夜雨聆风
夜雨聆风多数产品经理做 AI 产品,在选定大模型供应商的方式,是看测评榜单排名,选排名靠前的型号,申请 API Key,上线。这条选型路径的直接后果是,产品运行三个月后 API 成本超出预算 40% 以上,或核心功能因数据合规问题被迫关停。
选型的根本矛盾不在于哪家模型能力最强,在于哪家模型在产品自身约束条件下成本最可控、合规路径最短、迁移风险最低。
老王梳理了当前市面上 12 大模型家族 的产品线结构、定价逻辑和实际适用场景,从 产品经理选型决策 的视角逐一拆解每家的核心判断要点。先分享关注,以后用的时候别找不到了。
另外,老王给大家准备了一整套原型库和PRD模板,公众号私信:原型图
OpenAI
OpenAI 是大模型 API 市场的先行者,当前开发者生态最完整的供应商。GPT 系列 从 2022 年 ChatGPT 发布至今,持续占据 API 调用量的头部位置。
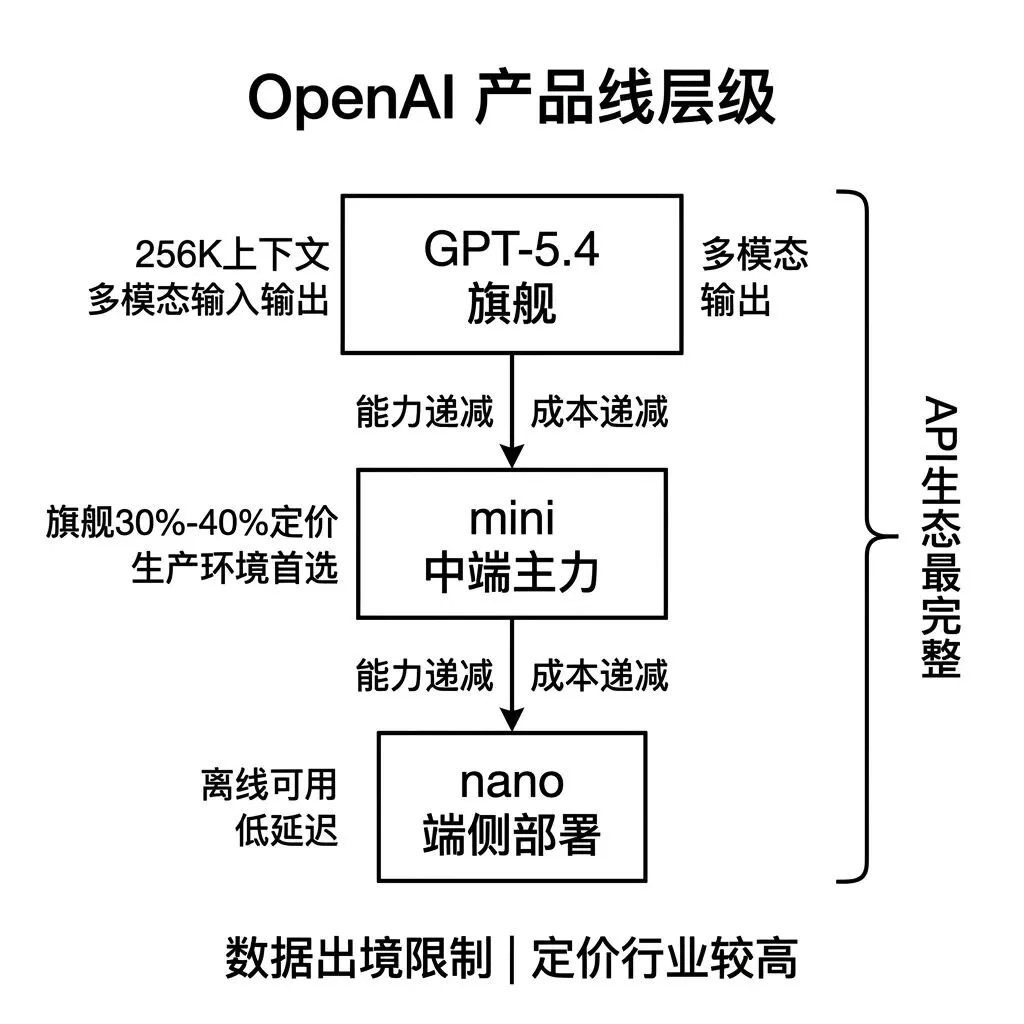
当前产品线包含三个层级。
GPT-5.4 是旗舰模型,综合能力在主流评测中处于第一梯队,支持文本、图片、音频多模态输入输出,Context Window 达到 256K Token。
mini 是中端模型,能力覆盖绝大多数生产场景,Token 单价约为旗舰版的 30% 到 40%,是 API 调用量最大的版本。
nano 是端侧模型,参数量压缩到可在移动设备 NPU 上运行的级别,适用于离线场景和对延迟要求极高的应用。
产品经理选型OpenAI需要评估三个核心约束。
⚠️ OpenAI · 三个核心约束
API定价处于行业较高水平。GPT-5.4 API 官方标准价为输入 2.50 美元/百万 Token、输出 15 美元/百万 Token。相较多数国产主流通用模型,其单价通常偏高,输出 Token 成本大致高出数倍到数十倍不等;在百万级日调用场景下,月度 API 成本可能达到数十万元人民币,具体取决于平均输入/输出 Token、上下文长度,以及是否使用 Batch、缓存或更小模型。数据通过国际网络传输到海外服务器处理。 涉及金融、医疗、政务等受监管行业的产品,在数据出境合规审查上存在明确障碍。产品经理在这类行业做选型评估前,必须先确认数据合规边界。API生态的完整度是当前所有供应商中最高的。函数调用、结构化输出、文件上传与检索、批量处理等API能力的成熟度和文档完善程度,领先于其他供应商。开发效率的差异在早期原型阶段体现最为明显。
老王认为,如果产品面向海外市场,OpenAI仍然是开发效率最高的选择。 如果产品面向国内市场且不属于高毛利业务,成本结构上用国产模型替代mini版本是更理性的方案。
