 夜雨聆风
夜雨聆风当你把一份重要文档交给AI助手修改,期待它像人类助理一样可靠地完成任务时——小心,它可能正在悄悄破坏你的文件。
论文通过大规模模拟实验揭示了一个令人不安的事实:即使是最先进的AI模型(Gemini 3.1 Pro、Claude 4.6 Opus、GPT 5.4),在经过20次委托编辑后,平均会损坏25%的文档内容。而其他模型的表现更糟,平均损坏率高达50%。这些错误稀疏但严重,会在长期交互中不断累积,最终导致文档静默损坏。
委托工作的信任危机
大语言模型(LLM, Large Language Model)正在改变知识工作方式,"委托工作"(delegated work)成为新的交互范式——用户将任务完全交给AI执行,就像"氛围编程"(vibe coding)那样。但委托的前提是信任:你必须相信AI能忠实执行任务,不会在文档中引入错误。
问题在于,当前的AI系统还不配得到这份信任。
论文引入了DELEGATE-52基准测试来研究AI系统在委托工作流中的表现。这个基准覆盖52个专业领域,包括编程、晶体学、音乐记谱等,模拟需要深度文档编辑的长期委托工作流。
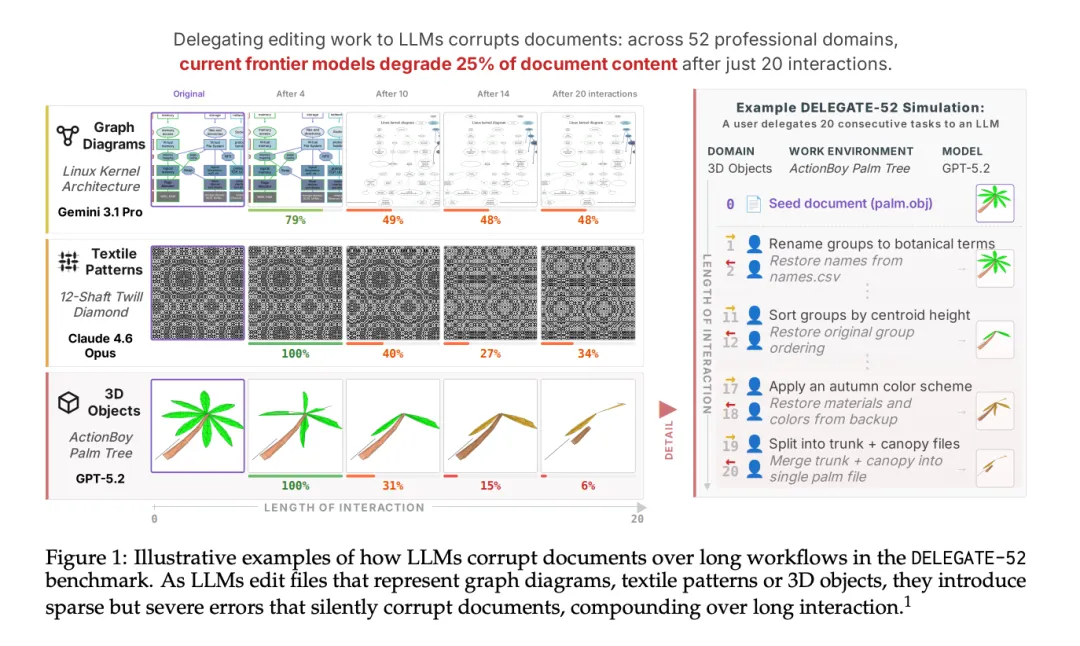
[Figure 1: 文档损坏示例] 展示了LLM如何在长工作流中逐步损坏文档。随着LLM编辑代表图表、纺织图案或3D对象的文件,它们引入稀疏但严重的错误,这些错误在长期交互中不断累积,静默地损坏文档。
往返测试:无需标注的评估方法
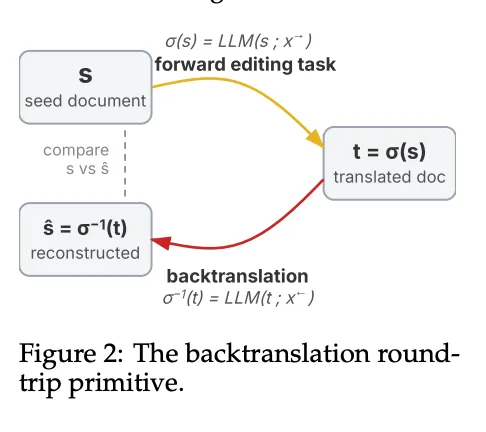
