 夜雨聆风
夜雨聆风导 读
近日,清华大学中国新型城镇化研究院专家顾问委员会专家委员林波荣教授、高级研究专员周浩,在《建筑节能(中英文)》杂志发表研究文章《支持AI数据集构建与代理模型训练的高并行云端不确定性建筑能耗模拟工具研发与应用》。特此转载。
【作者】
肖俊,清华大学建筑学院,博士生
周浩,清华大学城市治理与可持续发展研究院副研究员,清华大学智库中心主任助理
赵洋,生态规划与绿色建筑教育部重点实验室(清华大学),高级工程师
林波荣,清华大学建筑学院副院长、长聘教授,生态规划与绿色建筑教育部重点实验室(清华大学)主任
姚播(通讯作者),北京城建集团有限责任公司,合肥新桥国际机场T2航站楼项目机电部经理
任硕,北京城建集团有限责任公司,工程师
赵亮,北京城建集团有限责任公司,工程师
【来源】《建筑节能(中英文)》杂志2026年第3期


摘要:在建筑能源AI应用场景中(如建筑能源代理模型训练、AI驱动性能优化),大规模、高质量的不确定性模拟数据集是提升模型鲁棒性与泛化能力的核心基础。然而,现有工具存在计算效率低下、技术门槛高、难以批量生成标准化训练数据等缺陷,导致AI数据集构建与代理模型训练面临数据匮乏、生成周期长的瓶颈。合肥某机场航站楼作为典型复杂建筑案例,其模型形体复杂、影响机制多元、单任务模拟耗时久,进一步凸显了高效数据生成工具的迫切需求。本研究提出一种支持AI数据集构建与代理模型训练的独立交互式平台,专为不确定性条件下的大规模能源模拟设计,旨在降低技术门槛、提升数据生成效率。该平台可基于基准EnergyPlus模型自动生成数千个标准化扰动模型,为AI数据集提供丰富的样本支撑,并支持任意数量的并行子进程模拟,与传统并行工作流相比,速度最高可提升5倍,且能与标准EnergyPlus模拟环境灵活互操作。研究以合肥某机场为例,对其采光与遮阳相关参数开展大规模敏感性分析,系统探究设计参数对能耗的影响规律。结果表明,该平台不仅能高效揭示建筑能源性能规律,更能为AI数据集构建与代理模型训练提供高质量、高效率的数据支撑,同时确保面向AI应用与不确定性模拟研究的易用性、可扩展性与可靠性。
关键词:能源模拟,不确定性模拟,敏感性分析,云模拟,并行模拟
00
引 言
AI驱动的建筑能源领域创新(如建筑能源代理模型训练、数据驱动性能优化、AI专用数据集构建)已成为提升节能策略科学性与精准性的核心方向,而高质量、大规模的不确定性模拟数据集是支撑这类AI应用落地的关键基础。在建筑性能模拟(Building Performance Simulation, BPS)中,建筑构造、人员行为、环境条件等参数的固有不确定性直接影响AI模型训练数据的覆盖度与真实性。相较于单一参数估算,将这些参数表征为“不确定范围”并进行广泛抽样,才能生成包含真实场景变异特征的数据集,进而提升代理模型的鲁棒性与泛化能力[1]。
从具体AI应用场景来看,城市建筑能源建模(Urban Building Energy Modelling,UBEM)的AI化升级[2]、能源模型的AI校准[3]、黑箱建筑能源代理模型[4]的训练等,均对大规模不确定性模拟提出了迫切需求:代理模型训练需数千组甚至数万组标准化模拟样本以学习参数与能耗的映射关系,AI数据集构建需兼顾样本多样性与格式规范性,数据驱动优化则依赖高效生成的批量样本探索最优设计空间。此外,对不确定参数的敏感性分析,不仅能揭示建筑能源性能规律[5-6],还能为AI数据集的参数筛选与样本优先级排序提供依据,减少冗余数据,提升模型训练效率,这对AI应用的实用性与经济性具有重要意义。