Anthropic
Anthropic 由 OpenAI 前核心研究员创立,技术路线的核心差异点在于 安全对齐机制。Constitutional AI 是 Anthropic 的标志性训练方法,通过预定义的行为准则约束模型输出,在敏感内容过滤和指令遵循一致性上表现突出。
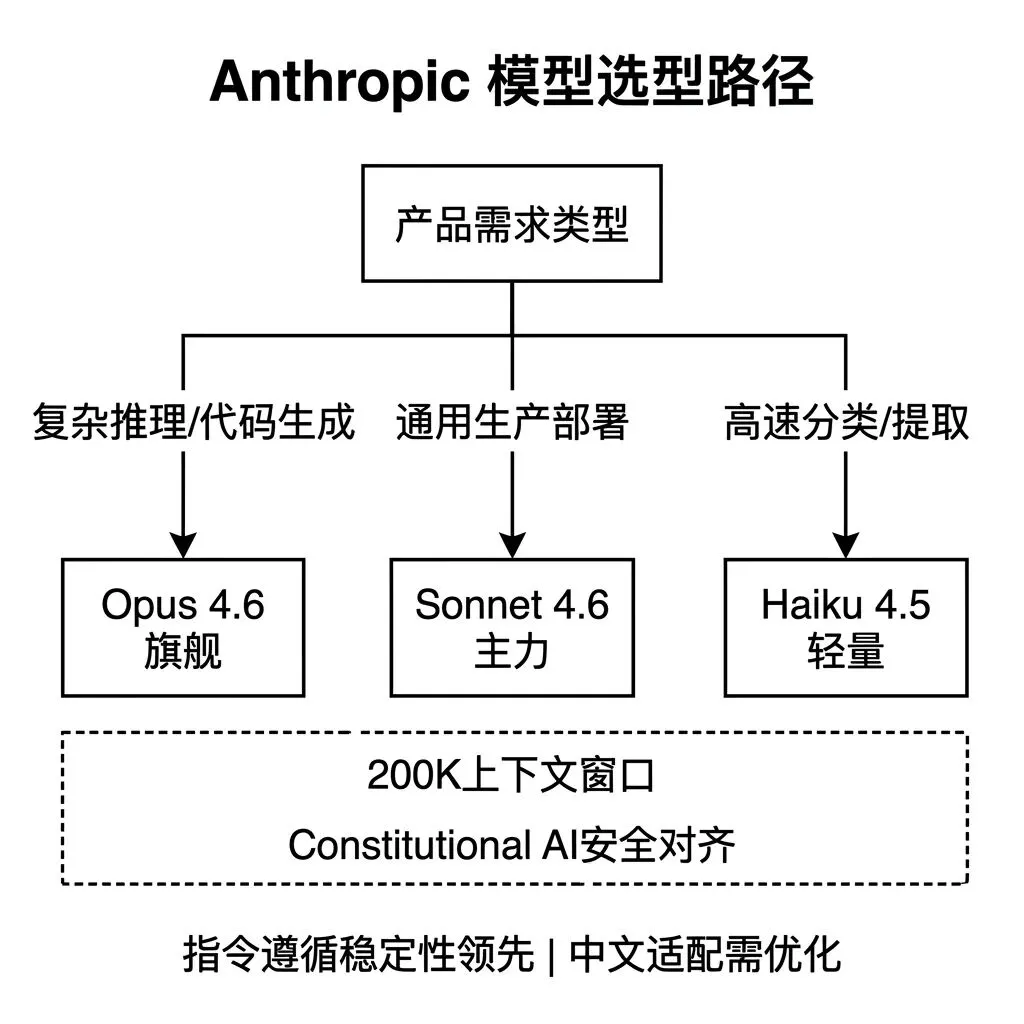
Claude 家族 当前包含三个版本。
Opus 4.6 是旗舰模型,在复杂推理、长文本分析和代码生成任务上与 GPT-5.4 处于同一梯队,部分代码评测中得分更高。
Sonnet 4.6 是生产环境中部署量最大的版本,综合能力与 OpenAI mini 处于同一区间,但长指令遵循和格式化输出方面的稳定性被多家企业评估报告认为更优。
Haiku 4.5 是轻量版本,推理延迟低,适合分类、提取等结构化任务。
Anthropic对产品经理的核心吸引力集中在两个方面。
Claude系列原生支持200K和1M Token的上下文长度。 长文档处理场景,如合同审查、研报分析、代码库理解,不需要额外的分段处理逻辑,产品架构可以更简洁。
在 System Prompt 设定复杂行为规则的场景下,Claude 系列的指令遵循率在多项第三方评测中排名前列。对于依赖 Prompt 工程控制输出格式的产品,指令遵循稳定性 直接影响后处理逻辑的复杂度和错误率。
局限性同样明确。API服务器在海外,数据合规约束与OpenAI一致。中文语境下的语言流畅度和文化适配性与国产模型存在可感知的差距,中文To C产品直接使用需要额外的Prompt优化工作。
Google 的 Gemini 家族 是模型版本数量最多的产品线,也是与云服务绑定最深的选型方案。
Gemini 3.1 Pro 是旗舰推理模型,在 MATH 和代码评测中的得分稳定在第一梯队。独特优势是原生支持超过 1M Token 的上下文窗口,在所有商用模型中实际可用的最长上下文。
3 Flash 是高性价比生产版本,Token 单价在海外模型中最低一档,吞吐能力强,适合高并发场景。
3.1 Flash-Lite 是极致成本优化版本,单价约为 Flash 的三分之一,能力有限但在简单分类和提取任务上够用。
2.5 Pro是上一代旗舰,仍然在服务中,在部分长期运行的生产系统中继续使用。
Google的差异化竞争力集中在三个点。
