 夜雨聆风
夜雨聆风Agentic AI 时代代表作即龙虾OpenClaw,最典型搭配就是OpenClaw部署于售价不足万元的 Mac Mini M4,作为其 24 小时私人助理,通过短消息交互(e.g.,WhatsApp),让它写 Bash 脚本整理照片,调用本地知识库解答问题,甚至控制智能家居。
M4芯片采用第二代3nm工艺,集成10核CPU、10核GPU和16核神经网络引擎,AI算力达19 TOPS@FP16,38TOPS@INT8,这个算力值显然远低于目前主流的所谓AI PC,这也证明AI算力数字毫无意义。苹果MAC其核心优势一是在于统一内存架构(UMA),即CPU、GPU与NPU共享同一内存池,避免了传统分离架构中频繁的数据拷贝开销,使16GB UMA的实际可用性接近32GB传统内存。配合MLX框架对中文模型的深度优化和4-bit量化技术,M4 Mac mini可高效运行Llama3.2、Qwen等7B-13B参数模型,推理速度稳定在19-34 tokens/s。最大优势还是CPU性能,特别是单核性能足以媲美最强台式机CPU如 i9-14900K。
与 AI 助理和 ChatBot 相比, AI 智能体的最大特点在其自主性,以及为实现给定目标的独立决策和多步复杂性操作。而要实现这些,就要求 AI 智能体具有如下细分能力:
感知(Perception):接收文本、语音、图像或来自外部 API 的数据的能力。当前的多模态大模型基本都具备这方面的能力。
规划(Planning):将复杂目标拆解为具体的执行步骤,并根据环境变化调整计划的能力。这要求大模型具备 Chain-of-Thought(CoT) 分步 reasoning推理的功能, 实现对特定目标的分步拆解; 同时还需具备 ReAct 模式, 减少Reasoning 过程中出现的幻觉,并能够根据环境反馈进行调整。
