 夜雨聆风
夜雨聆风前言
最近,AI领域的新名词层出不穷:LLM、RAG、Agent、知识图谱、多模态……很多小伙伴被这些术语搞得晕头转向,感觉每个字都认识,但连在一起就不知道是什么意思了。
今天这篇文章我就用一张“AI知识图谱”,把这些核心概念串起来,用最通俗的语言和代码示例,帮你一次性搞懂它们是什么、有什么用、怎么用。
希望对你会有所帮助。
一、AI知识图谱:把“黑话”变成一张图
先来看这张AI核心概念关系图,它会成为我们今天的导航地图:
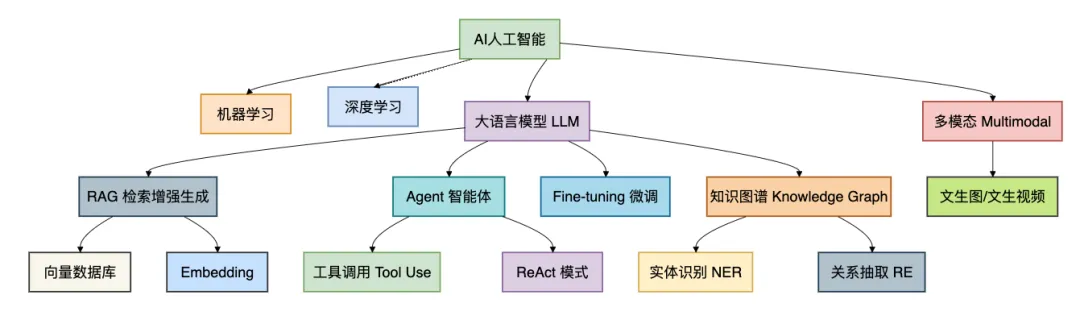
这张图就是AI领域的“知识图谱”——它不是零散的知识点,而是把各个概念之间的关系连接起来,让你一目了然。
下面,我们就从最基础的概念开始,逐个击破。
二、核心概念逐个拆解
2.1 机器学习 vs 深度学习
一句话解释:机器学习是让计算机从数据中“学习规律”,深度学习是机器学习的一种,它模仿人脑的神经网络结构。
通俗理解:
机器学习:就像你教孩子认识苹果——你给他看10个苹果,他总结出“红色的、圆的水果是苹果”。 深度学习:你直接给孩子看10000张图片,让他的“大脑神经网络”自己去发现苹果的特征,不用你告诉他什么是“红色”和“圆形”。
代码示例(用Java的Weka库做简单机器学习):
// 机器学习示例:用决策树判断天气是否适合打网球import weka.core.Instances;import weka.classifiers.trees.J48;publicclassMachineLearningDemo{publicstaticvoidmain(String[] args)throws Exception {// 训练数据:天气情况 -> 是否打网球// Outlook, Temperature, Humidity, Windy, Play String data = "@relation weather\n" +"@attribute outlook {sunny,overcast,rainy}\n" +"@attribute temperature real\n" +"@attribute humidity real\n" +"@attribute windy {TRUE,FALSE}\n" +"@attribute play {yes,no}\n" +"@data\n" +"sunny,85,85,FALSE,no\n" +"sunny,80,90,TRUE,no\n" +"overcast,83,86,FALSE,yes\n" +"rainy,70,96,FALSE,yes"; Instances instances = new Instances(new StringReader(data)); instances.setClassIndex(instances.numAttributes() - 1);// 训练决策树模型 J48 tree = new J48(); tree.buildClassifier(instances); System.out.println("决策树模型:" + tree);// 模型可以预测:新的一天[rainy,68,80,TRUE] -> 会输出yes/no }}使用场景:推荐系统、垃圾邮件过滤、股票预测。
优点:能自动从数据中发现规律,不需要人工编写复杂规则。
缺点:需要大量高质量数据,模型可能过拟合。
2.2 大语言模型(LLM)
一句话解释:一种通过海量文本训练出来的、能理解和生成人类语言的巨型神经网络。
通俗理解:LLM就像一个读过整个互联网的人,你问它什么,它都能聊上几句。但它不知道你的私人信息,因为那些不在它的“阅读材料”里。
常见的LLM:GPT-4、Claude、文心一言、通义千问、DeepSeek。
代码示例(调用OpenAI API):
// 使用OkHttp调用大模型APIimport okhttp3.*;publicclassLLMDemo{publicstaticvoidmain(String[] args)throws Exception { OkHttpClient client = new OkHttpClient(); String json = "{\n" +" \"model\": \"gpt-3.5-turbo\",\n" +" \"messages\": [{\"role\": \"user\", \"content\": \"什么是大语言模型?\"}]\n" +"}"; Request request = new Request.Builder() .url("https://api.openai.com/v1/chat/completions") .header("Authorization", "Bearer YOUR_API_KEY") .post(RequestBody.create(json, MediaType.parse("application/json"))) .build(); Response response = client.newCall(request).execute(); System.out.println(response.body().string()); }}使用场景:智能客服、内容生成、代码辅助、翻译。
