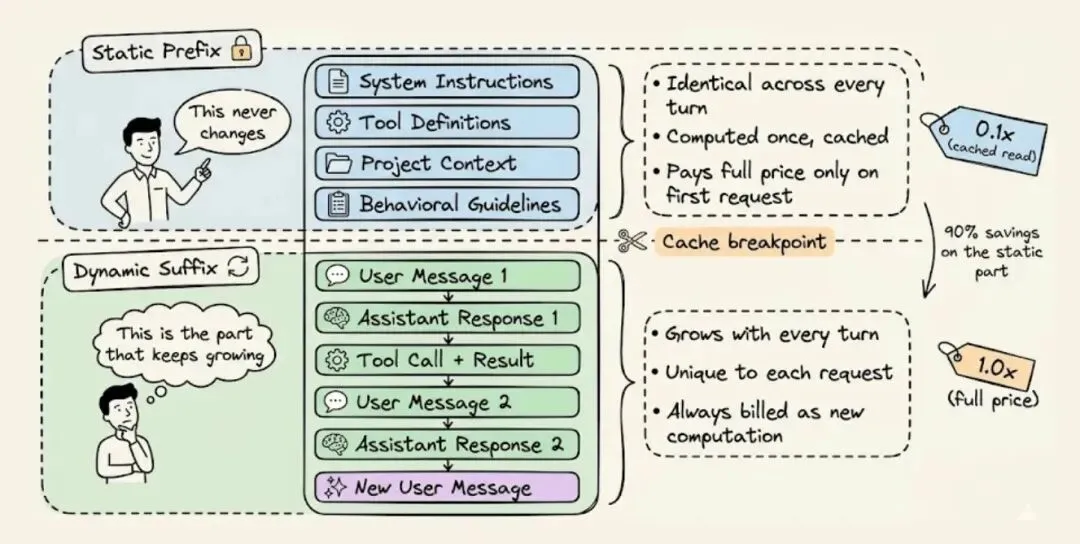
想要优化提示词,你首先要分清内容里哪些会变、哪些不会变。
每一次智能体请求,都包含两个本质不同的部分:
静态前缀:在多轮对话中保持完全不变的内容,包括系统指令、工具定义、项目上下文和行为准则。
动态后缀:随每一轮对话不断增长的内容,包括用户消息、助手回复、工具输出和终端执行结果。
正是这种内容拆分,让提示词缓存成为可能。基础设施会存储静态前缀对应的数学状态,后续带有完全相同前缀的请求,就可以直接跳过计算环节,从内存中读取结果。
一旦你理解了这个核心逻辑,本文中所有的架构设计决策,都会变得顺理成章。

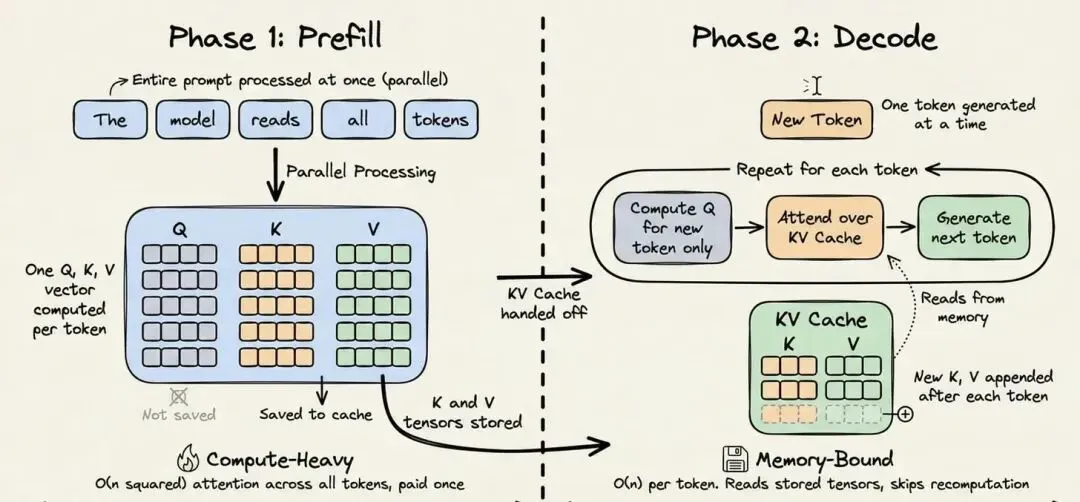
想要理解缓存为什么能有这么显著的效果,你需要先知道 Transformer 架构处理提示词时,到底做了什么。
每一次大语言模型推理请求,都分为两个阶段:
预填充阶段:处理完整的输入提示词。它会对上下文中的所有Token执行密集矩阵乘法,构建模型的内部表征。这个阶段是计算密集型的,成本极高。
解码阶段:逐个生成输出Token。每生成一个新Token,就会把它加入序列,再由模型预测下一个Token。这个阶段是内存密集型的,因为它主要是读取历史状态,而非执行大量计算。
在预填充阶段,Transformer 会为每个Token计算三个向量:查询(Query)、键(Key)和值(Value)。注意力机制会通过这三个向量,判断每个Token与其他所有Token的关联关系。任意Token的键、值向量,仅取决于它之前的Token,一旦计算完成,就永远不会改变。
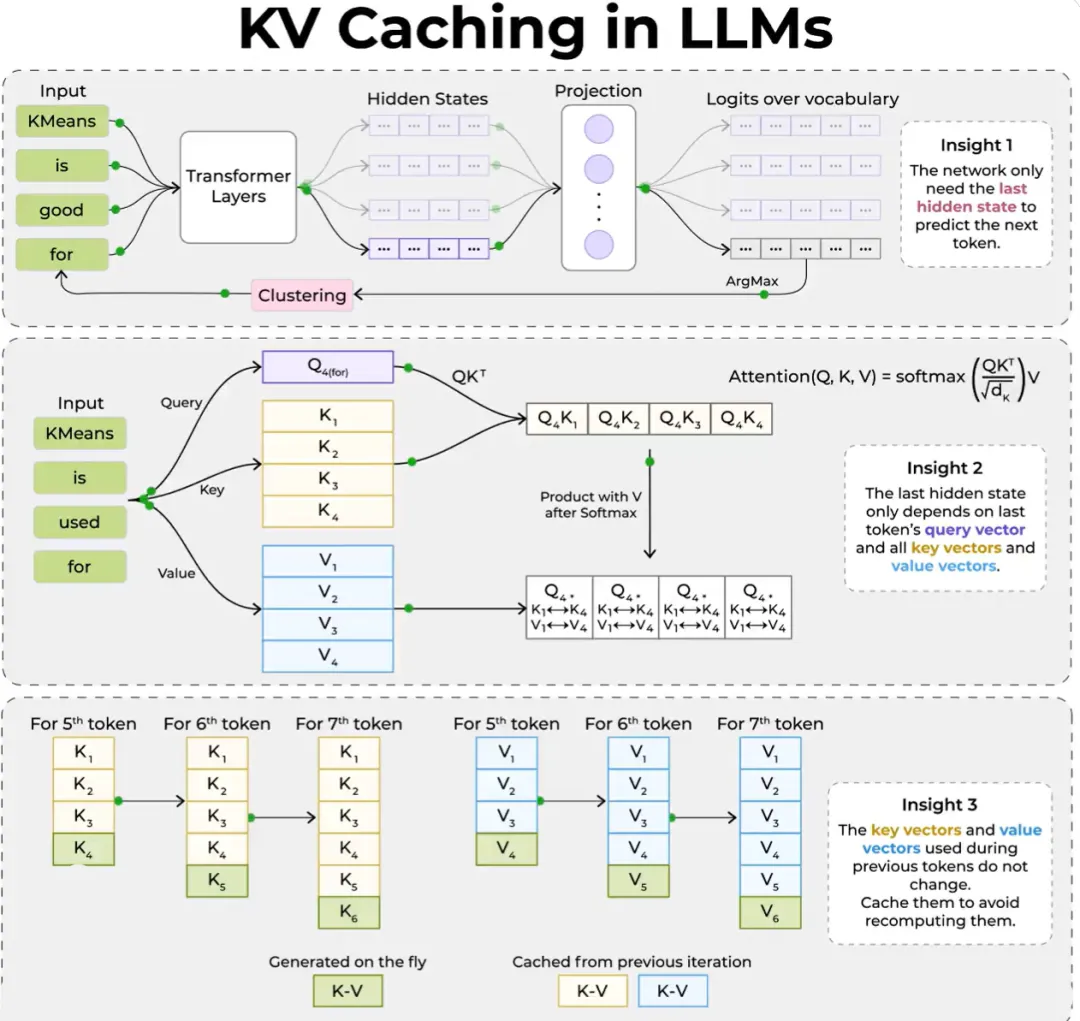
如果没有缓存,这些键值(KV)张量会在每次请求结束后被丢弃,下一次请求需要从头重新计算。对于一个 20000 Token的前缀来说,这意味着 20000 个Token对应的注意力计算,完全是不必要的重复工作。
KV 缓存的解决方式,是将这些张量持久化保存在推理服务器上,以Token序列的加密哈希值作为索引。当新请求带有完全相同的前缀时,哈希值匹配,系统就会从内存中加载对应的张量,直接跳过这些令牌的预填充计算。
这一机制将每个生成Token的计算复杂度,从 O (n²) 降至 O (n)。对于一个在 50 轮对话中重复使用的 20000 Token前缀来说,计算量的下降幅度是极其巨大的。

