 夜雨聆风
夜雨聆风关注我,了解更多 AI 技术与产品形态讲解
想要与我讨论问题公众号发送 “QQ”
关于 AI Agent 教程的第二弹,其实我思考了很久。关于到底要些什么内容,思来想去,我认为在 AI Agent 时代让我的观众拥有一个相当好的基础仍然是一件很重要的事情。基础不牢地动山摇。这句话,在AI时代仍然是适用的。
所以在正式讲解那些可以直接拿来用的 Agent 技术之前,我觉得有必要花第二个章节的时间,来向我的观众简单科普一下一些非常必要的关于大模型的通识知识。当你了解到这些通识知识之后,你不仅仅可以更加顺畅的理解我们后续的教程,也能用来更好的在生活中利用你现有的大模型,帮你完成工作。
虽然大模型的技术更新的非常之快啊,但是在多年的技术进步与竞争淘汰中,有大量的技术和名词被沉淀了下来,这些名词大概率在未来是不会发生很大的变化的。因此,掌握它们是一件非常有必要的事情。理解这些名词的,不仅可以让你更加快速与方便的看懂各个大佬与 KOL 写的文章,也能让你更加清楚的知道当你想要使用这类技术的时候,应该怎么去搜或者是怎么询问大模型。毕竟正所谓人们不知道他们不知道的东西。
2.1 什么是大模型——一栋庞大的摩天大楼
大模型其实就是一个非常复杂的深度学习模型,它是一段占用大量内存的电脑程序。我们往往使用“参数”这个词来形容深度学习模型的大小,而大模型顾名思义就是参数量非常庞大的深度学习模型。而在如今这个时代,对于大部分的普通民众来说,他们基本上已将「大模型、深度学习、深度神经网络」和「AI」划上了等号,但其实前者之间更多是个包含的关系,不过这对于我们理解后续的内容而言并不重要。
不理解什么是「非常复杂的深度学习模型」的朋友,我可以打一个比方。比如你们所在城市的摩天大厦,这个摩天大厦的每一层的每一个小隔间其实都不是很复杂,你甚至可以记住每一个小隔间的桌子椅子大概是怎么摆放的,并在一些模拟游戏里面将它复刻出来。但是整栋摩天大厦的复杂度就非常非常高,给你无限的材料,你几乎很难复原出整个摩天大楼里面的每一个细节。你可以将这里摩天大厦的每一层比作是一个非常基础的函数。比如说它可以是你们高中所学习到的1元2次函数,或者是一个稍微复杂一点的矩阵与矩阵操作的函数。而「复杂的深度学习模型」就是若干层这样的函数的堆叠,就如同这个复杂的摩天大厦,是无数个小隔间组成的无数个楼层的堆叠一样。稍微有点数学基础的朋友都知道函数的堆叠也是函数,所以你完全可以将深度学习模型等同于一个很复杂的函数,这两个是一个意思。至于具体的细节的话,感兴趣的朋友可以去学习一下,深度学习这门课。这里推荐大家可以看一下我的知乎专栏 机器学习幼儿园,无论从基础的机器学习概念,还是到稍微复杂一点的深度学习,还是到工程化的深度学习框架原理解析,一应俱全。
大模型技术的研发最早可以追溯到 2015 年,各项基础技术与理论验证储备的完善是在 2020 年,第一个爆款的商业大模型 ChatGPT 则出现在 2022 年,基础模型的预训练能力在 2025 年被验证基本收敛(这一点目前学界与业界仍然有争议。但是基于目前已有的算力登记和公开高质量数据而言,事实上的通用文本大模型能力在 2025 年年中的时候被验证基本收敛),而能力基本收敛,你可以简单理解成在基础训练范式不变的情况下,未来出现的大模型和现在最厉害的大模型相比,再也不会出现质的上的能力飞跃了。
而大模型基础能力的基本收敛是业内开始全面转向大模型应用开发,而非基础模型能力研发的一个重要标志,当然,这些都是我们后续需要了解的内容了,「如何将大模型做成 Agent?」,我们先按下不表。
2.2 那些你听的很多,但是不一定了解含义的名词
相信很多朋友都经常听到各式各样的科技文章、新闻稿、大佬的演讲,这里面提到各式各样的术语,「多模态」、「token/词元」、「上下文」、「提示词」。你或许对他们已经很熟悉了,但你不一定完全理解他们是怎么回事儿。我们这就给各位扫扫盲。
想要对这些术语有一个受用终身的理解程度,需要我们对大模型的工作原理有一个稍微形而上学一点的理解方式。放心,这里面不会涉及到什么让我亲爱读者望而却步的复杂数学公式。你们想一想就知道了,电脑和智能手机出现了这么多年,大家都已经对它们习以为常了。但是在我们的日常生活中,真正能讲明白这些复杂装置的人少而又少。但这并不妨碍我们大部分人对计算机电脑的基本原理有一个大致的理解。
