 夜雨聆风
夜雨聆风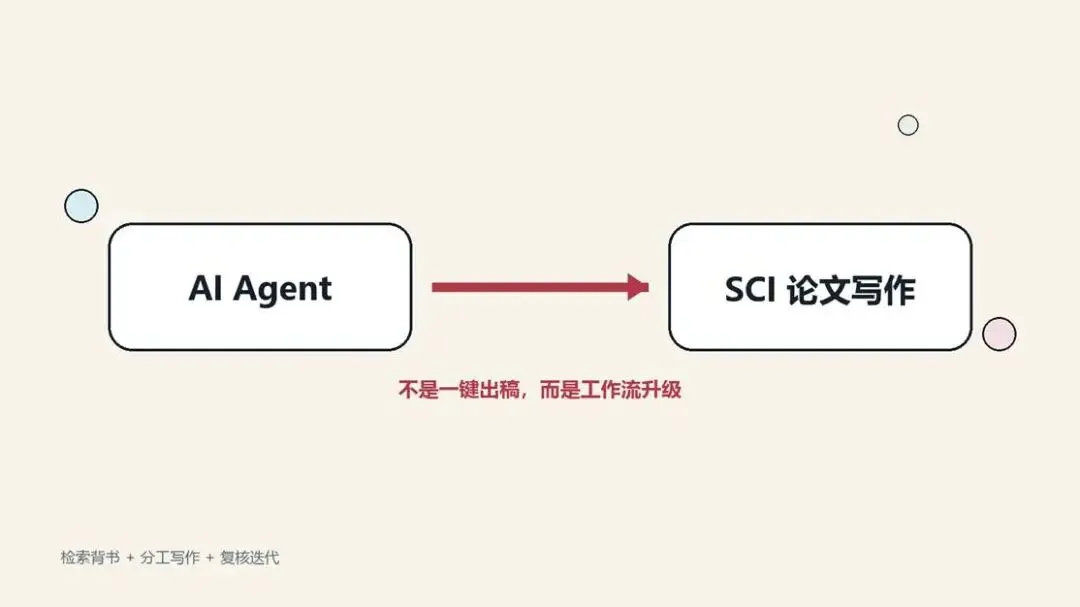
这两年,很多人一提到 AI 写论文,第一反应还是一句话:把题目丢给大模型,让它帮我生成一篇初稿。
但如果你真的看过近两年的 agent workflow 实践文章,再看几篇已经公开发表的自动综述写作研究,就会发现一个更接近现实的答案:
真正更稳的写法,不是“AI 一次性把论文写完”,而是把 SCI 论文撰写拆成一个闭环流程,让不同环节各司其职。
也就是说,AI 时代写 SCI,升级的不是某一句提示词,而是整条科研写作 workflow。
今天这篇推文,我不再按单篇论文解读写,而是把几类代表性材料合在一起,总结一个更适合现在科研工作者的做法:
·官方 agent 工作流经验:OpenAI 的 practical guide 与 Anthropic 的 agent pattern 文章
·自动综述写作研究 1:基于 RAG 与 modular agents 的 AI Survey Writer pipeline
·自动综述写作研究 2:基于 LLM 的 automated literature research and review-generation method
如果把它们放在一起看,一个结论非常清楚:AI 最适合做的,不是替你“冒充作者”,而是替你搭一个能持续产出初稿、持续纠错、持续补证据的科研写作系统。
先说结论:AI时代写SCI,最值得升级的是这4件事
·不要把论文写作理解成单轮对话,而要理解成多步骤任务流
·不要只依赖裸提示词生成,而要用检索、文献库、图表库来给内容背书
·不要一上来就追求很复杂的多智能体,而是先把单Agent+工具调用跑顺
·不要让 AI 直接交稿,而是一定要有评审器、核查器和人工终审
这4点,几乎贯穿了现在 agent workflow 和自动论文写作研究里的共同经验。
为什么“单句提示词写SCI”越来越不够用了?