真正让这个架构设计产生决定性影响的,是行业的定价规则。
缓存读取的成本,仅为基础输入价格的 0.1 倍,也就是每个缓存Token可享受 90% 的费用折扣。缓存写入的成本是基础价格的 1.25 倍,即需要支付 25% 的溢价来存储 KV 张量;而 1 小时的长时效缓存,成本则为基础价格的 2.0 倍。
以下是 Anthropic 旗下 Claude 系列模型的缓存定价规则:
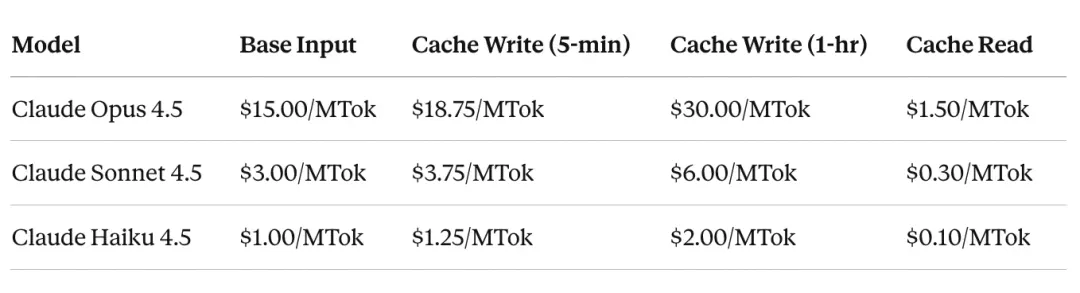
这套成本模型成立的唯一前提,是保持足够高的缓存命中率。而生产环境中最标杆的案例,就是 Claude Code。
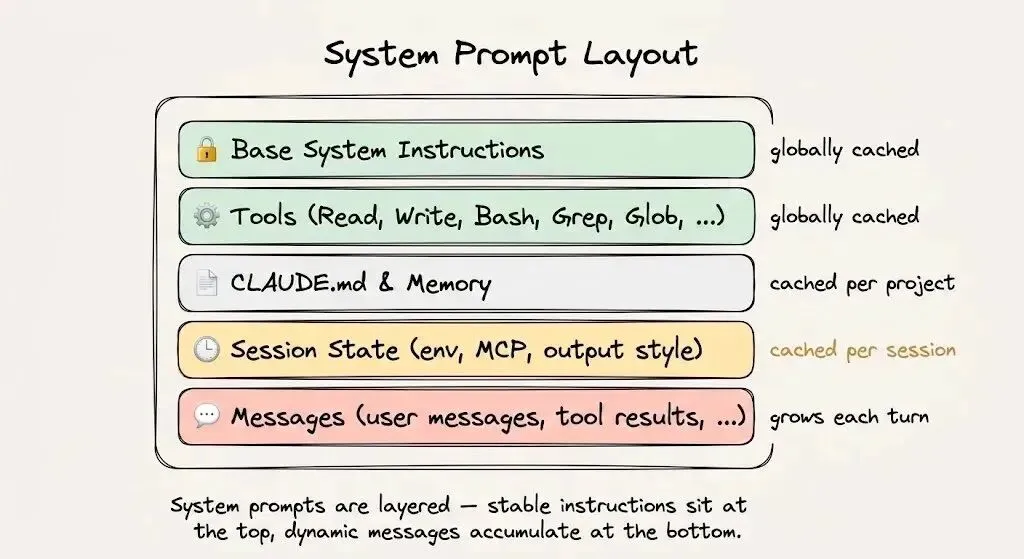
Claude Code 的整个产品设计,都围绕着一个核心目标:让缓存持续保持热启动状态。
下面是一次真实的 30 分钟编码会话,从计费维度的完整拆解:
第 0 分钟:Claude Code 加载系统提示词、工具定义,以及项目的 CLAUDE.md 说明文件。这部分内容超过 20000 个Token,且所有Token都是全新的,因此这是整次会话中成本最高的时刻。但这笔成本,你只需要支付一次。
第 1-5 分钟:你开始下达指令,Claude Code 会调度探索子代理,来遍历代码库、打开文件、执行 grep 检索命令。所有这些内容,都会被追加到动态后缀中。而那 20000 个Token的静态前缀,此时已经从缓存中读取,计费标准从 3 美元 / 百万Token,降至 0.3 美元 / 百万Token。
第 6-15 分钟:规划子代理收到的是精简后的需求摘要,而非原始结果 —— 因为直接传递原始输出,会无意义地撑大动态后缀。它会生成一份实现方案,在你确认后,Claude Code 就开始执行代码修改。每一轮对话都会从缓存中读取静态前缀,缓存命中率突破 90%,且每次访问都会重置缓存的生存时间,让缓存持续保持热状态。
第 16-25 分钟:你提出修改需求,这意味着更多的工具调用、更多的终端输出,以及更多上下文累积到动态后缀中。到这个阶段,会话已经处理了数十万个Token,但每一轮对话,都依然从缓存中读取那 20000 个Token的基础内容。
第 28 分钟:你在终端执行 /cost 指令查看成本。如果没有缓存,200 万个Token按 Sonnet 4.5 的定价,总成本为 6 美元。而在 92% 的缓存效率下,有 184 万个Token是缓存读取,最终总成本仅为 1.15 美元。单任务成本直接下降了 81%。
