 夜雨聆风
夜雨聆风做风控挖掘时间长了,难免会觉得传统特征工程越做越枯燥。
翻来覆去都是各类统计指标、分位数切割、行为频次计数、聚合衍生特征……每一个特征单独看都逻辑自洽,但堆砌组合在一起时,总觉得有些割裂,缺少对用户真实行为的理解与感知。
后来小编慢慢换了一种思路:不再人工拆解、强行提炼碎片化行为表征,而是直接读懂完整行为序列本身。
举个实际业务例子:小编最近在做海外风控数据挖掘,海外业务高度依赖自有生态数据,外部三方在小编负责的国家覆盖低且重要性不高(突然觉得还是国内好呀,不知道发达国家数据怎么样,知道的小伙伴可以跟小编讲讲)。
只能深度挖掘内部数据价值 如交易流水、APPlist、SMS、设备行为日志、埋点数据,都是我们核心的挖掘抓手。
今天咱们先聚焦最常用的 AppList 展开聊聊。之前分享过简易的 Encoder+CLS 建模方案。
本篇进一步升级,详解BERT 序列预训练在 AppList 上的落地用法,后续还会分享大模型 LLM 在风控行为建模的应用。
今天咱们就把讲讲 把用户手机上的 App 序列,当成一段文本来处理,然后用类似 BERT 的方式做预训练,让模型自己去学序列里的规律。
整个流程是什么样的
事情大概分这么几步:
原始数据是每个用户的 App 启动序列,已经被编码成整数,一行一条记录。
拿到这个之后,先做词表裁剪,把低频的 App 过滤掉;
再构建一个类 BERT 的小模型;用 MLM 方式做预训练;
最后把模型保存下来,等着接到下游任务里。
这套流程本身其实并不复杂,但里面有几个细节值得展开说。
词表:不是建越大越好
第一件事是整理词表,applist的词表是 App ID。
小编的做法是统计所有用户每个 App 出现的次数,按频率编号。这里还是有很多要注意的点,大家根据自己家的业务及算力情况调整吧。
keep = [(tid, c) for tid, c in cnt.items()
if tid >= SPECIAL_TOKEN_NUM and c >= min_count]
keep.sort(key=lambda x: -x[1])
比如要过滤掉一些低频的app,因为低频词没有足够的样本让模型学到有意义的表示,留着只会占 embedding 空间,还会引入噪音。
另一个点是词表不能用OOT来建。小编以前做预训练模型时并不会划分OOT,这次小编问了大模型需要划分OOT来避免数据穿越吗?
大模型的回答是 如果把盲测的数据也算进来,那些只在未来才出现的新 App,会被提前收录进词表。模型训练时就隐式地"见过"了未来的信息,线下指标会虚高,但上线之后大概率打脸。
算了,先听大模型的吧。
词表建好之后,再统一把训练集和盲测集都映射过去,遇到不在词表里的 token 就标记为 [UNK]。
app2id, vocab = build_vocab_from_sequences(train_df, ...)
train_seqs = remap_sequences(train_df['app_name_encoded'].tolist(), app2id)
oot_seqs = remap_sequences(oot_df['app_name_encoded'].tolist(), app2id)
检查一下 训练集和盲测集 UNK 的占比:
如果 OOT 的 UNK 比例明显高于 train,说明这段时间内 App 生态变化不小,有大量新的应用出现。这是数据漂移的一个信号,后续接下游任务时需要留意。
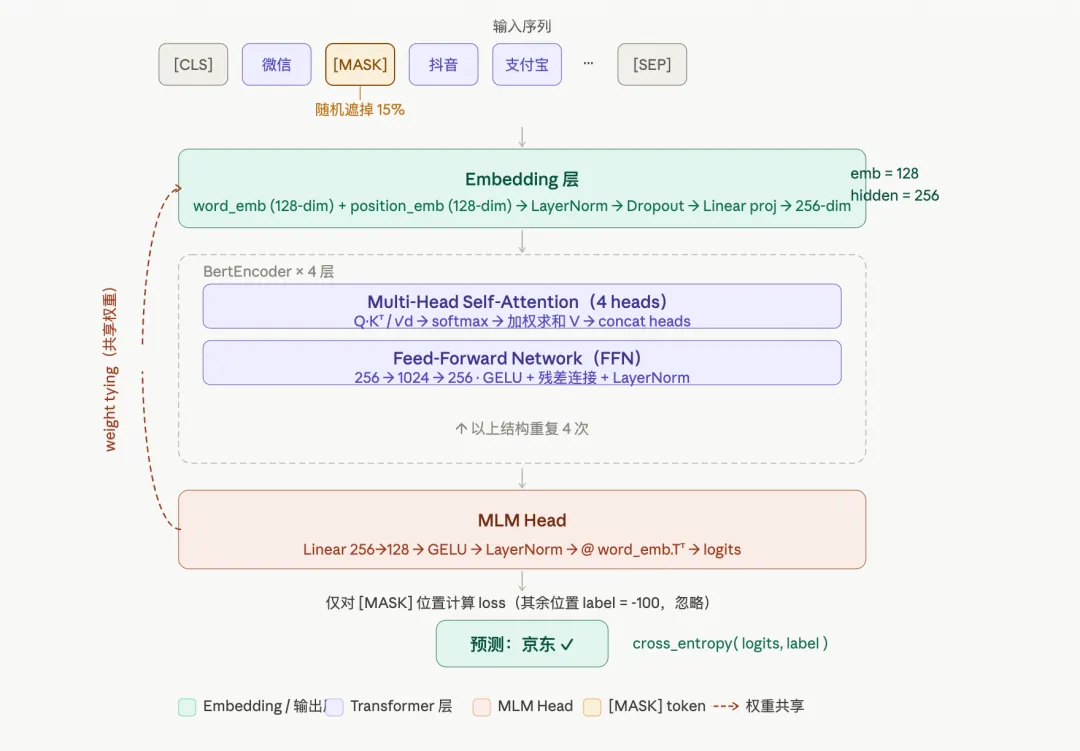
模型结构:一个精简版 BERT
模型不大,8M左右的参数量,整体是 embedding 层 + Transformer encoder + MLM Head。
embedding 层:两个维度,一个投影
每个 token 进来,先查两张vocab 和 position 表,这和 BERT 原版的做法是一样的。position embedding 的作用是告诉模型顺序,我们之前说过 Transformer 本身是并行处理所有位置的,它看不到谁前谁后,位置信息要显式注入进去。
这里有一个小设计:word embedding 和 position embedding 的维度是 128,但 Transformer 内部的 hidden size 是 256,中间用一个线性层做投影:
self.proj = nn.Linear(config.emb_size, config.hidden_size)
