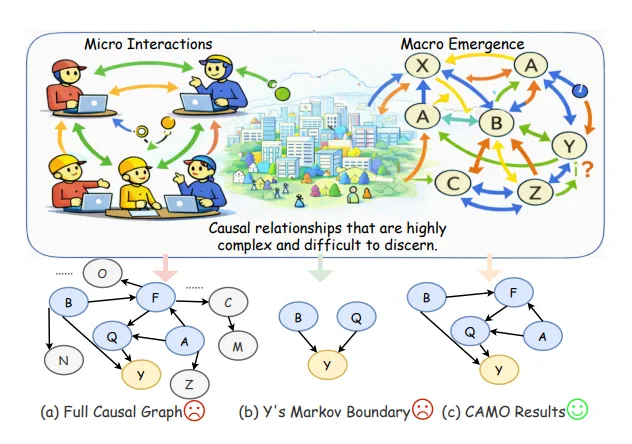
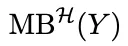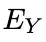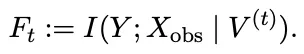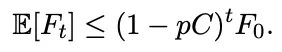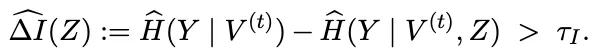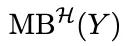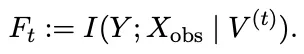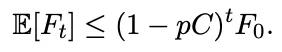AI 社会学的第一块基石:CAMO 让涌现机制第一次可计算、可追溯、可干预这两年,LLM 多智能体模拟突然成了研究社会行为的新宠。无论是 Generative Agents 里那些“会八卦的邻居”,还是 Smallville 里会组织派对的虚拟居民,又或者 AgentSociety 里大规模的社会互动实验,人们第一次看到 AI 代理在一个虚拟世界里自发形成合作、冲突、极化、规范、群体结构……这些现象看起来非常“社会学”,甚至有点“人味”。但问题也随之而来。我们能看到涌现,却不等于理解涌现。模拟器里发生了什么,我们往往只能描述,却无法解释。01 为什么涌现需要因果解释
当一个宏观现象出现,比如配送系统的整体效率突然下降,或者一个社区的观点突然极化,我们其实很难回答一个关键问题——这些宏观结果到底是怎么从无数微观行为里长出来的。是骑手的策略变了,是商家的定价变了,还是网络结构发生了某种反馈? 没人说得清。缺乏因果机制带来的后果非常现实。你无法解释,也就无法预测,更无法干预。 你只能“看着它发生”,却不知道“为什么发生”,更不知道“怎么阻止或强化它”。CAMO 的出现,就是在这个背景下诞生的。它试图做一件过去没人真正解决的事——在 LLM 多智能体模拟中,自动恢复一条从微观行为到宏观涌现的因果链条,让我们第一次能够“理解”涌现,而不是“围观”涌现。图1:CAMO恢复的因果表示。CAMO在目标结果Y周围确定了一个紧凑的因果邻域,足以进行因果识别,并用解释和支持微观到宏观出现干预所需的最小上游途径集对其进行扩展。这项工作来自天津大学智能与计算学部的一支年轻但实力很强的团队。作者包括 Xiangning Yu、Yuwei Guo、Yuqi Hou、Xiao Xue 和Qun Ma。团队横跨智能计算、复杂系统、因果推断和社会模拟等方向,既能写理论,又能搭系统,还能跑大规模仿真,是典型的“跨学科硬核组合”。