 夜雨聆风
夜雨聆风Hermes Agent是OpenClaw之后的下一代智能体,他具备自我学习、自我进化的功能,你使用的越久,他就越懂你,大家不要因为智能体工具太多而觉得烦,因为你使用网页AI比如GPT,你也不会只使用一个,多尝试不同的工具会为你解决不同场景下的问题。
快速安装 Hermes Agent
本质上安装只需要一行命令,但在不同系统下有一些前置条件。Hermes 的底层控制权非常深,官方明确不支持 Windows 原生环境,因此 Windows 用户必须通过 WSL2 虚拟机来运行。另外,你需要提前搞定网络问题。
Mac 系统安装
苹果系统拥有原生的生态支持,推荐首选。如果你在本地开了网络软件(假设端口是 7897),首先要让终端走代理。因为终端默认是不走代理的,你需要执行这四行配置:
echo 'export http_proxy="http://127.0.0.1:7897"' >> ~/.zshrcecho 'export https_proxy="http://127.0.0.1:7897"' >> ~/.zshrcecho 'export all_proxy="socks5://127.0.0.1:7897"' >> ~/.zshrcsource ~/.zshrc代理生效后,直接执行官方一键安装命令。脚本会自动帮你安装 Python、Node 依赖包,并进入系统初始化界面。
curl -fsSL https://raw.githubusercontent.com/NousResearch/hermes-agent/main/scripts/install.sh | bashWindows 系统安装
先点击开始菜单,搜索并打开 PowerShell,执行 wsl --install。安装完毕后设置好用户名和密码,输入 wsl 就能进入 Linux 系统。
为了让 WSL 连网顺畅,不建议去替换国内的 NPM 镜像源。因为 Hermes 安装会同时从 GitHub、NPM、Python 库下载大量组件,单纯换镜像有可能还是会有问题。更稳妥的做法是让 WSL 走 Windows 宿主机的网络代理。把你代理软件的局域网连接功能打开,然后把下面这段脚本直接粘贴进终端里执行:
# 1. 定义配置块,增加唯一标识符防止重复写入PROXY_BLOCK_START="# >>> WSL PROXY CONFIG >>>"PROXY_BLOCK_END="# <<< WSL PROXY CONFIG <<<"# 2. 清理旧配置,防止多次执行导致 .bashrc 变得臃肿sed -i "/$PROXY_BLOCK_START/,/$PROXY_BLOCK_END/d" ~/.bashrc# 3. 写入新配置(使用更加健壮的 IP 获取方式)cat << EOF >> ~/.bashrc$PROXY_BLOCK_START# 动态获取宿主机IP:先尝试路由表,如果失败则尝试 resolv.confexport hostip=\$(ip route show | grep default | head -n 1 | awk '{print \$3}')if [ -z "\$hostip" ]; then export hostip=\$(grep nameserver /etc/resolv.conf | awk '{print \$2}')fiexport PROXY_PORT=7897export http_proxy="http://\$hostip:\$PROXY_PORT"export https_proxy="http://\$hostip:\$PROXY_PORT"export all_proxy="socks5://\$hostip:\$PROXY_PORT"# 必须配置 NO_PROXY,防止本地开发流量走代理export NO_PROXY="localhost,127.0.0.1,::1,*.local,192.168.