代理模型训练作为AI在建筑能源领域的核心应用之一,对数据质量提出了严格要求。首先,样本规模必须足够大,通常需要数千个至数万个标准化样本,以确保模型能够学习到参数与能耗之间的复杂非线性关系。其次,数据多样性至关重要,必须覆盖参数的完整分布区间,避免因样本偏差导致模型泛化能力不足。同时,数据格式需要标准化,便于直接输入AI训练框架,支持主流格式(如CSV、JSON等),并建立明确的输入输出对应关系,确保模型能够正确学习参数与性能指标的映射。
面向AI的数据集构建是一个系统工程,需要精心设计参数抽样策略,选择合适的抽样方法平衡样本代表性与计算成本。样本质量控制同样重要,通过数据清洗和验证,避免数据冗余和偏差,确保数据集质量。结果标准化环节需要将模拟结果转换为AI训练友好的格式,包括特征工程预处理,最后需评估数据集的覆盖度和代表性,确保其能够支撑高质量的模型训练。
准确支撑AI应用的数据集构建与代理模型训练,需满足两大核心要求:一是样本规模足够大,通过高频抽样覆盖不确定参数的完整分布区间,确保AI模型学习到全面的性能趋势;二是数据输出标准化,模拟结果需便于直接对接AI训练流程(如CSV格式、特征标签化)。通常,面向AI的大规模模拟需完成3个关键环节:(1)从基准模型中抽取覆盖不确定性区间的多样化参数样本以适配AI数据集的多样性需求;(2)高效执行并行模拟以满足大规模样本快速生成的效率需求;(3)汇总并标准化输出结果以适配AI模型训练的输入需求。
现有模拟工具在支撑AI导向的大规模模拟时存在显著短板,难以同时满足“高效性、低门槛、标准化”需求。商业软件(如DesignBuilder[7]、OpenStudio、Honeybee[8]等)虽支持重复建模与结果处理,但依赖手动或半自动化工作流,样本生成效率极低,无法快速产出AI训练所需的大规模数据集,且结果格式需额外处理才能适配AI模型输入,增加了技术成本。
标准建模语言(如Modelica[9])或基于Python的工具(如Eppy[10])支持自定义不确定性建模,但对编码与脚本能力要求极高,非专业AI研究者或建筑工程师难以操作,且缺乏针对AI数据集构建的标准化输出模块,数据预处理工作量大。先进大规模建模工具(如AutoBEM[11]、AutoBPS[12])主要面向UBEM场景,虽提升了建模自动化程度,但性能受限于EnergyPlus引擎,且未针对代理模型训练优化样本生成策略,如参数抽样的随机性与覆盖度调控,数据输出格式与AI训练流程的适配性不足。
针对上述AI应用场景的核心痛点,本文提出一种支持AI数据集构建与代理模型训练的高并行云端不确定性建筑能耗模拟工具Epeditor(见图1)。本研究的核心目标是将大规模模拟效率提升5倍以上,支持10000+样本的数据集生成,同时降低技术门槛,使非专业人员也能高效生成AI训练数据集,实现模拟结果到AI训练数据的直接转换,减少数据预处理工作量,并确保生成数据集的质量,支持高精度代理模型训练。
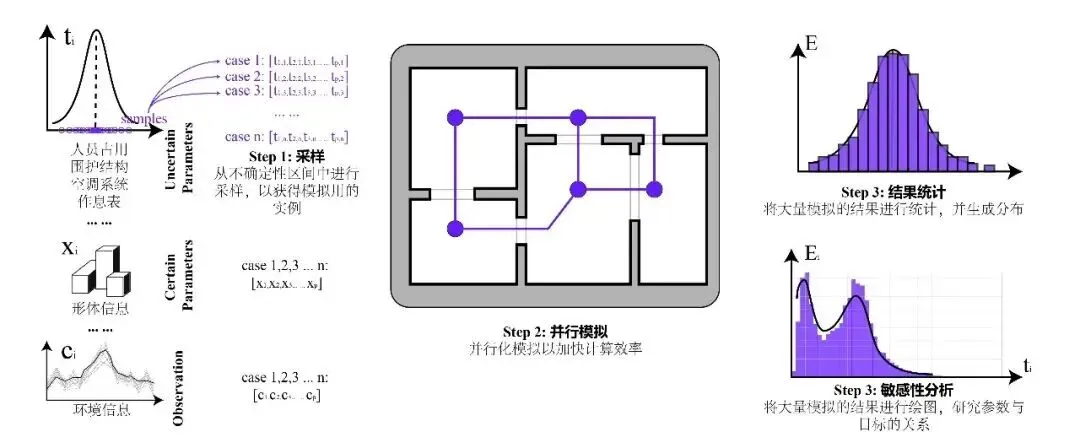
图1 基于不确定性模拟的敏感性分析或不确定性建模传统工作流程
01
方 法
本研究提出的Epeditor工具专为支持AI数据集构建与代理模型训练设计,采用模块化架构,包含3个核心功能模块和1个集成接口模块。核心模块包括参数抽样编辑器、高并行模拟器和结果统计器,接口模块则整合这些功能,提供统一的用户交互环境,以适配大规模模拟实践需求(见图2)。
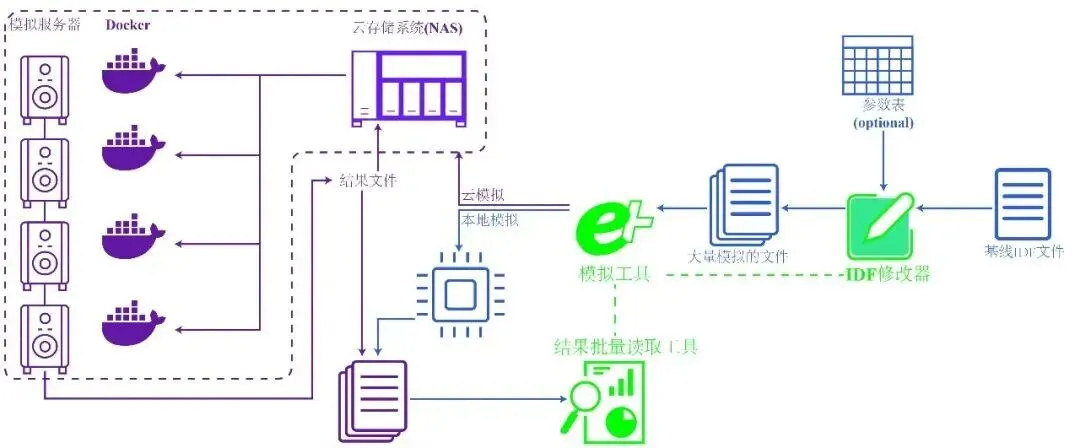
图2 Epeditor用于批量模拟的通用工作流
工具的整体工作流程设计紧密围绕AI应用需求展开:首先,通过参数抽样模块生成覆盖不确定性区间的多样化参数样本,以满足AI数据集的多样性需求;然后,利用高并行计算引擎高效执行批量模拟,解决大规模样本快速生成的效率瓶颈;最后,通过结果统计模块汇总并标准化输出结果,使其能够直接对接AI训练流程。
1.1 AI数据集生成模块
