一个顶会的诞生得讲点“天时地利人和”。所谓“天时”,是指这个会议所在的研究领域处在上升期,一切都方兴未艾,会不断有研究者进入这个领域进行研究。所谓“地利”,是指所在的研究领域内既有的顶会不足以满足研究者的需求,并且时空环境允许新的会议发展成顶会。所谓“人和”,指的是会议质量需要主办方和投稿人的双重背书:一方面,会议的发起人通常是所在研究领域的领军人物;另一方面,也是最重要的,会议收录的文章,特别是最初几届收录的文章中,需要有质量极高,影响极深远的“大文章”。这三点缺一不可。ICLR的诞生为这套理论提供了一个很有说服力的案例。第一届ICLR于2013年举行,由深度学习领域的两位领军人物Bengio和LeCun牵头发起。在这之前,Hinton等人已经提出了受限玻尔兹曼机等深度神经网络架构,提出了一些有效的深度神经网络学习策略,并且在语音识别领域初步验证了深度神经网络的性能。2012年,AlexNet在ImageNet图像识别比赛中进一步证明了用深度神经网络学习特征比人工设计特征更有效。彼时,学术界对于深度学习的可行性还存在争论,但在一系列证据面前,越来越多的研究者意识到这项技术是有巨大潜力的。在这个大背景下,ICLR会议聚焦以深度学习为核心的表示学习技术研究,可以说是恰逢其时。在2013年,以“学习”为核心的人工智能领域的顶会其实只有两个:ICML和NeurIPS(当时还叫NIPS)。这两个会议比AAAI和IJCAI更聚焦“学习”问题,同时又比AISTATS、UAI、COLT等更小众的会议具有更宽泛的主题。在投稿时间方面,ICML的投稿截止日期是每年的1月底或2月初,NeurIPS的投稿截止日期一般是5月。如果你是那个年代专注于学习技术的研究者,在投完NeurIPS之后,一直到次年初投ICML为止,会有一个长达8个月的投稿“空窗期”。因此,当时有机会举办一个同样聚焦“学习”并且主题具有一定差异度的会议。把它投稿截止日期设置在9月份,可以利用空窗期错开NeurIPS和ICML的投稿。只要这个会议的录取结果能在ICML的投稿截止日期之前发布,就基本不用担心投稿会被ICML和NeurIPS分流,甚至有机会吸引一些被NeurIPS拒绝后做了显著改进的论文。前两届ICLR的录取量不到三位数,但是其中却有两篇重量级的文章。2013年,Auto-Encoding Variational Bayes发表在第一届ICLR会议上。2014年,Adam: A Method for Stochastic Optimization发表在第二届ICLR会议上。前者提出了著名的变分自编码(VAE)框架,是高维数据生成式建模最有效的几条技术路线之一。后者提出了著名的Adam优化器,将动量法和自适应动能纳入统一的优化算法设计框架,已经成为几乎所有大模型训练的标配。VAE目前的引用数超过5万,Adam的引用数更是超过24万。这两篇文章也都获得了ICLR的时间检验奖。可以说,连续两届会议收录这种“大文章”奠定了ICLR的地位,使它成为了当之无愧的AI顶会。在这之后的几届ICLR也都有不少有影响力的工作,例如,2017年收录的Semi-supervised Classification with Graph Convolutional Networks掀起了图神经网络的研究热潮;2021年收录的Score-Based Generative Modeling through Stochastic Differential Equations是扩散生成模型的奠基性工作之一。