记忆(Memory):保存短期对话和长期经验,以便在后续任务中利用历史信息。这不一定要通过大模型本身来实现,但需要它支持长上下文。
行动(Action):通过调用外部工具(如搜索、计算器、代码解释器)来执行具体的物理或数字任务。
Agentic AI 的实现模式
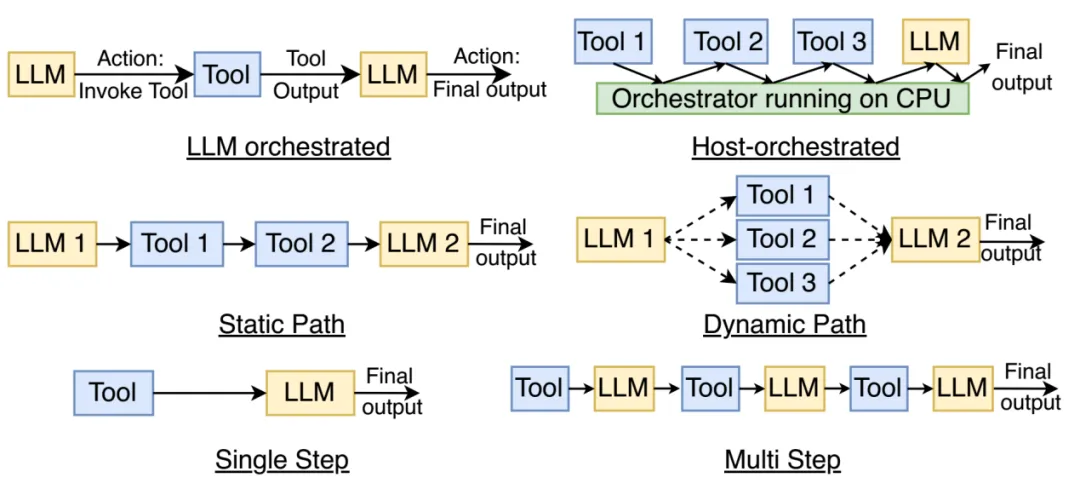
图片来源:论文《A CPU-Centric Perspective on Agentic AI》
上图是Agentic AI 的实现模式, LLM Orchestrated (工具调用由模型发起,而非其他工具);动态路径(每次工具调用,工具选择不唯一), 多步骤(支持工作链路上,LLM 多次调用工具),如上图右侧所示。
LLM-orchestrated (由模型调度) vs Host-orchestrated (由 Python 代码调度)。前者高度依赖 CoT,模型自己思考该干什么;而后者,若基础模型没有 CoT,开发者必须在外部编写极其复杂的 Python 逻辑(比如,if-else分支)来告诉模型:第一步干什么,第二步干什么。
无论是云端还是端侧,AI智能体时代,都是CPU更重要。
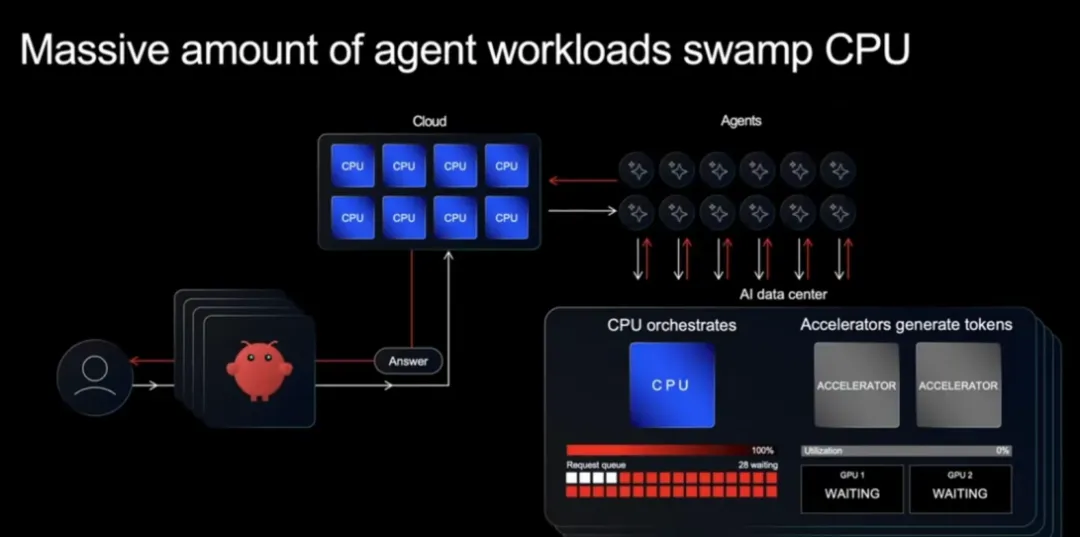
图片来源:ARM
虽然token由GPU或其他加速器生成;但人类对云上AI发出提示词、提出请求时,云(CPU)会去服务对应的请求,获取数据中心加速器(如GPU)生成的token。而数据中心CPU需要进行编排(orchestrate)工作,再返回token。