夜雨聆风
夜雨聆风
一、国内超节点需求端变化及主要厂商情况
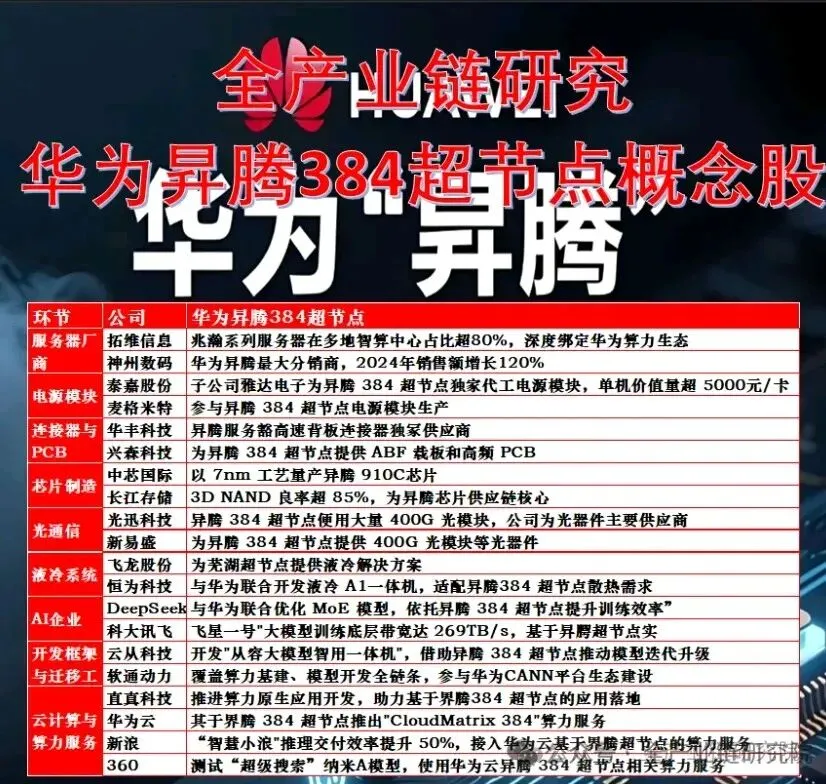
国内超节点当前以HW为主要出货厂商,其Cloud Matrix 384已在银行(工商银行、招商银行,各十余台)、央国企(国网)及政务机构(2-3台)批量部署,预计2026年出货量50-60台。互联网客户需求呈现分化:字节仅小规模测试HW超节点(3套),已转向自研并委托华三、中兴等8家ODM厂商设计,计划2027年超节点占比提升至80%;腾讯委托华勤设计超节点,2027年目标部署规模占算力总量50%,预计数量达数百台;阿里(盘古)、百度均推进自研超节点,2027年下半年需求将全面转向超节点。华三、浪潮等OEM厂商暂未实现大规模部署。
二、国产超节点部署的必要性及应用场景
国产超节点核心价值在于推理场景的性价比优势,较分立式八卡机集群性能提升20%以上,尤其适用于超大体量模型的并发推理。训练场景暂不具备可行性:国产卡算力较弱且定制化效率不足,即便构建超节点也难以承担大规模模型训练任务,当前训练仍依赖传统解决方案。
三、国内主要CSP厂商超节点进展
阿里:自研“盘久”超节点,支持第三方卡,2026年开始对外销售,内部阿里云暂未大规模使用。
百度:2026年内部超节点需求量对应近6万片卡,具体规模需结合单卡配置测算。
字节:“大禹”项目委托ODM厂商按规范设计,2027年将公开招标确定入围厂商及卡类型,全年超节点需求占比80%。
腾讯:仅向华勤开放超节点设计规范,2027年计划50%算力部署超节点,具体数量待整体算力规划确定。
四、国产超节点与海外高端超节点的性能差异及应用场景对比
国内超节点性能显著落后于海外,华为Cloud Matrix 384仅略优于NV172,与GT300差距达4-5倍,整体性能为海外产品的几分之一。应用场景分化:海外超节点聚焦大规模训练及训推一体,国内则专注推理场景的性价比优化,两者追求指标及业务场景差异显著。
五、国内超节点性能优势的核心差异因素
核心差异体现在两点:一是算力卡类型,二是scale up解决方案。ODM厂商超节点设计雷同性高,均强调对国产算力卡的兼容性,实际性能差异主要由单卡性能决定,超节点本身技术特性对性能影响有限。
六、超节点内部卡的功能划分及国产卡支持情况
Decoding:依赖HBM容量及带宽,国产卡普遍发力此方向,通过采用HBM2E/HBM3/HBM3E提升竞争力,部分卡容量达120-140G(类H200/H20水平)。
Prefill:依赖算力(FP8支持及TOPS值),受制于制程工艺(台积7nm/5nm算力上限400-500T,国产制程300-400T),各家差异较小。
国产卡功能划分需结合产品特性,部分厂商已推出分场景优化产品,但整体性能参差不齐。
七、超节点上游硬件环节的价值量变化及雷同性分析
国内超节点设计雷同性强,主流形态为64卡/128卡,PCB(M9/Q路板材)、液冷(国内供应商组合方案)、机架(第三方ODM)等环节供应趋同,价值量主要集中于算力卡。差异仅存在于网络解决方案(PCIe/OAM接口、网络交换机类型)及CPU/GPU配比。
八、第三方厂商超节点拓展情况
寒武纪、天数等厂商通过向ODM提供设计建议参与超节点方案,差异体现在compute tray与switch tray架构(如PCIe/OAM接口数量、网络接口方式),但机型近似性高,可互相套用。
