 夜雨聆风
夜雨聆风
在本地跑大模型这件事,我折腾了将近一个周。
第一次装好Ollama的时候,兴冲冲拉了一个70B模型下来,结果跑起来慢得像在翻老黄页。
问题出在哪?不知道。
模型参数太大?电脑带不动?还是Ollama没调用显卡?
不知道。稀里糊涂地换了两个模型,问题依旧,最后才发现是显卡驱动没装对。
所以有了这篇文章。
我假设你是一张白纸,从头开始讲:怎么检测自己的电脑能跑什么模型(用llmfit),怎么装好基础环境,怎么跑起第一个本地大模型(用Ollama),以及在动手之前,怎么用浏览器快速评估自己电脑的硬件能力(CanIRun.ai)。
整篇文章的逻辑很简单:先检测,再动手,不走冤枉路。
一、先用 llmfit 做硬件检测:适合跑什么模型,你的数据说了算
很多人装大模型,第一步就是直接去拉模型,结果下了半天跑不起来,白浪费时间和带宽。
llmfit 这个工具就是来解决这个问题的。它跑在你的终端里,检测你电脑的 CPU、内存、显卡和显存,然后跟模型库里几百个模型做匹配,直接告诉你:哪个模型能跑,哪个模型跑得好,哪个模型跑起来会很吃力。
安装 llmfit
Linux 和 macOS 安装方式一样,一条命令:
curl -fsSL https://llmfit.axjns.dev/install.sh | sh
如果你用 Homebrew:
brew install llmfit装完之后验证:
llmfit --version
看到版本号就说明装好了。
检测硬件配置
在终端里直接运行:
llmfit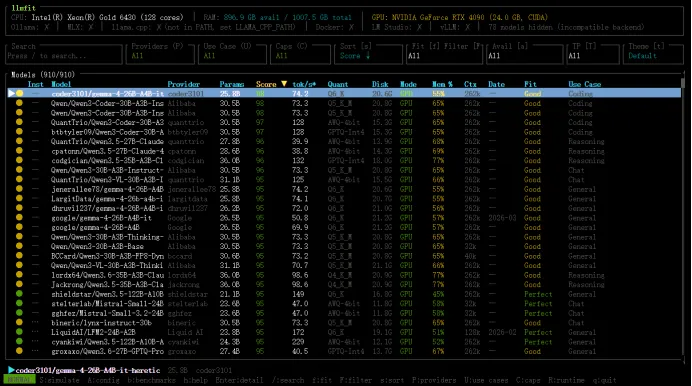
默认会进入一个交互式界面,显示你电脑的 CPU 型号和核心数、内存大小、显卡型号和显存。模型列表按"适合度"排序,适合度高的在前面。
我在用的电脑是 Ubuntu 系统,显卡是 RTX 4090,24GB 显存,120GB 运行内存。跑 llmfit 之后,它给我的推荐是:
27B-35B 参数模型:跑得很流畅
70B 参数模型:带不动,别试了
这个判断和我实际用起来的感觉基本一致。llmfit 的估算是准的。
命令行查推荐模型
如果你只想快速看结果,不需要图形界面,用 CLI 模式:
llmfit --cli recommend --limit 5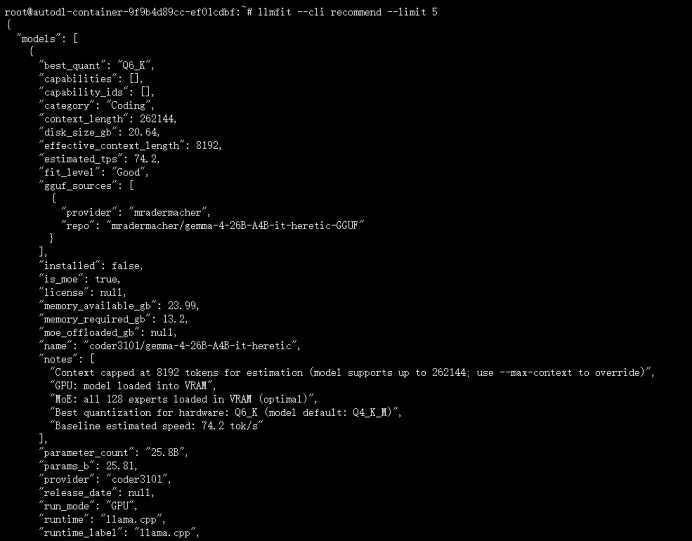
这条命令输出排名前5的推荐模型,包含模型名称、参数量、显存需求、速度估算。
过滤和搜索
在 TUI 界面里:
/ 键:搜索模型
j/k 键:上下移动
f 键:切换过滤条件
s 键:切换排序方式
如果你想找中文能力强的模型,搜索 "Qwen" 或 "deepseek",看它推荐哪个量化版本。
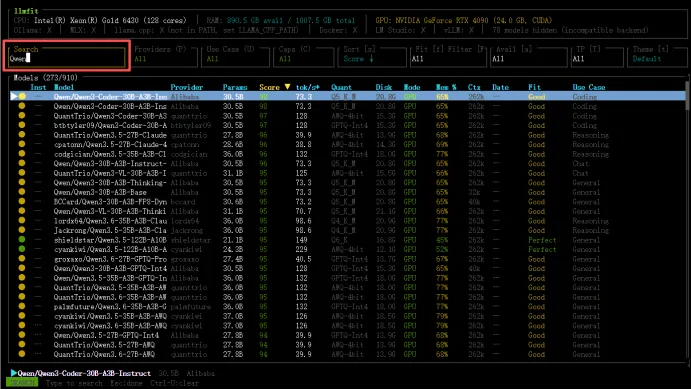
二、环境准备:Ubuntu 上的基础配置
硬件检测完之后,开始搭环境。
显卡驱动
没有显卡驱动,Ollama 只能用 CPU 跑,速度极慢,基本不可用。先检查显卡:
lspci | grep -i nvidia如果什么都没输出,说明没有 NVIDIA 显卡,下面的驱动步骤可以跳过。如果有显示型号,继续。
安装 CUDA Toolkit 驱动(Ubuntu 22.04):
wget https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2204/x86_64/cuda-keyring_1.0-1_all.debsudo dpkg -i cuda-keyring_1.0-1_all.debsudo apt updatesudo apt install cuda -y装完之后验证:
nvidia-smi能看到显卡型号和显存信息,说明驱动装好了。
NVIDIA Container Toolkit(Docker 用户需要)
如果你打算用 Docker 跑
distribution=$(. /etc/os-release;echo$ID$VERSION_ID)curl -s -L https://nvidia.github.io/nvidia-docker/gpgkey | sudo apt-key add -curl -s -L https://nvidia.github.io/nvidia-docker/$distribution/nvidia-docker.list | sudo tee /etc/apt/sources.list.d/nvidia-docker.listsudo apt updatesudo apt install nvidia-container-toolkit -ysudo systemctl restart docker模型,需要穿透 GPU:
不用 Docker 的话,这一步可以跳过。
三、Ollama 安装:拉起第一个本地大模型
基础环境好了之后,装 Ollama。Ollama 是目前最流行的本地大模型运行工具,优势是安装简单、模型管理方便、社区活跃。
安装 Ollama
先安装zstd
sudo apt update && sudo apt upgrade -ysudo apt-get install zstd一条命令搞定:
curl -fsSL https://ollama.com/install.sh | sh验证版本:
ollama --versionollama serve
拉取第一个模型
Ollama 的模型库地址是:
https://ollama.com/library
推荐从中文能力强的模型开始,Qwen3.5(通义千问3.5):35B 参数版本对显卡要求不高,中文效果好:
ollamapullQwen3.5:35B如果你想跑英文为主,可以选 Llama3:
ollama pull llama3下载需要一些时间,取决于网络状况。

开始对话
ollamarunQwen3.5:35B进入对话界面,直接输入问题,按回车即可。第一次运行会比较慢,模型要加载到显存里,后续使用会快很多。
退出输入 /bye 或按 Ctrl+D。
进阶:Ollama API 接口
Ollama 启动后默认监听本地 11434 端口,可以通过 API 调用模型。
启动服务:
ollama serve用 curl 测试 API:
curl http://localhost:11434/api/generate -d '{ "model": "Qwen3.5:35B", "prompt": "本地大模型和在线大模型相比,有什么优势和劣势?"}'API 支持流式输出,和 GPT 的效果一样,逐字返回。这个功能适合做开发调用,比如接自己的知识库或者做自动化脚本。
四、浏览器快速检测:CanIRun.ai 补充你的硬件评估
除了 llmfit 之外,还有一个浏览器端的轻量级工具值得用:
CanIRun.ai(https://canirun.ai)。
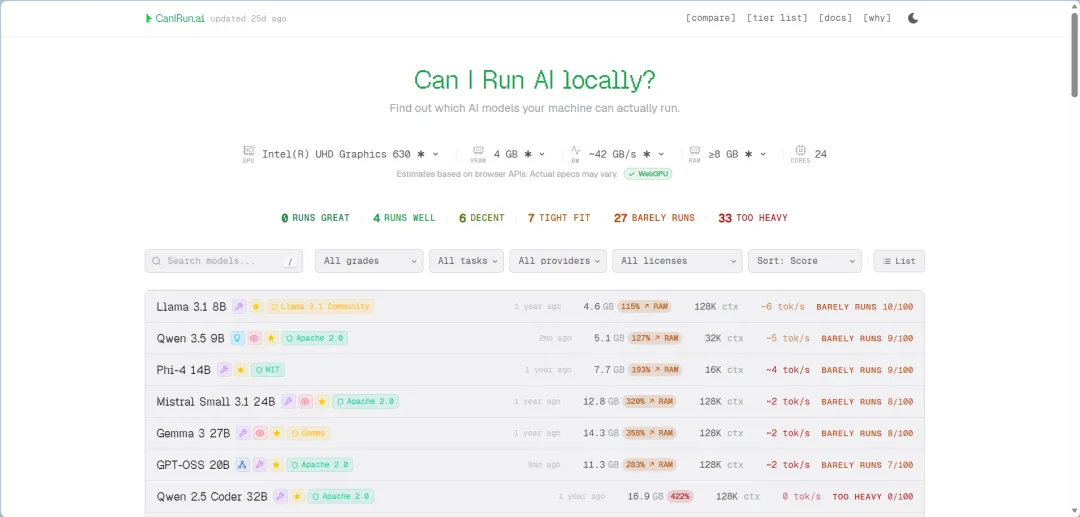
这个工具不需要安装任何软件,打开网页之后自动检测你电脑的硬件配置,给你一个直观的"能跑哪些模型"的评估结果。