在此过程中,CPU要执行控制平面的各种操作:包括云CPU负责处理用户面向的逻辑,数据中心CPU则要处理推理控制逻辑。比如云CPU首先要接收用户请求,并解析、验证、决策要用的模型、资源,将请求打包交给加速器集群等;在加速器生成首个token之前,AI数据中心的CPU就需要将模型权重加载并映射到加速器内存、配置缓存、准备首次推理调用、管理batching;在加速器生成token的过程中,CPU执行所谓token-by-token的编排(包括在每次生成token都要更新KV cache、发送下一个请求、应用采样等);
另外还有内存管理、KV cache控制,以及数据中心实际工作中的networking、加载均衡等等工作都只能由CPU完成。这意味着,每个活跃的Agent背后,都有一个由CPU驱动的“数字员工”在干活。当百万级Agent并发运行时,对CPU核心数量等的需求呈指数级增长。这也使得云端的CPU重要性也大大增加,CPU数量暴增到几乎与GPU相等的水平,而之前是1比8,即8块GPU 1块CPU。
AI智能体需要更多的CPU而非GPU
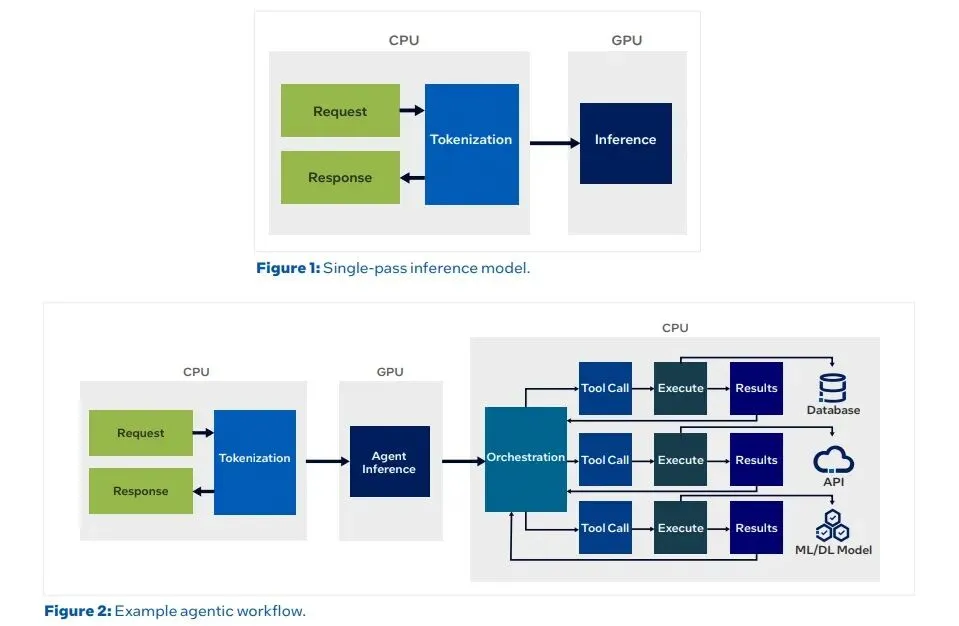
图片来源:英特尔
传统聊天机器人对AI智能体时代CPU与GPU的角色
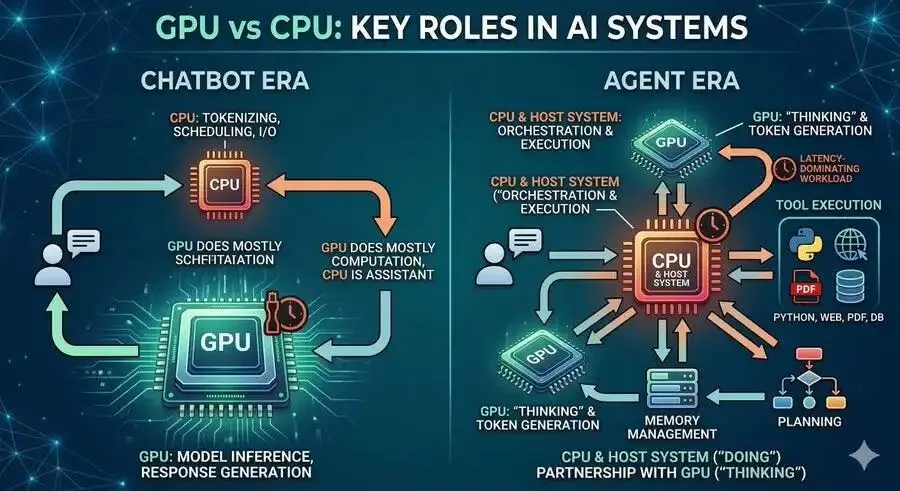
图片来源:网络
AI智能体的CPU/GPU工作流
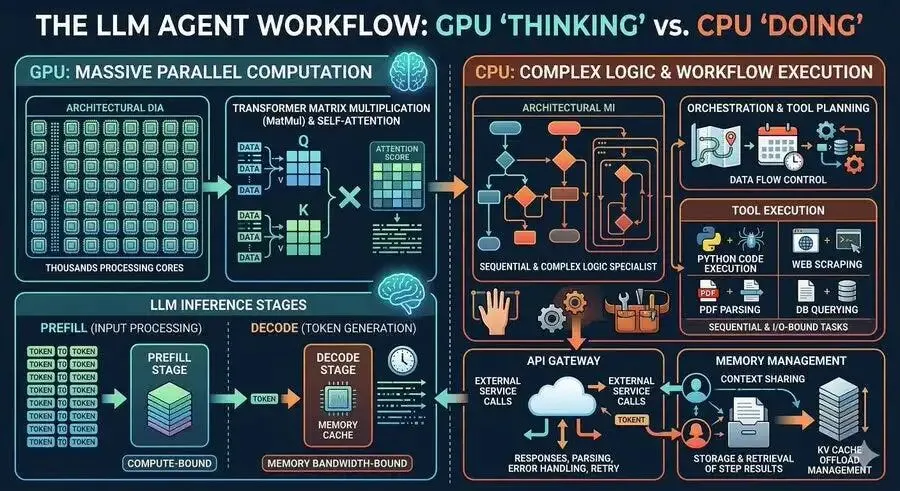
图片来源:网络