多模态原生能力。 Gemini 系列对视频和音频的原生处理能力是当前所有模型中最完整的,支持视频帧理解、音频转录和多模态混合推理。需要视频内容分析的产品,可选供应商范围很窄,Google 是头部选项。
版本丰富度。 四个版本覆盖从极致成本到极致性能的完整区间,产品经理可以在同一供应商体系内做精细化的成本分层,不同功能模块调用不同版本。这种分层策略在 Google 体系内最容易落地。
GCP绑定。 Gemini API 通过 Google Cloud Platform 提供,已经使用 GCP 基础设施的企业可以直接复用权限、计费和监控体系,集成成本最低。未使用 GCP 的企业需要评估是否愿意引入新的云服务依赖。

xAI
xAI 是 Elon Musk 创立的人工智能公司,Grok 系列 与 X 平台的数据和分发生态深度绑定。
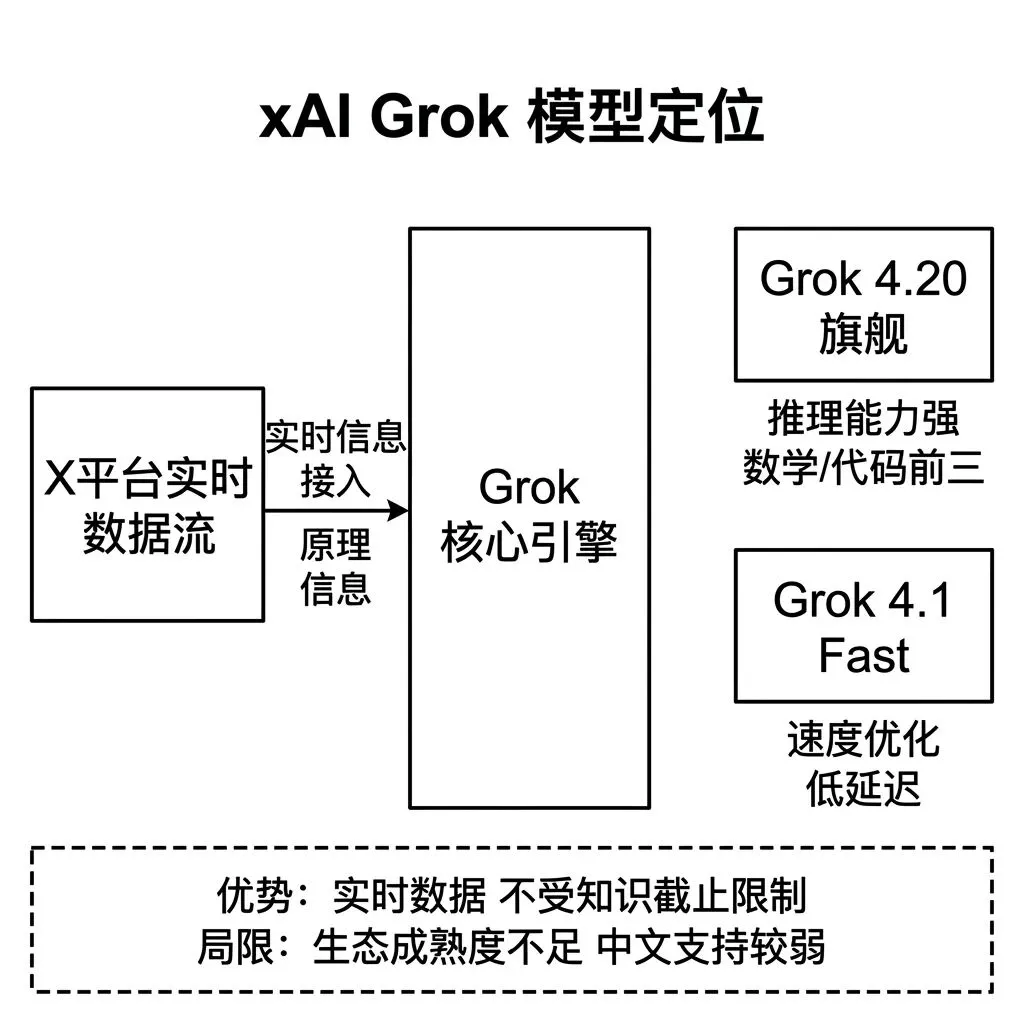
产品线精简为两个版本。
Grok 4.20 是旗舰模型,在推理类评测中表现强劲,部分数学和代码 Benchmark 得分进入前三。独特数据优势是可以实时访问 X 平台的公开数据流,在处理时事、舆情监测、实时信息检索类任务时,不受传统模型知识截止日期的限制。
Grok 4.1 Fast 是速度优化版本,推理延迟显著低于旗舰版,适合对响应速度要求高的场景。
xAI 对产品经理的选型价值集中在 实时信息获取能力。传统大模型的知识有截止日期,需要通过 RAG 架构补充最新信息。Grok 的 X 平台数据接入在一定程度上降低了这个环节的工程复杂度,对新闻资讯、社交监测、趋势分析类产品有直接价值。
局限性在于生态成熟度。xAI的API文档、SDK支持、开发者社区活跃度与OpenAI和Anthropic相比仍有差距。API的稳定性和SLA保障在企业级生产环境中的验证数据积累不足。中文支持能力弱于其他头部模型,国内产品直接使用需慎重评估。
DeepSeek
DeepSeek 是 2024 年以来对全球大模型市场定价体系冲击最大的中国供应商。
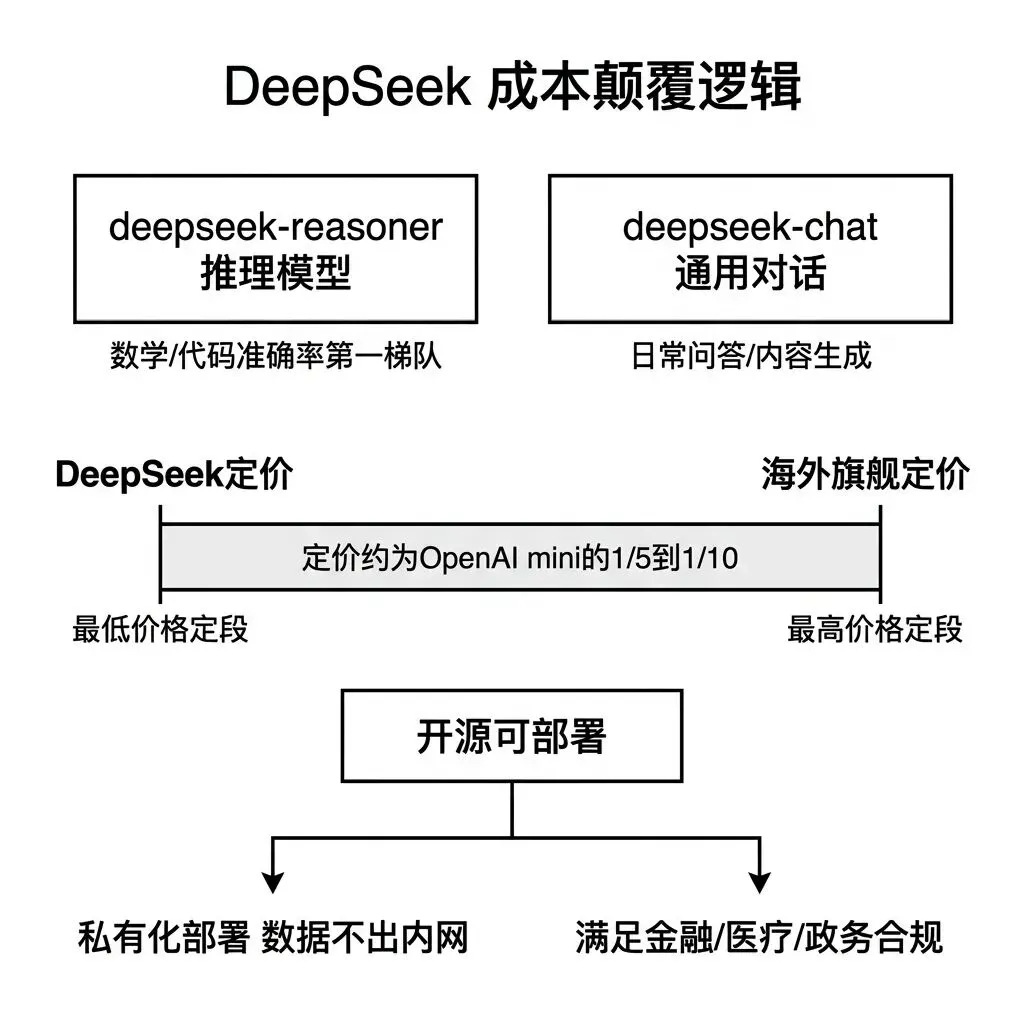
产品线分为两个版本。
deepseek-reasoner 是推理模型,机制类似 OpenAI o 系列,在回复前执行内部思维链推理,数学和代码任务的准确率在多项评测中与 GPT-5.4 和 Claude Opus 同一区间。
deepseek-chat 是通用对话模型,覆盖日常问答、内容生成、翻译等常规任务。
✅ DeepSeek · 成本拐点