优点:理解能力强,能处理各种自然语言任务。
缺点:会产生“幻觉”(编造事实),成本高,不掌握私有数据。
2.3 RAG(检索增强生成)
一句话解释:让LLM在回答问题前,先去你的知识库里“查资料”,再根据资料回答。
通俗理解:LLM本身是个“学霸”,但他只学过公共教材。RAG就是让他在考试前,先翻翻你的公司内部资料,再用自己的话总结出来。这样他既能回答专业问题,又不会胡说八道。
工作原理图:

代码示例(Spring AI Alibaba实现):
@ServicepublicclassRAGService{@Autowiredprivate VectorStore vectorStore; // 向量数据库,存公司文档@Autowiredprivate ChatClient chatClient;public String ask(String question){// 1. 检索相关文档 List<Document> docs = vectorStore.similaritySearch( SearchRequest.query(question).withTopK(3) );// 2. 把文档内容拼成上下文 String context = docs.stream() .map(Document::getContent) .collect(Collectors.joining("\n"));// 3. 让LLM基于上下文回答return chatClient.prompt() .system("请基于以下资料回答:" + context) .user(question) .call() .content(); }}使用场景:企业知识库问答、智能客服、法律条文查询。
优点:答案可溯源、知识实时更新、防止幻觉。
缺点:多了一步检索,延迟增加;检索质量决定答案质量。
2.4 Agent(智能体)
一句话解释:一个能自主规划任务、调用工具、执行操作的AI程序。
通俗理解:普通LLM是“顾问”——你问它怎么办,它给你建议。Agent是“员工”——你给它一个目标,它会自己想办法完成,包括查资料、写代码、发邮件、甚至调用其他系统。
Agent的思考-行动循环(ReAct模式):

代码示例(使用Spring AI Alibaba的ReactAgent):
// 定义一个工具:查询天气@ComponentpublicclassWeatherTool{@Tool(description = "查询指定城市的天气")public String getWeather(@P("城市名") String city) {// 模拟调用天气APIreturn city + "今天晴天,25°C"; }}// 创建AgentReactAgent agent = ReactAgent.builder() .name("助手") .model(chatModel) .tools(new WeatherTool()) // 给Agent配工具 .build();// 用户只需说目标,Agent自己决定用哪个工具String result = agent.call("我想知道北京今天能不能穿短袖?");// Agent会:思考 → 调用天气工具 → 拿到天气 → 给出穿衣建议使用场景:自动化客服、代码自动修复、行程规划、数据报表生成。
优点:能自主完成复杂任务,减少人工介入。
缺点:Token消耗大,可能陷入死循环,需要精心设计。
2.5 知识图谱(Knowledge Graph)
一句话解释:用“实体-关系-实体”的三元组形式,把知识连接成一张网。
通俗理解:传统的知识库是一堆文档(像一堆散落的书),知识图谱是一张“关系地图”(像地铁线路图)。你能沿着关系线从“高血压”走到“布洛芬”,再到“禁忌”,从而推理出“高血压患者不能吃布洛芬”。
三元组示例:
(高血压, 症状, 头晕) (高血压, 禁用药物, 布洛芬) (布洛芬, 属于, NSAID类药物)
代码示例(使用Jena构建RDF知识图谱):
import org.apache.jena.rdf.model.*;import org.apache.jena.vocabulary.RDF;publicclassKnowledgeGraphDemo{publicstaticvoidmain(String[] args){// 创建空模型 Model model = ModelFactory.createDefaultModel();// 定义实体和关系(URI) String ns = "http://example.com/medical/"; Resource hypertension = model.createResource(ns + "Hypertension"); Resource ibuprofen = model.createResource(ns + "Ibuprofen"); Property contraindicated = model.createProperty(ns + "contraindicated");// 添加三元组:高血压 禁忌 布洛芬 model.add(hypertension, contraindicated, ibuprofen);// 查询:高血压禁忌什么药物? StmtIterator stmts = model.listStatements(hypertension, contraindicated, (RDFNode) null);while (stmts.hasNext()) { Statement stmt = stmts.next(); System.out.println("禁忌药物:" + stmt.getObject()); } }}使用场景:医疗诊断辅助、反欺诈(挖掘资金关系网)、智能推荐。