论文采用了一个巧妙的评估方法——往返接力模拟(round-trip relay simulation)。核心思想是:每个编辑任务都是可逆的,由一个正向指令和一个反向指令组成。应用两者形成一个往返循环,在完美模型下应该能精确恢复原始文档。
具体来说,给定一个种子文档s,模型先执行正向编辑得到转换文档t,再执行反向编辑得到重建文档ŝ。通过测量s和ŝ的相似度,就能评估模型的性能,无需人工标注参考答案。多个往返可以串联成接力,模拟长期交互。
这种方法源自机器翻译中的回译技术(backtranslation),论文将其改造用于研究长期委托交互。
[Figure 2: 往返原语示意] 说明了由一对正向和反向编辑指令组成的往返原语,通过测量重建文档与原始文档的相似度来评估模型性能。
52个领域,310个工作环境
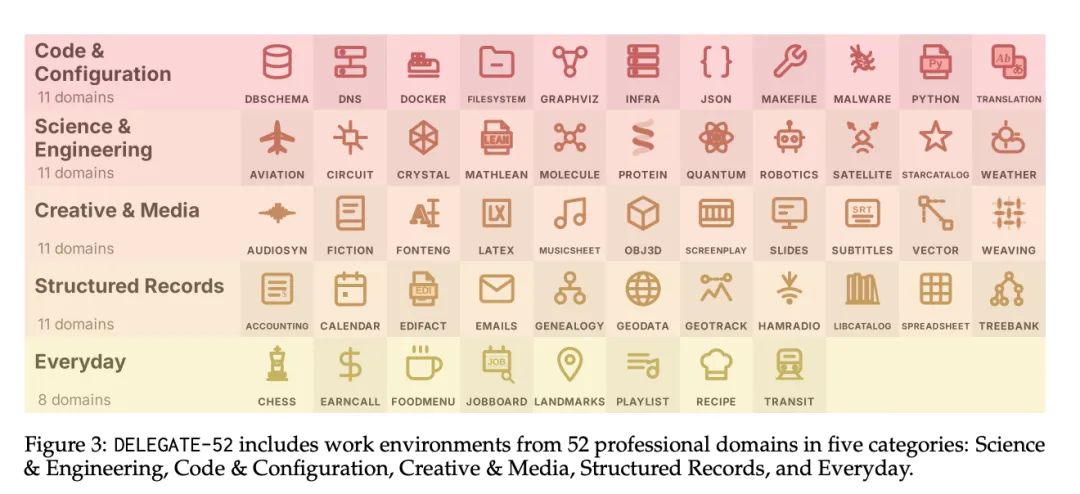
DELEGATE-52包含52个专业领域的310个工作环境,分为五大类:科学与工程、代码与配置、创意与媒体、结构化记录、日常应用。
每个工作环境包含:
- 种子文档
:2-5k token的真实文档(非合成数据),从网上找到并有许可重新分发 - 编辑任务
:5-10个可逆的正向/反向指令对,代表真实的工作任务 - 干扰上下文
:8-12k token的相关但不干扰任务的文档,模拟真实工作中检索精度不完美的情况
[Figure 3: 领域分类] DELEGATE-52涵盖52个专业领域,分为科学与工程、代码与配置、创意与媒体、结构化记录和日常应用五大类。