DeepSeek对产品决策的影响不只在能力排名,更在于显著改变了API成本结构。 以官方定价看,deepseek-chat和deepseek-reasoner的输出Token价格明显低于OpenAI mini与o系列模型;在输出占比较高、上下文缓存命中较多或推理调用频繁的场景下,整体调用成本可能降至OpenAI同类模型的数分之一到十分之一左右。对于日均API调用量超过10万次的产品,若单次调用包含数百到数千Token,月度成本差距可能达到数万到数十万元人民币。
它目前的模型权重是开放下载的,支持 私有化部署。对数据合规有要求的产品可以选择自部署路线,数据完全不出内网,同时满足能力和合规两个维度的要求。
老王觉得,DeepSeek让之前因为成本原因被否决的AI功能变得可行。 一个之前因API成本过高被砍掉的实时文档分析功能,换用DeepSeek后成本可能降到可接受范围内。选型时不仅要评估当前方案的成本,还需要用DeepSeek的价格做一遍对照测算,验证是否存在成本优化空间。
Kimi
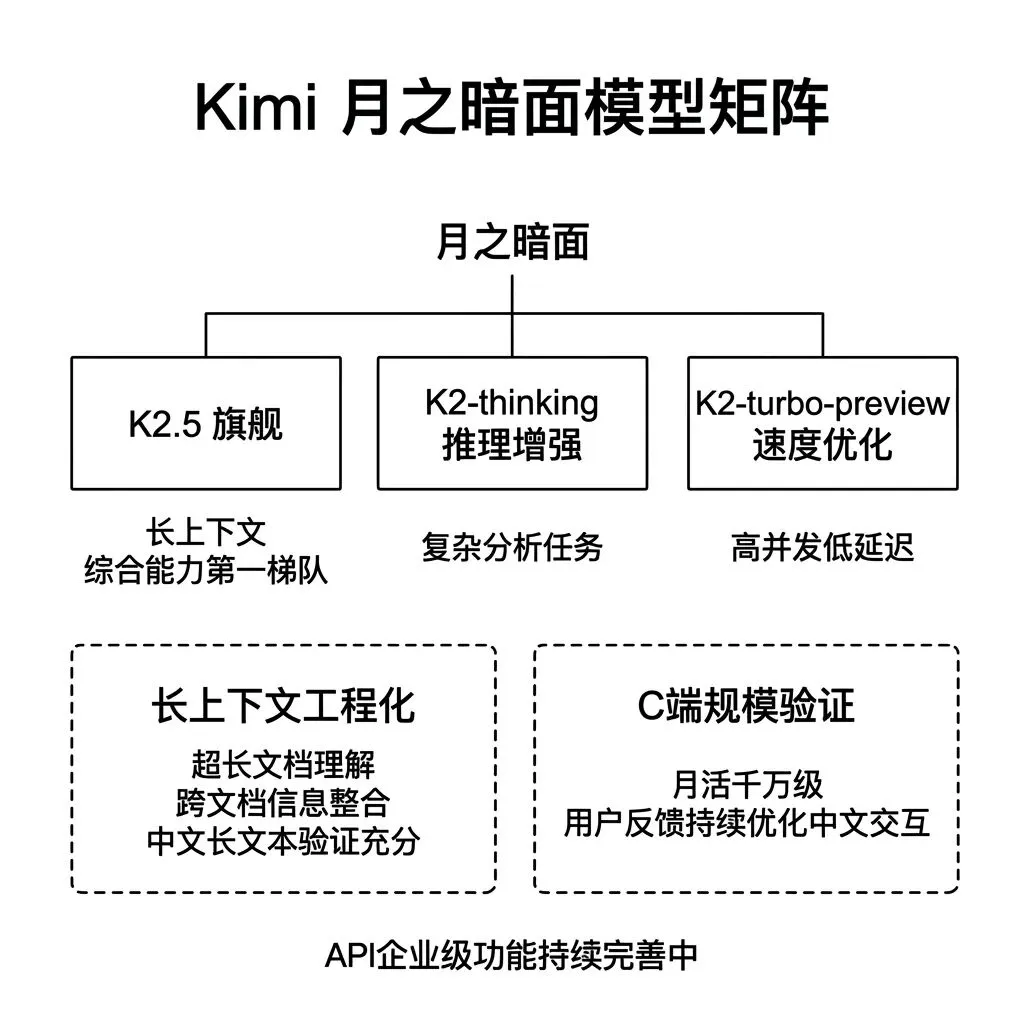
Kimi 是月之暗面推出的大模型产品,最早在国内市场打出 长上下文处理 的认知标签。
当前产品线包含三个版本。
K2.5 是旗舰模型,综合评测得分在国产模型中处于第一梯队,原生支持超长上下文输入。
K2-thinking 是推理增强版本,机制类似 deepseek-reasoner,在复杂分析任务上表现更优。
K2-turbo-preview 是速度优化版本,适合高并发低延迟场景。
Kimi的核心差异化在两个维度。
长上下文的工程化能力。 Kimi从早期版本开始就将长上下文处理作为核心技术方向,在超长文档理解、跨文档信息整合等任务上的实际表现,尤其是中文长文本场景,经过了大量C端用户的验证。产品中如果有处理完整合同、完整研报、完整代码库的需求,Kimi需要纳入评估范围。
C端产品验证。 Kimi是国内少数同时运营C端产品和B端API的模型厂商,C端产品的月活跃用户超过千万级别。C端积累的用户反馈数据对模型的指令遵循和中文交互质量有持续正向影响。
局限在于API生态的成熟度。与OpenAI和Anthropic相比,Kimi的函数调用、结构化输出等高级API功能的文档和SDK完善程度仍有差距。企业级SLA和技术支持体系处于建设阶段。
MiniMax
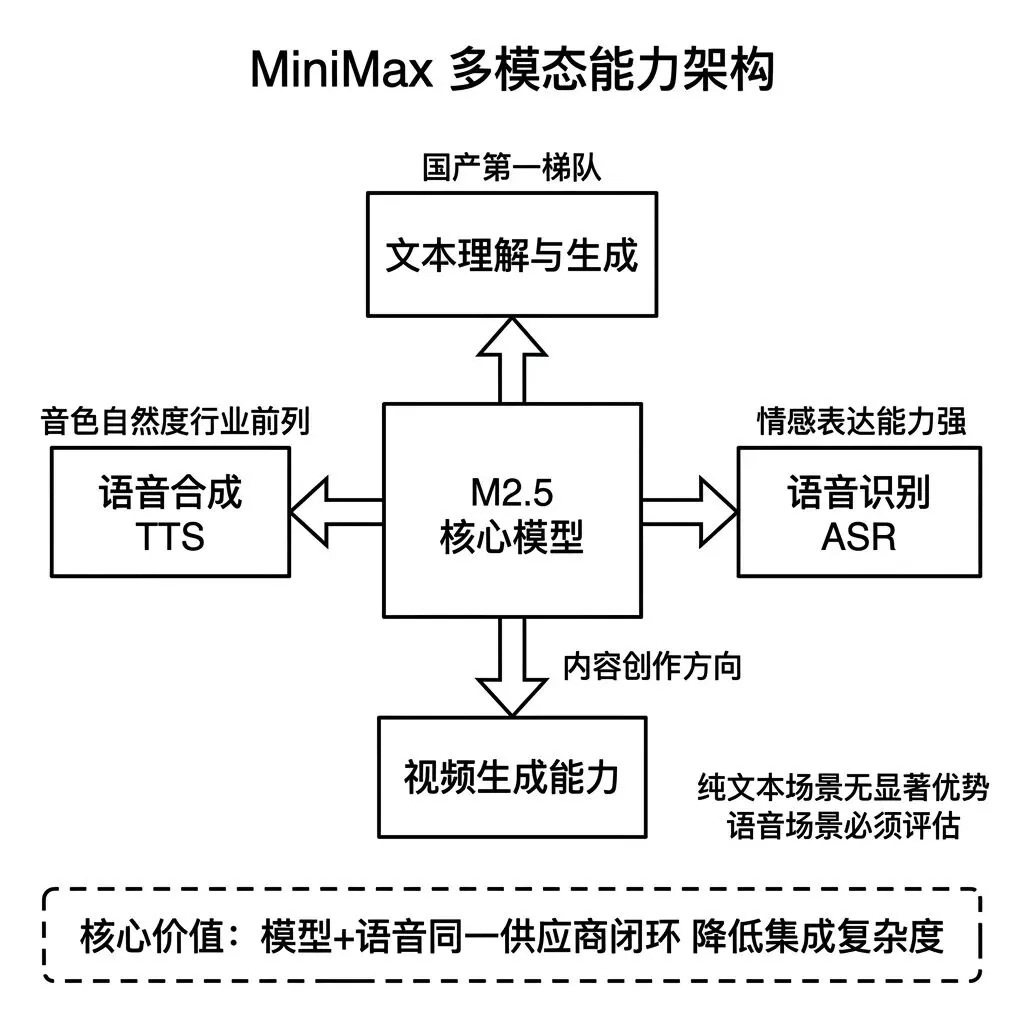
MiniMax 是国内在多模态方向布局最早的模型厂商之一,技术路线横跨文本、语音、视频三个模态。