传统问答大模型的用户行为是“问完即走”,并发比通常低于1%。而Agent(尤其是编程助手如Cursor、Claude Code)往往被用户长时间挂起,一开就是数小时,这导致两个关键变化:1. 会话时长从分钟级进入小时级,大量沙箱环境长期驻留,持续消耗CPU资源;2. 任务类型分化:易优化的任务,如网页下载、简单解压,CPU占用碎片化,可通过池化技术提升利用率;难优化的任务,如视频渲染、科学计算、长时间代码编译,会持续霸占CPU核心。
端侧也是如此,CPU的DMIPS算力远比AI算力重要,AI算力只需约30-50TOPS就足够了,瓶颈在CPU。
端侧VLA运行时间分析
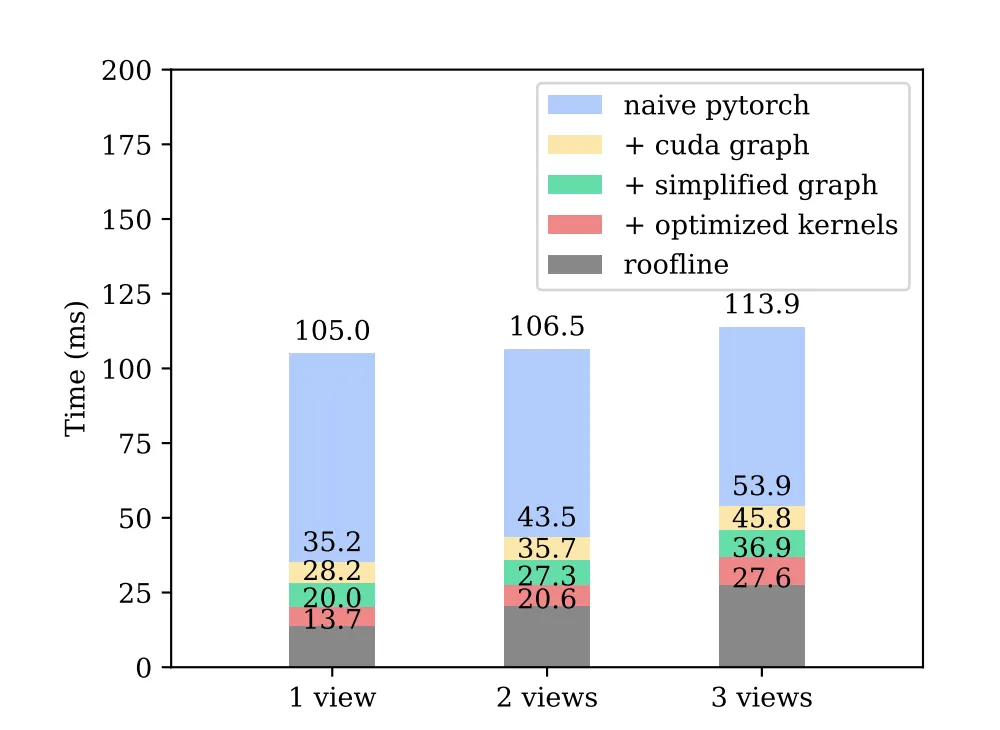
图片来源:原力灵机
上图是端侧VLA运行时间分析,原生Pytorch驱动非常消耗时间,这全都是CPU在做pytorch编译驱动,针对单一算法可以通过CUDA Graph机制,先记录一次推理过程中的所有内核流,后续推理直接重放该流——此时内核由GPU和驱动直接启动,消除部分Python执行开销,但这只针对单一算法(如某一特定的VLA),AI智能体需要面对无穷尽复杂pytorch算法,只能仰赖CPU的算力。
除了Python开销,目前AI智能体用到的最尖端的Engram也以CPU为核心,Engram从RAG发展而来,RAG(Retrieval Augmented Generation,检索增强生成,使其能够在生成响应之前引用训练数据来源之外的权威知识库)就是它获取“外部知识库”的途径。RAG主要就是抑制大模型的错误与幻觉,同时修正外部反馈。RAG 负责提供实际证据。它让模型从“凭空脑补”转向“根据材料作答”,解决了知识过时和不可靠推理的问题。模型先思考,发现缺信息,立刻去 RAG 检索,拿到结果后再修正思维。这种“思考 -> 观察反馈 -> 调整思考”的闭环,是单纯靠增加 Prompt 步数实现不了的,它也是 ReAct 框架的核心。
