夜雨聆风
夜雨聆风上个月,一个前同事找我。
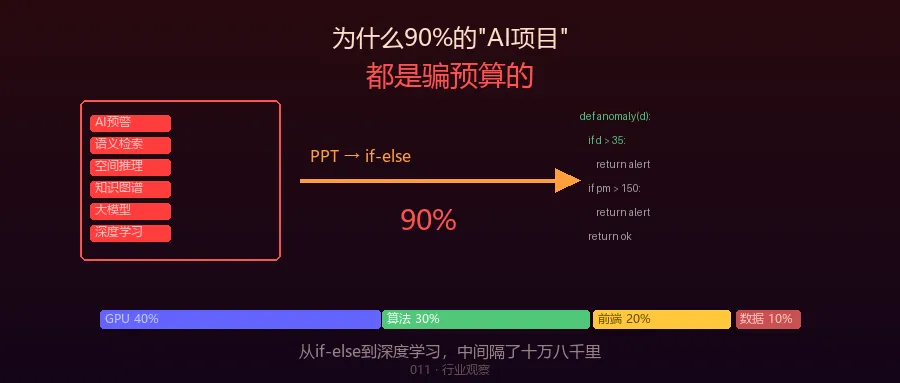
他说他们公司拿了一个"智慧城市数字孪生平台"的项目,预算两千万。甲方要求里面有AI——“智能预警”、“语义检索”、“空间推理”,PPT上写了十几项。
他说,你是搞空间智能的,帮我把AI这块撑起来。
我说,好啊,现有的数据什么样。
他说,数据还在对接。但甲方要下个月看demo。
我说,没有数据,demo怎么出。
他说,所以才找你嘛。
我当时没意识到,这句话的真正意思是——
用假的AI,撑一个真的项目。
两周之后,我看到了他们所谓的"AI智能预警系统"的代码。
# 这就是那个"AI驱动的城市异常检测引擎"defanomaly_detection(sensor_data):"""AI-based urban anomaly detection"""# 规则1:温度超过35度就报警if sensor_data['temperature']>35:return{"alert":True,"type":"高温预警","confidence":0.95}# 规则2:人流量超过阈值if sensor_data['crowd_density']>5:return{"alert":True,"type":"人流密集预警","confidence":0.9}# 规则3:PM2.5超过150if sensor_data['pm25']>150:return{"alert":True,"type":"空气质量预警","confidence":0.85}# 兜底:没有异常return{"alert":False,"confidence":0.99}这不是AI。这是一堆 if-else。
但PPT上写的是——
“基于深度学习+大语言模型的多模态城市异常检测引擎,采用自研时空图神经网络架构,实现秒级预警响应。”
每一句话都不是假的。
●“深度学习”:他们确实准备用,只是demo阶段没写。
●“大语言模型”:接了个OpenAI的API做告警文案生成。
●“自研时空图神经网络”:正在招人。
●“秒级预警响应”:if-else 当然是秒级。
技术上没有一句话是谎言。但整体就是骗。
我把这个系统拆成了三类。不是我发明的,是这个行业里每天都在发生的事。
第一类:PPT AI
PPT上什么都有。代码里什么都没有。
# PPT:# - 多模态大模型驱动的空间推理引擎# - 基于3D Gaussian Splatting的实时场景重建# - 千万级实体知识图谱关联推理# 代码:import requestsdefdemo():return{"status":"success","message":"AI引擎已部署","version":"1.0.0"}这类项目的特点是——甲方要的是PPT,不是产品。
因为甲方的PPT也要往上汇报。他拿了你给他做的"AI平台"的截图,放进他自己的PPT里,然后去找他的领导要下一笔预算。
你做的不是AI产品,你做的是甲方PPT的素材。
链条是这样的:
政府发政策 → "大力推进AI+城市建设" → 市级单位立项,拿到预算 → 外包给大公司,PPT上写满AI → 大公司分包给小公司,AI缩水一半 → 小公司找外包,AI变成if-else → 最终交付:一个会发告警短信的Web后台每一层都没骗人。每一层都按合同交了货。但最顶层说要做的"AI",和最底层实际交付的"if-else"之间,差了十万八千里。
钱在每一层都被抽走了。最后留给"AI"的预算,连一个好的GPU都买不起。
第二类:Wrapper AI
比PPT AI好一点——至少能跑。