就算你完全不理解磁盘、内存、CPU 这些东西,大家还是大概知道它是个什么东西的。虽然关于这些玩意儿是怎么组装成一整台电脑的,并不是每个人都能讲清楚。所以我认为在大模型时代,我们对于「多模态」「上下文」等术语的理解,在未来也会类似于如今人们对于电脑中内存和CPU的理解程度。大概知道有这么一个东西和大概知道它是什么。但是具体怎么组装,不知道。而我们对于大模型术语的理解达到这一层,其实也就够了。
2.3 大模型的基本原理(超级简单版本)
我们在前文说过的了,大模型的本质就是一个复杂的函数,它输入一些数字,然后再输出一些数字。但是我们看到的东西,它其实是文本,所以我们需要一套对应的编码与解码器,编码器能够将我们的文本编码成对应的一组数字,而解码器则能将一组数字解码成对应的文本。
而实际上的 openai 协议下大模型服务其实是会走EOS编码和对应的一套自循环的程序,但是为了方便非技术背景的朋友也能理解,所以我们目前所描述的是一个简化版本的大模型。真实的大模型,它的一个输入输出与我们描述的略会有一点差异。但是我觉得这并不影响我们对于它的理解。
具体的,可以看下面这张图理解「大模型是怎么回答你的问题」这件事。
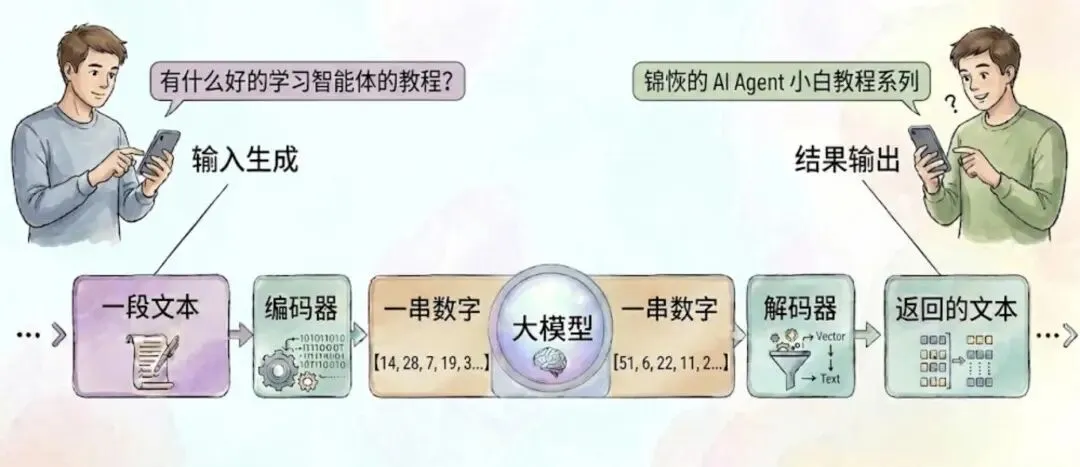
比如点进这篇文章的读者们想必都是想要学习智能体相关的教程的。那么当你询问大模型「有什么好的学习智能体的教程」这个问题的时候。其实经历的步骤非常简单,就如同上面流程图的几个步骤,请静下心来,我将为你非常通俗易懂的解释这个过程发生了什么。因为这对于我们理解上面提出的那几个专业术语来说非常重要。
首先我们在之前说过了,大模型的本质就是一个非常复杂的函数。既然是函数,那么输入的就必须得是数字,输出的也是数字,就如同 f(x) = x + 1 一样,这个函数的输入是数字,输出也是数字,你可以把f(x)就当成是我们的大模型,而 x 就是我们输入的这个文本。
但是文本是无法直接参与数学运算的,所以我们需要特殊的程序,来将文本转化为数字,并能够再将数字转化为文本,这是一个完全对称的过程。而将文本转换为数字的,就被我们称为编码器,反之就被我们称为解码器。
任何尝试将一个自然事物或者形式语言使用特殊的数字序列来表示的过程都可以成为编码,反过来可以称为解码。比如我们将一段现实生活中演奏的音乐刻录到你的手机里面。这个过程其实就是对音频的编码;而反过来,我们的耳机其实就是存储在手机里的这段音频的解码器,它能将这些存储在手机的编码重新转换成悦耳动听的音乐(当然,具体怎么将一段二进制转换成好听的音乐就有讲究了。所以音乐发烧友们制作了各种各样的音频解码器,所谓音频解码器就是这玩意儿)。所以编解码的概念是非常广泛的。由于计算机本身存储和处理数据都必须通过二进制的方法来进行。因此,任何物理世界对于计算机的交互一定会经过编解码。对于大模型而言也不例外,只不过我们和大模型交互是通过自然语言来的。
所以我们问了「有什么好的学习智能体的教程」时,实际上它经历了这么几个步骤:
「有什么好的学习智能体的教程」-> 把这串文字搞成数字(一般是长度略低于输入字数的一串数字)-> 输入大模型 f(x),计算得到结果 -> 把这串数字搞成文本 -> 「锦恢的 AI Agent 小白教程系列」
这个 f(x) 本质就是一个比你初中高中看到的那些函数复杂的多的函数,只不过其实它也没有复杂到,只有天才才能看得懂它的结构。因为大模型的本质就像是一座摩天大楼。虽然整体看上去极其复杂,但是每一层的每一个小隔间非常简单,只是通过一些科学的方法将这些小隔间堆积在一起之后,形成了我们能看到的庞然大物。
而我们算法工程师要解决的问题就是如何去设计这样的一个小隔间,以及如何更加有机的把这些小隔间融合在一块,形成一整个摩天大厦。嗯,如何设计和开发出这个 f(x) 其实就是大模型算法工程师要做的事情了。
怎么样,看着也并不是很难吧?只是不同的是真正盖一座大楼,以混凝土钢筋为原料,以各种工程器械为工具。而我们开发大模型则以大数据为原料,以显卡/AI 计算卡为工具。他们遵循的工程学方法论实际上是如出一辙的。
我希望大家可以充分理解一下这个过程中的一个基本流程。因为只有当你彻底理解了上面这个大致的流程之后,你才能更好的理解我们后面要讲的那些术语的本质。
2.3.1 Token:大模型理解信息的基本单元
在刚才的描述中,大家也能看到大模型的实际输入并不是我们询问的文本,而是文本编码之后的一串数字。那么具体文本变成数字是咋变的?有什么直观的玩意儿能让我更好理解这个过程吗?