因为 SCI 论文本来就不是一个单步任务。
它至少同时包含这些动作:
·明确研究问题和文章定位
·检索并筛选相关文献
·把文献内容转成可用证据
·生成提纲与章节结构
·按 Methods、Results、Discussion 等模块分别写作
·检查引用、事实、图表、逻辑和语言风格
如果你把这么多动作全塞进一句“帮我写一篇 SCI 论文”的提示词里,大模型当然也能给你一版看起来像论文的东西,但最容易出问题的恰恰也是这里:
·引用不稳
·细节容易幻觉
·章节之间前后不一致
·讨论部分容易空泛
·图表与正文不能互相支撑
所以现在越来越成熟的思路,不是让 AI “一把梭”,而是让 AI 在不同步骤里做不同事情。
官方agent工作流给了我们什么启发?
Anthropic 在 Building Effective Agents 里,把常见 agent pattern 讲得很清楚:最基础的 building block 不是某个神秘的超级智能体,而是一个被增强过的 LLM,也就是带有 retrieval、tools、memory 的 augmented LLM。
这句话对科研写作特别重要。因为它等于直接提醒我们:论文写作最核心的,不是让模型自由发挥,而是让模型在“能查、能调工具、能保留上下文”的环境里工作。
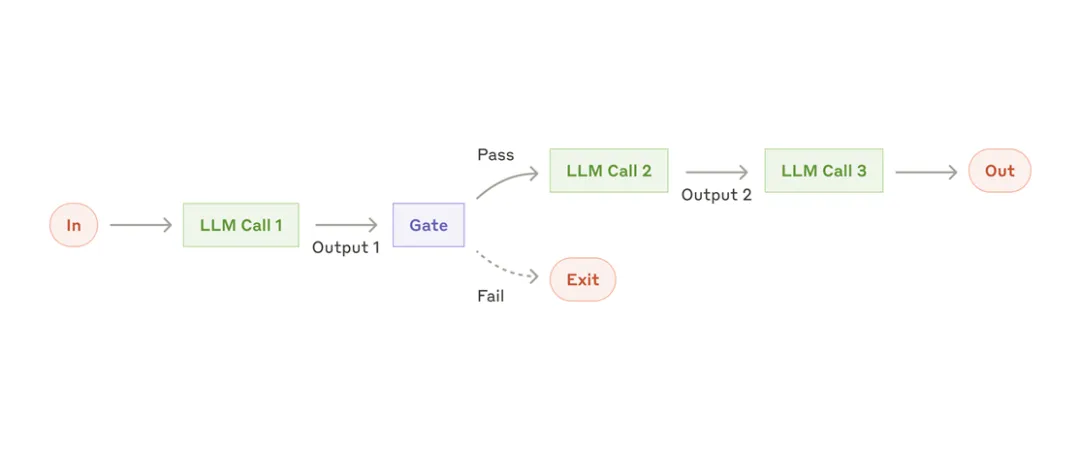
图1 Anthropic 的 prompt chaining 工作流:把一个复杂任务拆成若干有顺序的步骤,中间可以插入 gate 检查。
这张图最值得看的地方,不是“链式”这个词,而是中间的 gate。它的意思非常接近科研写作中的现实流程:前一步不过关,后一步就不要继续写。比如文献筛选没做好,就不要急着写讨论;提纲没定稳,就不要急着写全文。
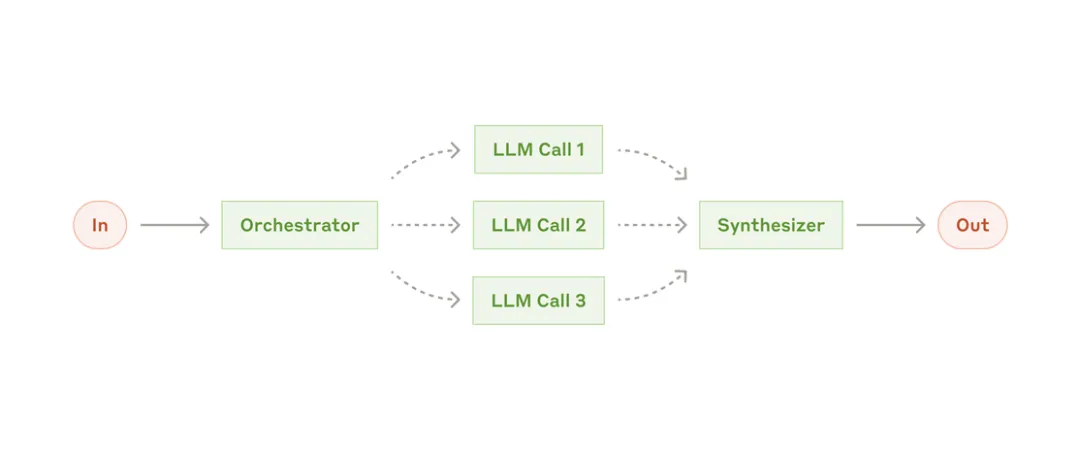