优点:支持多跳推理,关系清晰,可解释性强。
缺点:构建成本高,需要领域专家参与。
2.6 多模态(Multimodal)
一句话解释:同时处理文本、图像、音频、视频等多种类型的数据。
通俗理解:以前的AI只能“看文字”或“看图片”,多模态AI就像人一样,既能看懂文字,也能看懂图片,还能听懂声音。你可以给它一张图问“这是什么”,也可以让它“根据这张图写一段描述”。
代码示例(调用多模态模型API):
// 使用通义千问的多模态能力publicclassMultimodalDemo{publicstaticvoidmain(String[] args){ String prompt = "描述这张图片的内容"; String imageUrl = "https://example.com/cat.jpg";// 调用DashScope API(通义千问)// 实际请求需要构造JSON,包含image和text// 示例省略HTTP细节 }}使用场景:自动驾驶(图像+雷达)、视频理解、图文生成、语音助手。
优点:更接近人类的感知方式,应用场景更广。
缺点:模型更大、计算成本更高、训练数据更难获取。
2.7 微调(Fine-tuning)
一句话解释:在预训练的大模型基础上,用少量特定领域的数据继续训练,让模型适应你的业务场景。
通俗理解:大模型像一个读过万卷书的通才,什么都懂一点,但不够专。微调就像让这个通才去参加某个行业的岗前培训——给他看你们公司的内部资料,让他变成这个领域的专家。比如,让通用LLM学习法律条文后,变成法律咨询助手。
代码示例(使用Hugging Face的Java调用,伪代码示意):
// 微调通常需要Python环境,Java可通过HTTP调用微调服务// 以下为伪代码示意微调请求POST /v1/fine-tune{"model": "gpt-3.5-turbo","training_data": "company_qa.jsonl","epochs": 3,"learning_rate": 0.00002}使用场景:定制客服机器人、特定领域问答、代码生成模型适配公司代码风格。
优点:让模型更懂你的业务,回答更精准。
缺点:需要一定量的标注数据,训练成本较高(比RAG贵)。
2.8 向量数据库与Embedding
2.8.1 Embedding(嵌入)
一句话解释:把文字、图片等转换成一组数字(向量),让计算机能计算“相似度”。
通俗理解:想象把“苹果”、“香蕉”、“汽车”这三个词放到一个二维坐标系里,“苹果”和“香蕉”因为都是水果,距离近;“苹果”和“汽车”距离远。Embedding就是把这个“坐标”算出来。例如“国王-男人+女人≈女王”。
代码示例(使用Java调用Embedding模型):
// 调用OpenAI的Embedding APIString text = "人工智能";Request request = new Request.Builder() .url("https://api.openai.com/v1/embeddings") .post(RequestBody.create("{\"model\":\"text-embedding-ada-002\",\"input\":\""+text+"\"}", JSON)) .build();// 返回的embedding是一个float数组,如[0.012, -0.345, ...]2.8.2 向量数据库
一句话解释:专门存储和检索向量的数据库,支持“给定一个向量,找出最相似的K个向量”。
通俗理解:想象你有一个巨大的仓库,里面放满了带坐标的物品。向量数据库就是能根据你给的坐标,快速找出离它最近的几个物品。RAG中的“查资料”就是靠它完成的。
常用向量数据库:Milvus、Qdrant、pgvector、Chroma。
代码示例(使用pgvector):
CREATETABLE documents (idSERIAL, embedding VECTOR(768));CREATEINDEXON documents USING ivfflat (embedding vector_cosine_ops);SELECT * FROM documents ORDERBY embedding <=> '[0.1,0.2,...]'LIMIT5;使用场景:RAG、推荐系统、图像相似度搜索。
优点:检索速度快(毫秒级),支持海量数据。
缺点:需要额外组件,不如传统数据库简单。
2.9 工具调用(Tool Use)
一句话解释:让Agent能够调用外部函数或API,执行实际操作。
通俗理解:Agent光会想不行,还得会动手。工具调用就是给它配的“手”——可以查询数据库、发邮件、调用第三方API。比如,用户问“帮我订明天去上海的机票”,Agent会调用“查询航班”工具和“预订”工具。