有的兄弟有的。
我花了 5 分钟做了一个简单的网站来演示大模型运行的过程中,是如何把文本变成一串数字的。访问这个网址:https://kirigaya.cn/ktools/tokenizer
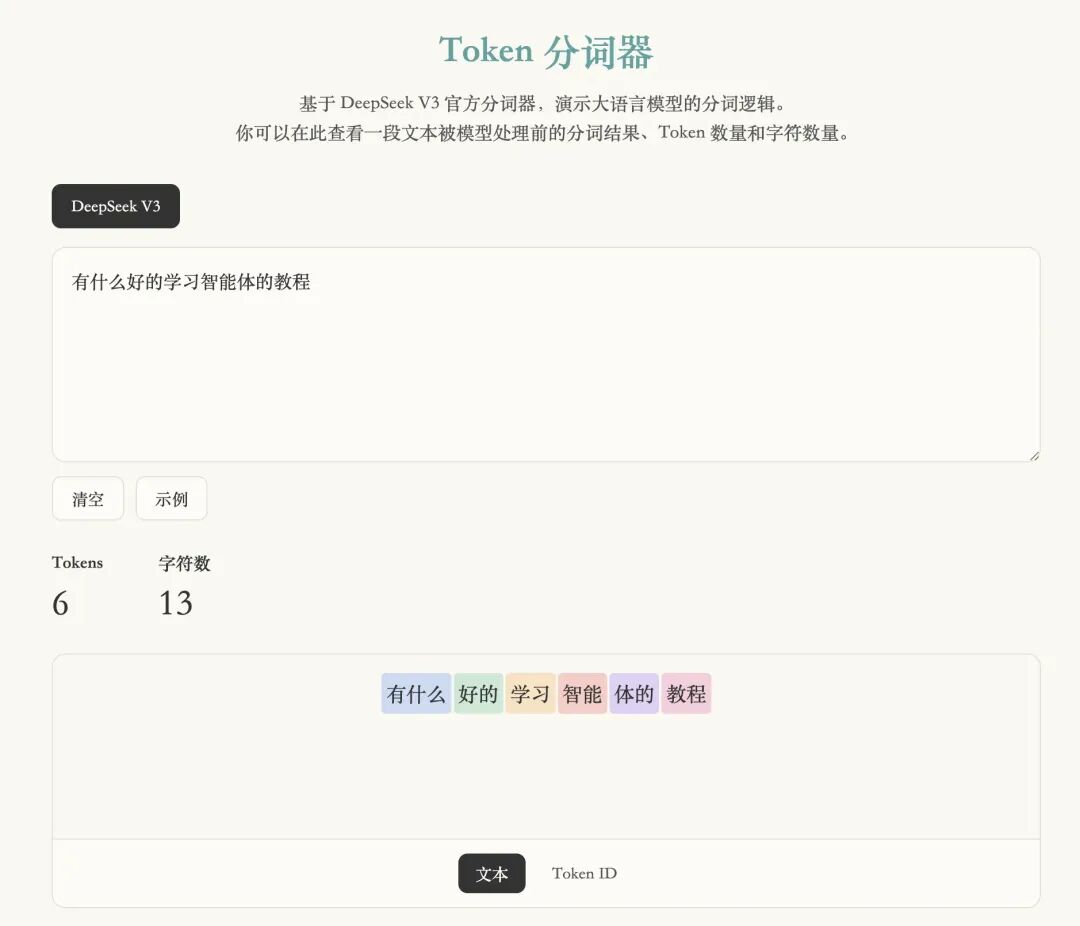
网页加载完成之后,点击一下上图的这个「示例」部分,你就可以看到在我们的这个教程中间「有什么好的学习智能体的教程」这个问题,大模型是如何把搞成一串数字的。
你能看到我们输入文本之后,编码器首先会通过一些方法将我们的这个句子切分成好几个基本的词语组合。
在 NLP 和大模型发展早期的时候,我们更习惯的将这样的一个编码器称之为分词器 tokenizer,这对应于传统自然语言处理中的一个非常经典的任务,也就是分词。对于这部分原理感兴趣的朋友可以去了解一下隐马尔可夫场,它们内部的数学原理和你正在使用的拼音输入法是一样的。想要亲手实践了解这个分词器内部的具体实现方法,可以参考我在多年之前写过的一篇教程:https://zhuanlan.zhihu.com/p/262949928
然后我们可以再点击一下「Tokens ID」
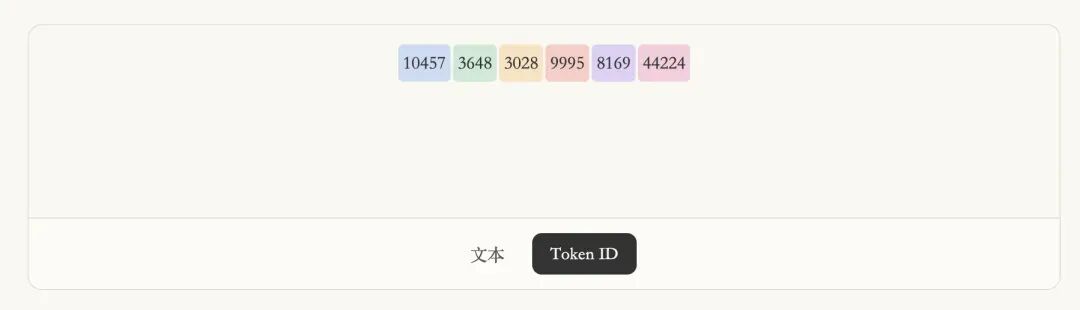
你会发现编码器就能再将这些切分好的词语映射成一个又一个的数字。
这些数字和词语的映射关系往往是我们在训练大模型前期进行数据处理的时候就提前准备好的。所以你完全不用在意为什么这些数字是这样。因为它们本身并没有意义,只是一个无意义的编号。
而将当我们将这样的一串文本通过上面的一系列步骤变成这样一串数字之后,数字就可以直接输入大模型里面参与运算了。
同样的,如果我们拿到了大模型输出的形如上图的这样的一串数字,也可以通过完全相反的操作,将它在解码成文本。比如上图最后一个「44224」对应「教程」,我们可以把「教程」这个词语翻译成「44224」。反过来,如果大模型 这个复杂的函数吐出了「44224」这个数字,我们就知道大模型是在告诉我们「教程」 这个词语。这是一个完全对称的过程。
相信大家平时用过的大模型也不少了。豆包,deepseek,ChatGPT,对于不同的大模型来说,由于处理数据的过程不太一样,所以他们的这样的一个编码和解码的过程也并不完全一样。同样是「教程」这个词语,它在deepseek这个大模型里面映射成「44224」,但是在别的大模型里面可能就映射成别的数字了。
而编码器中将这个输入文本切成词块之后,这每一个词块其实就被我们称为 token。
对于我们上面这个例子来说,我们输入的一共是13个汉字,而被切分成的是6个基本单词,所以这个句子对应的token数量是6。大家可以试试用其他的汉字或者是英文数字来看一下结果。但无论怎么样,你都会发现token的数量永远是小于你输入的字符数量的。
而大家可以看到啊,实际上是这些分词之后的词块所对应的数字参与大模型的后续运算。所以对于大模型本体来说,它的一个输入的基本单元并不是我们在和豆包交流时,语音输入或打字写的那一个又一个汉字。对于大模型来说,它的基本单元是这样的一个token。也正因如此呀。所以各个厂商的计费方式都是按token来计费的。
对于很多普通人来说,他们可能知道token多少钱一斤。但是他们或许并不了解,你真的和大模型在聊天的时候,这个词语到底指什么。但看完今天这期教程之后,相信大家对这个词应该有了一个相当本质的理解。
所以一言一蔽之,对于人类来说,我们理解消息的基本单元是一个又一个汉字或一个又一个英文单词,或是其他种族语言的基本词元,但对于大模型来说,它理解信息的基本单元就是这样一个又一个token。