# "AI驱动的空间语义搜索引擎"defsearch_spatial(query, location_data):"""AI语义搜索附近设施"""# 调一个LLM API,把自然语言转成结构化查询 llm_response = openai.ChatCompletion.create( model="gpt-4", messages=[{"role":"user","content":f'把"{query}"转成JSON格式: {{"type": str, "radius": int}}'}])# 解析LLM返回的JSON params = json.loads(llm_response['choices'][0]['message']['content'])# 在数据库里做普通查询 results = db.query(""" SELECT * FROM facilities WHERE type = ? AND ST_Distance(location, ?) < ? """,[params['type'], location_data, params['radius']])# 再调一次LLM把结果"总结"成自然语言 summary = openai.ChatCompletion.create( model="gpt-4", messages=[{"role":"user","content":f"用专业语气总结以下搜索结果: {results}"}])return{"results": results,"ai_summary": summary['choices'][0]['message']['content'],"ai_confidence":0.92# 随便写的}这个系统看起来是AI——用户说一句"帮我找附近三公里内的医院",系统返回了医院列表和一段"AI总结"。
但它做的事情,跟五年前的关键词搜索没有本质区别。"附近医院" → "type='hospital' AND distance < 3000"。
唯一的区别是中间加了个LLM当翻译官。而且这个翻译官有时候还会翻译错——
# 用户说:"帮我找附近不太吵的公园"# LLM返回:{"type": "park", "radius": 5000, "noise_level": "low"}# 数据库报错:列 "noise_level" 不存在数据库里没有噪音等级这个字段。但AI已经自信满满地返回了"confidence: 0.92"。
第三类:Zombie AI
这类最可怕。因为它真的上线了。
# "AI城市体检系统" — 已部署,日活用户:3defcity_health_check():"""AI驱动的城市健康评估"""# 每天凌晨3点自动运行 data = fetch_all_sensor_data()# 跑一个训练了三个月的模型# 模型最后一次更新:6个月前 predictions = model.predict(data)# 生成PDF报告# 报告格式跟去年一样,只是改了日期和数字 report = generate_pdf(predictions, date=today())# 发送到指定邮箱# 邮箱列表:5个人# 打开率:0% send_email(report, to=["领导A@xx.gov.cn","领导B@xx.gov.cn",...])return"done"它活着。每天跑。每天发报告。
没有人看。
但它"已上线"这件事,就足够让项目验收通过,让尾款到账,让团队去接下一个两千万的项目。
PPT上会写——“AI系统已成功部署于XX市,日均处理数据量XX万条,为城市管理提供智能决策支持”。
这句话里没有一个字是假的。但它也没有一个字是真的有用。
回到开头那个故事。
我没有帮他把那个demo做完。
不是因为做不了。而是因为做完了之后,我知道会发生什么:
demo通过 → 甲方满意 → 项目进入开发阶段 → 数据终于对接上了 → 发现AI模型根本跑不起来 → 数据质量太差 → 模型准确率不到50% → 项目经理说先用规则顶一下 → 规则越写越多 → AI模块变成了注释里的代码 → 最终交付:跟开头那个if-else一模一样这个链条我太熟悉了。不是因为我做过。是因为我见过太多次了。
为什么90%?