论文为每个领域实现了定制的相似度函数。例如在食谱领域,解析器将文档转换为结构化表示(成分、步骤、提示),相似度函数对成分列表(40%)、步骤(40%)和提示(20%)进行加权求和。这种灵活性允许对不同领域进行适当的评分:成分中的小改动(如200g→800g黄油)会严重影响总分,但不影响语义的表面变化(如200g vs. 0.2kg黄油)不会影响分数。
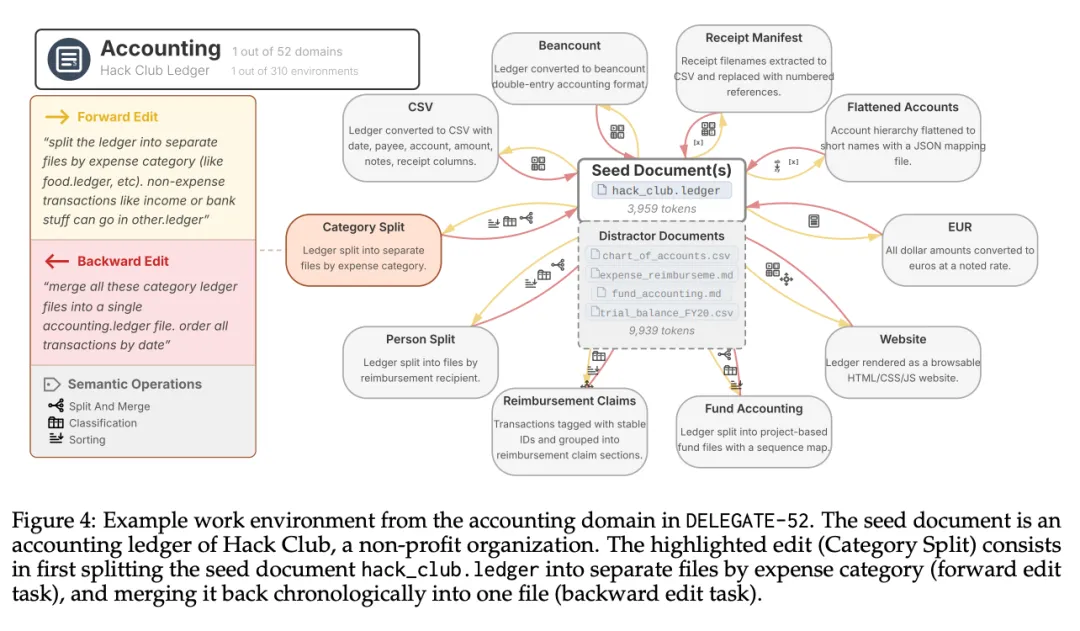
[Figure 4: 会计领域示例] 展示了会计领域的工作环境,种子文档是Hack Club非营利组织的会计分类账,高亮的编辑任务是按费用类别拆分和合并文档。
19个模型的大溃败
论文测试了19个LLM,包括OpenAI的GPT系列、Anthropic的Claude系列、Google的Gemini系列等,进行了10轮往返(20次交互)的模拟。
结果触目惊心:所有模型的性能都随交互次数增加而退化,平均退化率达50%。即使是最强的三个模型(Gemini 3.1 Pro、Claude 4.6 Opus、GPT 5.4),在20次交互后也平均损坏了25%的文档内容。
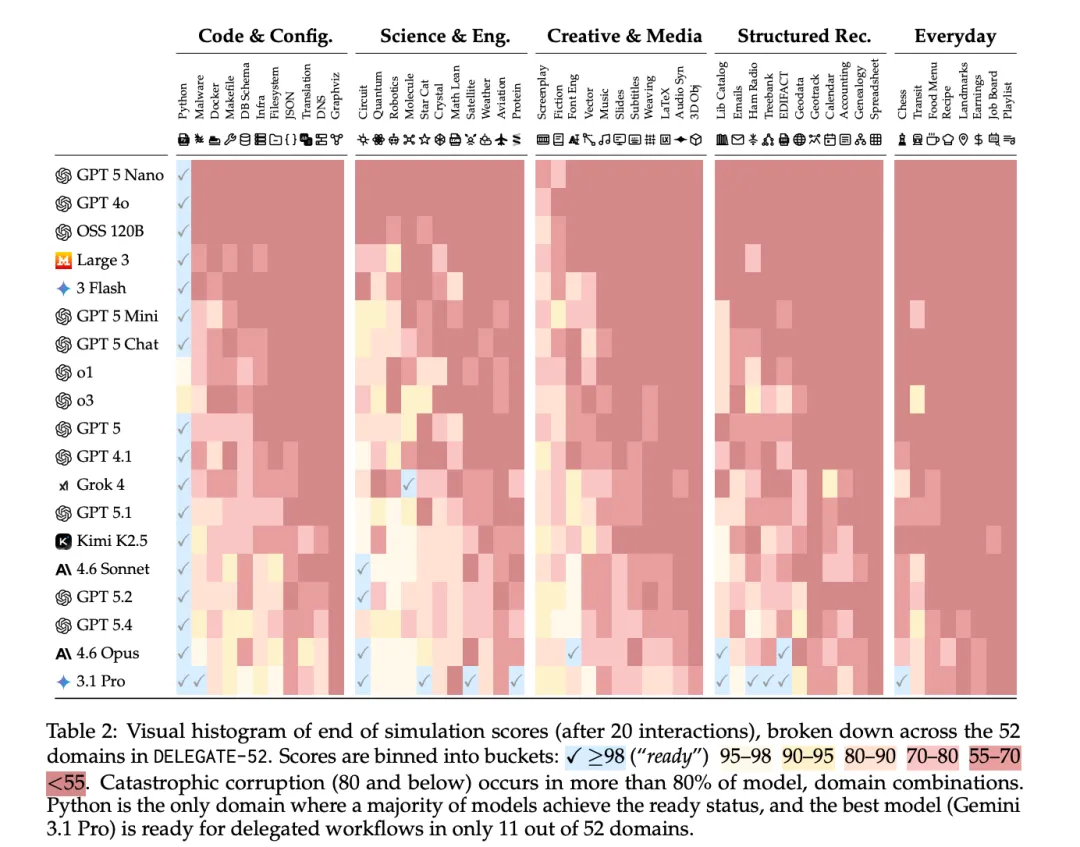
按领域分解的结果显示,模型在绝大多数领域都未准备好进行委托工作流,在80%的模拟条件下严重损坏文档(至少-20%退化)。Python是唯一的例外:19个模型中有17个实现了无损操作。表现最好的Gemini 3.1 Pro仅在52个领域中的11个达到"就绪"状态(RS@20 ≥ 98%)。
[Table 2: 领域分解结果] 展示了20次交互后各领域的最终得分分布。灾难性损坏(80分及以下)发生在超过80%的模型-领域组合中。Python是唯一大多数模型达到就绪状态的领域。
