夜雨聆风
夜雨聆风
说实话,咱们平时工作学习中,是不是经常碰到这种糟心事儿?好不容易找到一份技术文档或者论文,结果是个扫描版PDF,里面的文字根本没法复制。想把它转成可以编辑的Markdown格式,要么得开各种付费会员,要么转出来的格式乱七八糟,表格变成纯文本,公式全成乱码,图片也不翼而飞。手动重新排版吧,简直能把手都敲酸。
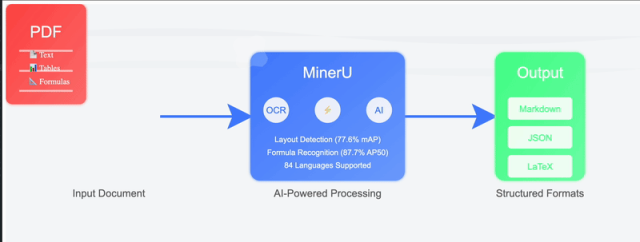
最近我在GitHub上挖到个宝,是上海人工智能实验室OpenDataLab团队开源的MinerU项目。这东西简直就是为咱们这种经常要跟PDF死磕的人量身定制的,它能把各种复杂的PDF文档精准地转成Markdown格式,而且完全开源免费。
它到底强在哪儿?
这玩意儿最厉害的地方在于,它不只是简单的文字提取。普通的转换工具,经常会把页眉页脚、脚注页码这些干扰信息也一起转进去,读起来特别难受。但MinerU聪明得很,它能自动识别并移除这些"杂质",只保留正文内容。而且对于那些复杂的排版,比如多栏布局、跨页表格,它都能按照人类正常的阅读顺序重新组织,不会出现从左栏跳到右栏的混乱情况。
更让我惊喜的是它对公式的处理。理工科的同学肯定懂,PDF里的数学公式要是能准确转成LaTeX格式,那简直能省大事。MinerU内置了公式识别引擎,能把复杂的数学符号准确转换成LaTeX代码。还有表格,它能把PDF里的表格转成HTML格式,保留原有的行列结构,这在以前可是很多商业软件都做不到或者要收费的。
另外,如果你手里的是扫描件,或者有些PDF文字层已经损坏了,MinerU也内置了OCR功能,支持109种语言的识别。不管是英文论文还是中文资料,甚至是手写的笔记,它都能想办法给你识别出来。
怎么安装?手把手教你
MinerU的安装其实挺简单的,官方也考虑到了不同用户的需求,提供了几种不同的安装方式。咱们就挑最实用的两种来说:
方法一:用pip快速安装(适合大多数人)
这个最简单,只要你有Python环境,打开终端直接敲命令就行。官方推荐用uv来安装,速度会快一些:
# 先升级pip,然后安装uvpip install --upgrade pippip install uv# 安装完整版MinerU(包含所有功能)uv pip install -U "mineru[all]"如果你的电脑配置比较一般,或者只想先试试基础功能,也可以装轻量版:
uv pip install -U "mineru[core]"这里有个小提示,[all]版本包含了VLM(视觉语言模型)加速的支持,如果你有独显的话,转换速度会快很多。纯CPU环境也能跑,就是处理大文件的时候会慢一些,耐心等等也能用。
方法二:Docker部署(适合服务器或者不想折腾环境的人)
如果你是在服务器上部署,或者就是想一键搞定所有依赖,那Docker绝对是最佳选择。官方提供了现成的镜像,拉下来就能用,不用担心各种环境配置问题。具体的Docker部署命令可以在他们的文档里找到,基本就是几行命令的事儿,特别适合想私有化部署的企业用户。
怎么用?三种姿势任你选
安装好之后,使用起来也很灵活,官方给了好几种使用方式,不管你喜欢命令行还是图形界面,都能找到适合自己的。
第一种:命令行操作(最快捷)
对于技术党来说,命令行永远是最高效的。转换单个文件特别简单:
# 基础用法,自动检测设备(有GPU会用GPU,没GPU用CPU)mineru -p /path/to/your/file.pdf -o /path/to/output/# 如果你的电脑没有独显,强制使用CPU模式(pipeline后端)mineru -p /path/to/your/file.pdf -o /path/to/output/ -b pipeline这里的-p后面跟你的PDF路径,-o指定输出目录。运行完之后,你指定的输出目录里就会生成一个同名的Markdown文件,还有一个images文件夹,里面存着从PDF里提取出来的所有图片。
如果你有一批文件要处理,也可以直接指定文件夹,它会批量处理:
mineru -p /path/to/input/folder/ -o /path/to/output/第二种:启动Web界面(最直观)
如果你不喜欢黑乎乎的命令行,MinerU也提供了基于Gradio的Web界面。启动也很简单:
# 安装必要的依赖后pip install gradiomineru-webui然后打开浏览器访问localhost:7860,就能看到个简洁的界面,上传文件、查看进度、下载结果,全程鼠标点点点,对非技术背景的朋友特别友好。
第三种:接入API(最适合开发)
如果你想把这个功能集成到自己的系统里,或者给团队用,MinerU还提供了FastAPI服务:
# 安装API依赖pip install uvicorn fastapi python-multipart# 启动服务marker_server --port 8001服务启动后,访问localhost:8001/docs就能看到详细的接口文档。你可以用Python这样调用:
import requestsimport jsonpost_data = {'filepath': '你的PDF文件路径.pdf',}response = requests.post("http://localhost:8001/marker", data=json.dumps(post_data)).json()一些实用的小技巧
用了几次之后,我发现几个能让体验更好的设置。如果你发现转换出来的文字有乱码,或者明明看着是文字却识别不出来,可以试试加上--force_ocr参数,强制对整页进行OCR识别。虽然会慢一点,但准确性会高很多。
还有就是处理学术论文的时候,如果你特别在意行内公式的准确性,记得开启force_ocr选项,这样那些夹在文字中间的数学符号也能被正确转成LaTeX格式。
写在最后
MinerU这个项目,从我个人的使用体验来看,确实解决了很多实际痛点。特别是咱们现在做知识管理、搭建个人知识库的时候,经常要把各种PDF资料转成Markdown存进Obsidian或者Notion里,有了这个工具,以前需要手动复制粘贴一小时的活儿,现在几分钟就搞定了。
项目还在快速迭代中,最近几个月更新特别频繁,比如增加了对长文档的滑动窗口处理,大幅降低了内存占用,几万页的文档也不用担心爆内存了。而且还优化了线程安全,支持多线程并发处理,效率提升不少。
感兴趣的朋友可以直接去GitHub上看看,星标已经快6万了,社区也挺活跃的,有问题去提Issue,开发者响应挺快的。
源码地址:https://github.com/opendatalab/MinerU
专注分享 GitHub知识,分享AI 资讯和AI搞米经验,分享OpenClaw使用经验。

想领取完整版OpenClaw资料的小伙伴,点赞+再看,扫码加我VX,备注“github"。