因为那10%真的在做AI的项目,有三个特征,跟那90%完全不同。
特征一:从问题出发,不从AI出发
# 90%的项目:# 问题:"领导说要上AI,我们用什么AI?"# 答案:选一个最热门的,写进PPT# 10%的项目:# 问题:"城市内涝预警准确率只有60%,怎么提高?"# 答案:分析现有系统的瓶颈 → 发现是数据融合不够# → 引入多模态模型融合气象+管网+地形数据# → 预警准确率从60%提升到85%90%的项目,AI是目的。10%的项目,AI是手段。
目的和手段的区别是——手段可以换,目的不能变。
如果用规则引擎能达到85%的准确率,那10%的项目会用规则引擎,而不会硬上深度学习。但90%的项目不会——因为他们已经跟领导说了"我们要用深度学习"。
特征二:敢承认AI做不到什么
# 90%的项目:# "我们的AI系统可以实现100%准确的城市异常检测"# (实际:if-else,阈值是人工调的)# 10%的项目:# "我们的AI系统在暴雨场景下预警准确率是85%,# 但在极端天气(比如台风)下会下降到60%,# 原因是训练数据里台风样本太少。"敢说出"AI做不到什么"的项目,通常是真的在做AI的。因为只有真的训练过模型的人,才知道模型的边界在哪。
没有训练过模型的人,会认为AI是万能的——因为他的AI知识来自PPT和新闻。
特征三:预算花在数据上,不花在模型上
# 90%的项目预算分配:# GPU服务器: 40% (买最贵的,用来撑门面)# 算法工程师:30% (高薪挖人,头衔要好听)# UI/前端: 20% (dashboard要好看,PPT要用)# 数据: 10% (数据?不是有数据库吗)# 10%的项目预算分配:# 数据治理: 40% (清洗、对齐、标注、补全)# 基础设施: 20% (GPU够用就行)# 算法工程师:20% (不一定要大厂背景,但要懂业务)# 数据标注: 10% (好模型不如好数据)# UI/前端: 10% (能用就行)90%的项目,数据是最后被想到的东西。10%的项目,数据是最先被想到的东西。
因为在AI项目里,数据决定了天花板,模型只是在这个天花板下面够一够。
但跟领导汇报的时候,"我们花了40%的预算清洗数据"没有"我们买了8张A100"好听。
空间智能领域的AI项目,还有一个额外的坑。
# GIS领域的"AI"项目,特别喜欢用一个词:# "赋能"# "AI赋能GIS"# "大模型赋能空间分析"# "3DGS赋能数字孪生"# 翻译过来就是:# 在原来的产品上,加了一个AI的按钮。defold_gis_system():"""传统GIS系统"""return query("SELECT * FROM buildings WHERE height > 50")defai_empowered_gis():"""AI赋能的GIS系统"""# 加了一个LLM,把自然语言转成SQL sql = llm_translate("帮我找高度超过50米的建筑")return query(sql)# 就这。# 但PPT上叫"AI赋能"。真正的空间智能,不是"AI+GIS"。
是AI从根本上改变了你理解空间的方式。
# 这不是赋能。这是替换。# 以前:# 人写规则 → 系统按规则查询 → 人分析结果# 真正的空间智能:# 系统自己从数据中学习空间模式 → 发现人写不出来的规则# 比如:# - 从30万条120报警记录中,自动发现"夜间22-24点、# 餐饮密集区、雨天"三个因素叠加时,纠纷发生率是平时的3.7倍# - 这个规律不是任何人预设的。是模型从数据里自己"看"到的# 这才叫空间智能。不叫"AI赋能"。所以我后来跟那个前同事说了一句话。
我说,你这个项目,最好的结局是——
甲方拿了你的demo去汇报 → 领导很满意 → 批了更多预算 → 招了真正懂AI的人 → 推翻了所有if-else → 从零开始做了真正的AI系统这是最好的结局。
最常见的结局是——
甲方拿了demo去汇报 → 领导很满意 → 项目继续推进 → 数据对接完成 → 发现AI跑不起来 → 继续用if-else → 项目验收 → 尾款到账 → 系统上线 → 无人使用 → 两年后:服务器下线这个结局里,每个人都拿到钱了。
除了城市。
那90%的"AI项目"里,有没有好东西?
有。
它们至少做了一件事——把"AI"这个词,塞进了政府的采购目录里。
三年前,政府的采购清单上写的是"信息化建设"。今年写的是"AI+智慧城市"。
从"信息化"到"AI",这个词的变化,意味着预算的方向变了。
方向变了之后,那10%真正在做AI的人,终于能拿到钱了。
虽然大部分钱还是流向了PPT。但总比三年前连门都找不到要好。
所以这篇文章的标题,其实不够准确。
不是"90%的AI项目在骗预算"。
而是——
在任何一个新风口上,90%的资源都会流向PPT。剩下10%的资源,才够真正做事的人吃饱。
AI不是第一个。云计算是,大数据是,区块链是,元宇宙也是。
AI也不会是最后一个。
但那10%的人做出来的东西,比90%的PPT活得久。
数据来源与参考:
●本文案例来源于作者参与/观察的多个智慧城市、数字孪生、空间AI项目的真实经历
●部分代码为示意性伪代码,不代表任何具体项目的实际实现
●行业预算分配数据基于公开招投标信息整理
专注空间智能技术拆解与产业分析。GIS+AI+具身智能三合一观察者。
以上,既然看到这里了,如果觉得不错,随手点个赞、在看、转发三连吧,如果想第一时间收到推送,也可以给我个星标⭐~谢谢你看我的文章,我们,下次再见。