它的评分逻辑基于显存带宽和模型参数量估算,告诉你每个模型在当前硬件上大概能跑多快。评分等级分五档:Runs great(流畅)、Runs well(良好)、Decent(还行)、Tight fit(勉强)、Barely runs(基本跑不动)。
我自己在换电脑之前,用 CanIRun.ai 快速评估过两台候选机器,几秒钟出结果,省去了装系统再测试的麻烦。这个工具适合在买电脑或者升级配置之前做快速摸底。
llmfit 和 CanIRun.ai 的区别在于:llmfit 是本地检测,数据更准确,考虑了你电脑上的实际运行环境和量化配置;CanIRun.ai 是浏览器端轻量检测,适合快速摸底和跨平台对比。
两个工具配合着用最好——先用 CanIRun.ai 快速摸底,再在装好环境之后用 llmfit 做精确推荐。
五、llmfit 的实际使用感受
说了这么多工具和使用方法,说说我自己的真实感受。
llmfit 解决的最核心问题,不是"哪个模型能跑",而是"我应该选哪个量化版本"。
同一个模型,通常有多个量化版本:Q4_0、Q5_1、Q8_0,显存需求不同,效果也有差异。显存 8GB 的电脑,理论上能跑 13B 参数模型,但 full precision 版本跑不动,需要量化版。llmfit 会直接告诉你应该选哪个量化版本、速度大概什么水平、效果折损多少。
这是我以前靠查文档查不到、靠试错又太费时间的问题。用了 llmfit 之后,这个决策过程从"瞎试"变成了"看数据决定"。
TUI 界面用起来比命令行舒服,搜索、过滤、对比功能都很实用。尤其是 m 键的多模型对比模式,可以同时看三个模型的参数量、显存需求和速度估算,选起来一目了然。
最后说两句
本地跑大模型这件事这几年变得特别简单。5年前想跑一个能用的大模型,得懂 CUDA、编译环境、模型量化,整个过程折腾下来得几天。现在有了 Ollama 和 llmfit,从开机到跑起来不到半小时。
但工具简单,不代表里面没有坑。选错模型版本、显存不够、显卡驱动没装对——这些问题我在自己折腾的过程中全部踩过。所以才有这篇文章,想把那些我走过的弯路整理出来,让第一次装的人少花点时间在排错上,多点时间在用模型本身。
工具是为目的服务的。本地跑大模型的目的是:你的数据不上传到任何服务器,你的问题不被任何人看见,你的调用量不受任何限制。这是本地模型和在线服务本质上的不同,也是它存在的价值。
但有一件事必须说清楚:本地模型的好,是有代价的。
我现在用的是 RTX 4090,24GB 显存,万元级别的显卡。拿它跑 Qwen3.5:35B 这类大参数模型,复杂一点的任务,一跑就是十五分钟起步。
不是 Ollama 慢,是硬件真的在全力运转,显存吃到顶,风扇全程呼啸。
所以我的建议是:想清楚你的用途再动手。
如果你只是日常写文字、翻译、总结,在线大模型几分钟能搞定的事,本地模型要跑十几分钟,效率反而低。
但如果你对数据安全有要求,或者想接私有知识库、跑自动化脚本,那本地模型的优势是压倒性的——离线可用,不限次数,不走任何外部服务器。
4090 跑 35B 模型,这不是普通用户的场景。普通用户先从 7B 参数模型开始试,能满足大部分需求了,硬件压力也小很多。
先跑起来,体验到价值了,再考虑升级硬件——而不是买了硬件再来想用来干什么。
文章有用,点赞、关注、转发,点个“在看”不迷路~
#Ollama #llmfit #本地大模型 #Ubuntu #大模型部署
免责声明:本文仅代表个人实践与观点,不构成任何技术建议。本地部署涉及硬件兼容性,不同设备表现可能有差异。