RAG依据 输入的查询Query,从数据库查询和获取与该 Query 相关的信息,并将这部分信息作为上下文和 Prompt 和 Query 一起输入给大模型。 由于数据库中的相关信息更为及时准确,大模型给出的回答也就避免了知识过时的问题变得更加准确可靠。
RAG依靠文本向量化嵌入、相似度衡量、最临近搜索三步实现,这三步都是非线性运算,无法在GPU中进行,只能完全依赖CPU运行。
AI智能体计算负担分布

图片来源:网络
GPU(NPU)一般只负责Prefill和Decode,其余均由CPU承担,这其中还包括了任务调度,实际无论是AI运算还是非AI运算,CPU都是总指挥,同时也承担部分不适合GPU的计算任务。在一个更为通用的智能体应用设定中,RAG 可能被替代为代码编译,Web 搜索,Python 解析和执行等等。CPU 成了智能体与环境交互的一个关键渠道。
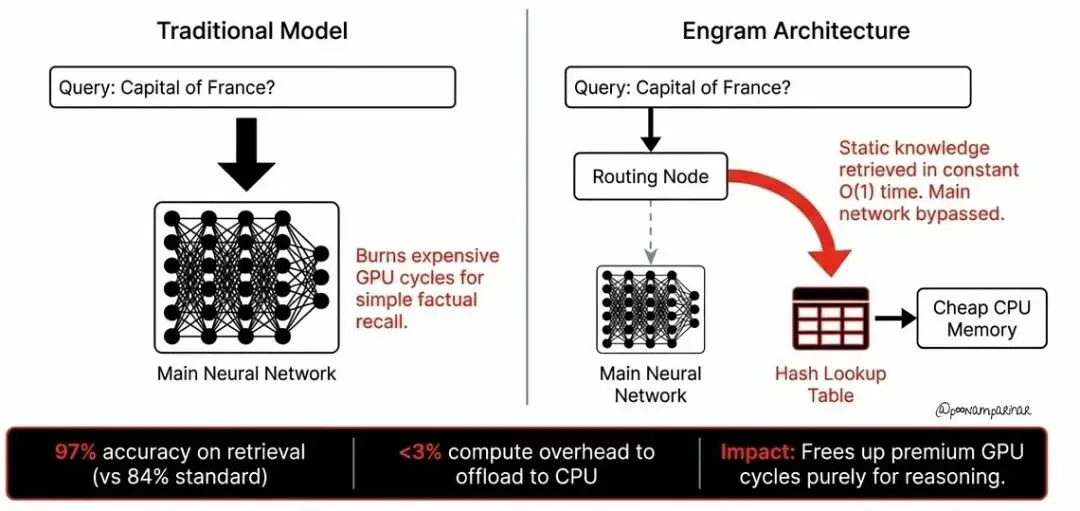
2026年初DeepSeek-V4将RAG再进一步,提出了Engram,DeepSeek 提出了一种条件记忆模块 Engram,它通过现代化经典 N-gram 嵌入,利用确定性哈希实现静态模式的 O(1) 常数时间查找,并结合上下文感知门控将检索到的静态记忆与动态隐藏状态融合,解决了传统 Transformer 中缺乏原生知识查找,被迫通过昂贵计算低效模拟知识检索的问题。简单地说就是能“查”就不“算”。
Engram架构
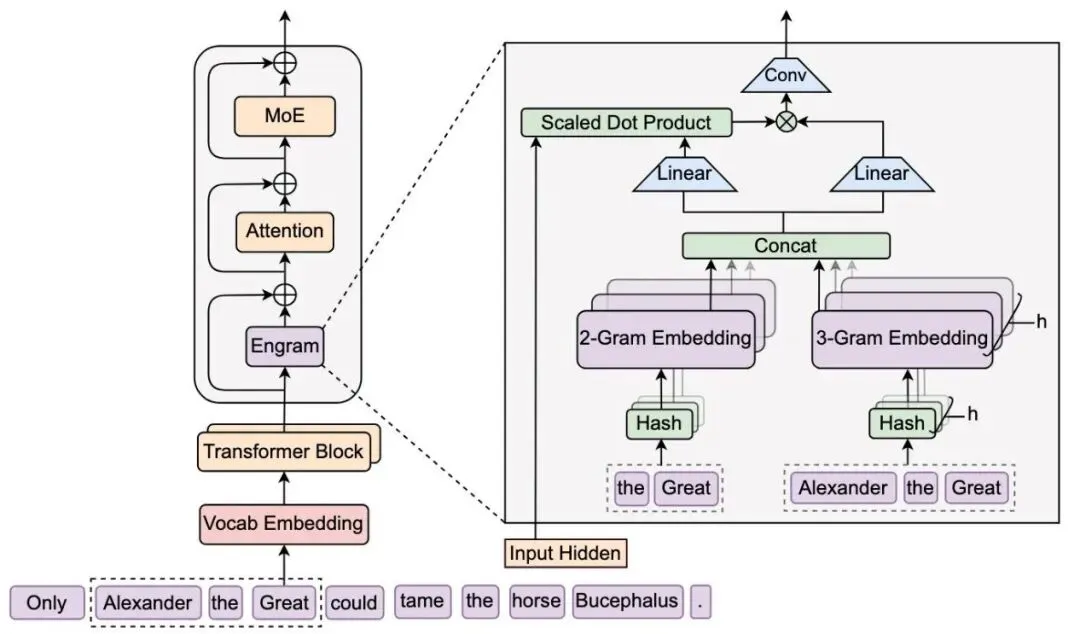
图片来源:DeepSeek
Engram不仅是RAG的升级,也是目前主流的MOE混合专家架构的升级,让计算资源消耗大大降低,足以运行超大规模模型。