他们把这套框架命名为CAMO,并把代码开源在 GitHub 上(https://github.com/RisingDate/CAMO.),显然是希望推动整个领域往“可解释的涌现科学”迈进一步。CAMO 的目标很直接,让涌现不再是“黑箱魔法”,而是“可计算、可验证、可干预”的因果过程。02 LLM Agent ×因果发现×涌现机制的三重挑战
LLM Agent 模拟的兴起让研究者第一次有机会在虚拟世界里观察“类社会行为”。这些代理不再是传统ABM 里那种简单规则的粒子,而是能理解语言、能推理、能协作的“类人智能体”。当成百上千个这样的代理在一个环境里互动时,涌现现象自然就冒出来了。然而,涌现的复杂性远超我们的直觉。多智能体之间的互动是高度非线性的,一个小小的策略变化可能在网络结构里被放大成巨大的系统效应。中观层面的结构,比如社交网络、任务分配网络、信息传播链路,也会不断变化,形成各种反馈回路。更麻烦的是,变量空间本身是动态的,新的行为、新的关系、新的模式会在模拟过程中不断出现。传统因果发现方法在这里几乎无能为力。它们假设变量是固定的,关系是静态的,数据是结构化的。 但在 LLM Agent 的世界里,变量是生成出来的,关系是演化出来的,数据是文本化的。 你让 PC、FCI、GES 这种经典方法去处理这种系统,就像让算盘去跑深度学习一样,完全不对路。更关键的是,传统方法只能告诉你“谁影响谁”,却无法解释“微观行为如何汇聚成宏观模式”。 这正是涌现研究最核心的问题。CAMO 就是在这三重挑战的交叉点上提出的。 它既要理解 LLM Agent 的行为,又要做因果发现,还要解释涌现机制。 这不是简单的技术叠加,而是一种新的研究范式。03 CAMO的核心思想|从Markov边界到最小解释子图
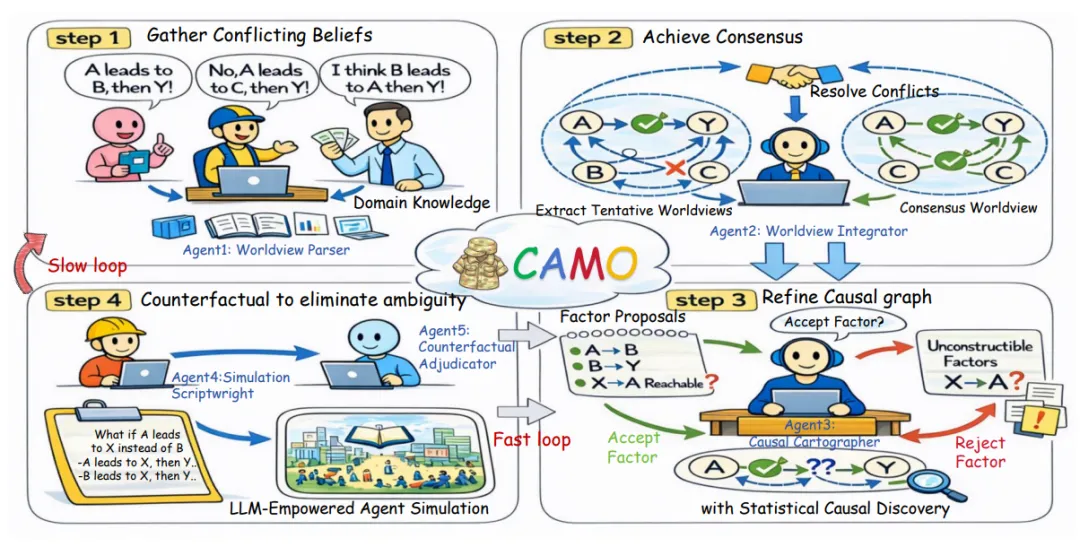
图2:CAMO概述。快慢循环整合了文本世界观、因果发现和模拟内部干预,以恢复目标结果的最小因果界面和微观到宏观的解释。CAMO 的设计哲学非常务实,它不试图恢复整个模拟器的全局因果图,因为那几乎是不可能的任务。它只做一件事——找到解释目标涌现变量 Y 所必需的最小因果结构。这是围绕 Y 的最小局部因果接口,只要知道这些变量,就能预测 Y,也能对 Y 做有效干预。 它是“因果识别”的核心。它从 Markov 边界往上追溯,找到所有必要的微观和中观因果路径,形成一条从微观行为到宏观结果的最短解释链条。 它是“机制解释”的核心。这两层结构组合起来,就构成了 CAMO 的因果解释框架。 既有统计上的最小性,又有机制上的可解释性。为了让因果方向真正“站得住脚”,CAMO 还引入了模拟器内部的反事实实验。 