 夜雨聆风
夜雨聆风一、显存是什么?AI计算的"厨房操作台"
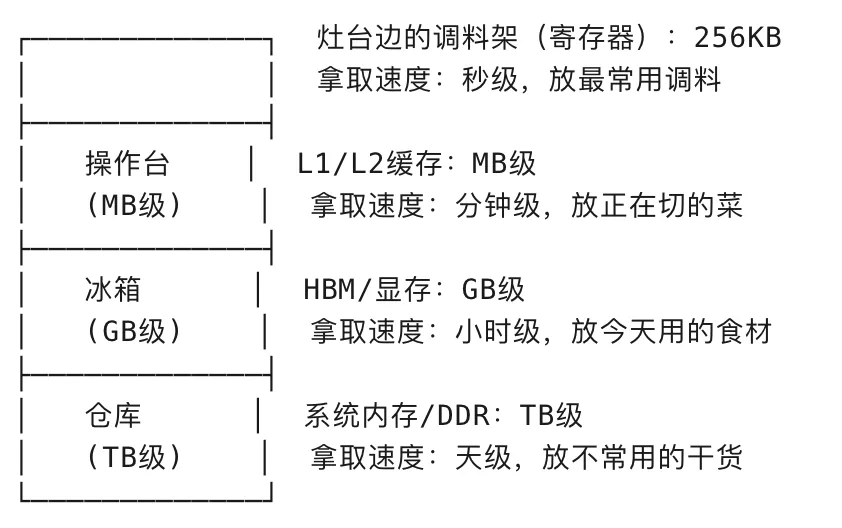
存放食材(模型参数)—— 鸡鱼肉蛋得摆得下
临时放半成品(计算中间结果)—— 切好的菜、调好的酱
快速取用(数据读取)—— 灶台边随手能拿到
显存的三大核心作用
GDDR6X是双向8车道(1008GB/s)
HBM3是双向32车道(3.35TB/s)
统一内存是双向4-8车道(256-819GB/s)
二、四大显存门派:不同的"物流方案"
1. GDDR:城市快送员(游戏显卡的"熟客")
随叫随到:技术成熟,成本可控
换车容易:显卡坏了换一张,升级方便
游戏优化:对画面渲染这种"短途配送"优化极好
车厢太小:单卡通常24GB封顶,装不下大模型
油耗太高:功耗450W,像 constantly 轰油门的跑车
长途不行:大模型需要频繁搬运数据,GDDR的"体力"跟不上
适合人群:游戏玩家、偶尔炼丹的轻度AI爱好者。
2. HBM:高铁货运专列(数据中心的"重器")
超宽轨道:1024-bit位宽(GDDR的32倍),一次能运32倍货物
零距离换乘:GPU和显存距离毫米级,数据"下车即到"
可加挂车厢:通过增加堆叠层数提升容量(HBM3e达12层)
HBM2(2016):8节车厢,307GB/s时速
HBM3(2022):12节车厢,819GB/s时速,带空调(ECC纠错)
HBM3e(2024):16节车厢,1.2TB/s时速
票价极贵:比GDDR贵3-5倍,一张H100显卡数万美元
车票难买:依赖台积电CoWoS封装产能,供不应求
专车专用:只有数据中心级别的"货运站"(A100/H100)能用
比喻:这是给"国家级物流枢纽"准备的方案,个人用户看看就好。
3. 统一内存:开放式厨房(个人AI的"新贵")
Apple Mac Studio(M3 Ultra):512GB超大操作台,819GB/s搬运速度
极摩客EVO-X2:128GB操作台,256GB/s速度,价格亲民
NVIDIA DGX Spark:128GB操作台,273GB/s速度,专业级品质
超大操作台:最高512GB,单机能摆下405B模型的"食材"(量化后)
转身即取:零拷贝,CPU切好的菜GPU直接炒,无需装盘搬运
省电:LPDDR电压0.95V,比GDDR的1.35V更节能
车道较窄:256-819GB/s带宽,比HBM的3.35TB/s慢
共用通道:CPU和GPU像两辆车共用一条道,偶尔堵车(带宽争用)
适合人群:个人AI研究者、内容创作者、预算有限但需要跑大模型的开发者。
4. 片上SRAM:厨房台面本身(极端路线的"偏锋")
伸手可取:片内带宽80TB/s,是HBM的20倍,延迟纳秒级
预约制:所有操作提前排好序(时序编译),运行时绝不卡壳(确定性延迟)
适用边界: 只能做"小份菜"(7B-13B模型)。要做大份菜(70B),得把食材分散到多个小厨房(多芯片并行),协调复杂度大增。
三、显存选型的"购物指南"
场景一:开中央厨房做大餐(大模型训练,100B+参数)
单卡H100(80GB车厢)
8卡并联组成640GB超级货运站
模型切分(Model Parallelism),像把大餐分多个灶台同时做
场景二:家庭厨房做私房菜(个人推理,70B-120B)
Apple用户:Mac Studio M3 Ultra(512GB超大中岛台,819GB/s传送带)
Windows用户:EVO-X2(128GB操作台,256GB/s传送带)
专业开发者:DGX Spark(128GB操作台,273GB/s传送带,CUDA生态)
场景三:快餐店出餐(实时交互服务)
极致速度:Groq LPU(预约制,确定性出餐,但只能做小份)
平衡方案:H100/H200(大容量冷库+高速传送带+TensorRT优化)
成本敏感:统一内存 + vLLM/TensorRT-LLM(软件层面的"动线优化")
场景四:户外野炊(端侧设备,手机/IoT)
手机SoC内置NPU(如Apple Neural Engine)
模型压缩至1-10B参数(便当盒大小)
INT4/INT8量化(食材预处理,缩小体积)
四、显存技术的未来:"智慧物流"演进
1. 近计算存储(PIM):仓库直接加工
2. CXL互联:跨厨房联动
3. 新型存储器:更高效的保鲜技术
MRAM(磁阻RAM):非易失,断电不丢数据,接近SRAM速度
ReRAM(阻变RAM):更高密度,更低功耗
4. 光学互连:光速传送带
结语:选显存就是选"厨房动线"
容量公式:食材总量(模型参数)× 包装大小(精度)≤ 操作台总面积(显存容量)
带宽公式:传送带速度(带宽)÷ 单次搬运量 ≈ 等待时间(计算单元空闲率)
延迟公式:首道菜时间 = 备料时间(数据加载) + 烹饪时间(计算)
