 夜雨聆风
夜雨聆风大家好,我是虎哥,二十年车辆研发经验的高工。
AI很热,工具很多,变化也很快。 但对我这样的传统工程师来说,真正的问题是:
它到底能不能帮我们解决实际工作中的问题?
我不敢说自己懂AI,也知道自己有很多局限。 正因为这样,我的尝试可能更接近普通工程师的真实状态。
今天继续前面的话题。上一篇聊第二大脑实战:单篇PDF知识的沉淀,这期讲 批量,分享一点实战收获。
如果你是工程师、研究者,或者任何需要长期跟技术文档打交道的人,这套流程应该能给你一些启发。
• 本次分享我将用对话的方式,完整呈现过程。 • 展示过程用到的资料是已发表的公开资料,如有侵权,请联系我删除。
1、我尝试与AI对话
我:
我能批量导入吗?AI:
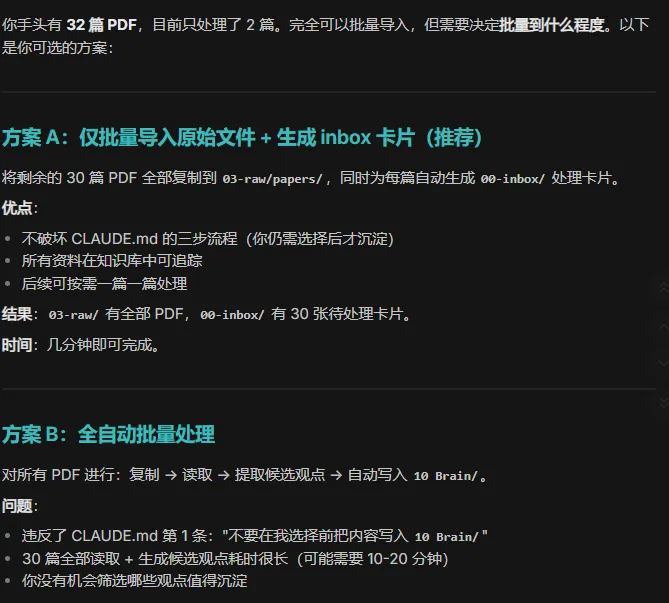

我:
我们尝试一下,我选方案A AI:
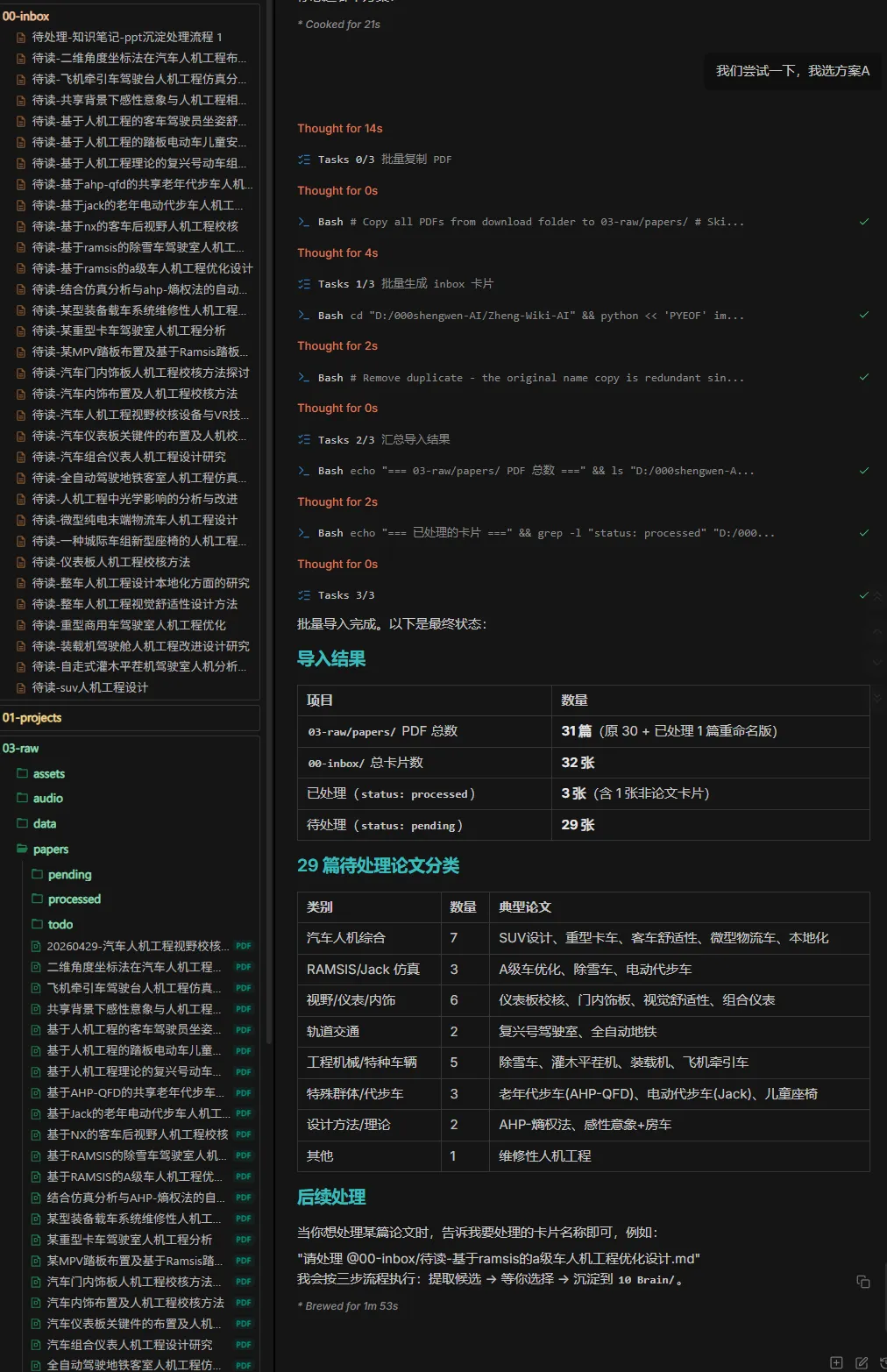
• 此时已经完成了批量导入,还没有内化沉淀为知识库 • AI在导入的同时,批量生成了”待读”卡片,留给你有时间去整理
2、我任意选择了一篇
随便挑了一篇论文,是个硕士论文,足足81页,刚好验证长篇了。
我:
请处理 @00-inbox/待读-基于ramsis的a级车人机工程优化设计.mdAI:
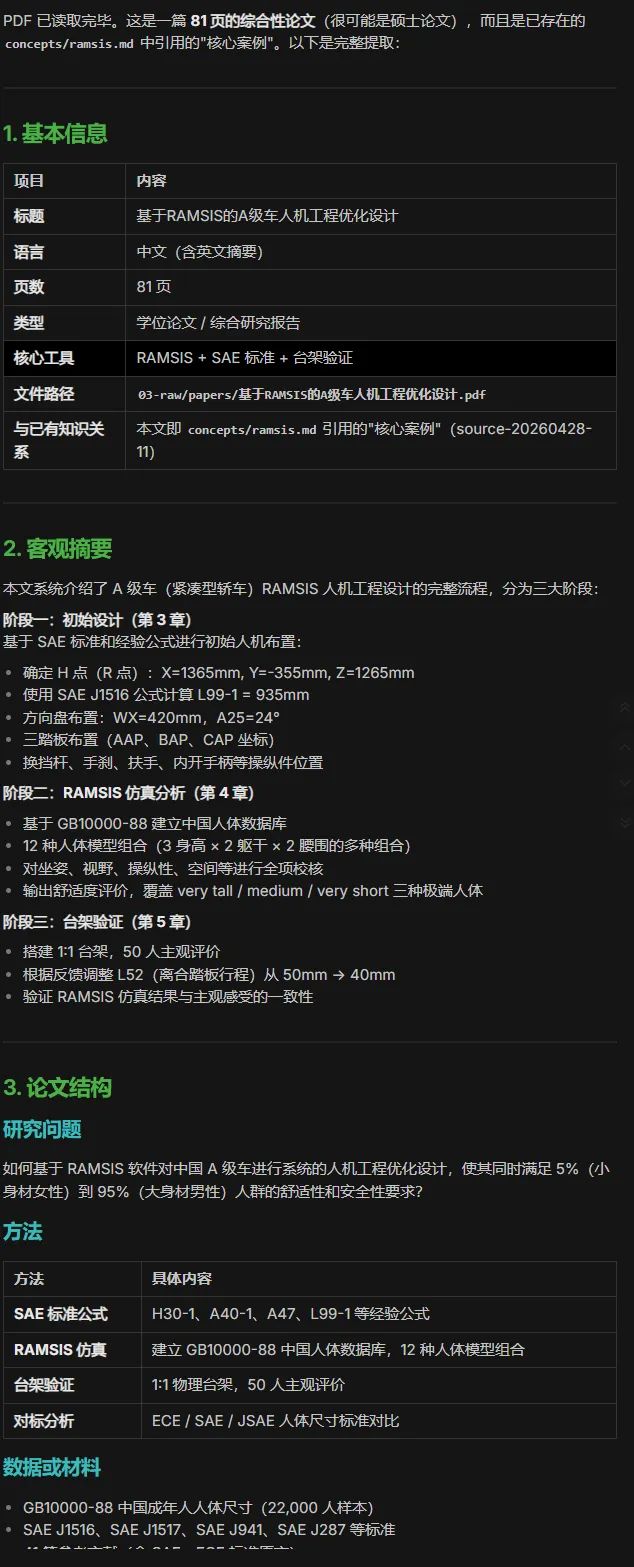
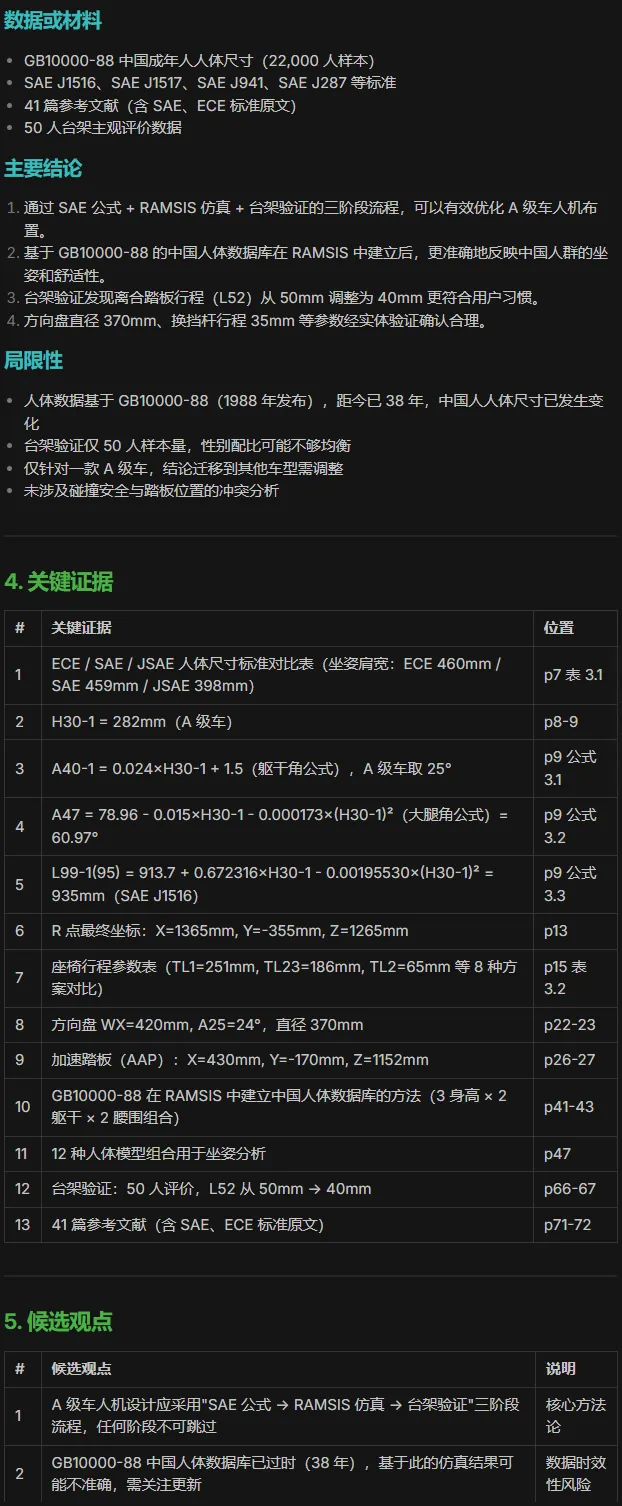


3、这里又用上了单篇的提示词
自己的知识库,得有自己理解。所以还得一篇一篇过,AI只是辅助。
当然,你也可以全权委托给AI,自主选择判断。
我选择以下内容:候选观点:1-10全选 候选概念:全选 候选项目影响:全选 候选决策:暂不需要形成独立的 decisions/。 推荐沉淀方案:B请先给我最终写入计划,包括:1. 会新建哪些文件2. 会修改哪些文件3. 每个文件写入什么内容先不要执行,等我确认。好,本次演示就到这里!
回过头来看,这套流程的核心价值其实就三条:
如果你也积压了大量论文、报告、网页却不知道怎么消化,不妨试试这套流程。
我是虎哥,一个传统车辆研发工程师,也是一名AI学习者。 之后会继续分享真实体验、踩坑和收获。 欢迎留言交流。