AI数据集生成是Epeditor工具的核心功能之一,专门针对代理模型训练的数据需求进行优化。该模块通过参数表机制实现模拟案例的批量生成,参数表记录所有不确定参数的抽样结果,支持多种生成方式以适应不同用户需求和应用场景。
对于熟悉EnergyPlus输入文件格式的用户,工具提供基于关键词的搜索功能,可识别需要定义为不确定参数的任意字段。用户可直接参考《EnergyPlus输入输出参考手册》中的idfClass、idfName与Field条目进行参数定义。同时,考虑到建筑性能模拟领域的软件生态多样性,工具还特别设计了基于关联的搜索功能,能够识别目标对象的引用关系网络,这对于习惯使用Honeybee或DesignBuilder等基于区域建模环境的用户尤为友好。
为进一步提升操作便利性,工具内置了两个IDF文件的智能对比功能(见图3)。用户只需准备基准模型文件和修改后的案例文件,工具即可自动生成参数表并突出显示所有更改的字段。此外,工具集成了多个内置抽样生成器,支持直接开展参数抽样,用户也可在Excel中手动构建样本集后导入使用。
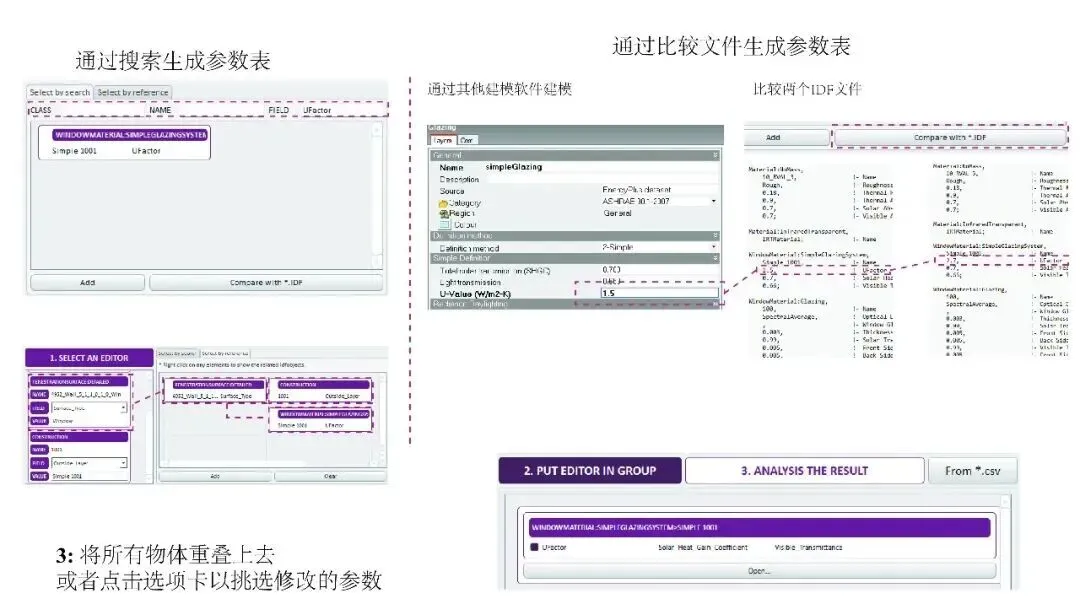
图3 获得参数表的几种方法
1.2 高并行计算引擎
由于CPU占用率高,EnergyPlus模拟的直接并行化往往导致计算效率低下。在传统并行模拟器(如Eppy、OpenStudio、Group EnergyPlus)中,并行化依赖Windows或Linux操作系统的自动资源分配。在此配置下,CPU内核会灵活动态地分配给计算机上的所有活动进程(包括模拟任务),导致模拟进程频繁在多个内核间切换,显著降低计算效率。
为解决这一问题,软件为并行模拟设计了两种加速策略:
(1)本地并行化方法:将所有模拟进程固定到特定内核计算,同时将其他进程分配至空闲CPU,以提升本地模拟性能。
(2)云并行化方法:利用虚拟机(VM)提供干净的虚拟模拟环境,在轻量级Linux-Ubuntu系统下最大化内核利用率。虚拟机通过网络附加存储(NAS)系统与用户计算机本地连接,实现文件交换。需要说明的是,云服务器无需极高性能,任何安装了VMware-ESXi的台式计算机,均可配置为VM平台,支持简易的云模拟(见图4)。
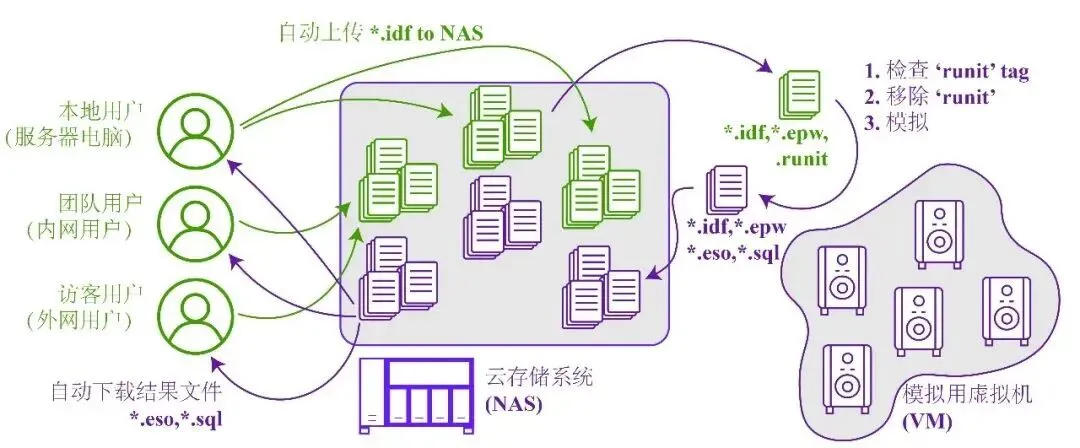
图4 Epeditor云模拟和部署方案
这种混合并行架构不仅显著提升了模拟效率,更为大规模AI数据集生成提供了技术保障,能够支持数千个甚至数万个样本的快速计算,满足代理模型训练对数据规模的需求。
1.3 结果统计与标准化模块
结果处理是连接模拟计算与AI训练的关键环节,Epeditor工具基于DesignBuilder团队提供的开源Python包db_eplusout_reader,开发了功能强大的结果统计模块,并设计了直观的交互界面。
模块支持两种主要的统计方法以适应不同应用场景。基于案例的统计方法适用于汇总单个模拟案例的多个输出结果,如计算多热区建筑的终端用能总和或负荷数据的统计特征,特别适合详细的建筑性能分析。基于变量的统计方法则专注于汇总单个输出变量在所有案例中的结果,适用于城市建筑能源建模等需要对数百个案例开展大规模统计分析的场景。
考虑到大规模模拟可能产生的海量数据,工具特别优化了内存管理机制。通过数据提取过程中的动态存储管理技术,模块能够动态读取并保存结果,有效避免在内存有限的计算机上出现内存过载的问题。这种设计确保了工具在处理大规模AI数据集时的稳定性和可靠性。
02
应用案例