# forward 里:
emb = self.word_embeddings(input_ids) + self.position_embeddings(pos_ids)
emb = self.LayerNorm(emb)
emb = self.dropout(emb)
if self.proj isnotNone:
emb = self.proj(emb) # 128 → 256
为什么这么拆?因为 embedding 矩阵的参数量是 vocab_size × emb_size。词表如果有几千个 App,emb_size 从 256 压到 128,embedding 层的参数直接少一半。而 Transformer 的 FFN 和 attention 计算复杂度跟 hidden size 有关 ,但跟 vocab_size 无关,可以单独调大一点来保住表达能力并且降低算力。
是为了解耦 词表规模 和 模型宽度 这两件原本被绑死的事情,在词表大、模型不能太重的场景下比较实用。
Transformer encoder:注意力在做什么
encoder 直接用了 HuggingFace 的 BertEncoder,4 层,每层 4 个注意力头,FFN 宽度 1024。参数量不大,但值得把里面的机制说清楚。
Self-Attention 是 Transformer 的核心,它做的事情是:对序列里的每个位置,去看其他所有位置,判断哪些位置的信息对当前位置有用,然后加权聚合过来。
Attention(Q, K, V) = softmax(QK^T / √d_k) · V
Multi-Head 的意思是把这个过程并行做多次,每次用不同的线性变换,最后把多个结果拼起来再投影回来。直觉上是:不同的头可以关注不同类型的关系,有的头可能在看相邻 App 的共现,有的头可能在看序列开头和当前位置的关联,各自学各自的,最后合起来。
Attention 计算完之后还要过 padding mask。因为序列长度不一样,短的序列会在末尾补 [PAD],这些位置不应该参与计算。mask 的做法是把 PAD 位置的 attention score 填成一个极大的负数,softmax 之后就趋近于 0,相当于屏蔽掉:
ext = attention_mask[:, None, None, :].to(dtype=dtype)
ext = (1.0 - ext) * torch.finfo(dtype).min
attention_mask 是一个 0/1 矩阵,PAD 位置是 0,有效位置是 1。这里做了一个变换:有效位置变成 0(不加惩罚),PAD 位置变成 -inf(加极大惩罚),然后传给 BertEncoder 在每层 attention 里叠加到 score 上。
每层 Transformer 除了 attention,还有一个 FFN(前馈网络),就是两个线性变换夹一个激活函数,hidden_size → 1024 → hidden_size,作用是在 attention 聚合了上下文之后,对每个位置的表示做进一步的非线性变换。每个子层后面都跟着残差连接和 LayerNorm,保证梯度流通,也让训练更稳定。
MLM Head:为什么要共享权重
encoder 出来之后,每个位置都有一个hidden state。MLM Head 的任务是:拿被 mask 掉的那些位置的 hidden state,预测原来的 token 是什么。
结构是先从 hidden_size 投影回 emb_size,过一个 GELU 激活和 LayerNorm,然后和 word embedding 矩阵做内积:
x = self.mlm_dense(seq_out) # 256 → 128
x = self.mlm_act(x) # GELU
x = self.mlm_norm(x) # LayerNorm
emb_w = self.app_embeddings.word_embeddings.weight
logits_active = x_flat @ emb_w.t() + self.mlm_bias
最后这一步 @ emb_w.t() 是关键——它直接复用了 word embedding 层的权重,而不是再接一个独立的线性层。这叫权重共享。
为什么这么做?直觉上,word embedding 矩阵的第 i 行,代表第 i 个 token 是什么样的。预测 token 的时候,其实是在问:hidden state 和哪个 token 的表征最接近?