事实上,ICML和NeurIPS也经历了类似的发展过程,从最初非常小众、精英化的学术会议开始,乘着特定领域的研究浪潮(包括90年代的统计机器学习、21世纪第一个十年的核方法、流形学习、第二个十年的深度学习、第三个十年的大模型技术)逐渐壮大,并在每个发展阶段都收录了最有影响力的论文。只不过ICLR用十年时间走完了ICML和NeurIPS三十年的路。如果按照这套理论,现在想办一个新的AI顶会难度已经非常大了。首先,在“天时”方面,目前主流的大模型技术本质上是深度神经网络与统计学习方法Scaling up之后的产物。从研究的角度,不同于从“人工特征+统计学习”到“深度学习”的范式跃迁,大模型技术是深度学习的自然延伸。它的出现并没有像当年深度学习出现时那样在学术界引起长达数年、势均力敌的争论——绝大多数研究者们几乎在第一时间就接受了这项技术并在此基础之上更新自己的研究工作。因此,研究者们并没有迫切的“另起炉灶”的需求,完全可以在既有的AI顶会上继续发表自己的工作。其次,在“地利”方面,由于顶会论文是“百万漕工衣食所系”,现在三大AI顶会的投稿量都已经过万了,进而导致审稿质量显著下降。虽然各个会议采取了一系列措施来提高审稿质量,但客观上效果很有限。对于一个每年投稿量过万的AI顶会,我认为3-4个月的审稿周期已经接近“品控”的生死线了。如果再增加一个新的AI会议,那一定会有一个现有的顶会和这个会议的截稿日期距离小于2个月,它的审稿周期一定会撞上另一个会议的投稿周期或者Rebuttal周期。因此,这个新会议在体量上要和现有的顶会相当,至少需要从现有的某个顶会中分流50%的投稿,或者催生出相当于一个顶会的新增投稿量,难度可想而知。第三,在“人和”方面,人工智能领域的研究从没有像今天这样热闹,也从没有像今天这样同质化。一方面,在技术层面具有深刻洞察和持续影响力的“大文章”其实已经有好几年没有出现过了(当然,也很可能是我看得少、见识浅薄、有眼无珠balabala);另一方面,arxiv、微信公众号、小红书上每天都会推送大量震惊体论文。结果就是,好文章、好工作不仅客观上存在稀缺性,并且因为信息过载变得愈发难以识别。没有“大文章”的背书,一个会议哪怕收到几万篇投稿也变不成顶会。事实上,大模型技术崛起之后,学术届也有知名学者在组织以大模型技术为核心的会议COLM。投稿量增长挺快,投稿和审稿质量也基本在线。但是,它现阶段的首要目标还是要从ACL、EMNLP等NLP会议中抢到足够的高质量稿源。在它收录到足以影响整个AI领域的“大文章”之前,我对它能否成为新的AI顶会保持谨慎态度。
AI顶会的异化
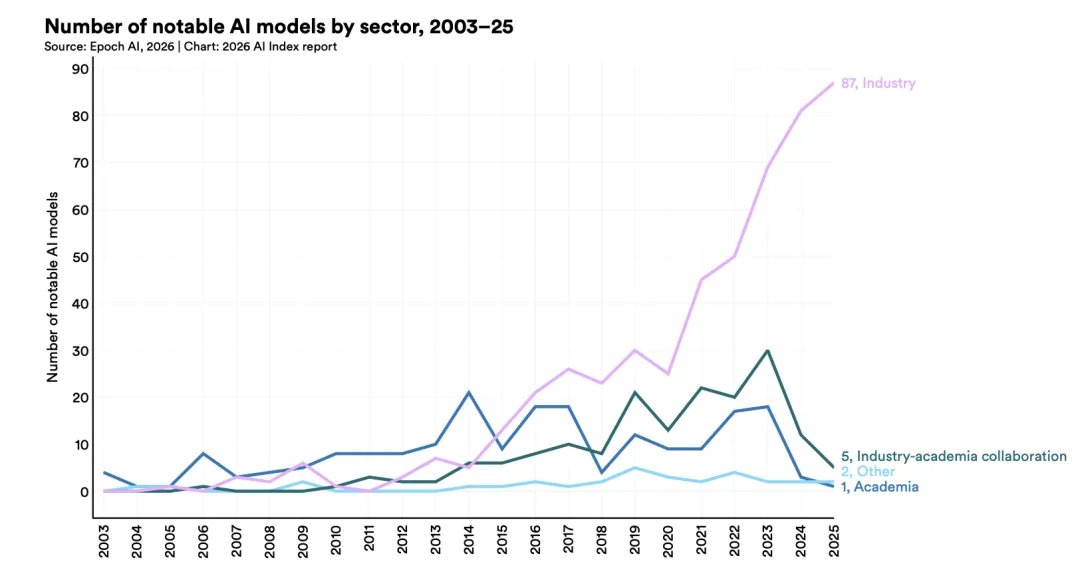
以上分析还仅限于如何创造一个传统意义上的学术顶会。然而,事物是变化的。随着越来越多的人和钱涌入,过去十年里,AI顶会论文和AI顶会本身已经发生了异化。从功能上讲,现在的AI顶会与其说是前沿学术交流会,不如说是“大型招聘会”。2018年参加NeurIPS的时候,我第一次清晰地意识到了这种学术会议氛围的变化。那一年,NeurIPS的赞助商数量超过了100家,参会人数也达到了空前的规模。几乎每天企业展台都非常热闹,中午和晚上还会有企业举办的活动。在这些活动中,传统意义上的学术交流更像是“佐料”,宣传和招聘才是“主菜”。这些企业通过赞助的方式进驻AI顶会现场,宣传自研的技术成果,同时也在现场面向参会人进行招聘。学生通过参加AI顶会获得和企业员工面对面交流的机会,进而有机会获得实习或全职工作的面试邀约。高校教师也可以通过参加AI顶会和企业、猎头甚至投资人建立联系,了解合作机会。相比于常规校招和社招,这些企业在AI顶会上“捞人”的性价比其实是非常高的。