图2 Anthropic 的 orchestrator-workers 工作流:由一个总控负责拆任务,再交给多个 worker 分别完成。
这张图特别适合解释现在很多人说的“多Agent写论文”到底是什么意思。真正有用的,不是开很多窗口同时胡乱生成,而是让一个总控 agent 负责统一提纲、统一要求,再把不同模块交给不同 worker。对应到 SCI 写作里,最自然的拆法就是:
·一个 agent 负责搭提纲与文章定位
·一个 agent 负责文献检索和摘要整理
·一个 agent 负责 Methods/统计路径表达
·一个 agent 负责 Discussion 的对比与局限
图3 Anthropic 的 evaluator-optimizer 工作流:一个负责生成,一个负责挑错和反馈。
这张图其实最接近论文写作里真正决定质量的一步。因为很多时候,第一稿不是最难的,最难的是第二轮和第三轮修改。让一个 agent 写,让另一个 agent 专门挑引用问题、逻辑断点、术语不一致、结论过度外推,这个收益通常比“让模型再润色一次”更大。
OpenAI 的 practical guide 也强调了一个很重要的现实原则:先尽量把单Agent系统做到位,再决定是不是真的需要多Agent。对科研写作来说,这一点非常实用,因为很多课题组一开始并不需要搭特别重的系统,先把下面三件事做稳,效果就已经会比“裸聊式写论文”好很多:
·明确 instructions
·接上文献检索与本地资料
·给模型可调用的结构化工具
现在真正值得学的,不是“AI替我写”,而是“RAG背书”
下面这篇开放获取文章很适合拿来说明这件事:**AI-Assisted Tools for Scientific Review Writing: Opportunities and Cautions**。