论文还发现,短期性能(2次交互后)并不总能预测长期性能。例如GPT 5和Kimi K2.5在2次交互后得分几乎相同(91.5 vs. 91.1),但到最后分别为48.3和64.1。这验证了长期评估的重要性。
工具反而帮倒忙
直觉上,给模型提供工具(如文件读写、代码执行)应该能减少退化,因为它们可以进行有针对性的程序化修改,而不是重新生成整个文档。但实验结果恰恰相反。
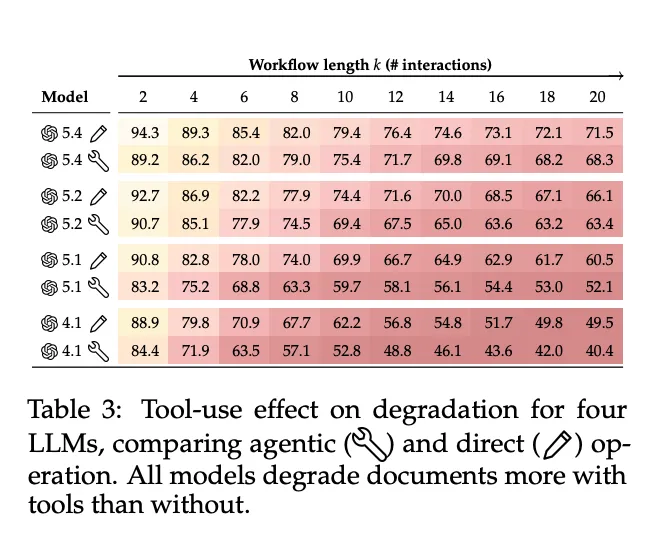
论文实现了一个基础的agent框架,提供文件读写和代码执行工具。测试的四个模型在使用工具时表现更差,平均额外退化6%。最好的GPT 5.4也额外退化了3%(71.5% vs. 68.3%)。
[Table 3: 工具使用效果] 对比了四个LLM在使用工具(agent模式)和不使用工具(直接模式)时的退化情况。所有模型使用工具后文档损坏更严重。
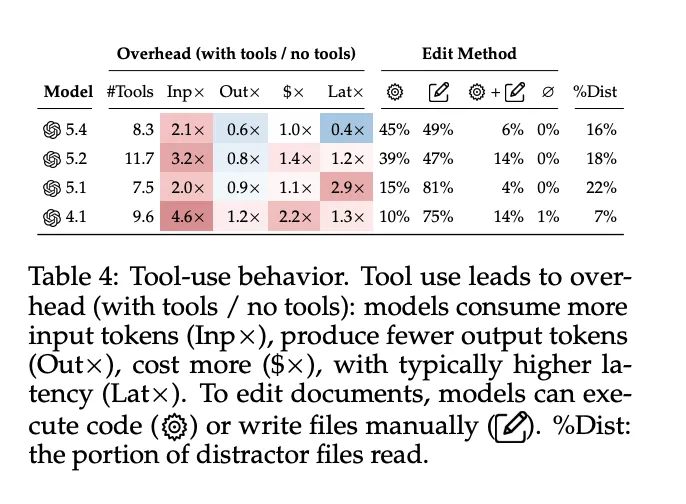
原因有二:首先,使用工具会产生开销——模型平均调用8-12次工具才能完成任务,消耗的输入token是无工具方式的2-5倍,而在长上下文环境中保持LLM性能本身就是已知挑战。其次,DELEGATE-52中的任务不能通过执行简单程序轻松完成,需要文本理解和推理,这限制了agent框架的优势。
[Table 4: 工具使用行为] 展示了工具使用导致的开销:模型消耗更多输入token、产生更少输出token、成本更高、延迟通常更高。模型可以执行代码或手动写文件来编辑文档。
在基础框架下,测试的LLM无法从agent工具使用中受益。 这表明DELEGATE-52可以服务于agent系统开发者:它提供了多样化领域的复杂编辑任务,当前LLM难以利用工具进行精确操作。