*,10.*,172.16.*,172.17.*,172.18.*,172.19.*,172.20.*"$PROXY_BLOCK_ENDEOF# 4. 生效并提示source ~/.bashrc# 5. 配置 npm(若已安装) if command -v npm >/dev/null 2>&1; then npm config set registry https://registry.npmmirror.com npm config set proxy "http://$hostip:$PROXY_PORT"npm config set https-proxy "http://$hostip:$PROXY_PORT"npm config set fetch-retries 5npm config set fetch-timeout 600000fiecho "WSL2 网络代理已永久配置完成。"echo "当前 Windows 宿主机 IP: $hostip"echo "本地开发白名单 (NO_PROXY) 已自动配置。"代理配置好之后,和 Mac 一样执行官方安装脚本就可以了。安装完成后,系统会询问是否马上运行,输入 y 进入对话页面,随便发一句“你好”,只要它能回复,就说明彻底装好了。
如果你没有网络工具,那么只能通过替换npm镜像和apt源的方式来安装,有可能有少部分组件会安装不上,但不影响使用。在wsl2里执行:
set -eecho "检测 Ubuntu 版本..."CODENAME=$(lsb_release -cs)echo "备份原始源..."sudo cp /etc/apt/sources.list /etc/apt/sources.list.bak 2>/dev/null || truesudo cp /etc/apt/sources.list.d/ubuntu.sources /etc/apt/sources.list.d/ubuntu.sources.bak 2>/dev/null || trueecho "配置 APT 清华源..."if [ -f /etc/apt/sources.list.d/ubuntu.sources ]; thensudo tee /etc/apt/sources.list.d/ubuntu.sources > /dev/null <<EOFTypes: debURIs: https://mirrors.tuna.tsinghua.edu.cn/ubuntu/Suites: $CODENAME $CODENAME-updates $CODENAME-backportsComponents: main restricted universe multiverseSigned-By: /usr/share/keyrings/ubuntu-archive-keyring.gpgTypes: debURIs: https://mirrors.tuna.tsinghua.edu.cn/ubuntu/Suites: $CODENAME-securityComponents: main restricted universe multiverseSigned-By: /usr/share/keyrings/ubuntu-archive-keyring.gpgEOFelsesudo tee /etc/apt/sources.list > /dev/null <<EOFdeb https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ $CODENAME main restricted universe multiversedeb https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ $CODENAME-updates main restricted universe multiversedeb https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ $CODENAME-backports main restricted universe multiversedeb https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ $CODENAME-security main restricted universe multiverseEOFfiecho "更新 apt..."sudo apt updateecho "安装基础组件..."sudo apt install -y curl git build-essential ffmpeg ripgrepecho "配置 npm 镜像..."npm config set registry https://registry.npmmirror.comecho "配置 Playwright 镜像..."npm config set ELECTRON_MIRROR https://npmmirror.com/mirrors/electron/npm config set PLAYWRIGHT_DOWNLOAD_HOST https://npmmirror.com/mirrors/playwrightecho "当前 npm registry:"npm config get registryecho "完成。"然后运行官方安装命令即可。
最新版本的 Hermes 增加了网页端控制面板。在命令行输入 hermes dashboard 就能在浏览器里打开图形化设置界面。不过目前网页端仅开放了系统设置,未来才会支持聊天功能。
常用命令与连通通讯软件
必须掌握的核心命令
日常排障和更新,下面这几个命令最实用:
• hermes setup:重新呼出初始化设置向导。• hermes update:官方迭代速度很快,用它来拉取最新版本。• hermes doctor:和 OpenClaw 一样,环境出毛病了先用它诊断。执行hermes doctor --fix可以让系统尝试自动修复。• hermes claw migrate:一键把你在 OpenClaw 里的记忆、配置和自定义技能全部搬运过来。
连通微信与飞书
Hermes 同样支持通过手机上的即时通讯软件派发任务。回到命令行,输入 hermes gateway setup 进入网关配置环节:
• 飞书:选择飞书后直接扫码,系统会在后台自动帮你建好机器人。权限选择“第一次连接需要配对码”或“允许所有”,群聊唤醒方式选 mentioned in groups。 • 微信:直接扫码登录即可。这里用的是之前微信直连 OpenClaw 的那个 ClawBot 机器人,重新扫码后新通道会自动覆盖掉旧的数据。