这就是热缓存的真实效果:静态基础内容你只需要付费一次,后续的读取几乎等同于免费,只有动态增长的尾部内容,才会产生计费。
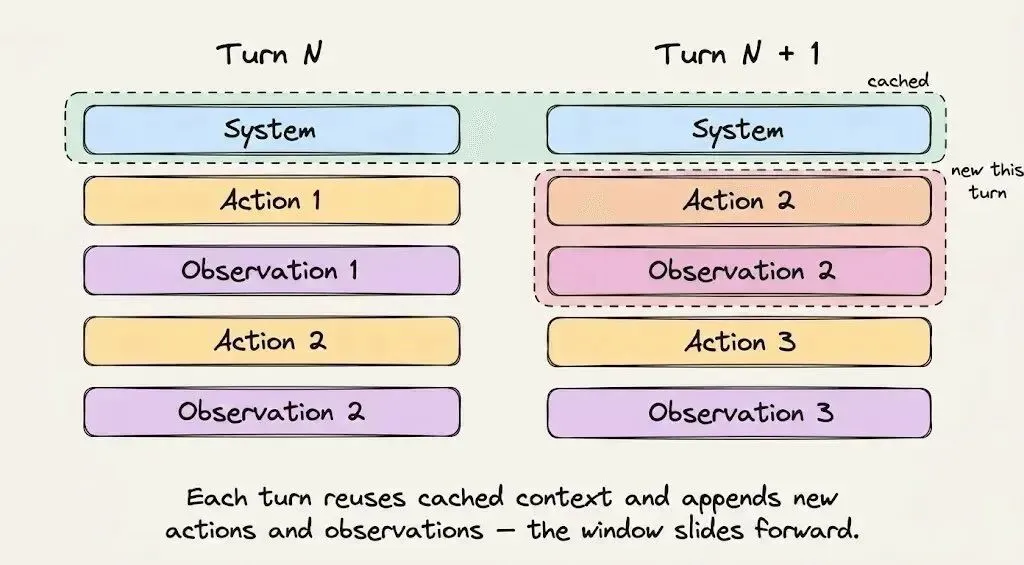
关于提示词缓存,最反直觉的一点是:
“1 + 2 = 3” 能命中缓存,但 “2 + 1” 就会缓存未命中。
基础设施会对从头开始的完整Token序列做哈希计算。只要序列中的任何内容发生变化,哪怕只是两个元素的顺序调换,哈希值都会改变,整个前缀就需要按全价重新计算。
这不是一个无关紧要的实现细节,而是 Claude Code 所有工程设计,都必须围绕的核心约束。
以下是生产环境中,真实导致缓存失效的案例:
系统提示词中插入了时间戳,导致每次请求的哈希值都独一无二。
JSON 序列化器在不同请求中,对工具模式的键做了不同的排序,直接导致前缀失效。
一个智能体工具的参数在会话中途被更新,直接清空了整个 20000 令牌的缓存。
由此衍生出三条铁则:
不要在会话中途修改工具。工具定义是缓存前缀的一部分,新增或删除工具,会导致下游所有内容全部失效。
绝对不要在会话中途切换模型。缓存是与模型绑定的,这意味着对话中途切换到更便宜的模型,需要从头重建整个缓存。
绝对不要通过修改前缀来更新状态。Claude Code 不会去编辑系统提示词,而是会在下一条用户消息中追加一个提醒标签,以此保证前缀完全不被改动。
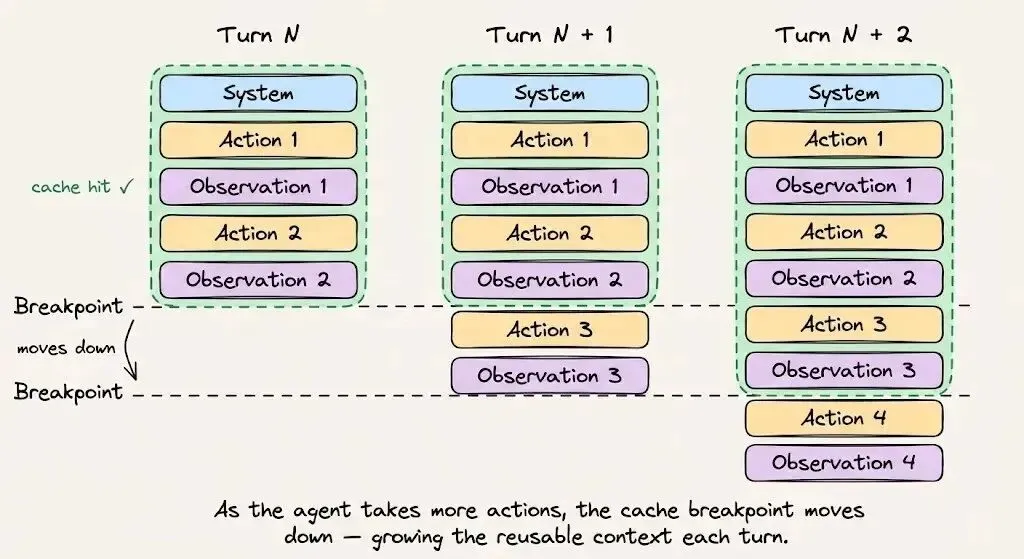
无论你是使用 Claude Code,还是从零搭建自己的智能体,这套规则都完全适用。
请按以下顺序组织你的提示词结构:
最顶部放置系统指令和行为规则,会话中途不要修改。
提前加载所有工具定义,不要中途新增或删除。
接下来是检索到的上下文和参考文档,在整个会话周期内保持稳定。
最底部放置对话历史和工具输出,这就是你的动态后缀。
在 Anthropic API 中开启自动缓存后,缓存断点会随着对话的推进自动前移。如果没有开启自动缓存,你就需要手动跟踪Token边界,一旦边界设置错误,就会完全无法命中缓存。
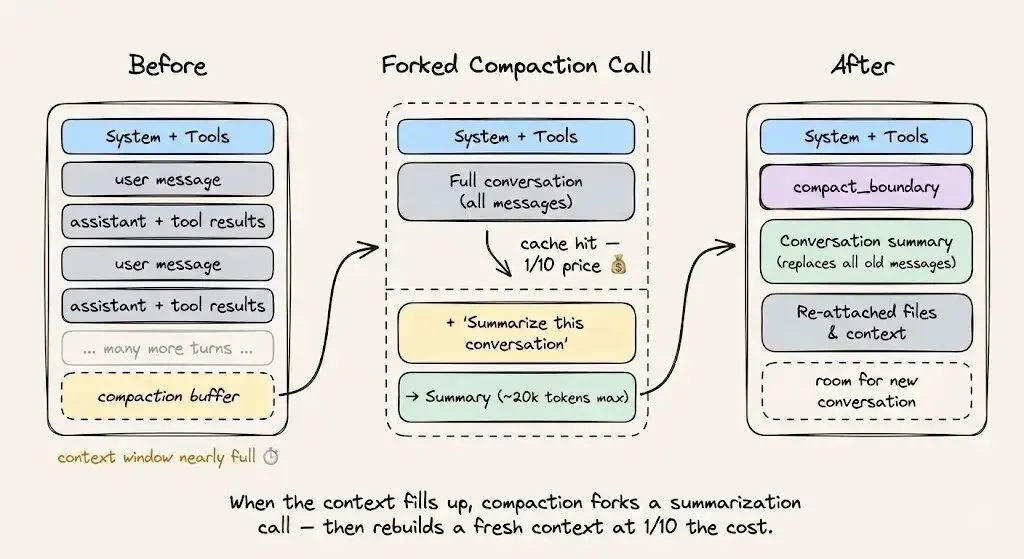
当你接近上下文长度上限,需要做上下文压缩时,请使用缓存安全分叉方案:保持原有的系统提示词、工具和对话历史不变,将压缩指令作为一条新消息追加在末尾。这样缓存前缀可以完全复用,唯一需要计费的新Token,只有压缩指令本身。