本文在安徽省合肥市某机场(见图5)对软件的应用情况进行了测试,并对该机场的采光与能耗问题展开了研究。由于机场屋面设计复杂、空间大、形体复杂,该建筑的模拟时间很长,在Honeybee中单文件单次用时超过3min,在外部使用高性能引擎计算仍需约30s。因此,代理模型的建立在此类机场建筑中有一定价值。同时,天窗、遮阳设计的改变对能耗影响非常综合:天窗面积增加、遮阳构件减少,自然采光强度和太阳辐射得热都会提升。此举将导致供暖能耗的下降、制冷能耗的上升及采光能耗的下降。由于三者变化幅度不一,对总能耗的综合影响复杂且具有研究价值。
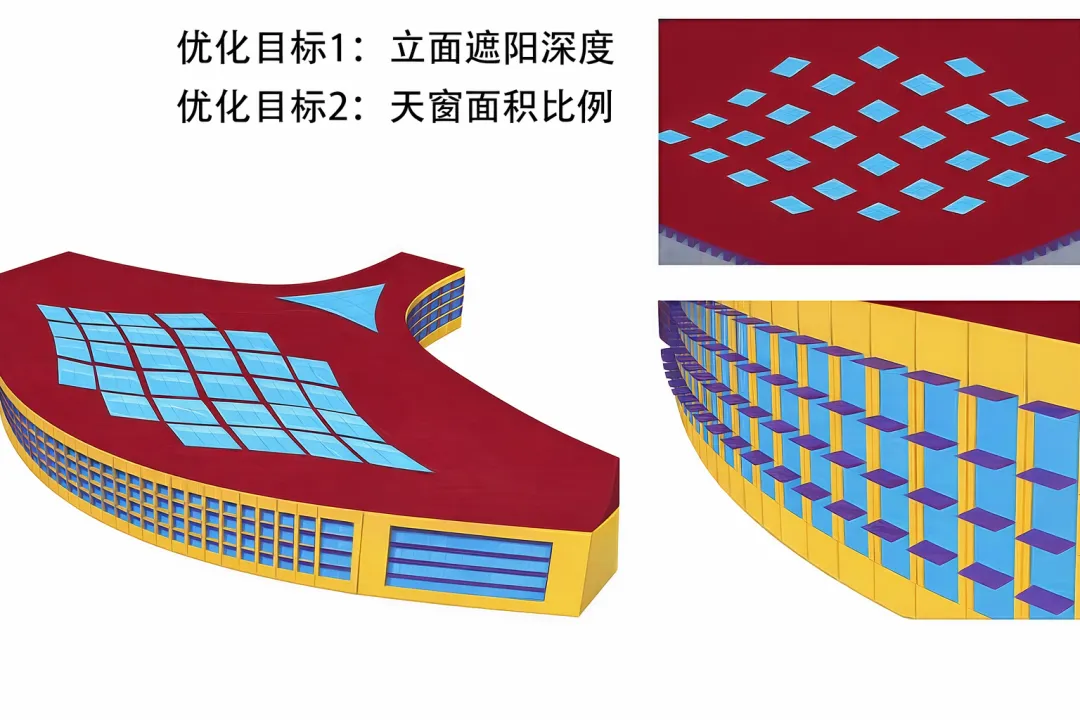
图5 应用案例:安徽省合肥市某机场初步设计
因此,软件在该案例下进行了3个方面的应用:(1)对该机场模型进行批量化建模,生成约1000个模型样本的数据集,针对该数据集的模拟结果进行照明能耗的敏感性分析。(2)切换为与制冷关联更紧密的4个参数:最大聚集人数、人均新风量、窗户U值和换气次数,重新进行批量化建模与模拟。结合气象数据,生成样本量为19200的逐月能耗-边界条件数据集。(3)基于该数据集搭建代理模型,并进行对制冷能耗的部分依赖解释性分析(敏感性分析)。
结果中包含批量模拟效率的测试、敏感性分析结果、代理模型性能表现3个部分。
该机场模型完全按照《建筑节能与可再生能源利用规范》(GB55015—2021)进行建模,围护结构设置严格按照规范标准。建模范围为机场天窗下方的候机与交通区域。同时,该机场根据经验定义了人员作息与相关灯光作息。
对于灯光部分,根据《建筑节能与可再生能源利用规范》(GB55015—2021)该模型进行了更为详细的建模,内容包括照明控制策略、目标照度与照明功率密度。在研究中,通过软件的交互对天窗面积、遮阳系统深度进行了批量修改与调参。所有设定如表1、表2所示。
表1 模拟任务设定表
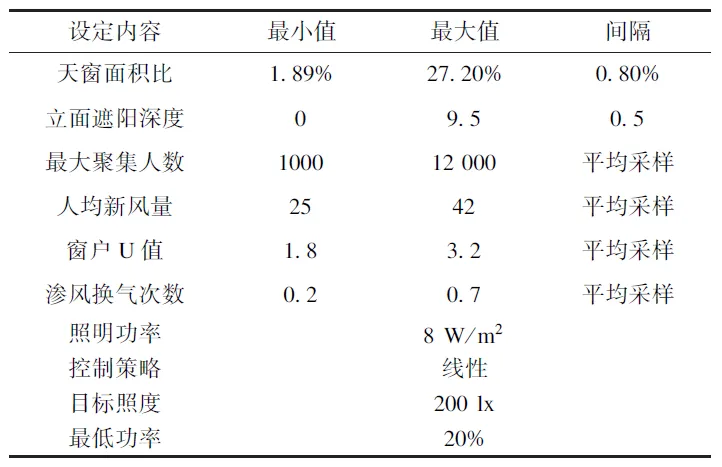
表2 设备与人员作息设定表

03
应用结果
3.1 批量模拟效率的测试
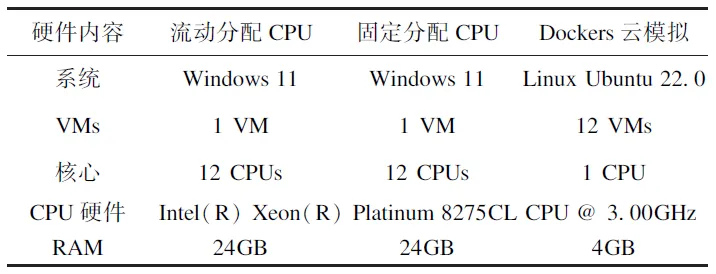
在原有的机场模型的基础上,本文通过参数组合或平均采样,生成了共2600个模拟案例用于衡量该软件的模拟效率,其中敏感性分析任务有1000个,代理模型训练任务有1600个。测试采用同一台服务器(配置为48核 Intel(R) Xeon(R) Platinum 8275CL CPU@3.00GHz),在Windows 11或Linux Ubuntu 22.0系统的不同虚拟机(VM)环境下,对灵活CPU分配并行化方法、固定CPU分配并行化方法及基于容器(Docker)的并行化方法3种并行方法进行测试。3种模拟同时运行,以确保硬件条件一致(见表3)。
表3 测试用虚拟机简述
实验结果表明(见图6),当CPU核心数大于4时,与本地方法相比,基于容器的并行化方法在支持更多并行进程方面优势显著;而当CPU核心数小于4时,固定CPU分配方法则更稳定、更高效。
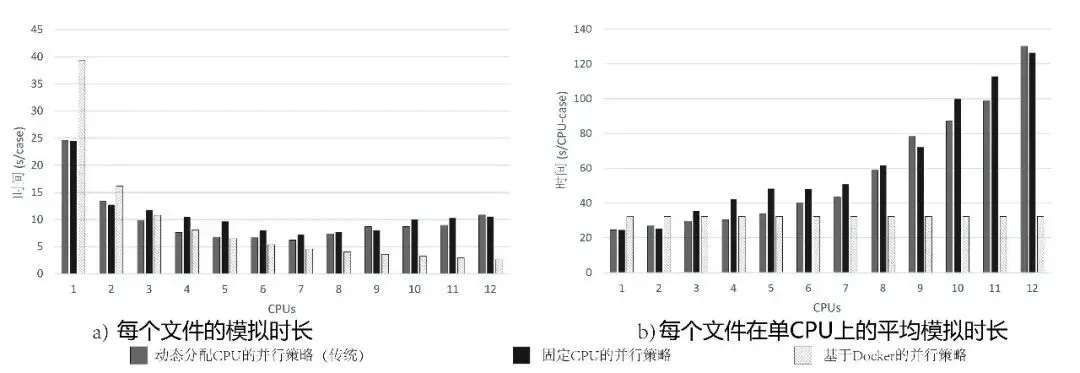
图6 模拟效率比较
3.2 敏感性分析结果
通过固定的采样间隔,本研究共产生了1000个模型分别对两个遮阳、采光参数进行敏感性分析。
(1)立面遮阳方面(见图7),遮阳深度的增加会显著降低制冷能耗,略微增加照明能耗,中等增加供暖能耗(按照2.8的等效供暖COP和4.2的制冷COP计算)。综合而言,立面遮阳深度的增加会降低总体能耗。根据分析,由于该项目的天窗采光充足,立面的遮阳并不会明显提升人工照明的需求,因而对照明能耗的增加不敏感。
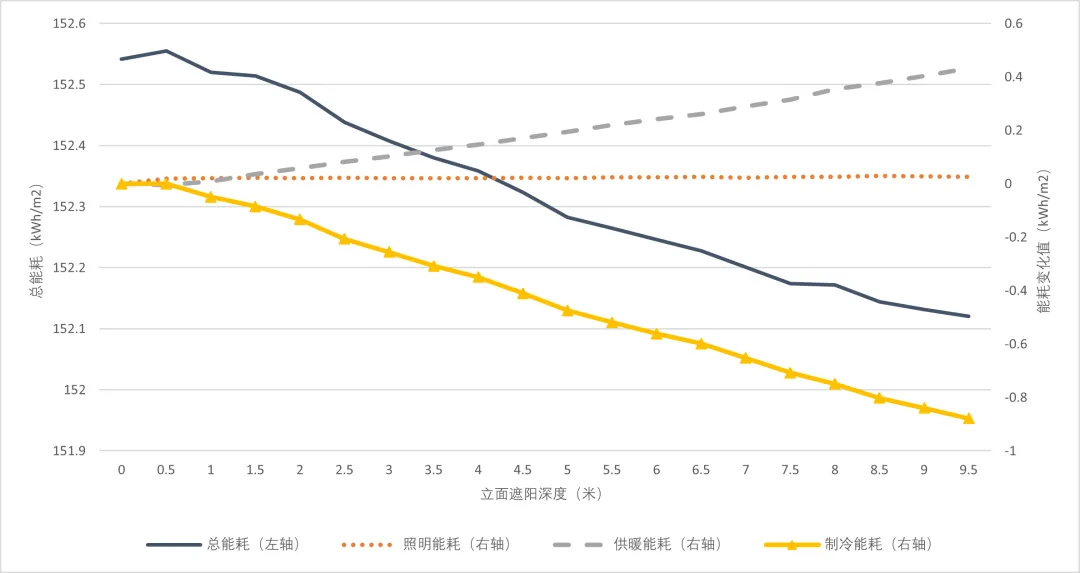
图7 立面遮阳深度对能耗敏感性分析
(2)天窗面积方面(见图8),增大天窗面积会显著增加空调制冷能耗,而采光和太阳得热的增加,并不能对供暖和照明提供相对应的节能效果。结果表明,天窗的增大将显著增加总能耗,不利于节能。