它提出的不是一句话写综述,而是一条完整的 AI Survey Writer pipeline。最关键的设计,是先把资料变成三类数据库,再让 agent 去调用:
·Content RAG
·References BibTeX RAG
·Figures RAG
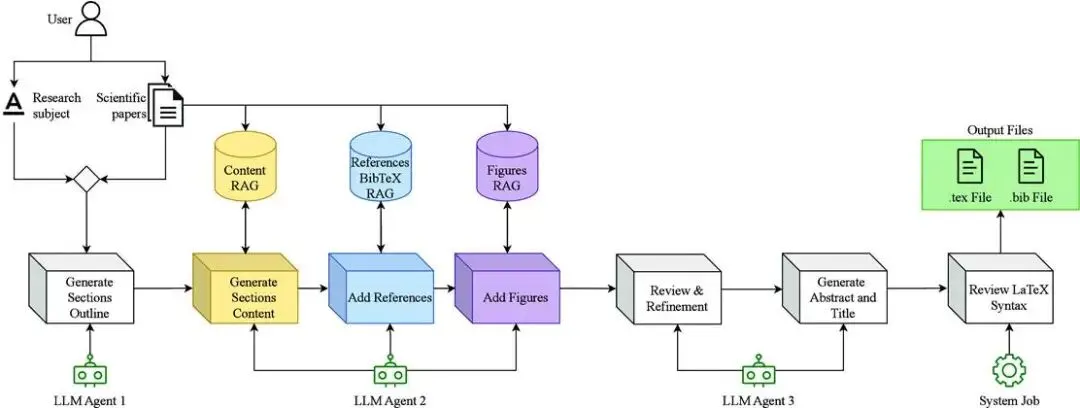
图4 AI Survey Writer 的完整 pipeline:从选题开始,到文献进入内容、引用和图表数据库,再进入章节生成与最后整合。
这张图的重点,是它把“写作”放在了“资料入库”之后,而不是之前。也就是说,先准备证据,再生成文字。这个顺序对于 SCI 写作几乎是决定性的。因为如果没有证据库做底座,模型写出来的内容再流畅,也很难真正经得起投稿时的细查。
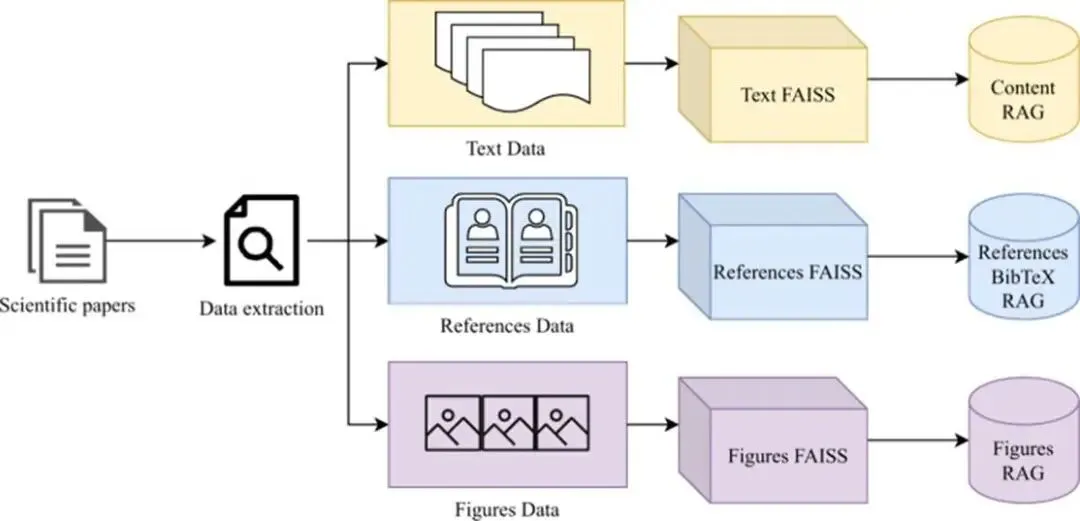
图5 AI Survey Writer 中的三类 RAG 数据库:正文内容、参考文献和图表被分开处理和检索。
这张图更值得科研写作者借鉴。它说明一个很朴素但经常被忽略的事实:论文不是只有正文。真正让文章变得像一篇论文的,还有引用、图表和结构。把这三类东西拆开存储、拆开检索,AI 写出来的文本才更像“有证据支撑的科研写作”,而不是“像论文的连续自然语言”。
这篇研究给出的态度也很克制:这种系统能生成 promising drafts,但还达不到顶级论文的 critical analysis 和 originality 水平。这个判断我很赞同,也很适合写进今天的结论里。因为它告诉我们:
AI 现在非常适合做高质量初稿系统,但还不适合被误解成“自动替代作者”。
第二个值得学的点:把“自动写作”做成一条可评估、可控幻觉的流水线