用内积来度量相似度,然后 softmax 选概率最高的那个,逻辑上是自洽的。
更重要的是,这个设计让两件事耦合在一起:embedding 层要学好每个 token 的表示,才能让 MLM Head 预测得准;反过来,MLM Head 预测得准,梯度也会返回来继续改善 embedding。两边互相约束,比分开训练更紧凑,参数也少一个大矩阵。
损失只算被 mask 的位置,其他位置 label 设成 -100,PyTorch 的 cross_entropy 会自动忽略:
active = labels.view(-1) != -100
x_flat = x.view(-1, x.size(-1))[active]
logits_active = x_flat @ emb_w.t() + self.mlm_bias
labels_active = labels.view(-1)[active]
loss = nn.functional.cross_entropy(logits_active, labels_active)
先把 mask 位置筛出来,只对这些位置算 logits 和 loss,而不是全序列都算一遍再过滤。这样在序列长、mask 比例只有 15% 的情况下,计算量能省不少。
整个模型加起来,参数量大概在几百万量级,放在 App 行为序列这个场景里算是合适的体量。不需要很大,够用就行。
训练目标:完形填空
预训练的核心是 MLM,思路来自 BERT,原理很朴素:
把序列里随机 15% 的 token 遮掉,让模型根据上下文去猜原来是什么。
具体实现上,被选中的 token 会按比例做三种处理:80% 替换成 [MASK],10% 随机换成另一个 token,剩下 10% 保持原样不动。
if random.random() < self.mlm_prob:
labels[i] = tokens[i]
r = random.random()
if r < 0.8:
input_ids[i] = self.mask_id
elif r < 0.9:
input_ids[i] = random.randint(self.random_token_start, self.vocab_size - 1)
为什么不全部换成 [MASK]?因为如果全遮,模型会学到一个捷径:只有看到 [MASK] 才需要认真预测,其他位置直接摆烂。加入随机替换和保持原样,是在强迫模型对每个位置都保持警惕,不知道哪个位置的 token 是真实的,哪个是被动过手脚的。
这个训练过程,本质上是在让模型学习:在这种行为序列里,什么 App 和什么 App 经常一起出现,什么样的序列模式是正常的,什么位置的 App 可以互相替代。这些知识,之后都会编码进 embedding 里。
训练时的几个工程细节
显存是这种单卡场景下绕不开的话题(求资源)。这里用了两个方式来让 batch 尽量大一点:
一个是梯度累积:
PER_DEV_BS = 64
GRAD_ACCUM = 8
每次只跑 64 条,但累积 8 步之后再更新参数,效果等价于 batch size 是 512,但显存峰值只有 batch 64 的水位。
另一个是 gradient checkpointing。正常的反向传播需要把前向传播时所有层的中间激活值都保存下来,显存占用和层数成正比。开了 gradient checkpointing 之后,中间激活不存,反向传播时重新算一遍,用计算换显存,代价是训练速度大约慢 20%-30%,但能跑更大的 batch 或者更深的模型。
gradient_checkpointing=True,
fp16=torch.cuda.is_available(),
混合精度(fp16)也开着,大约能省一半显存,在兼容性好的卡上几乎没有精度损失。
在预训练阶段其实不用太在意MLM accuracy 的绝对值高不高,毕竟这不是最终任务。咱们更关心的是:学出来的 embedding 有没有意义,接到下游任务之后有没有帮助。
总结一下
这整件事,核心思路是把用户行为序列类比成自然语言,借用 NLP 里成熟的预训练框架,让模型在无监督的前提下学习行为规律,再把学到的表示用于下游风控任务。
实现上没有太多新东西,但做对了几个容易忽略的细节,为了资源改了一点算法。这些东西不复杂,但少了哪个,效果好不好都不好说,更不知道哪里出了问题。
模型这个版本只是个起点。预训练结束之后,embedding 能不能在逾期预测这类有CLS模型上真正发挥作用,要等接上下游之后才能看到。
这个其实咱们讲过,大家自己翻翻吧。