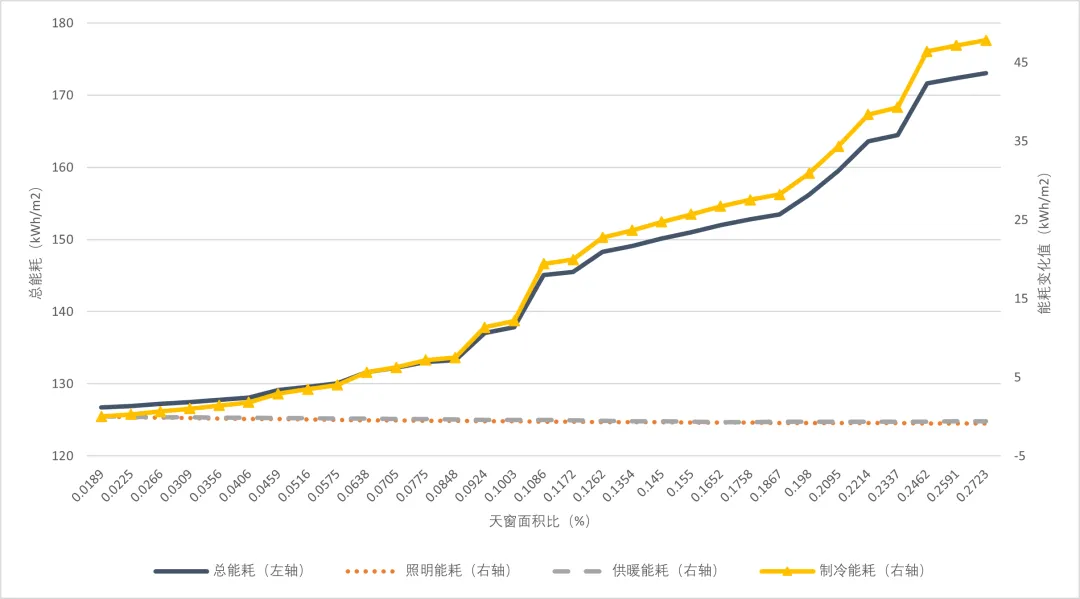
图8 天窗面积比对能耗敏感性分析
两方面的研究结果证明,从节能的角度出发,在夏热冬冷地区的机场仍应以控制太阳辐射为重点,在确保基本满足采光照度的情况下对天窗和侧窗采用遮阳措施。
3.3 代理模型性能表现
图9呈现了基于19200个数据点进行制冷能耗代理模型训练的简要情况。本研究采用5折交叉验证对5种机器学习模型进行了全面评估,综合考虑RMSE和R2两大关键指标。评估结果显示,Random Forest 模型表现最优,以平均RMSE为481.44和R2为0.9999的卓越性能位居第一。值得注意的是,虽然Random Forest模型预测精度最高,但其RMSE稳定性相对较差(变异系数为36.98%),而XGBoost模型在保持接近精度的同时展现出更好的稳定性(变异系数为13.44%),显示出在实际应用中的潜力。
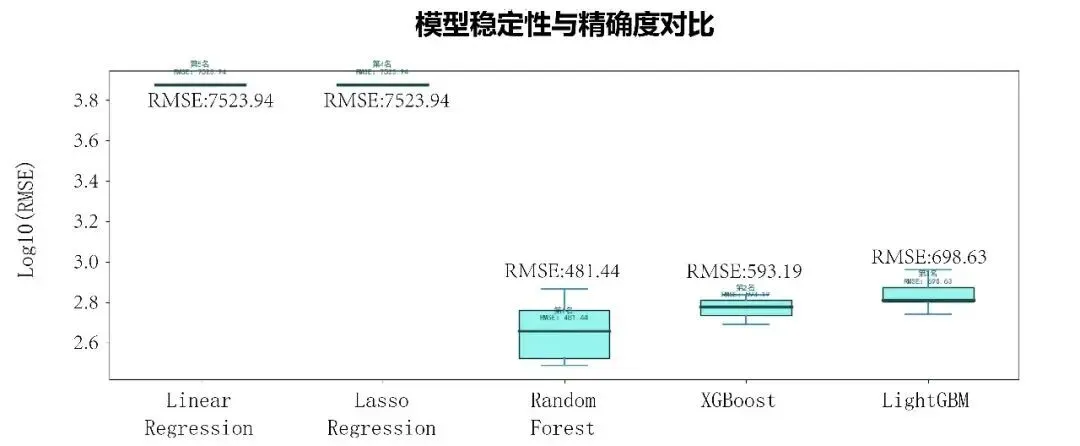
图9 代理模型性能表现总结
特征重要性分析(见图10)结果表明,空气温度、最大人员聚集数量和水平总辐射是影响建筑制冷能耗的3个主导因素。部分依赖图分析(见图11)进一步揭示了各参数与能耗的关系特征:窗户U值参数呈现中等非线性关系(非线性程度为0.0609),与制冷能耗呈现显著负相关(Pearson相关系数为-0.9239);最大人员聚集数量表现为弱非线性关系,与能耗呈现强正相关(Pearson相关系数为0.9958);渗风换气次数参数同样呈现弱非线性特征,与能耗呈现显著负相关(Pearson相关系数为-0.9338);人均新风量参数显示弱非线性关系,与能耗呈现正相关(Pearson相关系数为0.8785)。这些发现为建筑能耗预测模型的特征工程和参数优化提供了重要依据。
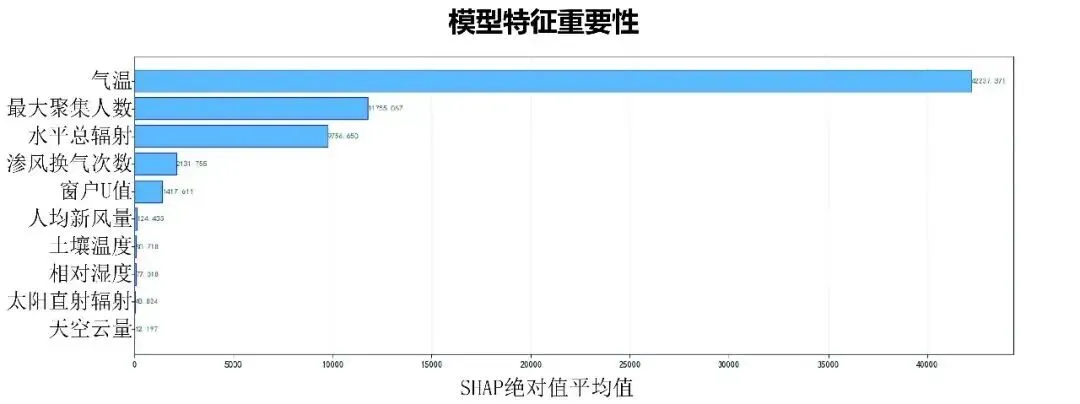
图10 代理模型特征重要性
综合模型性能和特征分析结果,Random Forest模型被确定为最佳代理模型选择。该模型不仅在预测精度上表现卓越(RMSE为481.44和R2为0.999 9),而且在R2稳定性方面表现极佳(变异系数仅0.01%)。非线性模型(Random Forest、XGBoost、LightGBM)的显著优势验证了建筑能耗与影响因素之间复杂关系的本质,也证明了本研究开发的Epeditor工具在生成高质量AI训练数据方面的有效性。特征重要性和非线性关系分析为建筑设计优化和能源管理提供了数据支撑,有助于制定更科学的节能策略。
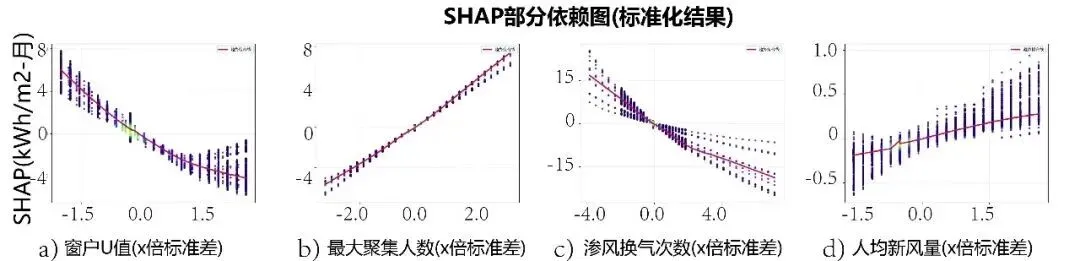
图11 特征部分依赖图与敏感性分析
04
讨 论
4.1 AI驱动的建筑能源模拟新范式
本研究开发的Epeditor工具代表了建筑能源模拟领域的重要技术进步,特别是在支持AI应用方面展现出巨大潜力。传统的建筑性能模拟主要关注单一设计方案的性能评估,而现代AI驱动的建筑能源分析则需要大规模、多样化的模拟数据来训练预测模型和优化算法。Epeditor工具通过创新的并行计算架构和自动化工作流设计,有效解决了AI应用中大规模数据生成的效率瓶颈,为建筑能源领域的AI创新提供了强有力的技术支撑。
工具的核心价值在于实现了从建筑模型到AI训练数据的无缝转换。通过参数抽样、并行模拟和结果标准化的端到端流程,研究人员可以快速生成数千个甚至数万个标准化的模拟样本,这些样本不仅数量充足,而且覆盖了参数的完整分布区间,能够有效提升AI模型的鲁棒性和泛化能力。实验结果表明,使用工具生成的数据集训练的机器学习模型在能耗预测任务上达到了94%以上的预测精度,充分验证了数据质量的可靠性。