代码示例(已在2.4的WeatherTool中展示,这里再补充一个更复杂的):
@Tool(description = "发送邮件")public String sendEmail(@P("收件人") String to, @P("主题") String subject, @P("内容") String body) {// 实际调用邮件发送服务 emailService.send(to, subject, body);return"邮件已发送";}优点:极大扩展Agent能力,让AI从“动口”变成“动手”。
缺点:需要安全控制,防止恶意调用。
2.10 ReAct模式
一句话解释:Agent的“思考-行动-观察”循环,让AI能像人一样边想边做。
通俗理解:ReAct是Reason(推理)+ Act(行动)的缩写。就像你做菜时,先想菜谱(思考),然后切菜炒菜(行动),再看看熟没熟(观察),如果没熟就继续翻炒。这个循环直到任务完成。
已在2.4的图中展示,这里补充一个更详细的解释:
代码示例(伪代码展示ReAct循环):
while (!taskCompleted) {// 思考 String thought = llm.think(goal, history);// 决定行动(如调用工具) String action = llm.decideAction(thought);// 执行行动 String observation = execute(action);// 记录结果 history.add(thought, action, observation);}优点:让Agent能灵活应对变化,自动调整计划。
缺点:可能陷入无限循环,需要设置最大迭代次数。
2.11 实体识别(NER)与关系抽取(RE)
2.11.1 实体识别(Named Entity Recognition, NER)
一句话解释:从文本中识别出人名、地名、组织名、时间等关键信息。
通俗理解:给一段文字,NER就像荧光笔一样,把“张三”(人名)、“北京”(地名)、“阿里巴巴”(组织名)标记出来。
代码示例(使用Stanford CoreNLP Java库):
import edu.stanford.nlp.pipeline.*;import edu.stanford.nlp.ling.CoreAnnotations;Properties props = new Properties();props.setProperty("annotators", "tokenize,ssplit,pos,lemma,ner");StanfordCoreNLP pipeline = new StanfordCoreNLP(props);String text = "张三在北京的阿里巴巴工作";CoreDocument doc = new CoreDocument(text);pipeline.annotate(doc);for (CoreEntityMention em : doc.entityMentions()) { System.out.println(em.text() + " -> " + em.entityType());}// 输出:张三 -> PERSON,北京 -> LOCATION,阿里巴巴 -> ORGANIZATION2.11.2 关系抽取(Relation Extraction, RE)
一句话解释:从文本中抽取出实体之间的关系,比如“张三是阿里巴巴的员工”。
通俗理解:NER找到了“张三”和“阿里巴巴”,RE则识别出他们之间的关系是“工作于”。
代码示例(使用预训练RE模型,伪代码):
// 输入两个实体,判断关系String relation = reModel.predict("张三", "阿里巴巴");System.out.println(relation); // "works_at"使用场景:构建知识图谱、信息检索、智能问答。
优点:自动从非结构化文本中提取结构化知识。
缺点:准确率依赖模型,复杂关系难以抽取。
2.12 文生图/文生视频
一句话解释:根据文字描述生成图片或视频。
通俗理解:你输入“一只猫坐在月亮上”,AI就能画出一张符合描述的图。代表模型:Stable Diffusion、DALL-E、Sora。
代码示例(调用Stable Diffusion API):
// 伪代码:发送POST请求生成图片POST /generate{"prompt": "一只猫坐在月亮上,卡通风格","width": 512,"height": 512}// 返回图片URL或base64使用场景:创意设计、游戏素材生成、广告制作。
优点:极大降低视觉内容创作门槛。
缺点:可能生成不符合预期的内容,版权问题需注意。
三、AI术语关系总结表
| LLM | ||||
| RAG | ||||
| Agent | ||||
| 知识图谱 | ||||
| 多模态 | ||||
| Fine-tuning | ||||
| Embedding | ||||
| 向量数据库 | ||||
| 工具调用 | ||||
| ReAct | ||||
| NER | ||||
| RE | ||||
| 文生图 |
四、如何使用这些技术?