九、超节点计算机柜配置方案
标准配置为16个计算节点(每节点4卡,共64卡)及16个交换节点,单卡对应1个网络接口(共64接口),需配128口交换机。51.2T带宽场景下需68颗交换芯片,GPU与交换芯片配比约1:2。
十、GPU数量增加对超节点架构的影响
GPU数量提升(如80卡、128卡)需增加compute tray数量(如3个tray,每tray含8模组)及采用双机柜拼接。互联方式从铜缆改为光纤,液冷需增加冷板数量及管路复杂度,供电功率提升,但无技术改良(国内未采用英伟达微循环方案)。
十一、国内自研超节点的价值量区间
64卡超节点:BOM成本300-330万元(含卡),售价470-600万元,包含计算节点、交换节点及PDU供电。华为384超节点:BOM成本8800万元,售价超1亿元。十二、整机厂商超节点与八卡机的盈利能力对比
超节点利润空间更高:系统设计及制造成本高于八卡机,可通过技术溢价提升盈利;八卡机同质化强、成本透明,技术元素少(如6U板、OAM模组为标准件),溢价能力弱。
十三、超节点用于训练的中长期展望及集群规模对架构的影响
短期内超节点无法用于训练:国产卡性能不足,分立式八卡机尚不能完成训练任务,超节点更无意义。国内万卡集群均用于推理,超节点因性价比优势(1.2倍提升)替代分立式方案。集群规模扩大(如10万卡)需突破交换解决方案,国内当前最大支持128卡,进一步扩展受限于交换芯片能力。
十四、国产交换芯片在超节点中的应用情况
国产交换芯片渗透率低:中兴微电子在自研超节点中使用自有芯片,云和智网处于评测阶段,盛科暂未应用;光交换以西质方案为主(OEM硬件+自研协议系统),整体仍以博通方案为主。
十五、超节点对网络和算力卡的性能要求及均衡规律
需平衡网络带宽、CPU内核数与算力卡性能:每100G网络占用1个CPU核(至强六代),单卡需20核CPU支持,如A100配400G网络为平衡点,避免“大马拉小车”(网络/CPU过强而算力卡弱)。
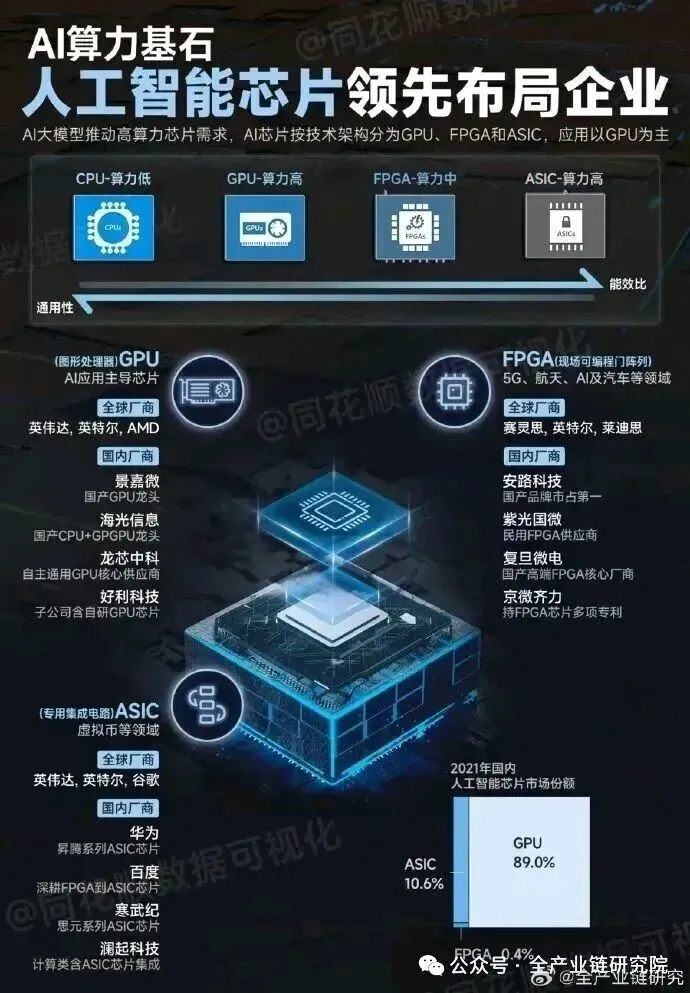
十六、国产AI芯片下一代产品技术比较
2026Q4多家厂商将推出对标H100/H200的产品,包括寒武纪690、华为950、沐曦C600、壁仞B220、天数天垓300、摩尔线程S6000及阿里PPU。技术路线分IC架构与GPU架构(类AMD),性能接近(制程、HBM带宽/容量趋同),竞争焦点为软件优化及供应链稳定性。
十七、超节点集群性能提升维度及规模放大效果
当前1.2倍性价比提升来自scale up方案(芯片直连带宽优化),规模超128卡后需依赖scale out,性能损失显著。国内交换芯片能力不足(51.2T vs 海外1024T),进一步放大效果有限。
十八、国产超节点与海外差距的未来趋势
短期内差距难以弥合:国内短板在单卡算力及网络互联(SerDes 112G vs 海外400G,交换能力51.2T vs 海外1024T),纯性能差距或持续拉大。国内聚焦推理场景性价比优势,GB300等海外产品在推理端不具备优势。
十九、国产卡不同出货形式的比例展望
互联网企业:2027年以超节点为主(字节80%、腾讯50%),追求推理性价比。其他用户:以八卡、十六卡为主,因管理维护便利。