当前核心模型是 M2.5,定位为全能型多模态模型。M2.5在文本能力上接近国产第一梯队,同时原生支持高质量的语音合成和语音理解能力。MiniMax的语音合成技术被多家头部应用集成,在音色自然度和情感表达方面的评测得分处于行业前列。
MiniMax对产品选型的意义在于,如果产品的核心交互场景涉及语音,MiniMax提供了 模型能力和语音能力在同一供应商体系内闭环 的方案。通常情况下语音交互产品需要分别接入LLM和TTS/ASR两套供应商,集成复杂度和调试成本都更高。MiniMax在一定程度上降低了这种集成开销。
老王理解,MiniMax的适用范围相对聚焦。纯文本API调用的产品,没有选择MiniMax的成本或能力优势。但一旦产品涉及语音对话、有声内容生成、虚拟角色等场景,MiniMax需要列入评估短名单。
腾讯混元
腾讯混元 是腾讯自研的大模型家族,核心竞争力与 腾讯云和微信生态 直接绑定。
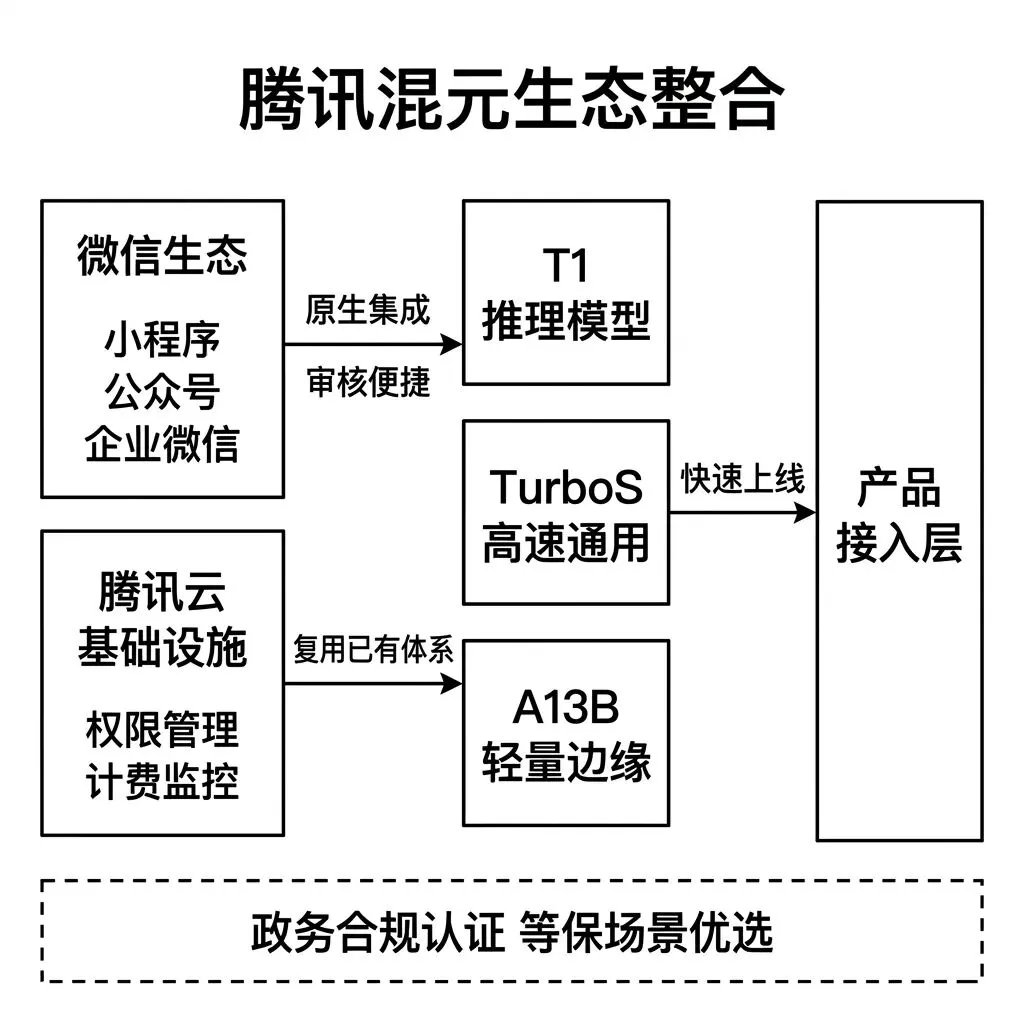
产品线包含三个版本。
T1 是推理模型,在逻辑推理和代码任务上的能力处于国产模型中上水平。
TurboS 是高速通用模型,主打低延迟和高吞吐。
A13B 是轻量模型,参数量在13B级别,适合私有化部署和低成本调用场景,也可以在边缘设备上运行。
腾讯混元的核心选型逻辑与技术能力排名无关,与 企业已有的技术栈 强相关。
产品如果运行在微信生态内,包括小程序、公众号、企业微信,使用腾讯混元可以获得与微信API的原生集成支持,审核流程更顺畅,数据流转链路更短。这个优势不体现在Benchmark得分上,但在实际上线周期和运维效率上有直接影响。
已经使用腾讯云基础设施的企业,接入混元API的权限管理、计费和监控可以复用现有体系。切换到其他模型供应商意味着引入新的云服务依赖或增加跨云网络的复杂度。
腾讯在政务和大型企业市场有长期积累,混元模型通过腾讯云的政务合规认证。在需要政务等保的场景中,混元是减少合规审查流程的选项之一。
智谱
智谱AI 脱胎于清华大学知识工程实验室,是国内学术背景最深厚的大模型厂商。
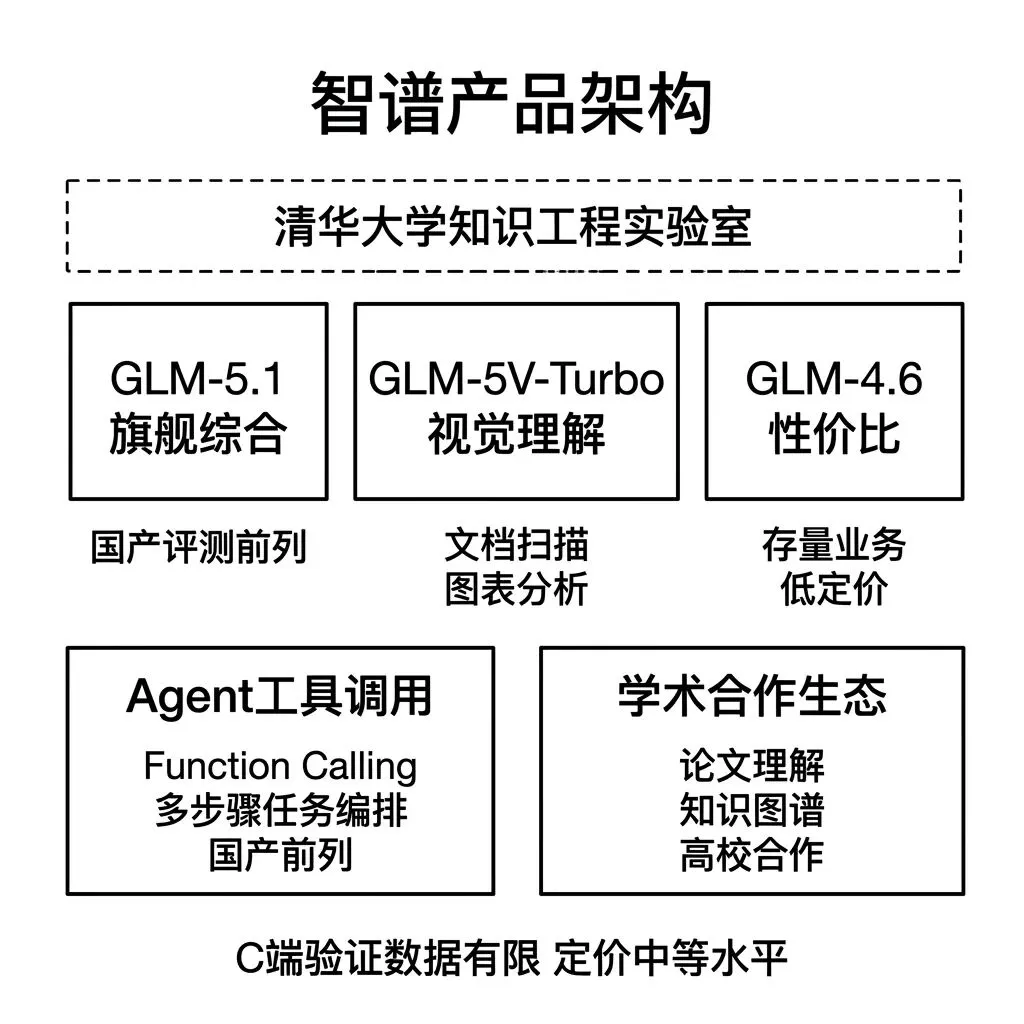
产品线包含三个版本。
GLM-5.1 是最新旗舰模型,综合评测在国产模型中排名前列。
GLM-5V-Turbo 是视觉理解模型,支持图片输入和分析,在文档扫描件识别和图表理解任务上有专项优化。
GLM-4.6 是上一代主力版本,仍在服务中,定价更低,适合对能力要求不高的存量业务。
智谱对产品选型有两个差异化维度。