只不过英文单词对于中国老百姓来说有点不太友好,所以我国的官方在2026年的时候,正式将token这个词翻译为了词元。
2.3.2 你的 token 又何只是文本?多模态大模型
通过上一个章节的描述,大家不难看出token和词语基本上就是一个东西,只是有一层非常浅薄的对应关系而已。但是实际上我们的野心远不只此。毕竟对于人类来说,我们每天能接收到的信息80%以上都来自于眼睛看到的东西。一个正常人类每天处理的信息量中,真正由纯粹的文本所代表的逻辑信息,并不占主要部分。
正因如此,如果我们想要让大模型变得更加通用和智能,就绝对不能只让大模型有能力计算文本再输出文本。我们还需要让大模型能够处理日常生活中能看到的图像、音频甚至是视频。
不过我讲课一般不喜欢把阵子铺的太开,所以我们这边只讲输出文本的大模型。而那种能帮你画图,能帮你写歌,能帮你做出卖货视频的大模型,并不在我们本文的讨论范围内。
如果真的理解了上一个章节,我们谈论的关于编码器与解码器的理解,相信一些聪明的读者已经想到怎么做,才能让大模型可以理解这些纷繁复杂的输入格式了。我们只需要为这些不同类型的多媒体格式分别实现它与大模型之间的编码器就行了。
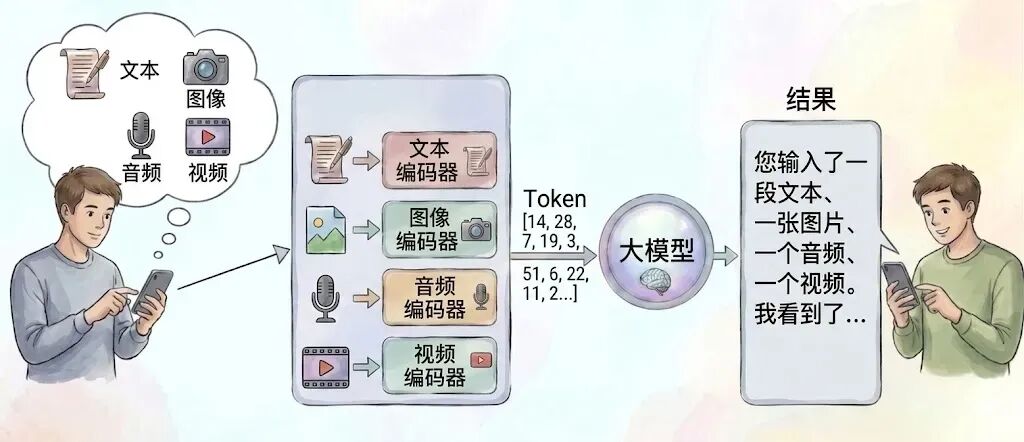
我们只要把这些多媒体,包括文本在内的信息全都把它映射成这样的一些token,那么就大功告成了。当然,具体是怎么实现的,对这个方向感兴趣的朋友,想要深入研究的,我推荐可以从transformer和CLIP这两项工作开始看。我在这里就不赘述了,因为理解这些更加深入的原理,对于我们后续开发工作智能体并没有太多的直接帮助。
没有直接帮助,但是可能会有一些间接的帮助。因为当我们在训练这些大模型和对应的编码器的过程中间,会将很多的专业术语和想要的一种视觉听觉效果绑定在一起。所以如果你能知道这些编码器是怎么被训练出来的,你就知道有哪些特定的专业术语,是被对应到一些很好的实现效果里的。我在这篇知乎问答里面举过一个很小的例子:
在AI能秒答一切的时代,人的核心竞争力到底是什么? - 锦恢的回答 - 知乎
https://www.zhihu.com/question/1992302419741266883/answer/2021874007222355382
回到我们讨论的话题中来,假设我们已经实现了这样的一组编码器,使得大模型能够真正的去计算这些图像音频视频等等多媒体的信息,那么我们就称这样一个大模型是多模态大模型。
多模态这个词并不是在大模型时代才出现的,这个词的出现已经很长时间了。在机器学习领域,甚至是更加古早的模式识别领域,我们通常将涵盖了不同信息类型的数据集称为多模态数据,而能处理它的模型/程序/装置,就被称为多模态处理机。比如在军用领域,能够同时通过热成像图片、RGB图片和深度图片进行一些综合工作的无人机处理模块,我们就可以将它称之为是多模态的。在医学影像领域,能够同时根据 MRI,CT 给出病人的影像级诊断的 AI 程序,也可以称之为是多模态模型。
目前大部分主流的模型几乎都已经实现了对于图像的支持(比如月之暗面的kimi,阿里巴巴的千问,谷歌的 gemini,还有openai的ChatGPT等等),而对于音频和视频的支持,很多不做,并不是因为技术达不到,而是因为没有这个必要。
讲到这里可能有的观众会非常好奇,既然我们已经实现了对于这些多媒体的编码器,那么这些编码之后的图片、音频、视频,它们的token又是多少呢?毕竟对于大模型来说,token是它处理信息的基本单元。那么它处理编码之后的图像、音频、视频也是要把它当成token处理的。那么一张图片的token大概是多少呢?