另一篇开放获取文章 **Automated literature research and review-generation method based on large language models** 更进一步。它不是只讲理念,而是把自动综述写作做成了一条可验证的方法学流程。
文中提到,他们的系统在一个具体案例里处理了 343 篇文章、35 个主题;而在数据挖掘部分处理了 1041 篇文章。更重要的是,这篇文章不是只展示“能生成”,而是同时展示“怎么控风险”。
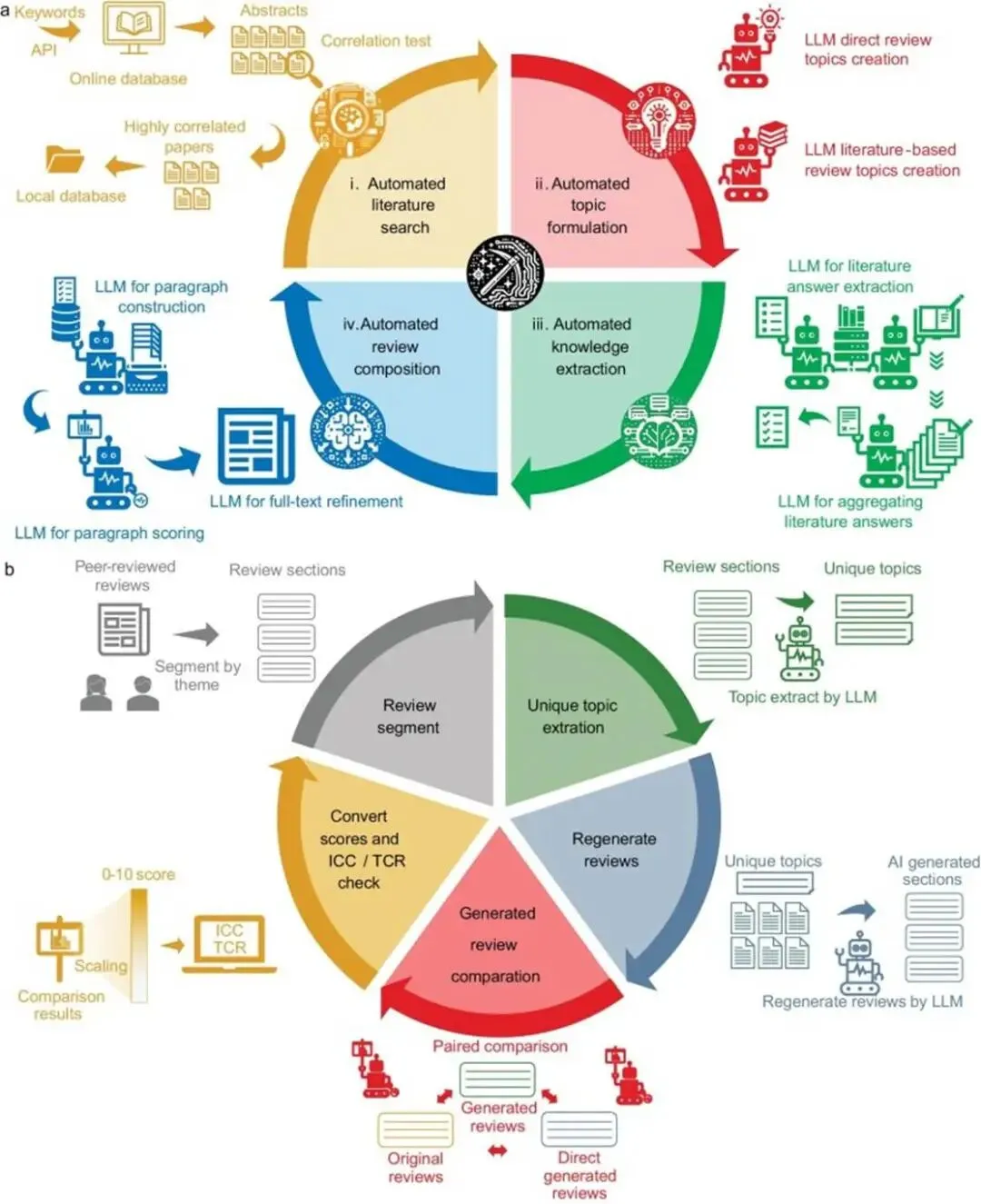
图6 自动综述生成方法的总流程图:从文献搜索、主题形成、知识抽取到 review composition,写作被拆成了明确模块。
这张图特别像一个已经能拿去复用的 SCI 写作方法模板。读图时要重点看它不是直接从“问题”跳到“全文”,而是把过程拆成了 literature search、topic formulation、knowledge extraction 和 review composition。对于真实科研写作来说,这种分模块做法比一句超长 prompt 更稳定得多。
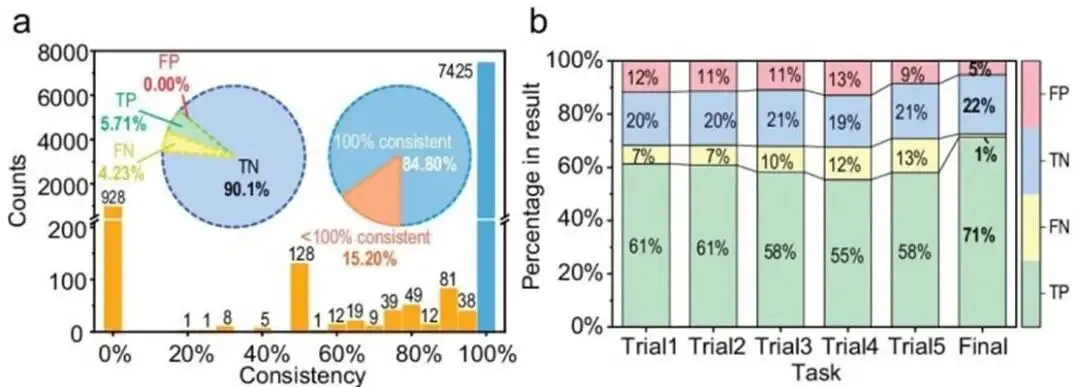
图7 自动综述生成中的幻觉控制结果:作者专门评估了直接生成与聚合后结果的一致性和误差。
这张图最重要的价值,不是告诉你某个模型多强,而是提醒你:如果你想让 AI 真正进入科研写作流程,就必须把 hallucination control 当成系统设计的一部分。文中提到,通过多层质量控制,幻觉风险可以被明显压低。这对临床科研或医学写作尤其关键,因为这里的错误不是措辞问题,而可能是事实问题。
所以,AI时代写SCI,最稳的一条工作流到底长什么样?
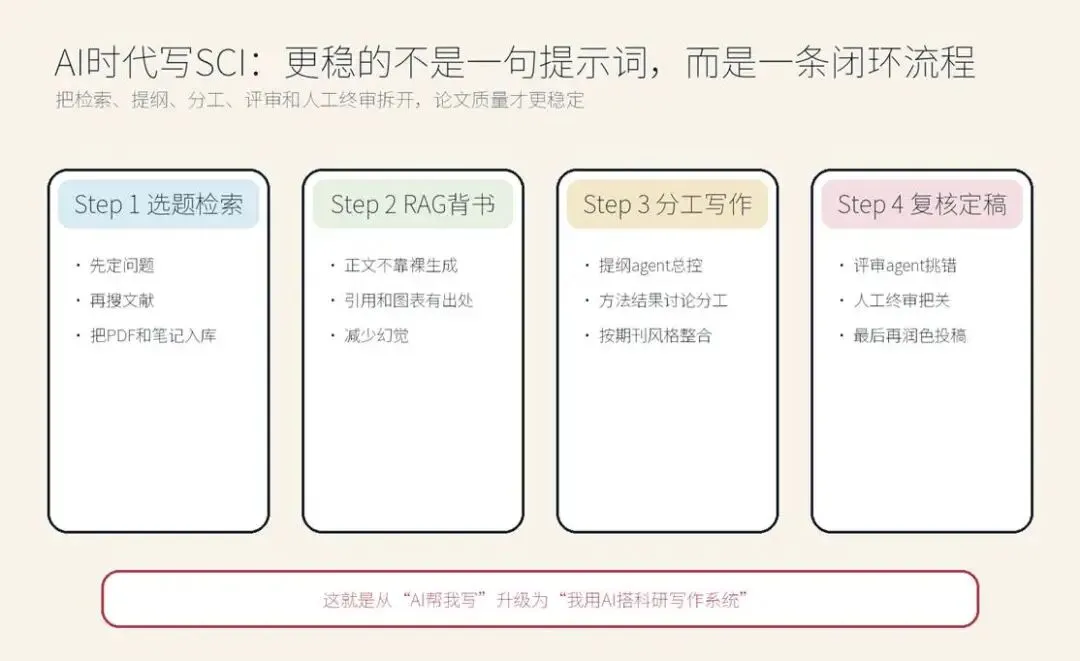
AI时代下更稳的SCI写作闭环:不是一句提示词,而是检索背书、分工写作与复核迭代。