Agent和工具调用能力。 智谱在 Function Calling 和 Agent 框架方面的投入较深,API在工具编排、多步骤任务执行方面的支持度在国产模型中处于前列。产品中需要构建Agent工作流,如自动化数据采集、多步骤报告生成,智谱的API设计与此类需求的匹配度较高。
学术合作生态。 智谱与多所高校和研究机构有合作关系,在学术论文理解、知识图谱构建等偏学术的应用场景中,有独特的数据和方法论积累。
局限在于C端验证不足。智谱的C端产品用户规模不及Kimi和豆包,在消费者市场的验证数据相对有限。API定价在国产模型中属于中等水平,没有DeepSeek那样的极致成本优势。
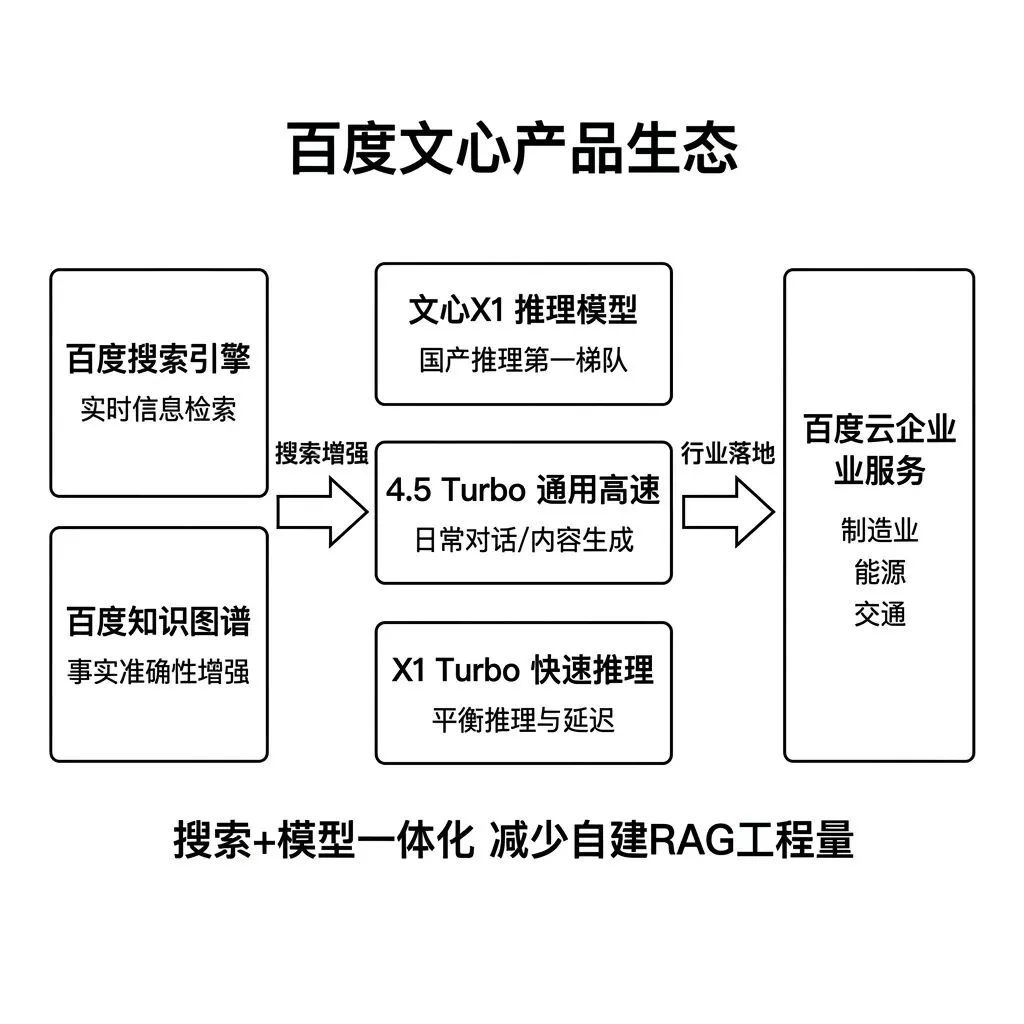
百度文心
百度文心 是国内最早发布大模型产品的厂商之一,依托百度搜索和百度云的双重基础设施。
当前产品线有三个核心版本。
文心X1 是推理模型,机制上与deepseek-reasoner和o系列同类,在数学推理和复杂分析任务上的表现处于国产推理模型第一梯队。
4.5 Turbo 是通用高速版本,覆盖日常对话和内容生成需求。
X1 Turbo 是推理模型的速度优化版,平衡推理能力和响应延迟。
百度文心的选型逻辑需要从两个维度评估。
百度的核心资产是搜索引擎和知识图谱。 文心模型在需要实时信息检索的场景中,通过百度搜索的结果增强模型回复的时效性和准确性。对于需要融合搜索能力的产品,如问答系统、资讯聚合,百度文心提供了搜索加模型一体化的方案,减少自建RAG系统的工程量。
百度在制造业、能源、交通等传统行业有长期的云服务客户基础。 这些行业的企业在选择AI供应商时,倾向于与现有云服务供应商保持一致,减少供应商管理成本。文心在这些行业的落地案例数量处于国产模型前列。
老王感觉,百度文心的综合能力在国产模型中属于第一梯队,但差异化竞争力核心在于搜索能力的绑定和传统行业的渠道覆盖。如果产品不涉及搜索增强场景且不在百度云体系内,文心相比其他国产模型没有显著成本或能力优势。
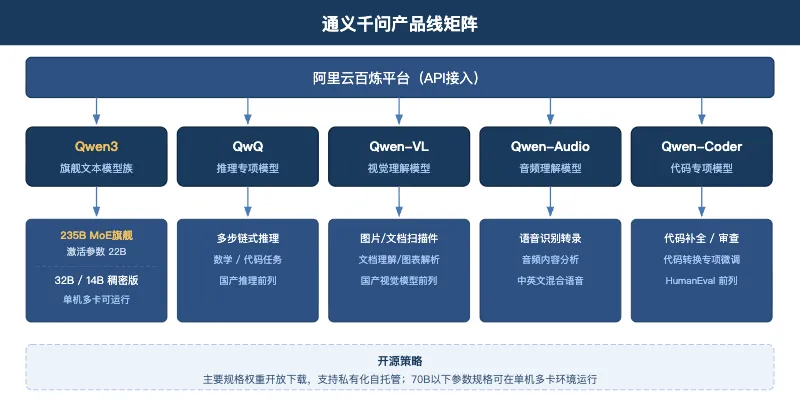
阿里通义千问
阿里通义千问 是国内开源模型矩阵最完整的供应商,Qwen系列 在Hugging Face和ModelScope的累计下载量处于全球中文模型前列,同时通过阿里云百炼平台提供商业API接口。
当前核心产品线覆盖五个方向。
Qwen3 是最新旗舰文本模型族,包含235B混合专家架构旗舰版和32B、14B多个参数规格的稠密模型。235B旗舰版实际激活参数为22B,推理成本接近稠密版32B模型,在主流评测中能力指标达到旗舰级别。
QwQ 是阿里的推理专项模型,机制类似deepseek-reasoner和o系列,在回复前执行多步链式推理,数学和代码任务的准确率在国产推理模型评测中排名前列。