那么我们就得知道对于图像这种特殊类型信息,大模型是如何的把它从图像编码成对应的token的。其实做法也非常简单:我们会把 512 乘 512 像素点(或者是别的尺寸)看成是一个 token,然后把图片像做皮蛋拌豆腐时,切豆腐一样切成 N 块 512 乘 512 像素点,那么这张图片它被编码后就是N个 token。
下面这张表描述了主流模型中,不同尺寸的图片分别会被编码成多少的token。
| 图片规格 | GPT-4o / 5 (高精度) | Gemini 3 (标准) | Qwen 3.5-VL | 形象类比 |
|---|---|---|---|---|
| 头像/Icon (100x100) | 一封短邮件 | |||
| 高清照 (1080p) | 一篇 2000 字长文 | |||
| 超清全景图 (4K) |
只有当我们了解了这些重要的信息,我们才能在后续开发我们的智能体的时候,知道我们当前的这样的一个基本输入,大概会消耗多少的token和多少的资源。从而更好的为我们商业化来做成本估算。
这里不得不插一句题外话了,相信大家经常会把PDF这种特殊的格式扔进大模型里面,让它帮你总结内容或者是做一些概括。相信大家在读论文的时候,这一个操作应该是经常做的。很多人可能会下意识的认为大模型处理PDF的做法就是将PDF里面的文本读取出来,然后把它作为正常的文本信息进行后续的计算和处理。但实际上对于某些特殊的大模型。比如说 gemini 来说,它会先将PDF转换成对应的图片,然后将每一页的图片作为上下文再去处理得到最终你要的结果。而为什么要这么做呢?这是因为如果你将这一页的PDF当成文本来处理,它所消耗的token是大于把PDF看成图片所消耗的token的。而如果你学习完了本章节的内容,对于图片在编码之后占据的token量有了一个大概的了解,你就应该能够理解为什么这句话是对的了。
部分读者可能又会好奇了,哎,既然如此,我们能不能利用这种做法来大幅的压缩token的消耗量为我们的服务省钱。事实上,有不少团队在这一个方向都进行了一些探索。而一项我个人认为很系统的工作就是deepseek在去年发布的 deepseek-ocr,这项工作系统性地研究了在什么情况下,我们使用图片这种格式来取代文本,能够得到一个性价比更高的结果。作为拓展读物感兴趣的朋友们可以去看一看。
2.3.3 拓展阅读(可跳过):全模态 Omni
既然我们在上节里面讲到通过改变编码器,就可以让大模型输入文本音频图像这些东西,让它能够理解这些多媒体。那么我们能不能也改变解码器,让大模型输出的结果可以被翻译成这些图片音频和视频呢?
假设我们实现的这一件事情,是不是就可以得到类似于这样的一个大模型的概览图了呢?
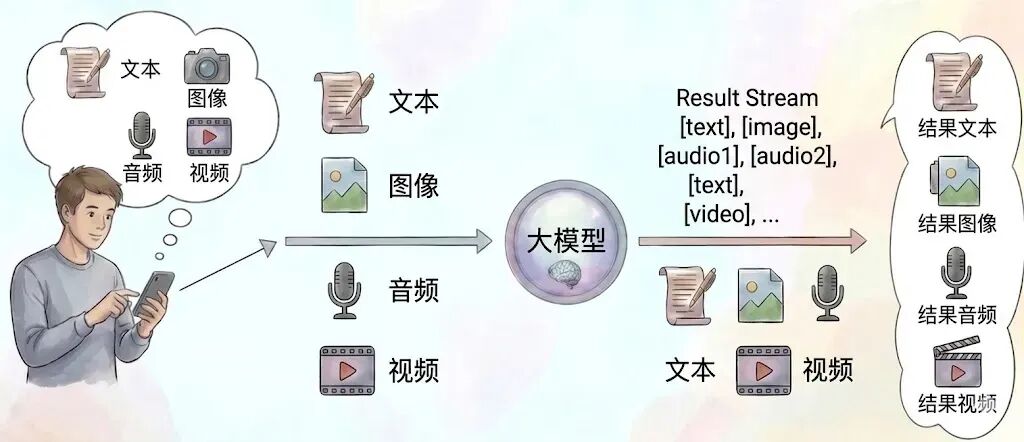
你很聪明,能想到这样的一个事情,这便是我们现在做的。而支持这样输入任何的文本,图像,视频,输出任意文本,图像,视频的模型,被我们称为全模态大模型,英文简称 Omni。如果你们未来看到了任何一个新闻报道里提到了 Omni 这个的英文单词,你们就应该知道这个大模型的突破点就在于它是支持全模态的。你们并不需要知道它内部的原理和训练方法。你们只要知道它支持什么样的输入和什么样的输出。以便更快的应用到自己的业务里面。
2.3.4 上下文:许愿机也是有容量上限的
上下文是一个我们在今后都会频繁使用的词语,这个词语它也不是人工智能的独创概念。我们任何人在进行一场对话的过程中间,这个对话从开始到结束所有的文字组合,它其实就是上下文。
当我们做语文阅读理解的时候,请根据上下文分析出作者在此处的思想感情,这个地方的上下文指的就是文章整体的文本。所以你真的让我要给「上下文」下一个定义的话,很难下。但是我相信你们所有人都知道它指什么。