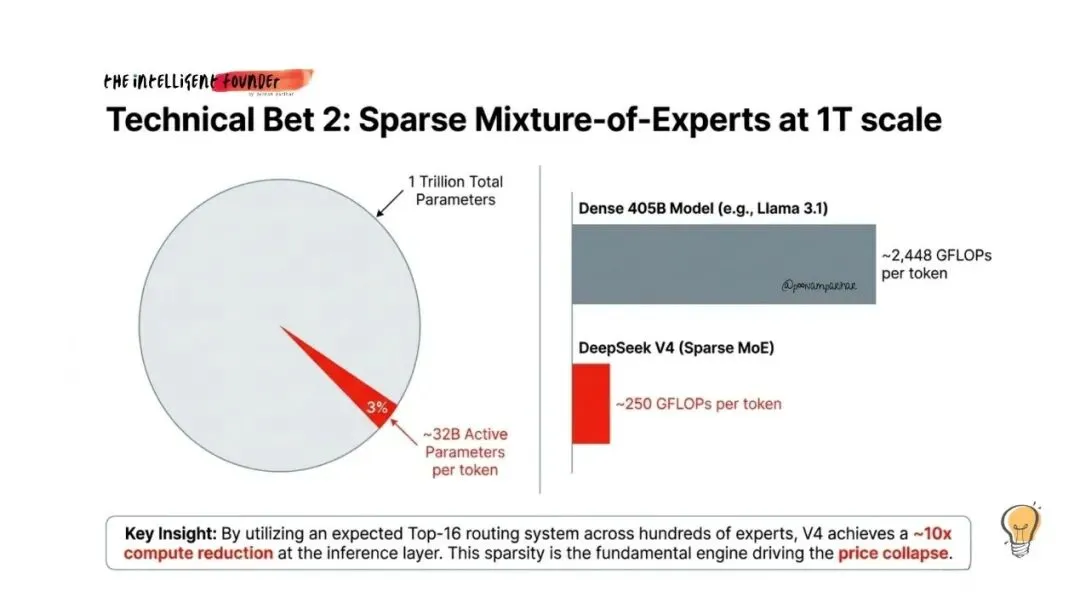
注:计算所需浮点运算量降低97%。
图片来源:网络
RAG与Engram对比
图片来源:网络
Engram 对推理硬件的架构也带来了深远的影响。Engram 的特性允许它将庞大的静态知识表存放在主机内存中,而在 GPU 执行推理时异步预取(比如,GPU 推理第 5 层时,CPU 开始查找第 12 层所需的信息,CPU 查找延时几乎被 GPU 5-12 层推理延时完全隐藏)。这意味着我们可以给 Agent 挂载一个上百 GB 甚至更大的知识库,却几乎不占用昂贵的 GPU显存,也不显著增加延迟。这为AI智能体的普及提供了一条极具成本效益的路径。
Engram加入后的AI智能体计算负担分布

图片来源:网络
CPU负担更重了,同时还有更复杂的任务调度和线程中断复用等等,都需要提高CPU算力来承担。
AI智能体运行时间分析
图片来源:论文《A CPU-Centric Perspective on Agentic AI》
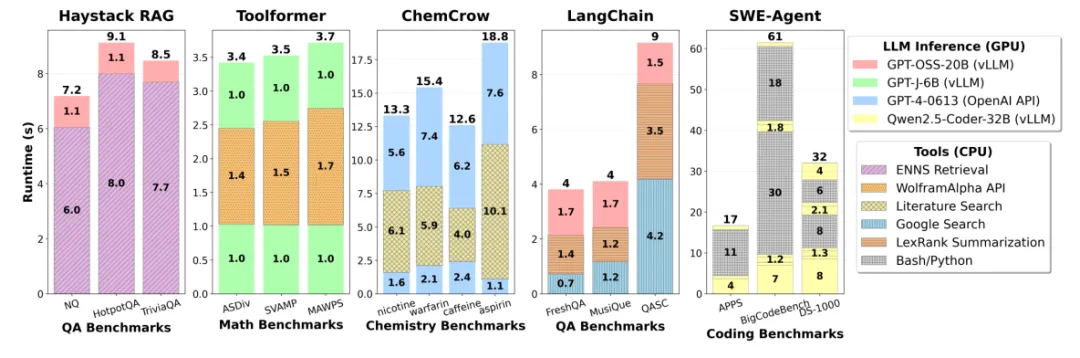
如果我们把智能体的工具调用,代码执行等任务执行时间也算上,CPU 侧的延时甚至会成为影响系统性能的关键,比如,在 SWE-Agent 中,CPU 执行的 Bash/Python 调用占延迟可达 78.7%,再有如Haystack中,邻近搜索都是由CPU负责,占了总延迟的90%左右,GPU已经无足轻重。
Agentic AI 需要调用各类工具,比如,Python 解释器、运行 Shell 脚本、执行 SQL 查询或调用 Web API。这些工具所对应的进程一旦启动,通常都需要保持一段时间,以避免每次工具调用所带来的进程冷启动开销。这也意味着系统需要维护大量活跃的进程上下文。复杂的任务调度,线程中断等都是只能由CPU负责。