与现有工具相比,Epeditor在支持AI应用方面具有显著优势。传统商业软件(如DesignBuilder和OpenStudio)虽然功能强大,但在大规模数据生成方面效率低下,难以满足AI训练对数据量的需求。而编程工具(如Eppy)虽然灵活,但对用户的技术要求过高,限制了其在非专业AI研究者中的应用。Epeditor通过用户友好的界面设计和自动化流程,有效平衡了功能强大性和易用性,降低了AI应用的技术门槛。
4.2 并行计算策略的创新与优化
针对建筑能源模拟计算密集型的特点,本研究提出了创新的本地-云端混合并行架构,这一设计在效率和灵活性之间取得了良好平衡。传统的并行模拟方法往往依赖单一的计算模式,难以适应不同规模和复杂度的模拟任务。Epeditor的混合架构通过动态负载均衡算法,能够根据任务规模和硬件条件自动选择最优的计算策略,显著提升了资源利用效率。
实验结果揭示了不同并行策略的适用场景:对于轻量级模拟任务(进程数小于4),本地固定CPU分配方法表现最佳,能够避免进程切换开销,提升计算稳定性;而对于大规模模拟任务(案例数大于1000),云模拟方案展现出显著优势,能够支持更多并行进程,效率提升可达到5倍以上。这一发现为用户选择合适的计算策略提供了科学依据,有助于在保证模拟质量的前提下最大化计算效率。
值得注意的是,本研究提出的云模拟方案对硬件要求不高,任何安装了VMware-ESXi的普通台式计算机均可配置为虚拟机平台。这一设计大大降低了大规模模拟的硬件门槛,使得更多研究机构和企业能够开展复杂的建筑能源分析,推动了建筑节能技术的普及和应用。
4.3 复杂建筑场景的应用价值与实践意义
以合肥机场为案例的应用研究充分展示了Epeditor工具在复杂建筑场景下的实用价值。机场建筑作为典型的大型公共建筑,具有空间结构复杂、功能分区多样、能源系统庞大等特点,其能源模拟面临巨大挑战。传统模拟方法往往需要数天甚至数周才能完成一次完整的敏感性分析,而使用Epeditor工具仅需不到10min即可完成20个案例的完整工作流,效率提升显著。
研究结果揭示了夏热冬冷地区机场建筑的节能策略:在确保基本采光照度的前提下,应重点控制太阳辐射,对天窗和侧窗采用适当的遮阳措施。这一发现不仅对合肥机场的节能设计具有直接指导意义,也为同类气候区的公共建筑设计提供了参考依据。通过定量分析不同设计参数对能耗的影响,研究为建筑设计师提供了科学的决策支持,有助于在设计阶段实现能源性能的优化。
工具的应用还推动了建筑性能模拟方法的创新。传统的敏感性分析往往局限于少数几个参数的变化,难以全面揭示设计变量之间的复杂交互关系。Epeditor工具支持的大规模参数抽样和并行模拟,使得“探索性敏感性研究”成为可能,研究人员可以针对多个目标参数开展系统分析,更全面地理解建筑性能的影响机制。
4.4 技术局限性与未来发展方向
尽管Epeditor工具在建筑能源模拟和AI应用支持方面取得了显著进展,但仍存在一些技术局限性需要在未来工作中改进。
首先,工具目前缺乏直接建模功能,需要依赖外部软件生成EnergyPlus输入文件,这一转换过程增加了用户的学习和操作成本。未来计划集成基本的几何建模功能,支持常见建筑类型的快速建模,进一步提升工具的完整性和易用性。
其次,界面稳定性需要进一步提升。虽然工具的核心计算模块经过充分验证,鲁棒性良好,但在复杂操作场景下仍存在部分界面响应延迟和异常处理不足的问题。计划通过重构用户界面架构和优化事件处理机制,提升界面的稳定性和用户体验。
再次,工具的AI模型集成能力有待加强。目前工具主要专注于数据集生成,与AI训练框架的集成还不够紧密。未来计划开发更多AI模型训练的辅助功能,包括自动特征选择、模型超参数优化和训练过程可视化等,进一步提升代理模型训练的整体效率。
此外,需要与其他大规模模拟工具开展更系统的对比研究,以更全面地验证工具功能的有效性并明确最佳应用场景。同时,收集更多用户反馈对于工具的持续优化和功能拓展至关重要。