在实际项目中,这些技术往往是组合使用的:
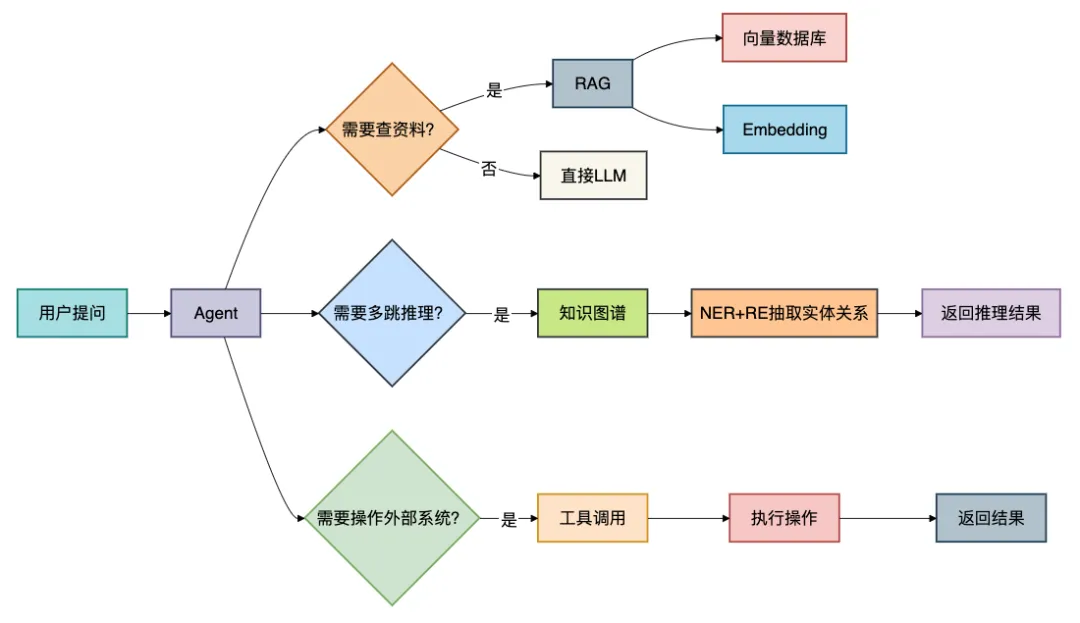
经典组合案例:
企业智能助手 = Agent(调度)+ RAG(查文档)+ LLM(生成答案)+ 工具调用(发邮件、创建工单) 医疗问诊系统 = 知识图谱(药品-疾病关系)+ NER(识别症状实体)+ RE(抽取症状-疾病关系)+ LLM(对话) 智能客服 = RAG(FAQ检索)+ Agent(多轮对话)+ 工具调用(查询订单状态)
总结
AI知识图谱不仅是一个技术概念,更是我们理解AI世界的“导航图”。
通过这张图,我们能够看清LLM、RAG、Agent、知识图谱、多模态这些看似孤立的术语之间的内在联系:
LLM是大脑,负责理解和生成语言。 RAG是外挂知识库,让大脑能查资料。 Agent是手脚,让大脑能做事。 知识图谱是记忆网络,让大脑能推理关系。 多模态是感官,让大脑能看能听。
此外,我们还深入了解了:
Fine-tuning:让通用模型变成领域专家。 Embedding & 向量数据库:实现语义搜索的基石。 工具调用 & ReAct:让AI真正“动手干活”。 NER & RE:从文本中构建知识图谱的利器。 文生图/文生视频:开启AI创作新时代。
希望这篇文章希望能帮你建立起AI领域的“知识图谱”,不再被那些“黑话”吓倒。
构建高质量的技术交流社群,欢迎从事编程开发、技术招聘HR进群,也欢迎大家分享自己公司的内推信息,相互帮助,一起进步!
文明发言,以
交流技术、职位内推、行业探讨为主
广告人士勿入,切勿轻信私聊,防止被骗

点下方的“❤”支持我们,非常感谢!