如果把上面几类资料揉成一条适合大多数科研工作者上手的流程,我更推荐下面这个 6 步闭环。
第一步:先让AI帮你缩小问题,而不是直接写全文
最适合先交给 AI 的,往往不是全文写作,而是这几件事:
·帮你把题目收窄成一个可写的问题
·帮你列出关键词组合与检索式
·帮你把目标期刊风格转成写作约束
这一步更像“研究秘书”而不是“代笔作者”。
第二步:把文献、图表、笔记先入库
这是最像“背书”的一步。
你可以把 PDF、自己做的读书笔记、表格、既往项目结果、目标期刊 instructions 都放进一个可检索资料池。之后无论是写 Introduction、Discussion 还是图表说明,都尽量基于这个资料池生成,而不是让模型裸写。
对医学和临床研究尤其如此。因为很多时候,我们并不缺语言,而是缺“有出处的语言”。
第三步:先生成提纲,再分章节写
不要一上来就让 AI 连写 4000 字。更稳的做法是:
·先定标题与一句话主问题
·再定二级标题
·再逐段写每个 section
如果需要多Agent,总控 agent 最适合负责这里。它负责统一文章逻辑,避免 Methods 和 Discussion 像两个人写的。
第四步:把不同写作任务分给不同agent
这一步最常见、也最容易出效果的拆法是:
·检索 agent:找文献、做主题摘要
·提纲 agent:做结构、控制逻辑顺序
·写作 agent:按 section 出初稿
·审稿 agent:专门找漏洞、找夸大、找不一致
注意,这里不是为了追求“听起来高级”,而是为了降低一口气让同一个模型同时承担所有角色带来的不稳定性。
第五步:让评审agent专门负责挑错
真正让文章质量拉开差距的,通常是这一轮:
·这段话有没有证据支撑?
·这个结论是不是过度外推?
·前后变量名是否一致?
·图和文字有没有互相支撑?