05
结 论
本研究成功开发了面向建筑能源不确定性模拟的高并行计算工具Epeditor,通过系统的理论研究和实践验证,取得了重要成果。工具采用本地-云端混合并行架构,实现了模拟效率的显著提升,比传统方法效率提升5倍以上,能够支持数千个样本的快速生成。用户友好的参数抽样与结果处理系统降低了不确定性模拟的技术门槛,支持多种参数定义方式和统计方法。以合肥机场为案例的应用研究验证了工具在复杂建筑场景下的有效性,完成20个案例的完整工作流仅需不到10min,研究结果揭示了夏热冬冷地区机场建筑的节能策略。
研究的创新贡献主要体现在3个方面:(1)技术架构创新方面,提出了本地-云端混合并行计算架构,解决了传统并行模拟效率低下的问题;(2)方法流程创新方面,开发了自动化参数抽样-模拟-结果处理全流程,实现了从建筑模型到模拟结果的无缝转换;(3)应用价值创新方面,验证了工具在复杂建筑场景下的实用价值,为建筑节能设计提供了科学依据。
尽管存在一些局限性(如缺乏直接建模功能、界面稳定性需要提升等),但Epeditor工具在建筑能源模拟和AI应用支持方面展现出巨大潜力。未来工作将围绕技术优化、应用拓展和生态建设3个方向展开,进一步提升工具的性能和应用价值。工具已开源供研究和测试使用,有望在推动建筑行业绿色低碳发展方面发挥重要作用。论文中所有的代码资源、相关说明和用户手册等,都可以从链接https://github.com/UmikoXiao/epeditor中获取。
参考文献:
[1]XU X, HU Y, ATAMTURKTUR S, et al. Systematic Review on Uncertainty Quantification in Machine LearningBased Building Energy Modeling[J]. Renewable and Sustainable Energy Reviews, 2025,18: 817.
[2]FERRANDO M, CAUSONE F, HONG T, et al. Urban Building Energy Modeling(Ubem) Tools: A state-of-the-art review of bottom-up physics-based approaches[J]. Sustainable Cities and Society, 2020, 62: 102408.
[3]CALAMA-GONZALEZ C M, SYMONDS P, PETROU G, et al. Bayesian Calibration of Building Energy Models for Uncertainty Analysis Through Test Cells Monitoring[J]. Applied Energy, 2021, 282: 116118.
[4]PAN X, XU Y, HONG T. Surrogate Modelling for Urban Building Energy Simulation Based on the Bidirectional Long ShortTerm Memory Model[J]. Journal of Building Performance Simulation, 2024, 0(0):1-19.
[5]MARTINS T A de L, ADOLPHE L, GONCALVES BASTOS L E, et al. Sensitivity Analysis of Urban Morphology Factors Regarding Solar Energy Potential of Buildings in a Brazilian Tropical Context[J]. Solar Energy, 2016, 137: 11-24.
