 夜雨聆风
夜雨聆风在人工智能领域,我们正经历一个从“模型为中心”向“系统为中心”的范式转移。2026年的技术格局已经明确:一个孤立的大语言模型(LLM)无论其参数规模如何宏大,都无法直接转化为具备商业价值的智能体。业界领先的企业如Anthropic、OpenAI及LangChain,其核心竞争力已不再仅仅局限于模型权重的微调,而在于围绕模型构建的那层复杂而精密的软件基础设施——智能体架构(Agent Harness)。
正如业内资深人士所言:“如果你不是在做模型,你就是在做Harness。”这句话深刻揭示了当前AI工程化的真相。开发者们逐渐意识到,一个在演示中表现惊艳的Demo与一个能够稳定运行的生产级系统之间,隔着一整套被称为Harness的工程体系。这套体系决定了模型能否处理长程任务、能否在错误中自我修复,以及能否在受控的边界内安全运行。
核心哲学:Harness是智能体的“操作系统”
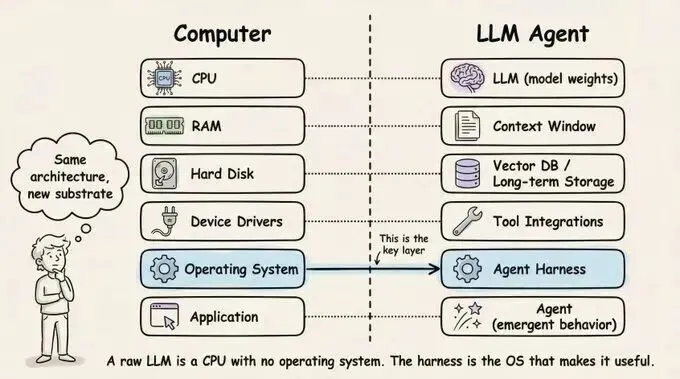
要理解Harness,最贴切的类比是计算机架构。一个裸的大语言模型就像是一个高性能的CPU,它拥有强大的计算能力,但缺乏外部接口和持久化能力。如果没有内存、硬盘和输入输出设备,CPU只是一个无法产生实际功用的计算核心。在这种语境下,上下文窗口(Context Window)充当了高速缓存,外部数据库则是其硬盘,而各种API集成则是其设备驱动。Harness,便是协调这一切的操作系统。
这种类比揭示了一个深刻的洞察:我们正在AI领域复刻冯·诺依曼架构(Von Neumann architecture)。这种抽象并非偶然,而是任何计算系统在追求通用性与可靠性时的必然演进路径。Harness的作用在于将不确定性的模型输出,通过确定性的工程手段,转化为可预测的业务行为。
从工程视角看,智能体的构建涵盖了三个层层递进的圆环:最内层是提示工程(Prompt Engineering),负责指令的精细化;中间层是上下文工程(Context Engineering),负责信息的动态调度;而最外层则是Harness工程,它包罗万象,承载了状态持久化、错误恢复和安全护栏等所有使“自主性”成为可能的工程实现。
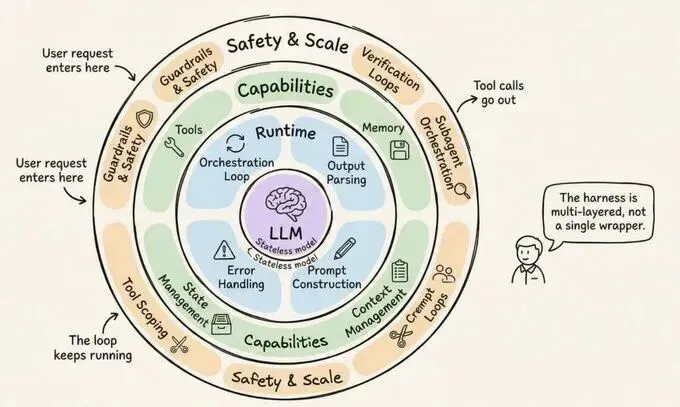
以下我们将深度拆解构成生产级Agent Harness的十二个核心模块。
1. 编排循环(Orchestration Loop):智能体的心跳
编排循环是Harness的核心驱动力,它实现了经典的思考-行动-观察(Thought-Action-Observation, TAO)循环,也就是我们熟知的ReAct模式。这个循环本质上是一个管理状态机的控制流:它负责组装当前的提示词,调用LLM生成决策,解析输出中的工具调用指令,执行该指令并捕获结果,最后将观察到的反馈重新喂给模型。
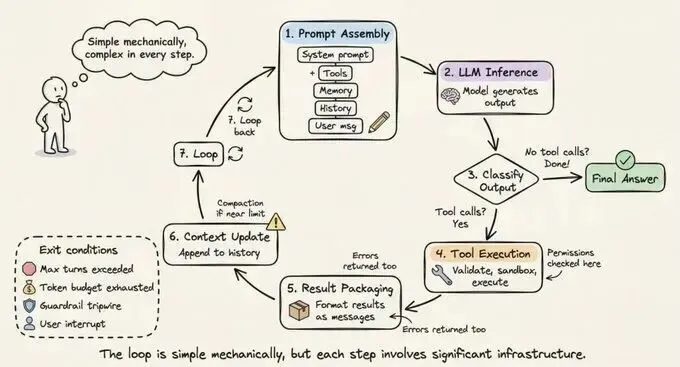