当因果结构学习得到 CPDAG 或 PAG 时,方向往往是不确定的。 CAMO 会自动生成干预脚本,在模拟器里执行 do(X=x) 和 do(X=x') 的成对实验,通过结果差异来判断因果方向。 这让因果关系不再只是“推出来的”,而是“验证出来的”。在研究的理论部分,团队还给出了 Markov 边界收敛的数学保证。 残余依赖量这意味着 CAMO 的因果接口会稳定收敛,而不是越做越乱。整体来看,CAMO 的核心思想可以总结成一句话 让涌现从“现象”变成“因果链条”,让因果链条从“推测”变成“可验证”。04 CAMO的五智能体体系结构|一个真正意义上的Agentic因果发现流水线
如果说 CAMO 的思想是“让涌现变得可解释”,那它的工程设计就是“让解释这件事自动化”。研究最有意思的部分,就是它把整个因果发现过程拆成五个 LLM Agent,每个 Agent 负责一个环节,组合起来就像一条自动化的因果发现流水线。这五个 Agent 分工明确,风格迥异,有点像一支跨学科科研团队在虚拟世界里协作,只不过所有成员都是 LLM。世界观解析器 A1 是整个流程的入口。它的任务很像一个“文献综述机器人”,从各种文本知识里挖出可能相关的变量、机制、假设。更重要的是,它不会强行把所有观点揉成一个统一答案,而是会把冲突观点保留下来,形成多个“候选世界观”。这点非常关键,因为真实世界的机制往往不是单一的,涌现现象背后可能存在多种解释路径,A1 的工作就是把这些可能性全部摊开。世界观整合器 A2 则像一个“变量工程师”。它会把 A1 提取的变量做统一化处理,把同义概念合并,把模糊概念具体化,并且生成一批可计算的因子,比如比率、滚动统计、图结构指标等等。它还会从多个世界观中挑选一个当前最合理的版本,作为本轮因果发现的“决策世界观”,记作 W(k)。这一步让整个系统有了一个可操作的起点。因果制图师 A3 是 CAMO 的核心角色。它负责真正的因果结构学习,分成两个阶段。第一阶段是 Add–Prune 迭代,也就是不断尝试加入新的可计算因子,并根据信息增益判断它们是否真的有用。信息增益的计算方式是如果某个因子 Z 能显著减少对 Y 的不确定性,就留下,否则就剔除。经过多轮迭代,A3 会收敛到一个可计算的 Markov 边界第二阶段是约束式因果结构学习。A3 会在世界观提供的结构约束下运行 PC、FCI 或基于评分的方法,得到一个 CPDAG 或 PAG,也就是一个部分定向的因果图。那些方向不确定的边会被标记出来,等待后续处理。反事实脚本生成器 A4 的任务,就是把这些“不确定边”变成可执行的实验。