想要验证缓存是否正常生效,请监控每一次 API 响应中的三个关键字段:
cache_creation_input_tokens:写入缓存的Token数
cache_read_input_tokens:从缓存中读取的Token数
input_tokens:未经过缓存、直接处理的Token数
你的缓存效率计算公式为:缓存读取Token数 / (缓存读取Token数 + 缓存写入Token数)。你需要像监控服务可用率一样,持续跟踪这个指标。
提示词缓存,不是一个你一键开启就能用的功能,而是一套你需要围绕它做架构设计的工程准则。
它的核心逻辑非常简单:合理组织你的提示词,让静态内容固定在顶部,动态内容在底部增长。基础设施会为前缀生成哈希值,存储对应的 KV 张量,让你后续的每一次读取,都能享受 90% 的费用折扣。
但真正的考验,藏在细节里:不要在系统提示词里插入时间戳,不要打乱工具定义的顺序,不要在会话中途切换模型,不要修改缓存断点上游的任何内容。
Claude Code 已经向我们展示了这套方案的规模化效果:92% 的缓存命中率,81% 的成本下降。如果你正在搭建智能体,却没有围绕提示词缓存做设计,相当于白白丢掉了绝大部分利润空间。

Prompt Cache 的本质是持久化存储预填充阶段生成的 KV 张量,通过令牌序列加密哈希实现精确匹配,后续请求前缀完全一致时,直接跳过预填充阶段,仅处理新增动态内容。其核心规则如下:
精确前缀匹配铁则:缓存命中的唯一前提是请求前缀的 Token 序列完全一致,1 个字符、1 个空格、大小写差异、元素顺序调整,都会导致哈希值变化,缓存完全失效。
核心设计规范:必须严格遵循「静态内容前置、动态内容后置」原则。将系统指令、工具定义、项目知识库等永久不变的内容作为静态前缀固定在请求最前端;将用户消息、工具输出、会话状态等高频变动内容作为动态后缀,仅在请求末尾追加。
缓存断点机制:支持手动设置cache_control: {type: "ephemeral"}缓存断点(最多 4 个),也支持自动缓存的断点智能滑动 —— 随对话增长自动前移断点,永久锁定静态前缀,保障长会话的缓存复用。
计费与成本模型:常规输入 Token 计费为$3.00/百万,缓存读取仅为$0.30 / 百万(仅 10% 价格),缓存写入为 1.25 倍基础价格。高命中率可直接实现 90% 的成本下降,同时降低 90% 以上的算力消耗。