对于大模型来说的话,它的上下文就是我们输入的一段文本。事实上,我们在上文中介绍的那个大模型输入文本,在输出文本的流程是一个简化的范式,实际的范式稍微复杂那么一点点。因为在实际上我们和这些大模型交互的过程中间,我们并不是只问一个问题,而是问了一个问题获得一个回答之后,继续询问下一个问题。我相信大家平时在使用大模型应用的时候,应该就会是这样,就导致一个问题,问到后面越来越长。
比如在下图中间,我在询问某家上市公司的一个产品板块和他的营收分布。而在询问这个问题之前,我已经和大模型来回交互了十多次,问出了十多个问题了。
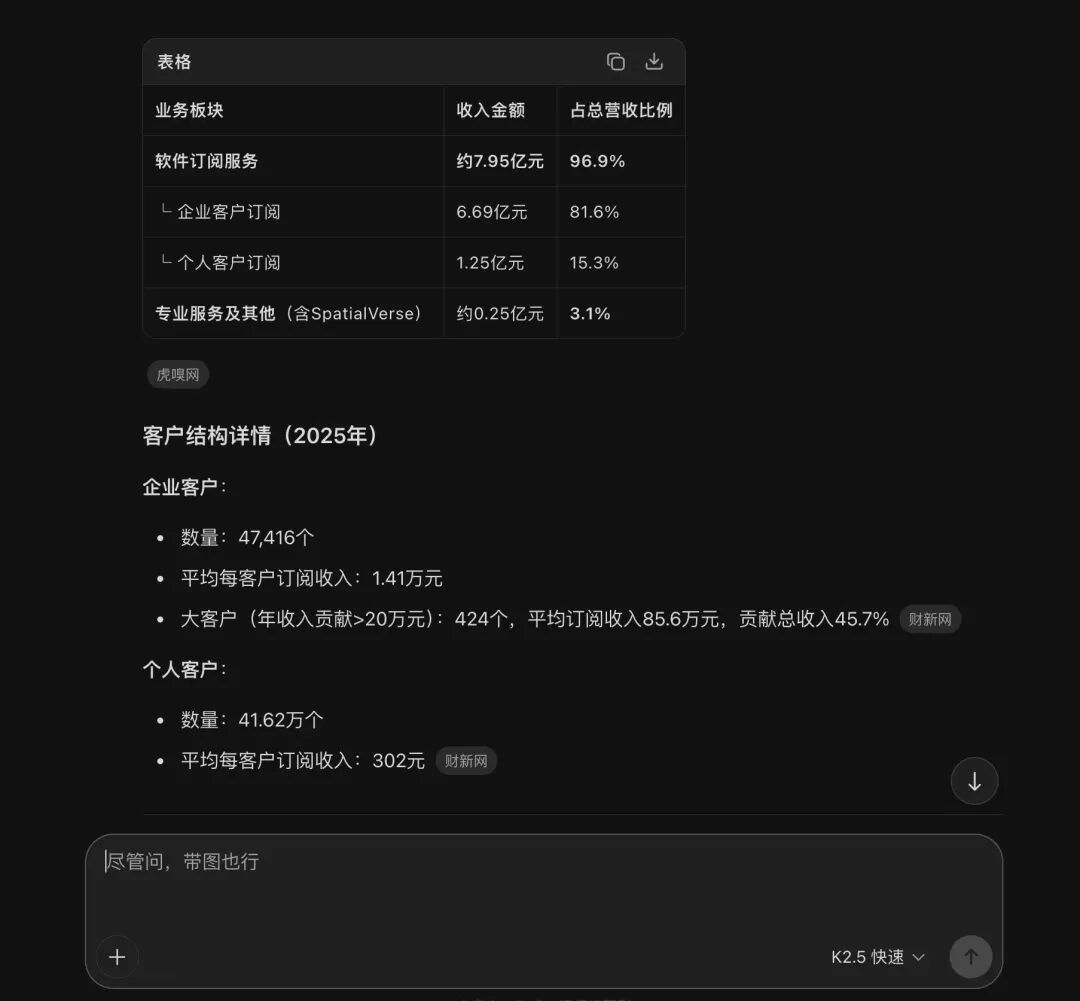
真实大模型在运行的过程中间,它并不是输入一个问题再返回这个问题的答案。
当我们在对话框里面敲入
有什么好的学习智能体的教程复制
按下回车键之后,大模型返回的其实并不是「锦恢的 AI Agent 小白教程系列」,而是:
有什么好的学习智能体的教程锦恢的 AI Agent 小白教程系列复制
而假设你在当前的这一个会话的过程中,你已经问了大模型两个问题,现在要问它第三个问题。你实际的输入在大模型看来是:
{第一个问题}{第一个问题的回答}{第二个问题}{第二个问题的回答}{第三个问题}复制
那么大模型对于你第三个问题,实际的输出就是:
{第一个问题}{第一个问题的回答}{第二个问题}{第二个问题的回答}{第三个问题}{第三个问题的回答}复制
随着对话的进行,大模型实际的输入也会连上之前你所问过的所有问题和大模型所有的回答结果。因此你能看到,随着问题的进行,大模型的这个输入会越来越长。而我们预留给大模型的内存显然是有限的。因此,大模型的输入一定不能是无限长,当我们的输入超出一个很大的长度时,就会超出预留给大模型的内存,从而让大模型报错。
而这个在规定内存大小中,大模型输入的最长文本量,我们就把它称之为这个大模型的「上下文窗口」,在很多时候,我们也会简称为上下文。当然了,通过上一节的学习,你也能知道大模型处理信息的基本单元并不是文字,而是token。所以上下文窗口的衡量单位也是token。
而相信我的读者可能对基于token这个单位的上下文窗口量缺少一个感性的认知。所以我下面给了一些比较基本的案例,来帮助你们快速建立起多少 K 的上下文窗口大概是一个什么样的处理量级。
| 窗口大小 | 对应纸媒形态 |
|---|---|
| 1K | |
| 10K | |
| 100K | |
| 1M |
注:1K = 1000, 1M = 1000K
那么我们常用的大模型,它的一个上下文窗口有多大呢?也就是说,它到底能够一次性输入多少的文本,或是处理多少同等文本量的任务呢?下面这张表格展示了目前常见的主流大模型,它的一个上下文窗口。
| 模型名称 | 最新上下文窗口 (Tokens) |
|---|---|
| 字节跳动 豆包 Pro | 512K - 1M |
| OpenAI GPT-5.4 | 272K - 1.05M |
| 阿里巴巴 Qwen 3.5 Plus | 512K |
| Google Gemini 3.1 Pro | 1M - 10M |
也就是说,最新的模型几乎都可以把常见的一整本长篇小说给扔进去了。或者如果你需要执行的这个任务量,它的问题和答案首尾拼接在一块儿小于一本中长篇小说,那么大模型也都是可以处理的。
如果你理解了大模型上下文窗口这个概念,你也就不难理解为什么我们要做大模型的记忆模块和大模型的上下文压缩这两件事情了,这两件事情的本质都是在大模型上下文窗口有限的情况下,让大模型可以在体感上执行几乎无限长的任务。
毕竟如果将每个人每天所做的所有工作和接收到的消息都记录下来的话,那么不出一两天,这些信息本身就可以堆积成一本长篇小说了。
当然了,具体这两个部分是如何做的,而我们又要如何使用它们,我会在后续的章节详细展开。如果能在本节课理解上下文窗口的这个概念,并且基于我们上面给的数据建立一个感性认知,大概知道多少K的一个上下文窗口的大模型,它能够处理什么样一个量级的信息,那么这节课的目的其实也就达到了。