它会自动生成干预脚本,设计成对的模拟实验,也就是所谓的 paired rollouts,让模拟器分别执行 do(X=x) 和 do(X=x'),并保持其他随机性一致。A4 的角色有点像一个“实验设计师”,负责把因果问题转化成可验证的实验。反事实裁决者 A5 则是整个系统的“实验审稿人”。它会执行 A4 生成的干预脚本,观察结果差异,判断因果方向是否成立。如果某条边在多个配置下都表现出一致的因果效应,就会被标记为“模拟器确认的因果方向”,并反馈给 A3更新因果图。这五个 Agent 形成了一个快慢结合的循环。快速循环负责因子筛选和局部因果结构学习,慢速循环负责世界观修正和反事实验证。整个过程既有统计基础,又有机制推理,还能通过模拟器实验来校准方向,形成一个闭环。从工程角度看,这套体系非常“Agentic”。它不是让 LLM 单独推理,而是让多个 LLM 分工协作,像一支虚拟科研团队一样完成因果发现任务。05 CAMO的可证性基础
CAMO 不只是一个工程系统,它背后还有一套严谨的理论保证,让整个框架不仅“能跑”,而且“站得住”。首先是 Markov 边界的收敛性。A3 的Add–Prune 过程不是盲目试错,而是有数学保证的。研究团队定义了一个残余依赖量也就是在当前变量集合下,Y 与所有观测变量之间还剩多少未解释的依赖。作者证明了,在合理条件下,这个残余依赖会以几何速度下降这意味着随着迭代进行,系统会越来越接近一个“足够解释 Y 的最小变量集合”,不会越做越乱,也不会陷入无休止的膨胀。其次是反事实实验带来的可识别性提升。传统的 CPDAG 或 PAG 只能告诉你“可能的方向”,但无法确定真正的因果方向。CAMO 通过模拟器内部的反事实实验,把方向不确定的边一个个验证出来。研究团队证明,这种模拟器内部的反事实对某些边的方向具有排除性,可以消除部分结构歧义,让因果图从“可能”变成“确定”。最后是最小解释子图 Ey 的充分性与最小性。Ey 是在Markov 边界的基础上,向上追溯所有必要的因果路径,形成一个最小连接子图。研究团队证明,Ey 足以支持对 Y 的预测和干预,同时不包含任何冗余节点或冗余路径。换句话说,它既不缺东西,也不多东西,是解释涌现机制的最简结构。这三项理论贡献让 CAMO 不只是一个“能跑的系统”,而是一个“有理论支撑的系统”。它让因果发现从经验主义走向可证明性,让涌现解释从猜测走向结构化。06 实验设计|从O2O外卖平台到社会模拟
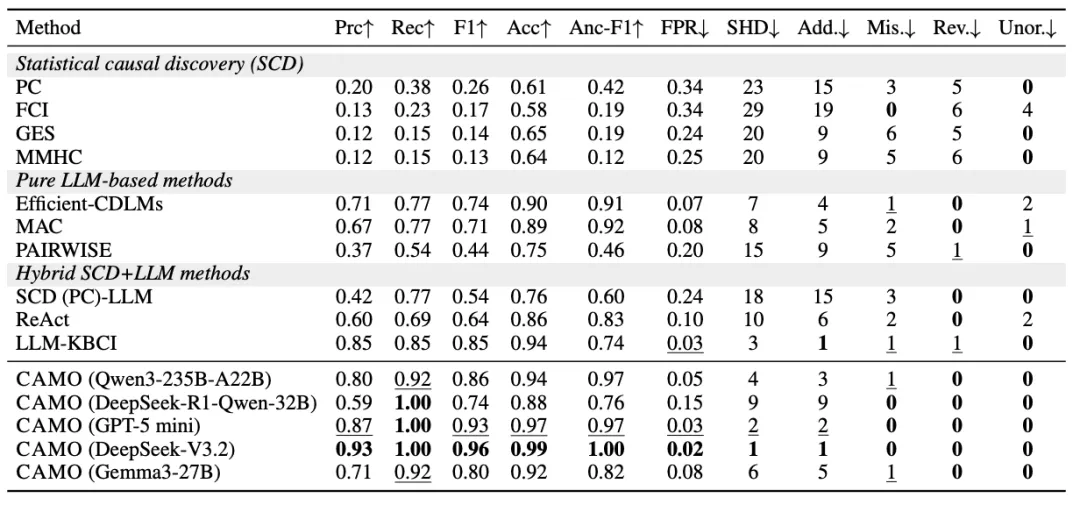
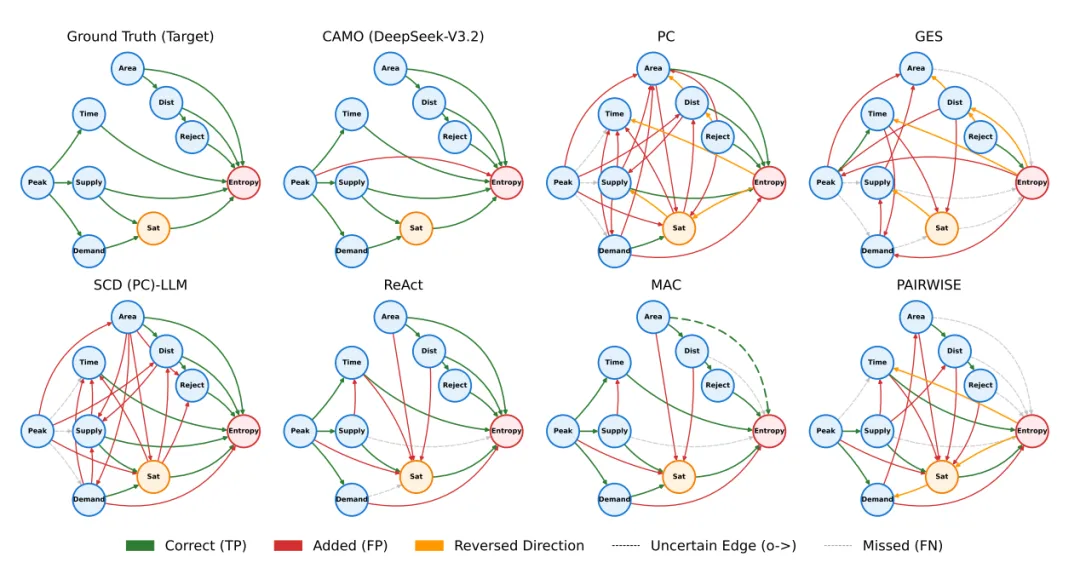