官方黄金准则:Claude Code 团队将缓存命中率纳入生产事故级管控,明确 7 条硬性规则:前缀稳定第一、不修改系统提示注入动态内容、工具列表锁定、模型隔离不中途切换、特性设计围绕缓存、上下文压缩复用父前缀、全链路缓存监控。
缓存命中的核心判定指标
缓存是否生效的核心量化指标为cached_tokens(已缓存Token数),该指标仅当请求前缀与已缓存序列完全匹配时产生有效计数:
计数 > 0:前缀匹配成功,对应数量的 Token 跳过预填充计算,直接复用 KV 缓存;
计数 = 0:前缀匹配完全失败,所有输入 Token 需执行全量预填充计算,无任何缓存复用。

结合 OpenClaw 的架构设计逻辑与 Claude Prompt Cache 的核心规则,其缓存命中率恒为 0 的核心原因,是架构设计完全违背了缓存机制的底层约束,从根本上破坏了缓存命中的前提条件,具体拆解如下。
OpenClaw 的核心设计逻辑为:每次操作都将之前的全量历史信息重新组织,生成全新的 Prompt 后提交给模型。该机制直接打破了缓存命中的核心前提 —— 静态前缀的精确匹配:
每一轮请求的 Token 序列都会被完全重构,原本应固定不变的系统指令、工具定义、基础上下文等静态内容,会被重新排序、修改、插入动态信息,导致每一轮请求的前缀哈希值完全不同,无法与历史缓存匹配。
该模式完全废弃了 LLM 原生的「会话增量追加」模式,没有固定的缓存断点,无论是手动设置的缓存块还是自动缓存的智能断点,都无法实现跨轮复用,每一轮都必须从头执行全量预填充计算。
Claude Prompt Cache 的高命中率,完全依赖静态前缀与动态后缀的严格拆分,而 OpenClaw 的架构设计完全违背了该规范:
动态内容侵入前缀区域:OpenClaw 会将历史对话、工具输出、执行结果等动态内容,插入到系统提示词、工具定义等静态内容之前或中间,直接破坏了静态前缀的完整性和一致性。
系统提示与工具定义动态修改:为适配每一轮的操作需求,OpenClaw 会动态修改系统提示词内容、增删 / 重排工具列表,而这两类内容是核心缓存前缀的核心组成部分,任何改动都会直接导致整个缓存完全失效,完全违背了「工具列表锁定、系统提示永久固定」的官方黄金准则。
在长会话场景下,OpenClaw 的上下文处理逻辑进一步加剧了缓存失效:
当接近上下文窗口上限时,OpenClaw 会对全量历史信息进行重写和压缩,生成全新的 Prompt 结构,而非 Claude 官方推荐的「缓存安全分叉方案」—— 保留静态前缀完全不变,仅在动态后缀追加压缩指令,复用父级缓存。
该压缩逻辑会导致整个会话的 Token 序列被完全重构,原本可能存在的缓存被全部清空,后续请求必须重新执行全量预填充,形成「缓存失效→算力高消耗→压缩重写→缓存完全清零」的恶性循环。

基于用户提供的两组实测数据,量化对比缓存失效与正常命中的算力消耗差异,验证 OpenClaw 架构缺陷的实际影响。
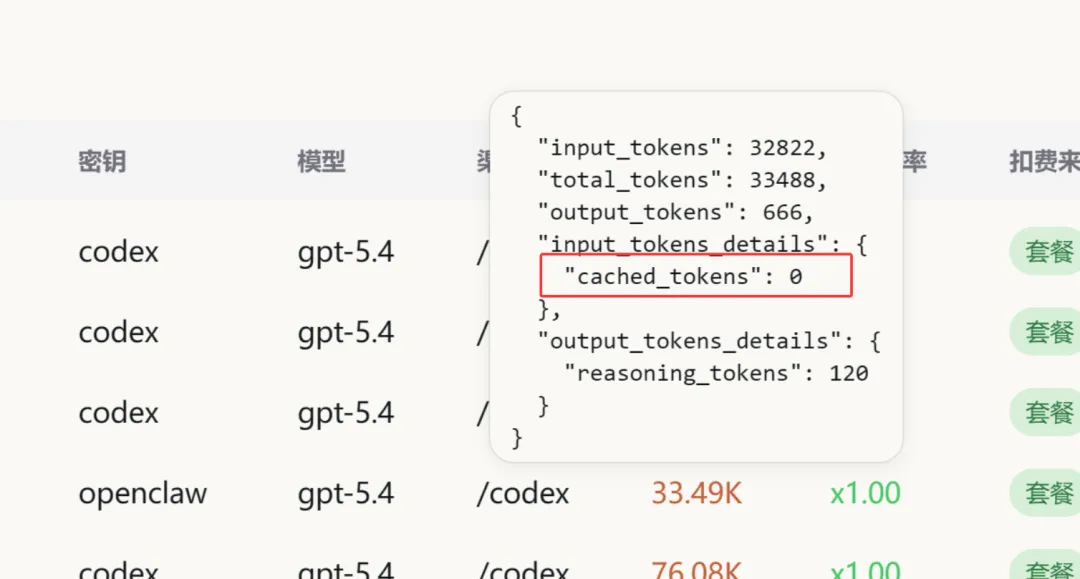
结论:该场景完全匹配 OpenClaw 的架构表现,单轮 3.28 万 Token 的输入无任何缓存复用,Anthropic 需为该请求承担 100% 的预填充算力成本,无任何成本优化空间。
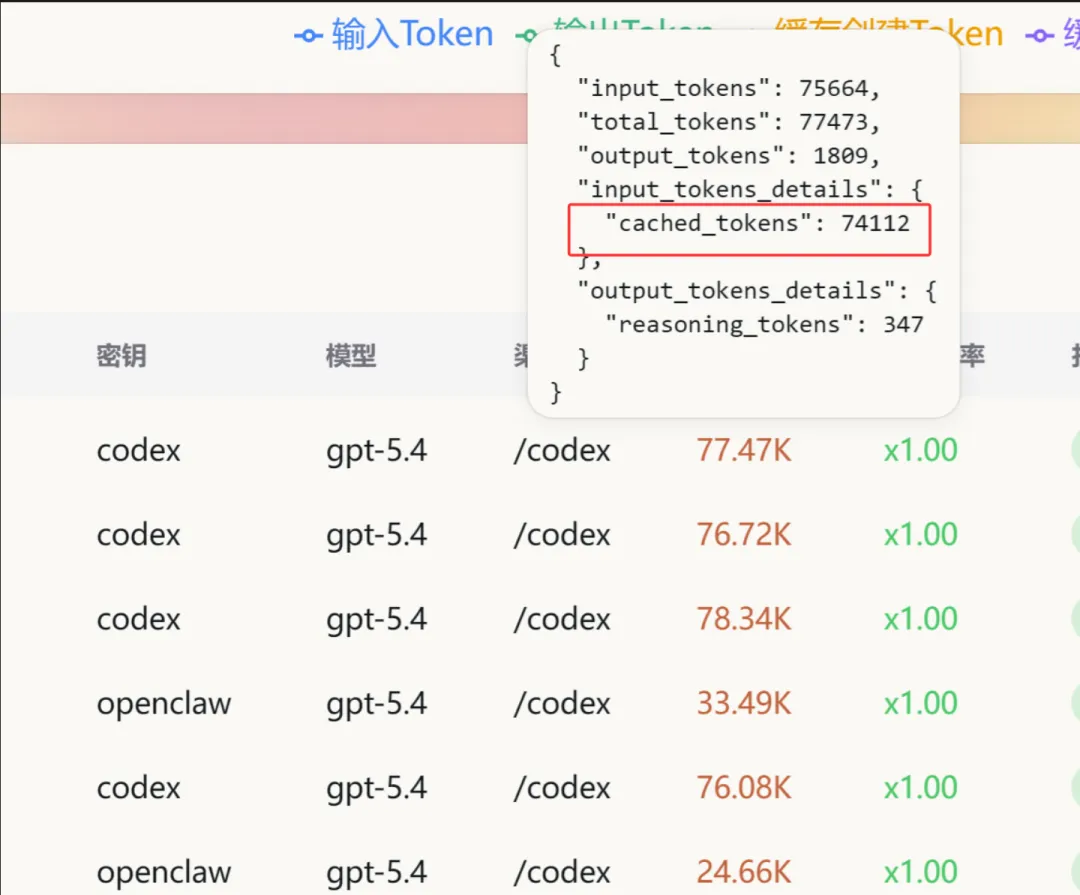
结论:合规架构设计下,即使输入规模翻倍,98% 的 Token 可通过缓存复用,仅需处理 1552 个新增动态 Token,算力消耗仅为失效案例的 2% 左右,两者的集群资源占用差距达到两个数量级。

OpenClaw 的架构缺陷,不仅导致自身应用成本居高不下,更对 Anthropic 平台的算力调度、商业收益、服务稳定性造成了系统性冲击,这是其被封禁的核心商业与运营原因。
预填充阶段是 GPU 算力消耗的核心环节,OpenClaw 的 0 缓存命中率架构,导致其算力消耗呈指数级增长:
以 2 万 Token 静态前缀、50 轮对话的长会话场景为例:合规应用仅需执行 1 次全量预填充,后续 49 轮均命中缓存,总预填充计算量为 2 万 Token;而 OpenClaw 需执行 50 次全量预填充,总预填充计算量为 100 万 Token,算力消耗是合规应用的 50 倍。
对于企业级长会话智能体场景,单会话 Token 规模可达数十万级别,OpenClaw 的算力消耗可达合规应用的上百倍,直接占用 Anthropic GPU 集群的核心算力与显存资源,导致集群整体负载飙升。
Anthropic 的计费模型与缓存机制深度绑定,OpenClaw 的架构设计导致平台出现严重的成本收入失衡:
对于合规高命中率应用,Anthropic 的收入结构为「1 次全价缓存写入费用 + N 次 10% 价格的缓存读取费用」,对应的算力成本极低,毛利率极高;