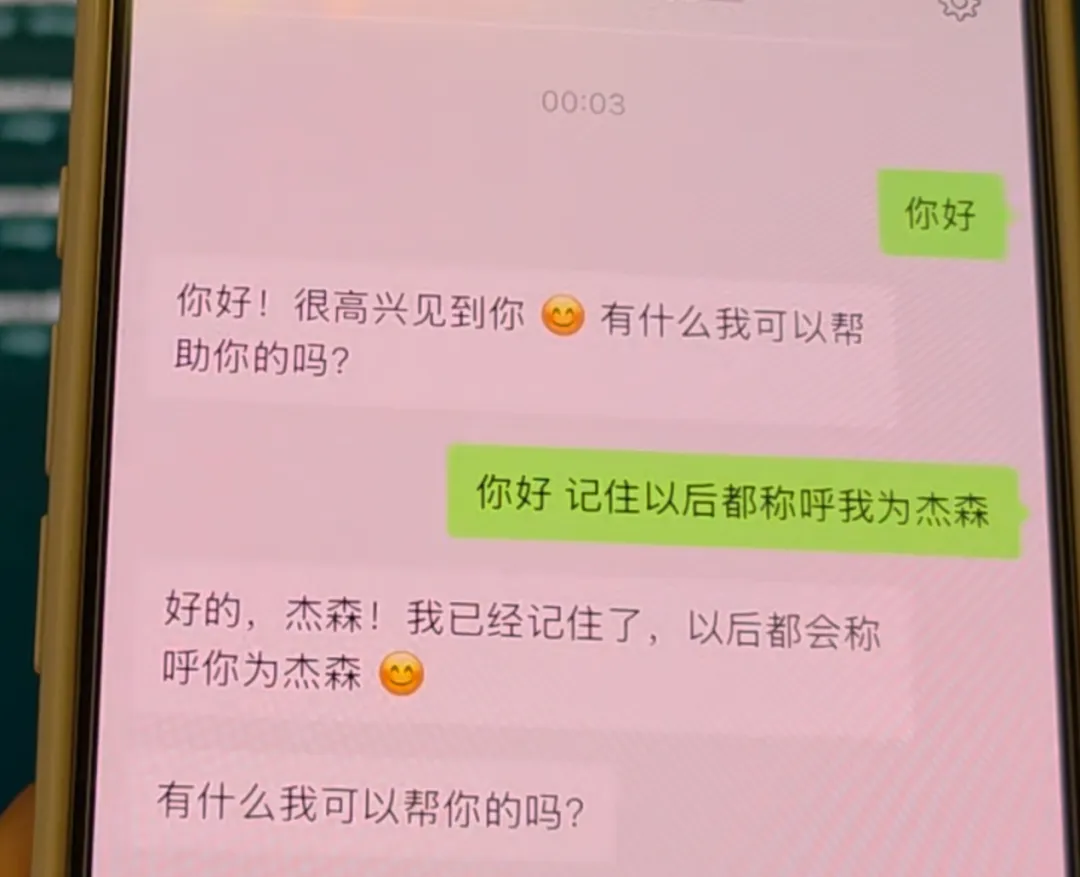
连通后,你在微信里给它发一句:“你好,记住以后都称呼我为杰森”。回到 Hermes 的网页控制台刷新一下 Session 页面,就能实时看到同步的聊天记录。
彻底掌握记忆机制
市面上的工具往往你一刷新网页,它就把你忘了。Hermes 最大的特点就是自动收集线索,完成自我成长。作为用户,你其实只需要做两步:
1. 手动修改全局约束 (SOUL.md):找到系统路径 ~/.hermes/SOUL.md。这个文件是系统的绝对行事准则,优先级最高。你一定要把“输出保持简洁”、“遇到代码必须用 TypeScript 并写全注释”这类规则手动敲进去。2. 聊天时主动纠偏:当你告诉它“我喜欢看 Mermaid 格式的思维导图”,它就会默默调用记忆工具把这句话刻进脑子里。
其余的工作全交给 Hermes 自动处理。它的内部记忆分为了四个存储区块:
• 个性化用户画像 (USER.md):限制约 500 Tokens,记录你的身份与偏好。系统会自动观察并静默更新。 • 事实性长期记忆 (MEMORY.md):限制约 800 Tokens,存放项目经验和客观事实,空间快满时它会自己跑去合并压缩内容。 • 跨会话历史检索:所有的聊天记录都存在本地的 SQLite 数据库里。当你提及很久以前聊过的话题,智能体会触发 session_search工具,把数据库里的碎片全部找出来拼接好再回答你。• 项目局部上下文 (AGENTS.md):只要你把这个文件丢进具体的代码文件夹里,以后在终端进入这个目录,Hermes 就会自动读取里面的专属规则,各个项目互不干扰。
辅助模型分配 (性能与成本控制)
刚才提到的 session_search 其实是系统内置的 8 个底层任务之一。为了省钱并提高响应速度,我们要给不同难度的任务分配最适合的模型:
• 网页内容提取 (web_extract):纯纯的体力活,把网页 HTML 洗成 Markdown。配置本地零成本模型比如 Qwen 3.5:14b 最合适。 • 历史会话检索 (session_search):典型的 RAG 文本组装,用速度极快的推理模型,比如 DeepSeek V3 或者 Gemini 3 Flash。 • 视觉多模态 (vision):要用它解析前端截图,必须挑视觉底子强的,建议上 Gemini 3 Pro 或 Kimi K2.5。 • 技能中枢 (skills_hub):这关乎它能不能在后台帮你把代码写对,一分钱不能省。强制分配 GPT-5.4 或者 Claude 4 级别的算力。
通过命令行可以单独指定某个任务的提供商和具体模型。如果你接了 OpenRouter 这类的聚合器,模型名称前必须要带上厂商前缀:
# 指定使用 OpenRouter hermes config set auxiliary.skills_hub.provider openrouterhermes config set auxiliary.skills_hub.model anthropic/claude-4# 指定使用 Anthropic 官方直连hermes config set auxiliary.skills_hub.provider anthropichermes config set auxiliary.skills_hub.model claude-sonnet-4-6警惕上下文压缩崩溃风险
当你的对话越来越长,AI 响应速度明显变慢时,你需要使用 /compress 聚焦的主题名称 这个命令,强行让系统砍掉废话,把注意力拉回到核心逻辑上。