CAMO 的实验部分非常“接地气”。不像很多研究团队只在玩具数据集上跑一跑,它直接把战场搬到了一个真实世界里极其复杂的系统——O2O 外卖平台。这个平台的行为模式由美团的真实统计数据校准,既有微观层面的个体决策,又有中观层面的网络结构,还有宏观层面的系统涌现,是一个天然的“涌现实验室”。表1:O2O交付模拟中因素发现的不同因果发现方法的比较(马尔可夫边界与完整祖先目标)。所有基于LLM的基线都使用DeepSeek-V3.2进行评估。表2:O2O交付模拟中因果结构恢复的不同因果发现方法的比较。所有LLM基线都使用DeepSeek-V3.2;CAMO使用括号中指定的LLM。在这个模拟里,微观层面是骑手的接单策略、商家的定价行为、顾客的下单需求。每个智能体都有自己的偏好和行为逻辑,彼此之间的互动会不断累积,形成复杂的动态。中观层面是配送网络本身。订单在城市空间里流动,骑手在路网中穿梭,拥堵、延迟、反馈循环不断出现。网络结构不是静态的,而是随着行为变化而演化。宏观层面则是整个系统的效率表现,比如平均配送时长、订单完成率、系统拥堵程度,以及研究团队中定义的涌现指标。这些宏观结果不是任何单个智能体能控制的,而是无数微观行为叠加后的产物。图3:恢复因果结构的定性比较(O2O交付模拟;预计)。为了验证 CAMO 的因果发现能力,作者设置了多种基线方法。传统统计因果发现方法包括 PC、FCI、GES 和 MMHC,它们代表了经典的结构学习路线。纯 LLM 因果推断方法包括 MAC、PAIRWISE等,依赖语言模型的推理能力来判断因果关系。混合方法则把统计方法和 LLM 结合起来,比如 SCD-LLM、ReAct、LLM-KBCI。为了避免模型偏差,作者还在多个 LLM backbone 上测试了 CAMO,包括 Qwen3、DeepSeek-R1、GPT-5 mini 和 Gemma3。这让实验结果更具普适性,也能看出CAMO 是否依赖某个特定模型的能力。整个实验设计非常完整,从真实系统到多模型对比,再到多任务验证,几乎把因果发现能遇到的挑战都覆盖了。07 实验结果|CAMO的优势
实验结果可以用一句话概括,CAMO 在所有关键指标上都“碾压式领先”。但为了不显得夸张,我们还是把细节摊开来看。在因子发现任务中,CAMO 是唯一一个能完整恢复 Markov 边界的方法。其他方法要么漏掉关键因子,要么引入大量错误因子,而 CAMO 的错误因子数量是零,也就是 OT=0。更夸张的是,它在祖先集恢复上的 Anc-F1 达到了 0.98,几乎是满分。这说明 CAMO 不仅能找到局部因果接口,还能把上游因果路径完整地恢复出来。在因果结构恢复任务中,CAMO 的表现同样亮眼。无论是 F1、Anc-F1、结构哈明距离 SHD,还是假阳性率 FPR,CAMO都全面领先。