Qwen-VL 是视觉理解模型,支持图片和文档扫描件输入,Qwen2.5-VL在文档理解和图表解析评测中进入国产模型前列。
Qwen-Audio 是音频理解模型,支持语音识别转录和音频内容分析,覆盖中英文混合语音场景。
Qwen-Coder 是代码专项模型,针对代码补全、代码审查和代码转换任务做了专项微调,在HumanEval评测中得分高于通用模型同参数规格版本。
产品经理选型通义千问需要评估三个核心维度。
开源部署路径。 Qwen3系列大部分参数规格的权重已开放下载,支持在私有环境自托管。数据出境合规要求严格且有GPU资源的企业,自托管Qwen3是同时满足能力、合规、成本三个约束的可行方案。70B以下参数规格可在单机多卡环境运行,运维门槛在国产开源模型中较低。
API定价。 百炼平台的Qwen3系列API定价在国产模型中处于中低水平,旗舰版输入Token价格约为同档次OpenAI模型的十分之一以内,推理调用频繁的产品月度成本差距可能达到数万元人民币。
阿里云生态集成。 已经使用阿里云基础设施的企业,接入百炼API可以复用RAM权限、账单体系和VPC内网调用链路,集成成本低于引入新供应商。
老王判断,通义千问在国产开源模型市场的综合竞争力处于第一梯队,私有化部署场景是其最高差异化价值点。阿里云体系内的企业选型通义千问的迁移成本最低。
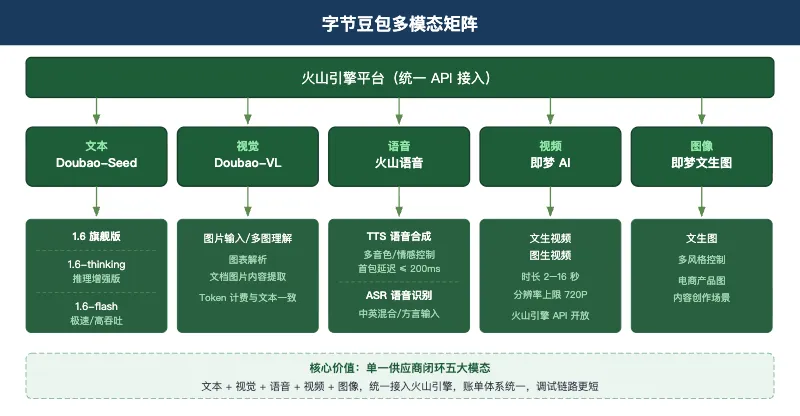
字节豆包
字节豆包 旗下的大模型产品线已经扩展为覆盖文本、视觉、语音、视频、图像五个模态的完整矩阵,统一通过火山引擎平台提供API接入。
文本基座是Doubao-Seed系列。 Doubao-Seed-1.6是旗舰版,综合能力在国产模型评测中处于第一梯队。1.6-thinking是推理增强版,机制与deepseek-reasoner同类,在复杂分析和代码任务上表现更优。1.6-flash是极速版,主打最低延迟和最高吞吐,适合实时对话类场景。
视觉能力通过Doubao-VL系列扩展。 支持图片输入和多图理解,覆盖图表解析、文档图片提取等场景,Token计费逻辑与文本API一致,不需要引入独立的图像理解供应商。
语音能力通过火山语音服务体系提供。 TTS方面,火山语音合成支持多种音色、情感控制和实时流式输出,200毫秒内的首包延迟已有批量生产验证。ASR方面,语音识别支持中英文混合和方言输入,识别准确率在嘈杂环境下经过抖音、番茄小说等字节系产品的大规模用户验证。