对于 OpenClaw,Anthropic 每一轮请求都需承担 100% 的预填充算力成本,却只能收取 1 次全价输入 Token 的费用,单位收入对应的算力成本是合规应用的数十倍,完全不符合平台的商业收益模型。
大规模使用场景下,OpenClaw 的单用户算力成本,远超其带来的商业收入,同时挤压了高价值付费客户的服务资源,直接影响平台的核心商业收益。
预填充阶段为计算密集型操作,会持续占用 GPU 核心算力,OpenClaw 的全量预填充请求会对平台稳定性造成直接冲击:
大量 0 缓存命中率的请求持续涌入,会导致 GPU 集群算力被持续占满,引发推理请求排队延迟升高,其他合规用户的请求响应变慢,甚至出现超时、服务不可用,严重影响平台的 SLA 保障;
全量预填充操作会频繁触发 GPU 显存的读写与分配,加剧集群的资源碎片化,进一步降低整体服务效率,提升平台的运维成本。
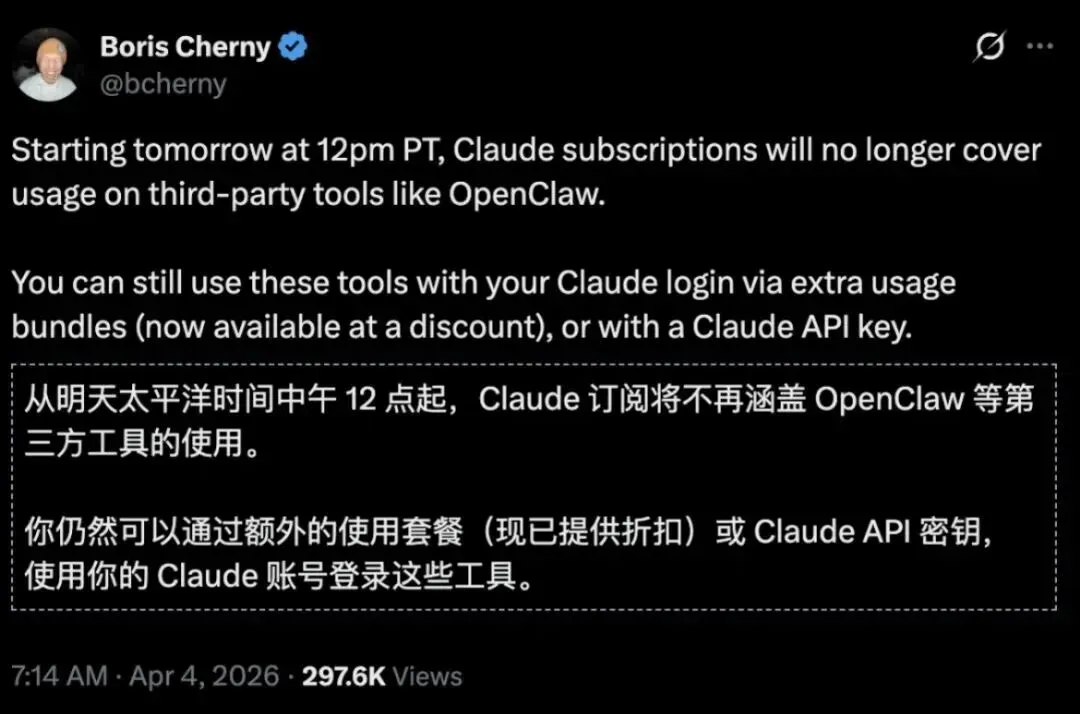
Anthropic扔出一颗重磅炸弹:从太平洋时间 4 月 4 日中午 12 点起,Claude 订阅将不再涵盖 OpenClaw 等第三方工具的使用。用户仍可通过 Claude 账户登录这些工具,但需另行付费,选择额外用量套餐(目前有折扣)或直接使用 Claude API 密钥。
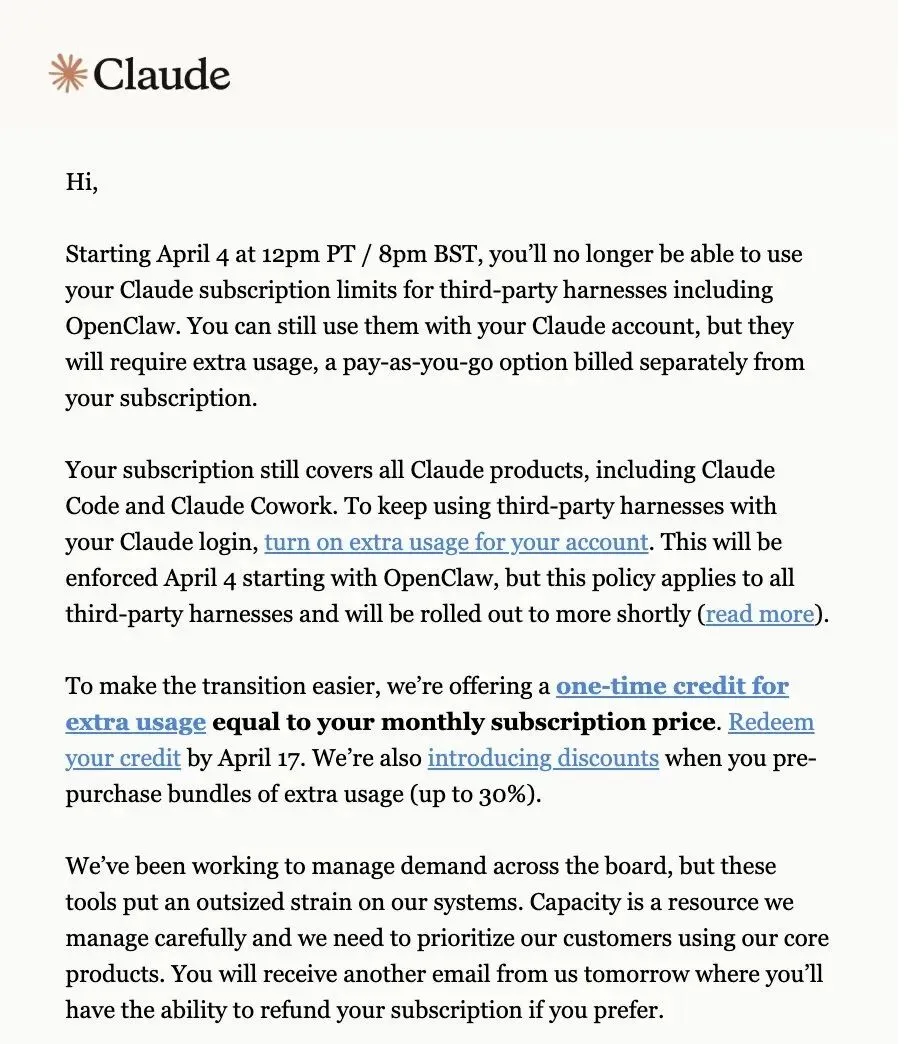

OpenClaw 在 2026.4.5 版本(正式发布于 2026 年 4 月 6 日) 完成了 Prompt Caching 设计的系统性优化,从根本上解决了此前缓存命中率极低(甚至长会话场景下恒为 0)的核心问题;在此之前,2026 年 3 月社区已针对缓存架构缺陷完成了多项底层修复与技术铺垫,为正式版本的落地完成了核心架构验证。
该版本是 OpenClaw 针对 Prompt Caching 命中率问题的正式修复版本,完整覆盖了此前导致缓存失效的所有核心缺陷,官方更新日志明确将「prompt caching 命中率提升」作为核心性能优化项。
1. 核心优化动作
固定工具列表排序规则,彻底解决了此前工具列表随机排序导致的前缀哈希值变动、缓存全量失效问题;
统一系统提示词的格式细节(空格、换行、大小写规范),移除重复的工具说明,保证静态前缀的字节级一致性;
完成系统提示词结构重构,严格遵循「静态内容全前置、动态内容全后置」的缓存适配规范,将工具定义、固定身份指令等大体积稳定内容放在请求最前端,时间戳、运行时元数据等动态内容全部后置;