在生产环境中,编排循环的复杂度并不在于其逻辑循环本身,而在于对循环边界的处理。例如,如何防止模型陷入死循环?如何设定最大步数以控制成本?一个优秀的Harness会采用“笨循环、聪明模型”的策略,将复杂的决策权交给模型,而将严格的流程控制逻辑固化在Harness中。
2. 工具集成层(Tool Integration):智能体的手
工具层是Agent与现实世界发生交互的唯一媒介。在Harness中,工具不仅仅是API调用,它包含了一套完整的生命周期管理:从工具Schema的定义与注入,到参数的自动校验,再到执行环境的沙箱化。高效的工具层必须能够处理异构的输入输出,并具备结果格式化的能力,以确保模型能够读懂“观察结果”。
个人观点:工具层的深度直接决定了Agent的“职场天花板”。未来的Harness将不再仅仅是被动地调用API,而是具备“工具发现”能力,能够根据任务需求动态加载甚至现场编写脚本来解决问题。
3. 记忆管理(Memory Management):跨越时空的连续性
记忆模块解决了LLM“无状态”的本质缺陷。它通常分为短期记忆(当前对话的上下文)和长期记忆(基于向量数据库的经验存储)。Harness需要决定哪些信息值得被永久记住,哪些信息应该在当前任务结束后丢弃。这涉及到复杂的语义索引和重要性权重计算,确保在关键时刻提取出最相关的历史片段。
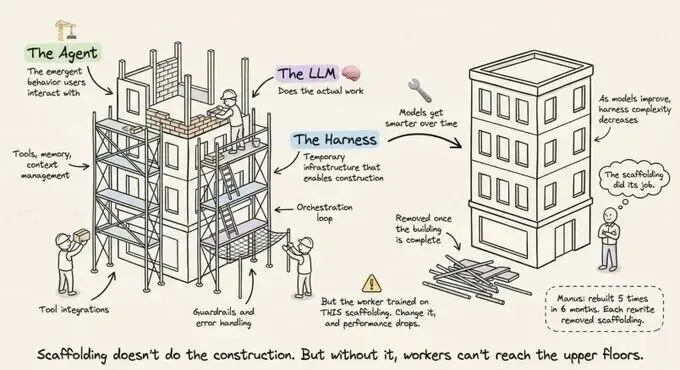
4. 动态上下文管理(Context Management):信息的调度艺术
尽管模型的上下文窗口在不断扩大,但“上下文填充”依然是导致性能下降和成本激增的元凶。Harness的上下文管理模块负责动态压缩、摘要和筛选进入窗口的信息。它像是一个高级编辑,在数万行的日志或文档中,只选出对当前决策最关键的那几百个Token。这种精准的调度能力是区分业余与专业Agent的分水岭。
5. 状态持久化(State Persistence):任务的“存档点”
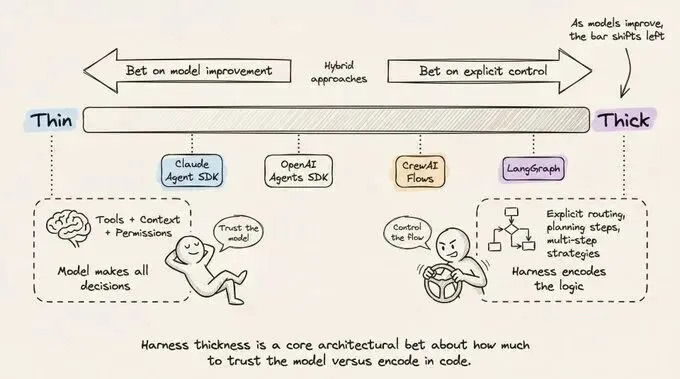
在处理需要数小时甚至数天才能完成的长程任务时,系统崩溃或网络中断是常态。状态持久化模块确保Agent在每一轮循环后都能保存其内部状态(包括当前的思考路径、已获取的变量和待办事项)。这使得Agent具备了“断点续传”的能力,能够从故障中无缝恢复,极大地提升了复杂任务的成功率。
6. 错误处理与自我修复(Error Handling & Recovery)
模型可能会生成错误的语法,工具可能会返回超时。Harness必须具备强大的容错机制。当模型产生幻觉导致工具调用失败时,Harness不应直接抛出异常,而是应该将错误信息反馈给模型,引导其进行自我纠正(Self-correction)。这种闭环的反馈机制是实现真正“自主性”的关键。
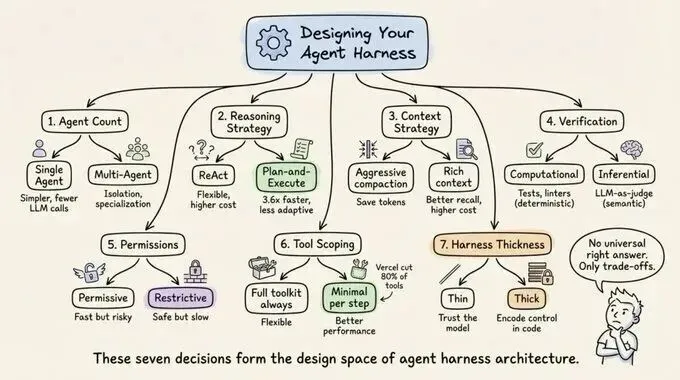
7. 安全护栏(Guardrails):行为的边界