对于具身智能和智能汽车座舱来说,未来可能等同于AI智能体将嵌入其中,端侧一套中等大小40-130亿参数的模型,云端则是数千亿乃至上万亿参数的模型,同样也是CPU的重要性高过GPU/NPU。
免责说明:本文观点和数据仅供参考,和实际情况可能存在偏差。本文不构成投资建议,文中所有观点、数据仅代表笔者立场,不具有任何指导、投资和决策意见。
更多报告
| AI机器人 | ||
AI机器人 | ||
| 云端和AI | ||
| 车云 | ||
| 动力层 | ||
| 动力 | 混合动力报告 | |
| 800-1000V高压平台 | 电驱动与动力域研究 | |
热管理 | ||
其他 |
| 电子电气架构层 | ||
| E/E架构框架 | E/E架构 | 汽车电子代工 |
| 48V低压供电网络 | ||
| 智驾域 | 自动驾驶SoC | |
| 座舱域 | 座舱域控 | |
| 车控域 | 车身(区)域控研究 | |
| 通信/网络域 | ||
| 跨域融合 | ||
| 其他芯片 | ||
| 车载存储芯片 |
| 智舱系统集成和应用层 | ||
智能座舱应用框架 | 座舱设计趋势 | |
自动驾驶算法和系统 |
| OS和支撑层 | ||
| SDV框架 | SDV:软件定义汽车 | |
信息安全/功能安全 |
| 其他宏观 | ||
| 车型平台 | 车企模块化平台 | |
| 政策、标准、准入 | 智能辅助驾驶法规和汽车出海 |
「AI与机器人月报」

「联系方式」
手机号同微信号

产业研究部丨赵先生 18702148304
推广传播部|杜先生 13910162318