2.3.5 像一个专家一样选购大模型——了解大模型的一些基本性能参数
相信很多朋友买手机的时候,都会去询问:这个手机内存多少 G 的呀,CPU 咋样呀,打王者卡不卡呀?
那我们使用大模型的时候,其实也是类似的。我们总需要一些量化的参数来大概了解到我们购买的大模型服务,它到底是一个什么样的水平。而通过上面几章的学习,是时候非常轻松的让大家了解到我们最关心的一些大模型的基本参数是什么了。
1)上下文窗口
当然了,首当其冲的上下文窗口,这个肯定是非常关键的一个参数。不过我们一般也不会太过关心这个参数。因为通过上面的表格,你也能发现主流大模型的这个上下文窗口其实是处于相同的一个数量级上的。而且对于大部分应用来说,我们的一次任务执行也不可能直接把它的上下文给挤爆。所以对于大模型的上下文这个参数,大家只需要知道主流大模型的这个上下文大概是一个什么样的量级,大概是能塞几本长篇小说进去就行了。比如目前主流的大模型,都可以塞1到2本长篇小说进去。当然,我相信你要处理的业务和你的场景中,大概率这些文本加在一块是没有两篇长篇小说这么长的。
2)首词延时 Latency
当我们询问大模型时,并不是按下回车键之后大模型立刻有个响应的。我们往往需要等个几秒钟,大模型才会开始吞吞吐吐的把结果像打字机一样,返回给我们。而这个从我们按下问出问题的回车到等待大模型,在屏幕上打出第一个字,这中间的时间就被我们称为首词延时。
很多朋友可能会好奇,为什么大模型的服务会存在一个首次延时,明明大模型后续给出返回的速度都非常非常快。这个问题提的非常好。这个问题深入到了大模型 AI Infra 推理加速这个领域的部分。事实上就是当我们的问题抵达了大模型的服务厂商的服务器时,它并不会立刻的开始计算,服务器而是会等待另外的若干个用户也将问题都发送到服务器之后,把你们几个人问的问题捆在一块,一次性让大模型并行的处理你们的这些问题。这么做的最大好处就是可以大幅度的降低成本。事实上,在 2025 年年初 deepseek 爆火的一段时间之后,网络上有大量的人都在质疑 deepseek 的数据是造假的。因为他们发现自己去部署了 deepseek 的开源模型之后,赚不了几个钱甚至亏损,但 deepseek 却对外声称自己有 30% 的利润率。而后来大家才知道,这差的30%利润率,主要就在于我们上面所提到的这样一个把问题捆在一块并行计算的技术上。而这一块技术就是 AI Infra 中的中台调度算法,在 vllm,sglang 等开源框架中都得到了实现,如果大家对这项技术的实现细节感兴趣的话,不妨用 deepwiki 来查看这些框架的源代码。如果大家未来对 AI Infra 技术感兴趣的话,我也可以来写一篇文章系统介绍这些技术的发展历史和目前行业中的一些细节。
3)推理速度 TPS
“少废话?TPS 多少” 成为了一线工程师圈子内大家对待新的大模型服务,往往会说出的第一句话。TPS 这个指标就是用来衡量大模型输出速度的一个重要指标,TPS越高,大模型输出内容的那个打字效果,你会感觉越快。
还记得我们在上文中提到的这个例子吗?我们输入了:
有什么好的学习智能体的教程复制
而大模型返回了:
有什么好的学习智能体的教程锦恢的 AI Agent 小白教程系列复制
在这个例子中,我们输入的这一部分「有什么好的学习智能体的教程」,它被我们称为输入 token(input token);而输出的结果中,实际上返回的结果为「锦恢的 AI Agent 小白教程系列」,它被我们称为输出 token(output token)。
为什么输出 token,我们只计算截取后的结果,而不是返回整个包括输入在内的 token 呢?因为有 KV Cache Hitness,也就是你们能在价目表上看到的缓存命中与缓存不命中。此处我们都假设缓存是命中的。因为对于目前大部分厂商而言,在执行智能体任务时,缓存命中率几乎都能做到 95% 以上。这一部分对于没有计算机基础的观众而言,可能会有点难理解。如果你暂时无法理解的话,就可以先跳过,放心,这并不影响我们后续内容的理解。