·讨论部分是不是只在重复结果?
这一步如果只靠作者自己盯,很累;如果给 AI 一个单独的“审稿身份”,收益反而很高。
第六步:人工终审,尤其是医学/SCI写作
这一点我还是想说得明确一点:
AI 可以帮你提速、帮你搭框架、帮你生成初稿、帮你检查逻辑,但真正要对论文负责的,仍然必须是作者本人。
尤其是下面这些内容,不建议完全交给 AI 自动放行:
·研究设计是否成立
·统计解释是否准确
·研究结论是否越界
·引用是否真的匹配原意
·投稿前的伦理、署名与学术诚信问题
从今天开始,如果你真想把AI用进SCI写作,最值得先改的不是模型,而是习惯
你不一定需要一上来就搭一套很复杂的平台,也不一定非要有很多 agent。
但至少可以先把自己的习惯从下面这种方式:
·想到什么就问一句
·让 AI 直接写一段
·哪里不顺就继续追问
升级成这种方式:
·先定义问题
·再准备资料池
·再按步骤生成
·再做审稿式复核
这一步一旦改过来,你会明显感觉到,AI 不再只是一个聊天窗口,而更像一个能被组织起来的科研写作团队。
一句话总结
AI时代下,SCI论文撰写真正的变化,不是“AI会不会写”,而是“我们会不会把写作变成一个可检索、可分工、可复核的系统工程”。
谁先把这个 workflow 搭起来,谁就更可能在接下来的科研写作里,把 AI 用成生产力,而不是用成风险源。
工具推荐
如果你后面也想把自己的科研写作流程配套图做得更清楚一些,比如研究对象纳入流程图、章节逻辑图,或者把某个中介机制、分析路线画成更适合展示的图示,可以试试 TomatoStats,网址是 `www.tomatostats.com`。像 bar chart、study population flowchart、mediation mechanism diagram 这些图,用来配公众号推文或者给论文初稿补图,都会很方便。