更重要的是,它恢复出来的因果结构最紧凑、最准确,没有冗余边,也没有方向错误。这正是最小解释子图Ey 的价值所在。在无真值图的环境里,比如协调、极化、仇恨传播等社会模拟任务,CAMO 的干预效果也遥遥领先。无论是 Precision@5、MAP@5 还是 MRR,CAMO 都拿下第一。这说明它不仅能“解释涌现”,还能“改变涌现”,找到真正有效的因果杠杆,而不是凭直觉调 prompt。这些结果共同指向一个结论,CAMO 不只是一个“能跑”的系统,而是一个“能解释、能预测、能干预”的系统。08 方法价值|CAMO为什么重要
第一,它让涌现机制变得可解释。过去我们只能看到现象,却不知道为什么会这样。CAMO 让我们第一次能把微观行为、中观结构和宏观结果串成一条因果链条,让涌现从“神秘现象”变成“可分析机制”。第二,它让干预变得可设计。过去我们只能凭直觉调 prompt,或者盲目修改规则,希望系统能变好。CAMO 能告诉你真正的因果杠杆在哪里,哪些变量能改变宏观结果,哪些只是噪声。这让干预从“试试看”变成“有依据”。第三,它让 LLM 多智能体模拟成为一种“可科学研究”的工具。只有当一个系统具备因果可验证性、机制可追溯性和结构可解释性,它才能真正用于科学研究,而不是停留在“好玩”的层面。CAMO 正是在为这个方向铺路。从更大的视角看,CAMO 代表了一种新的研究范式。它把 LLM Agent、因果推断和复杂系统科学结合起来,让我们有机会在虚拟世界里研究社会机制、经济系统、组织行为,甚至未来的 AI 社会学。如果说 LLM Agent 模拟是“虚拟社会的显微镜”,那 CAMO 就是“虚拟社会的因果分析仪”。它让我们不仅能看到世界如何运转,还能理解它为什么这样运转。(END)参考资料:https://arxiv.org/pdf/2604.14691关于波动智能——
波动智能旨在建立一个基于人类意图与反应的真实需求洞察及满足的价值体系,融合人工智能与意识科学,构建覆盖情绪识别、建模与推荐的智能引擎,自主研发面向社交、电商等场景的多模态意图识别引擎、意图标签系统及意图智能推荐算法,形成从情绪采集、意图建模到商业转化的完整解决方案。波动智能提出“意图是连接人、物与内容的新型接口”,其产品广泛应用于AI社交、个性化内容推荐、虚拟陪伴、电商体验优化等领域。波动智能正在探索“EMO-as-a-Service”技术服务架构,赋能企业实现更高效的用户洞察与精准情绪交互,推动从功能驱动到意图驱动的产业范式升级。
亲爱的人工智能研究者,为了确保您不会错过*波动智能*的最新推送,请星标*波动智能*。我们倾心打造并精选每篇内容,只为为您带来启发和深思,希望能成为您理性思考路上的伙伴!
加入AI交流群请扫码加微信
 夜雨聆风
夜雨聆风