如果一个学生能发表顶会论文,至少说明他智力达到平均水平,能在导师的指导下保质保量地完成工作;如果能持续发表多篇顶会论文,已经一定程度上说明他是一个工作能力不错,有吃苦耐劳精神和自驱力的人了;如果发表的顶会论文水平也很不错(比如被选为Spotlight、Oral甚至Best Paper),那很可能意味着他不仅吃苦耐劳而且具有不错的科研品味和突出的科研能力。这些企业只需要交一笔赞助费,就可以借助顶会这个平台,在短时间内接触到大量素质过硬的人才。由于这些头部企业的示范效应,行业内的其他企业也开始用顶会作为简历筛选和人才定价的重要依据。相应地,对于学生而言,顶会论文就成了他们在求职市场上的“硬通货”:每一篇顶会论文都是他们参加“招聘会”的门票,并在最终求职季变成他们通过简历筛选、拿到企业Offer的前置条件以及后续薪资博弈的筹码。相比学生和企业的关系,高校教师和企业的关系通常更复杂。但是在AI领域,顶会论文目前仍然是两者关系的重要纽带。如果一名高校教师能常年发表顶会论文,说明他和他的课题组保持着较高的业务水平。如果他的论文还被广泛引用,那就已经是有一定曝光量和影响力的学者了。企业会更乐意和这种教师合作横向项目,其背后的目的也包括宣传和招聘。高校科研成果距离转化成企业产品通常还有一段路。因此,企业一般也并不指望通过一个为期一年的横向项目就能彻底搞定某个方向的产品研发——很多时间,一个横向项目如果能形成一个产品开发的起点就已经非常好了。与此同时,高校教师让学生参与项目,去企业实习,可以获得前沿研究所需的算力和数据资源,产出相应的研究成果。项目执行过程中产生的顶会论文会成为企业宣传材料的一部分。同时,企业可以在学生实习期间,用较低的成本对学生进行较为全面的考察,并通过向满意的人才发放Return Offer的形式在招聘市场上抢占先手。上述两种关系中,顶会论文数量都是重要指标。因此,也就不难理解为什么这些年人工智能领域的论文数量会呈现爆发式增长。它反映的更多是行业的扩张和市场的繁荣,而不是传统意义上的学术思想进步。这种功能的转变也体现在AI顶会前沿性的消退上——现在的顶会其实没有那么“顶”了。特别是在大模型为核心的研究方向上,遵循Scaling Law扩大模型、数据和算力规模仍然是提升模型性能最有效的手段。在这个方向上,高校已经很难脱离企业(或者任何坐拥算力和数据的机构)独立做出有影响力的成果了。并且,国内外大模型的头部企业已经逐步地不再以顶会论文的形式发布他们的研究成果了。他们的研究工作开始和高校解耦,甚至超越了高校科研水平。上图来自斯坦福2026年度AI指数报告(https://hai.stanford.edu/assets/files/ai_index_report_2026.pdf),它显示企业界2025年发布绝大多数的大模型。很多时候,高校科研人员需要根据他们挂在arxiv上的文章了解他们的一些研究动向,通过试用每个季度他们发布的新模型来猜测他们上了什么科技狠活。在这样的大背景下,AI顶会本身转型成“大型招聘会”可以说是顺应时代发展的必然趋势:既然学术成果上已经没有那么前沿了,那么至少AI顶会作为一个平台,得把“促进交流”这项服务做好。从这个角度来思考,假如未来某个AI顶会因为各种内部或外部因素让出生态位,我们能办一个新的顶会取代它么?按照前面的分析,在缺少前沿技术争论也缺少重量级文章加持的情况下,要创造一个传统意义上的学术顶会是非常困难的。但是,如果要办成一个以高水平论文为门票的“大型招聘会”,却不是不可能。这里我开个脑洞:如果有某个AI会议,审稿人是国内外各大企业的研究员和高校教师为主体,投稿的论文必须是以学生为第一作者、高校教师为通讯作者的论文。