安全护栏是Harness中不可逾越的红线。它负责在指令进入模型前进行合规性检查,并在输出结果到达用户或执行环境前进行拦截。这包括对敏感数据的脱敏、对抗性攻击的防御,以及对高风险操作(如删除数据库)的二次人工确认。安全不是插件,而是Harness架构中不可分割的一部分。
8. 规划与推理模块(Planning & Reasoning)
对于复杂目标,Agent需要先制定宏观计划,再拆解为微观步骤。规划模块通常引入分层架构(Hierarchical Architecture),让一个“经理Agent”负责分解任务,多个“执行Agent”负责具体实施。Harness在此过程中负责维护全局目标与子任务之间的逻辑一致性,防止Agent在细节中迷失方向。
9. 验证与评估循环(Verification Loops)
生产级系统需要对结果负责。验证模块通过引入“LLM-as-a-Judge”或其他确定性校验手段,对模型生成的答案或执行的结果进行质量评估。如果结果未达到预设阈值,Harness会触发重试或切换备选策略。这种闭环评价体系是提升系统可靠性的核心工程手段。
10. 生命周期管理(Lifecycle Management)
这涉及到Agent从初始化、任务执行到资源释放的全过程。它包括Token消耗的配额管理、会话超时的处理以及并发任务的调度。在多用户环境下,高效的生命周期管理能够显著降低基础设施的运营成本,并提高系统的响应速度。
11. 环境沙箱(Execution Sandbox)
为了执行代码或操作文件,Agent需要一个受控的执行环境。Harness提供的沙箱模块确保了代码执行的隔离性,防止恶意代码对宿主系统造成破坏。无论是Docker容器还是Wasm虚拟机,沙箱层都是Agent与操作系统深度交互时的安全底座。
12. 可观测性与日志(Observability & Logging)
由于LLM的非确定性,传统的调试方法往往失效。Harness必须内置全链路追踪能力,记录下每一轮循环中的原始提示词、模型推理过程、工具返回数据及耗时。这不仅是为了事后审计,更是为了通过数据回溯来不断优化Harness的各项参数。
结语:从工程化视角看AI的未来
当我们拨开“人工智能”的神秘面纱,会发现支撑其走向现实生产力的,依然是这些扎实的软件工程原则。Agent Harness的兴起标志着AI开发进入了“系统工程”时代。我们不再只是与一个聪明的对话框聊天,而是在构建一套能够自主思考、自主决策并安全执行的精密机器。
未来,最成功的AI产品可能并不拥有最顶尖的模型,但一定拥有一套最稳健、最灵活的Harness。因为在这个领域,架构的优劣直接决定了智能涌现的上限。对于每一位开发者而言,掌握Harness的十二大模块,便是掌握了通往下一代计算范式的入场券。
 微信AI机器人 |  公众号AI矩阵 |  AI产品 |  微信 |
扫码关注我们一起探索学习AI&建站&营销
加查尔斯微信,微信ID:dreamer901204