视频生成通过即梦AI提供。 即梦底层模型支持文生视频和图生视频两种生成路径,单次生成时长覆盖2秒到16秒区间,分辨率上限720P。API通过火山引擎开放,适合集成到内容批量生产工作流。
图像生成同样集成在即梦体系内。 文生图支持多种风格控制,在电商产品图和内容创作场景下有商业应用验证。
字节豆包的核心选型价值在于 多模态能力的供应商集中度。产品如果需要文本加语音加视频的能力组合,在字节体系内完成集成的工程复杂度低于多供应商拼接方案,调试链路更短,账单体系统一。
定价方面,Doubao文本API单价接近行业最低水平,结合火山引擎企业合作折扣,批量采购场景下实际成本有进一步压缩空间。
局限在于API成熟度存在明显分化。文本API生产稳定性已经大量商业验证,视频生成API的企业级SLA和高级功能的文档完善程度与文本API存在差距,B端API整体成熟度低于智谱和OpenAI。
老王判断,字节豆包体系对内容创作、社交媒体运营类产品的适配度最高。纯文本场景下,与DeepSeek同处价格洼地,是成本敏感型产品的优先评估对象。多模态场景下,是当前国内单一供应商内完整度最高的方案。
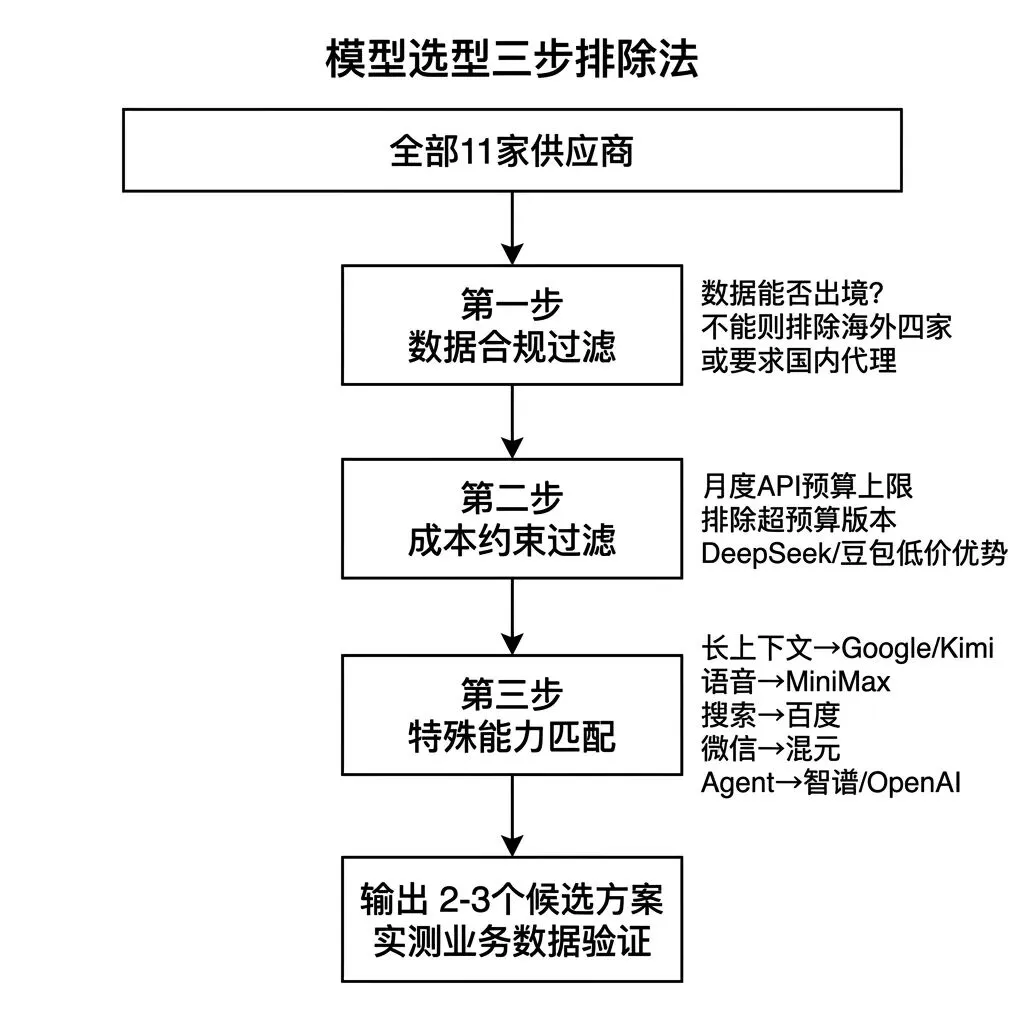
选型决策框架
💡 选型动作 · 三步排除法
产品经理面对12个供应商,最低效的方式是逐一测评再做选择。用三个维度的排除法可以在30分钟内缩小到2到3个候选。
第一个维度,数据合规。 产品的数据是否允许出境。如果不允许,直接排除OpenAI、Anthropic、Google、xAI四家海外供应商,或者要求使用其国内代理服务,通常有额外成本和功能限制。DeepSeek、智谱等支持私有化部署的模型进入候选。
第二个维度,成本约束。 估算日均API调用量和平均Token消耗,用各家公开定价计算月度成本。如果月度成本超过预算上限,排除定价偏高的版本。DeepSeek和字节豆包的极低定价在这个环节通常会显著影响候选名单。
第三个维度,特殊能力需求。 产品是否有特定的能力依赖。长上下文超过200K的需求指向Google和Kimi。语音交互需求指向MiniMax。搜索增强指向百文心。微信生态集成指向腾讯混元。Agent工具调用复杂度高指向智谱和OpenAI。私有化部署需求指向DeepSeek和通义千问。多模态能力组合需求指向字节豆包。
按老王思考,模型市场在2026年的竞争格局已经进入同质化阶段,各家旗舰模型在通用评测上的差距持续缩小。选型的胜负手不在于选了哪家分数最高的模型,在于是否精确匹配了产品自身的约束条件组合。 用测评榜单的排名代替产品约束条件的分析,是选型失误的最常见原因。