雪上加霜的复合效应
论文进一步研究了文档大小、交互长度和干扰文档的影响,发现这些因素会复合放大退化。
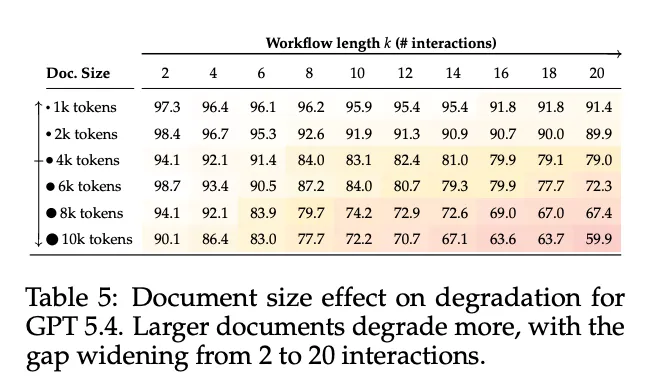
文档大小效应:随着文档从1k增加到10k token,GPT 5.4的退化逐渐恶化,在10k规模下最终得分为59.9%。每增加1000个token,2次交互后退化约0.7%,但20次交互后退化3.6%——约5倍增长。文档大小和交互长度呈乘法复合:文档增大导致的退化在交互过程中滚雪球式增长。
[Table 5: 文档大小效应] 展示了GPT 5.4在不同文档大小下的退化情况。更大的文档退化更严重,且差距从2次交互到20次交互不断扩大。
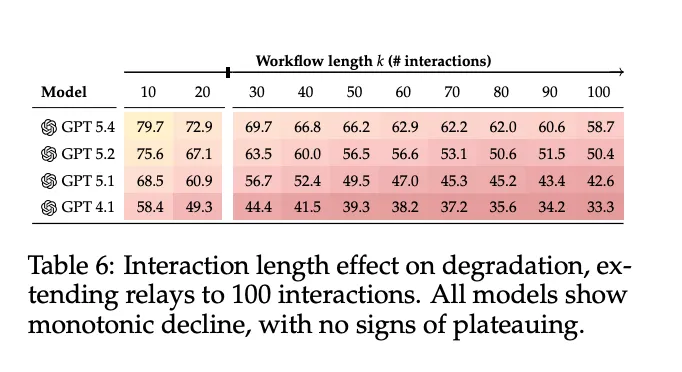
交互长度效应:将接力扩展到50轮(100次交互),退化继续累积,没有任何模型显示出趋于平稳的迹象。最强的GPT 5.4在50轮接力结束时降至60%以下。随着接力从10轮扩展到50轮,性能持续退化,即使任务重复,模型仍会引入新错误。
[Table 6: 交互长度效应] 将接力扩展到100次交互,所有模型都显示单调下降,没有趋于平稳的迹象。
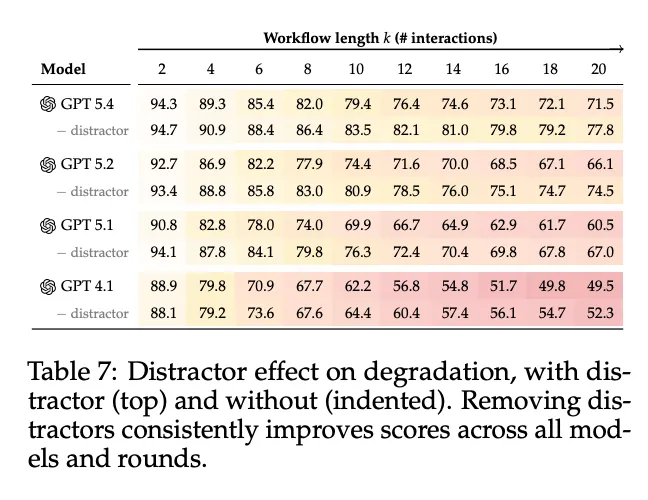
干扰效应:移除干扰文档后,初始步骤(2次交互)改善0.4-4%,但到模拟结束改善2-8%。干扰的危害随交互长度复合,测量短期干扰效应可能低估其在长期真实交互中的影响。