这里有一个致命坑点需要避开:你给压缩任务 compression 分配的模型,它的上下文容量上限,必须远远大于你聊天的主力模型。如果你主模型能扛 100 万字,但压缩用的模型最高只支持 3 万字。一旦触发压缩,系统瞬间塞给它几十万字,就会爆出内存超载错误。为了保护系统不崩溃,Hermes 会直接静默丢弃你所有的中间聊天记录。
为了彻底杜绝这个风险,务必把长上下文模型分配给压缩任务,比如 Gemini 3 Flash:
技能扩展与卡帕西知识库管理
Hermes 目前已经有了几百个现成的外部扩展技能。你可以直接在终端输入 hermes skills install 技能名 安装,或者把之前的技能文件拖到 ~/.hermes/skills/ 目录里。
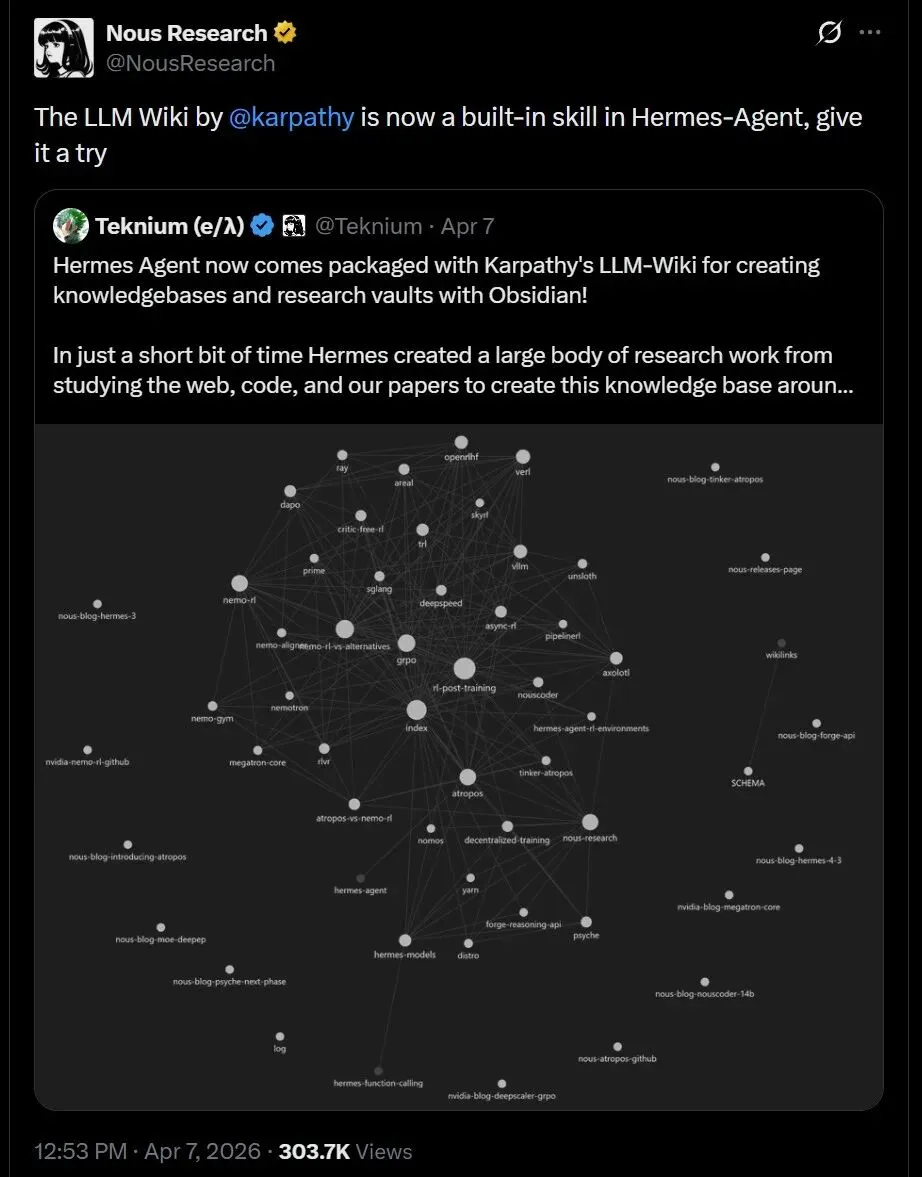
官方亲自下场做了一个名为 llm-wiki 的神级技能,这是对硅谷 AI 大神 Karpathy 知识库理念的完美复刻,对 Obsidian 用户极度友好。
具体玩法如下:打开 ~/.hermes/.env 文件,把环境变量 WIKI_PATH 填上你的 Obsidian 知识库绝对路径。设置好之后,直接用斜杠命令跟它交互:
• 喂资料进去: /llm-wiki ingest ~/ob-vault/raw/paper.pdf• 找它查资料: /llm-wiki query 讲讲 Cursor 和 OpenClaw 的对比?• 知识体检: /llm-wiki lint
每次执行完,Hermes 就会自动在 Obsidian 里给你归档出规范的实体页面、概念对比表,甚至连操作日志都按年分好类。
当前好用的免费 AI 模型供应商
如果你暂时不想为大模型付费,可以利用这三个平台的官方免费额度:
1. Google AI Studio (推荐 Gemma 4)最近新发的 Gemma 4 在端侧和代码能力上表现很好,Google 每天给开发者送 1500 次调用额度,26b 和 31b 参数版本都支持。申请好 API Key 就能免费试用。
# 测试接口连通性的代码curl "https://generativelanguage.googleapis.com/v1beta/models/gemma-4-31b-it:generateContent" \ -H "x-goog-api-key: $你的apikey" \ -H 'Content-Type: application/json' \ -X POST \ -d '{ "contents": [{ "parts":[{"text": "请简述Gemma 4相比Gemma 3的核心提升。"}] }], "generationConfig": { "temperature": 0.7, "maxOutputTokens": 2048 } }'2. 英伟达 AI 服务 (MiniMax M2.7)MiniMax M2.7 刚刚开源,英伟达 NIM API 直接提供了免费接口,每分钟可以发 40 次请求,注册账号就能拿到 API Key。接口地址为:https://integrate.api.nvidia.com/v1,填写的模型名称是 minimaxai/minimax-m2.7。
3. OpenRouter 免费专区这也是个很靠谱的渠道,很多新模型正式发布前都会放在这里免费公测。搜索页面打上 free 标签,随时关注上架的新货。
以上就是Hermes Agent的安装方法以及核心技巧。
如果你在环境配置中卡壳了,欢迎在留言区提问。