论文按照三盲原则进行严格审理,并且额外追加两条要求:(1)确保每篇文章的审稿人至少有一名企业界的研究人员;(2)每篇中稿的论文在审理后会公开审稿人所在的机构信息。如果一篇文章被录用为Poster,论文第一作者将被视为通过了审稿人所在企业的初试,自动获得“二面”的机会;如果一篇文章被录用为Oral,论文第一作者将获得直接进入审稿人所在企业“三面”的机会;如果一篇文章被选为Best paper,那么论文第一作者将获得审稿人所在企业“终面”的机会,如果通过面试可以获得企业的Offer,并且Offer有效期1年。对于高校教师,如果他有高质量论文被录用并被评为Oral或者Best paper,或者他连续几年都有论文被这个会议收录,那么他可以获得审稿人所在企业的一个横向项目,围绕投稿相关的问题定向开展研究工作。对于审稿人,企业可以将审稿工作也纳入研究人员的绩效,用这个审稿人给出“录取”决定的论文总数除以这些论文的作者最终接受企业Offer的人数,低于某个阈值企业就给审稿人发奖金。在当前的高校工作环境和市场就业压力下,我觉得会有一部分老师和学生愿意把高质量工作投到这个会议上,审稿人也会看在钱的份上更认真负责一些。这样一个会议,靠CCF(或者其他任何一个学会)来牵头是干不好的。究其原因,在于这些学会筹办的会议具有浓重的行会色彩,无论是组织会议还是参与会议,最终最大的收益会留在这些学会内部,而不是普遍地、广泛地让每个投稿人都能从中获得具有确定性的收益。因此,这些会议很难吸引到真正高质量的稿源。相比之下,阿里、字节、DeepSeek、月之暗面等AI头部企业可能会更有动力组织这样的会议。这些企业每年花在人才招聘上的钱已经是天文数字,但是效果上不一定好。HR往往不具备过硬的专业知识,通过数顶会论文数量来筛简历,特别是头部人才的简历,难免有“错杀”情况。如果能让多个专业人士通过一个会议,用比较长的时间认真地审阅潜在申请者的一项工作,有可能可以降低这种风险。另外,对于头部人才,各家企业的招聘竞争已经白热化,薪酬总包越给越大。这背后其实是一种FOMO(Fear of missing out)焦虑:这个人是不是值这么多钱不是最重要的,最重要的是不能让他去别的公司。如果有一个相对透明的会议,让各家企业知道潜在申请者的工作受到了多少家企业的认可,议价的时候也许能够更有的放矢。当然,这种以企业为主导的AI顶会显然会是一种资本异化后的产物,也会存在很多问题,但这很可能是现阶段创造一个AI“顶会”的唯一可行路径。归根到底,AI顶会的异化是因为以大模型为代表的资本密集型技术使得人工智能的研究高地逐渐从高校转向了企业。在这条赛道上,许多现象和问题只有在你的数据和算力达到一定规模之后才会出现。如果你看不到这些现象和问题,针对这些现象和问题的研究也就无从开展。也正因为如此,这几年从事人工智能研究的高校教师都在积极开展和企业、新型研究机构的合作,有不少甚至亲自下场开公司、办企业。但毕竟不是所有的高校教师都有机会、有意愿、有能力开公司。在这种情况下,一名从事人工智能研究的高校教师最主要的成果和对社会最大的贡献,其实不是他所研究的所谓前沿技术,更不是他发表的顶会论文,而是他培养的那些能发表顶会论文的学生。高校教师向学生传授研究方法、思维方式甚至研究品味,培养效果以顶会论文为载体,帮助学生获得就业市场上的“硬通货”。这些学生进入企业工作之后也许会从事和在学校完全不同的科研工作,但是他从导师那里获得的方法论,甚至价值观,会对他产生长期的影响。因此,在人工智能方向上,高校教师每年获得的研究经费,很大一部分可以认为是人才培养费。
 夜雨聆风
夜雨聆风