[Table 7: 干扰效应] 对比了有干扰文档和无干扰文档时的退化情况。移除干扰文档在所有模型和轮次中都能持续改善得分。
稀疏但致命的关键错误
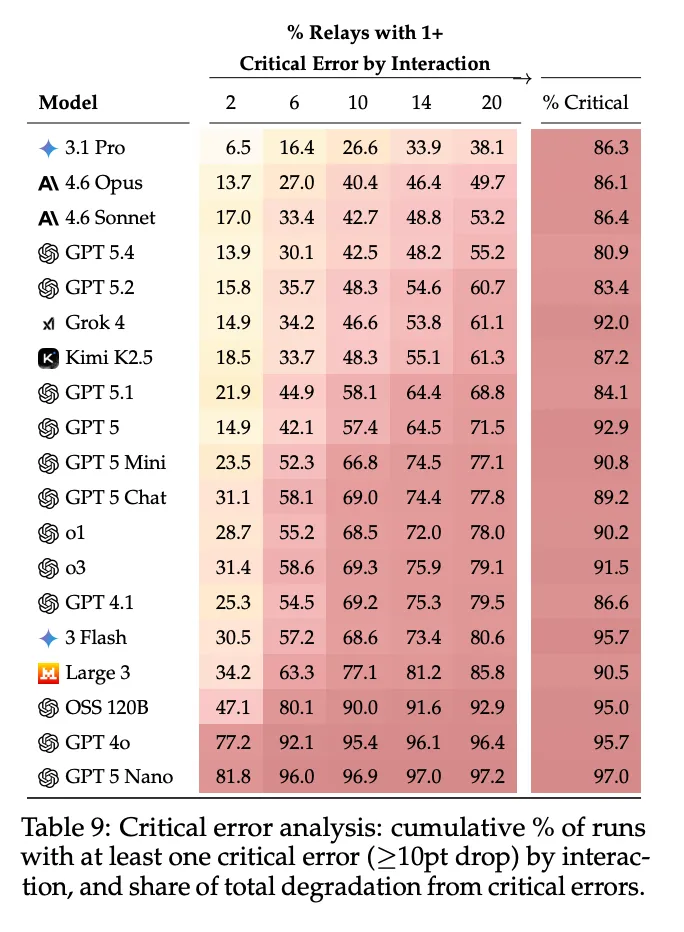
论文定义"关键错误"为单次往返导致至少10分退化。分析显示,关键错误占总退化的80-98%。换句话说,模型不是"千刀万剐"式地慢慢损坏内容,而是在某些轮次保持近乎完美的重建,在少数轮次经历关键失败——通常在单次往返中损失10-30+分。
到第20轮,除Gemini 3.1 Pro外,所有模型的大多数运行都经历了至少一次这样的关键错误。更强的模型不是更好地避免小错误,而是将关键失败延迟到后面的轮次,并在更少的交互中经历它们。
[Table 9: 关键错误分析] 展示了各模型在不同交互次数后至少出现一次关键错误(≥10分下降)的累积百分比,以及关键错误占总退化的比例。
论文还将退化分解为删除(丢失内容)和损坏(修改或幻觉内容)。较弱模型的退化主要源于内容删除,而前沿模型的退化主要归因于内容损坏。
图像编辑更糟糕
论文还实现了六个视觉工作环境来测试图像编辑工作流,测试了9个具有图像生成能力的模型。
结果显示,图像操作的退化比文本领域严重得多。最好的模型最终重建得分为28-30%,而文本领域为70-80%。即使在2次交互后,没有图像生成模型超过65%,比文本模型20次交互后还差。图像编辑模型比文本模型退化文档严重得多,尚未准备好进行委托工作。
[Figure A5: 图像领域画廊] 展示了9个图像生成模型在20次委托交互(10轮往返)中的视觉退化。每行显示一个模型在每轮往返后的输出,从原始图像(左)开始。所有模型都表现出渐进式退化。
>

X说