而 TPS(token per second,每秒输出token数量),它的一个计算方法就是大模型每秒打出的字对应的 token 的数量。而从之前我们的描述中,你也不难看出,这个地方我们描述的 token 它是输出 token。
我们可以从这个网站 https://artificialanalysis.ai/里面获取实时的TPS数据,比如锦恢目前的文章写于2026年4月20号,我在官网上看到的数据如下:
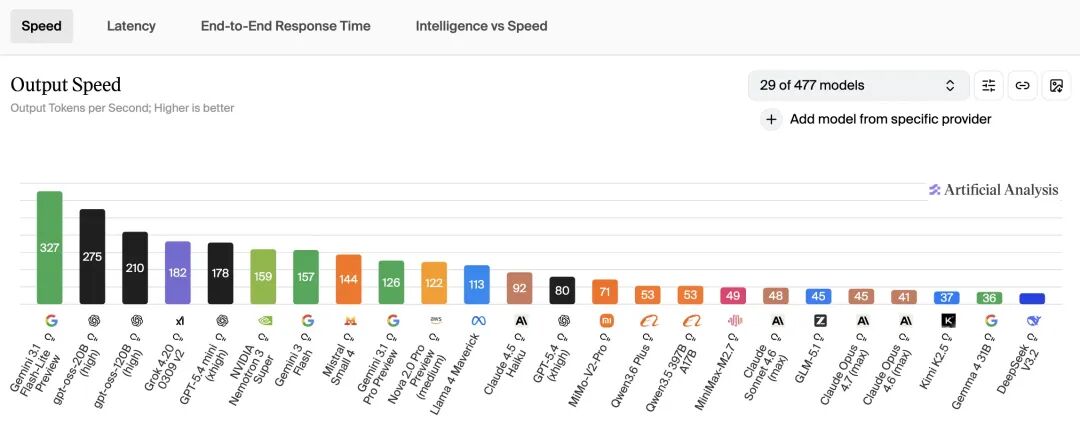
我们可以看到,目前全球速度最快的模型是谷歌的模型,能达到 327,根本原因是因为谷歌自研的AI加速芯片第二代 TPU 在去年完成了部署。而国内由于缺少最先进的 AI 芯片,所以和国外的模型在速度上仍然有不少的差距。而这一部分大家也能看到,它并不是通过优秀的算法就可以弥补的差距。所以为什么锦恢一直在频道里和大家强调,大模型时代的优先级是 数据 > 算力 > 算法,相信大家从这张图里面可知一二。
注:最新实验表明,如果将大模型的参数直接刻到芯片里面,能将TPS提升1000倍至1万倍。也就是某些人嘴里的专用芯片或是存算一体了。如果成本允许的话,在未来这可能会成为一种主流方案,我们拭目以待,我先在这里插个眼。
4)是否支持多模态
这个指标就非常简单了,也就是查看当前的这个大模型是否支持输入图片。我们目前所谈的多模态一般指的就是能否输入图片。因为音频和视频对于大部分通用任务而言,并不是一个需要经常输入的信息,而且这类信息往往我们甚至不需要。
对于大部分常规任务而言,最常使用的信息仍然是文本和图片。所以当我们选购大模型服务的时候,支持图片和文本的输入几乎已经是一个必要选项了。只不过对于某些模型而言,它仍然不支持输入图片。
2.4 课后作业
问题 1:小 C 的 token 焦虑
小 C 最近迷上了用AI来写代码,但是他发现自己总是把好不容易买来的额度快速用完,所以他打算精细化管理自己寻问AI时的操作。他最近正在做一个自己的个人网站,然后询问了AI如下的内容
“请帮我制作一个符合 Swiss 扁平风格样式的个人网站,需要展示我的个人名字、学校名和我的项目经历等等信息。”
并且小 C 还将一张从 dribbble 上拿到的设计稿(1080p)扔进了AI里,希望AI可以照着这个图做出一个差不多的网站。请问,小 C 的这个输入的问题大概相当于多少 token ?
问题 2:史密斯专员
小 P 所在的公司想要进行AI转型,首当其冲的就是需要稳定的大模型供应商,而不知道从哪里突然冒出一个自称史密斯专员的人,找上了小 P 想向他们的公司推销自家的系列产品,总之,这里有五花八门的各式模型,但基本上都是你听过的型号。
作为一个看过锦恢的 AI Agent 的小白教程的非技术人员,小P应该如何设计调研表格,去客观地了解到史密斯专员推销的大模型产品的好坏?
2.5 总结
如果您能看到这个部分,我会非常感激的。因为我觉得对于很多急于快速的将智能体技术应用到生产劳动中的朋友而言,这些看似理论的内容是很枯燥的。但我认为为了让大家能够对后续的技术有个更加本质的了解,从而非常彻底的记住这些在他人看来,或许会所难懂的术语,了解一些大模型的基本原理是大有裨义的。
而在下一章节中,我们将开始见证这项技术的一个阶段性转型。也就是我们如何基于大模型这样一个强大的工具,慢慢的制作出一个智能体。而这个过程中又有哪些非常重要的概念和我们总结的工程技巧,需要让大家学学掌握。大家可以期待一下。
okey dockey,这里是 00 后全栈工程师锦恢,一个正在尝试撰写全网最小白最全面最系统的AI Agent系列教程的学徒。同时我的《氛围编程锦囊》系列教程也准备上线了。对于如何使用AI来 10 倍效率地写代码或者是做出软件网站的感兴趣的朋友,欢迎关注。