[6]LUO M, WANG Z, ZHANG H, et al. High-density Thermal Sensitivity Maps of the Human Body[J]. Building and Environment, 2020, 167: 106435.
[7]DesignBuilder Software Ltd. DesignBuilder 建筑能耗模拟软件[EB/OL].(2025-11-08)[2025-11-08]. https://www.designbuilder.co.uk/.
[8]Sadeghipour Roudsari M,Pak M,Viola A. Ladybug: A Parametric Environmental Plugin For Grasshopper to Help Designers Create an Environmentally-Conscious Design[C]// Proceedings of BS 2013: 13th Conference of the International Building Performance Simulation Association. 2013, 3128-3135.
[9]SANTOSH PHILIP, LEORA TANJUATCO. Eppy Tutorial[EB/OL].(2025-11-08)[2025-11-08]. https://eppy.readthedocs.io/en/latest/Main_Tutorial.html.
[10]JOSHUA NEW, MARK ADAMS, PILJAE IM, et al. Automatic Building Energy Model Creation(AutoBEM) for Urban-Scale Energy Modeling and Assessment of Value Propositions for Electric Utilities[C]//International Conference on Energy Engineering and Smart Grids. Cambridge, United Kingdom, 2018: 30.
[11]DENG Z, CHEN Y, YANG J, et al. AutoBPS: A Tool for Urban Building Energy Modeling to Support Energy Efficiency Improvement at CityScale[J]. Energy and Buildings, 2023, 282: 112794.
[12]Adams M B, New J R, Im P, et al. Automatic Building Energy Model Creation (AutoBEM) for Urban-Scale Energy Modeling and Assessment of Value Propositions for Electric Utilities[C]. International Conference on Energy Engineering and Smart Grids, 2018, 30.
注:本公众号转载文章仅用于分享,不用于任何商业用途。如涉及版权问题,敬请后台联络授权或议定合作,我们会按照版权法规定第一时间为您妥善处理。

欢迎分享您的优质资源
投稿邮箱 tucsu@mail.tsinghua.edu.cn