论文的发现对不同群体有重要启示:
对LLM开发者:DELEGATE-52的工作环境可以重新用于训练模型,循环一致性训练(cycle consistency training)提供了潜在的训练框架。每个领域都可以被视为在线强化学习的"迷你健身房",agent可以在其中训练以无损完成任务循环。
对NLP从业者:短期交互中的模型性能并不总能预测长期性能,研究长期交互的模型能力对于理解真实委托工作流的准备情况至关重要——我们需要更多长期基准。此外,理解模型能力的努力在各领域分布不均,过度研究数学和代码能力,而大量知识工作发生在其他领域——我们需要更广泛的基准来缩小这一差距。
对AI系统用户:委托工作给AI系统时,用户应谨慎,不要将LLM在一个领域的能力泛化到其他领域。模型能力遵循"锯齿状前沿"(jagged frontier),在某些任务上表现强劲(有时令人惊讶),而在其他任务上犯严重错误。当前LLM在某些领域(如Python编码)已准备好进行委托工作流,但在其他不太常见的领域则不然。总体而言,用户仍需密切监控LLM系统的操作。
论文指出了一个令人鼓舞的趋势:GPT 4o和GPT 5.4相隔16个月,但基准性能从14.7%提高到71.5%,表明进展迅速。
当前的LLM是不可靠的委托者:它们引入稀疏但严重的错误,静默地损坏文档,在长期交互中不断累积。 论文公开发布DELEGATE-52作为监控AI系统委托工作准备情况的工具,推动长期人机交互的研究。
原文标题: LLMs Corrupt Your Documents When You Delegate
原文链接: https://arxiv.org/abs/2604.15597