优化上下文压缩逻辑,采用缓存安全的分叉压缩方案,压缩操作不修改历史静态前缀,保证缓存持续复用;
新增openclaw status --verbose缓存诊断命令,支持实时查看缓存命中率、成本节省数据,实现缓存效果的可观测。
2.优化效果
官方数据显示,该版本实现了 prompt caching 命中率平均 35% 的提升;在长会话、固定系统提示词的智能体场景下,可实现97%-98% 的稳定缓存命中率,彻底解决了此前前缀频繁变动导致的缓存完全失效问题,单会话 token 成本最高可降低 90%。
在 2026.4.5 正式版本发布前,OpenClaw 社区已在 3 月完成了缓存架构的核心底层修复,解决了命中率为 0 的根因问题,为正式版本的发布完成了技术验证:
2026 年 3 月 2 日,社区提交核心架构修复 PR,重构系统提示词的块构建顺序,将动态内容(时间戳、运行时元数据、会话状态)从系统提示词前缀区域移除,改为静态内容(工具定义、固定身份指令、技能说明)全前置,从架构层面解决了前缀每轮变动导致缓存恒为 0 的核心问题;
同期完成动态信息注入方式的优化,将时间戳等会话必需的动态内容,通过<system-reminder>标签追加到用户消息末尾,不再修改系统提示词前缀,同时完成了工具定义排序的确定性修复;
2026 年 3 月中下旬,社区完成了缓存边界漏洞修复、提示词构建回归测试补充、缓存安全压缩逻辑优化,完成了全链路的缓存适配验证,为 4 月正式版本的发布完成了底层技术闭环。

核心封禁根因:Anthropic 封禁 OpenClaw 的核心技术原因,是其架构设计完全违背了 Prompt Caching 的底层规范,导致缓存命中率恒为 0,产生了数十倍于合规应用的算力消耗,造成平台算力资源严重浪费、商业成本与收入倒挂,同时冲击了平台整体的服务稳定性。
缓存技术的本质:Prompt Caching 不是一个可一键开启的附加功能,而是 AI 原生应用架构设计的核心准则,其核心是通过「静态前缀永久固定、动态内容增量追加」的设计,最大化复用 KV 缓存,降低预填充阶段的算力消耗。
优化核心路径:OpenClaw 通过核心架构重构,严格遵循模型厂商的 Prompt Caching 的设计规范,锁定静态前缀、增量追加动态内容、合规处理上下文压缩,才能实现 90% 以上的缓存命中率,解决平台适配问题,同时实现自身应用的算力成本大幅下降。



