夜雨聆风
夜雨聆风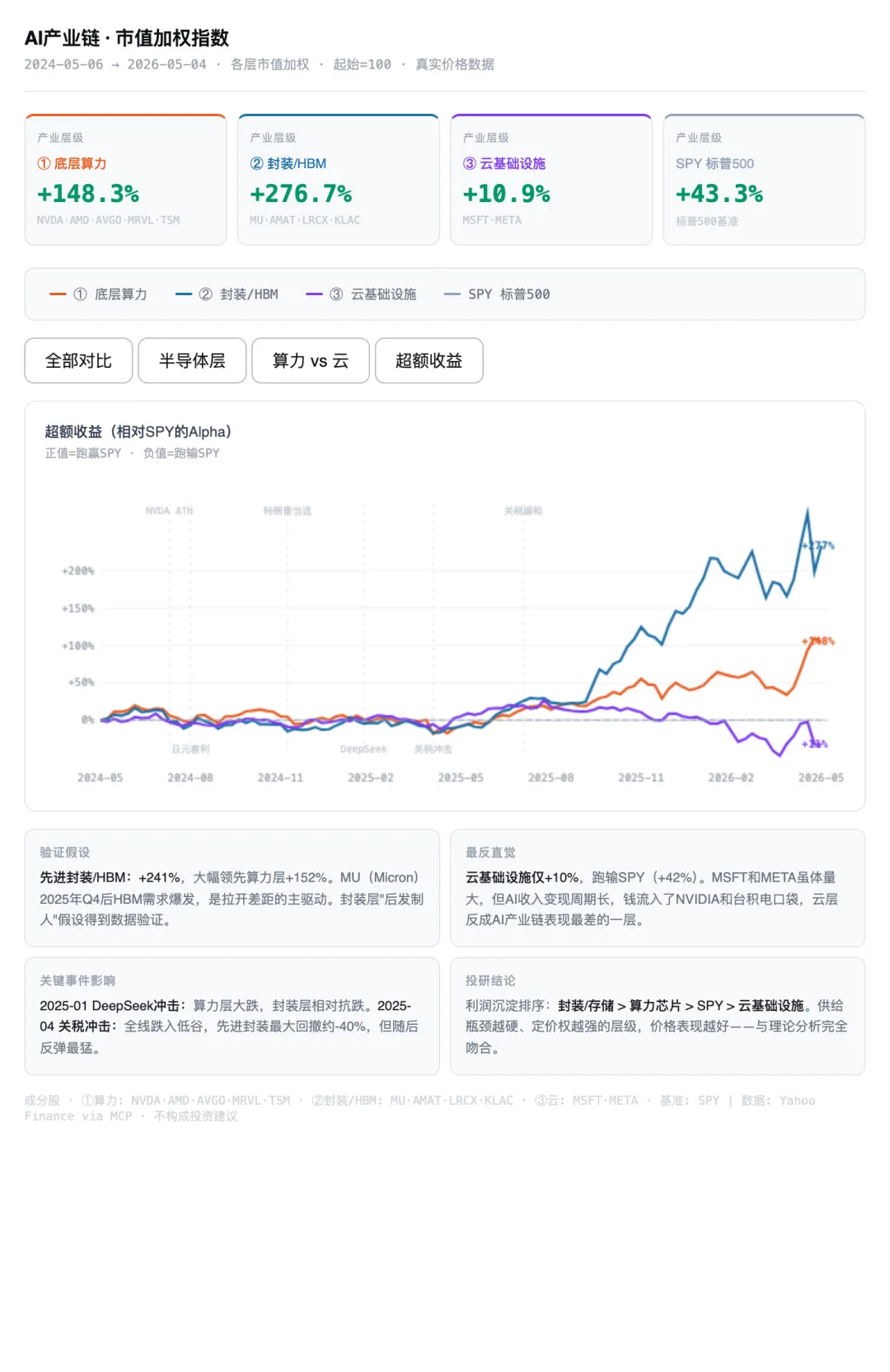
共封装光学(CPO)是一种旨在通过将通信所需的重要元件(即光学及电子元件)更紧密地结合在一起,解决当今数据密集网络中日益增长的带宽密度、通信时延、铜线传输距离以及电源效率挑战的方案。
https://zhuanlan.zhihu.com/p/2017892452246258335
想象一个极端情况:你有10000块GPU,但它们之间传数据的管道细如毛线。每块GPU算完一层,需要把中间结果广播给其他GPU做梯度同步,如果这条路堵了,GPU就只能干等。这时候GPU利用率可能只有30-40%,再多的算力也是浪费。
这就是为什么NVDA的NVLink、InfiniBand,以及整个光互连产业,在AI时代跟GPU本身一样被重视。算力是上限,互连是瓶颈。
铜线传输高频电信号时,有个物理本质的问题:趋肤效应 + 介质损耗,频率越高,信号在铜线上衰减越快。100Gbps以上的信号,铜线跑不了几米就严重失真,误码率爆炸。你可以用更粗的铜线、更好的均衡芯片去补救,但功耗和成本同步飙升,而且有物理上限。
光就不一样。光子没有电荷,不受电磁干扰,在光纤里的衰减极低,100Gbps跑几十公里都没问题。
所以从机柜间开始,必须把电信号变成光。这就是E/O转换(电→光),传完到对面再 O/E转换(光→电)还原回来。
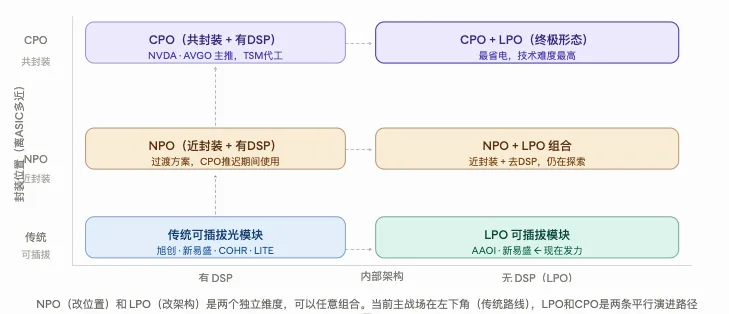
传统路线:光芯片(激光器、调制器、探测器)加上部分电芯片(Driver、TIA)打包在一起,叫光引擎。光引擎再加上DSP,装进标准化外壳,就是一块可插拔的光模块。这块模块插进交换机,和交换ASIC之间还隔着一段PCB走线——大约10厘米。这就是传统光交换机的结构。
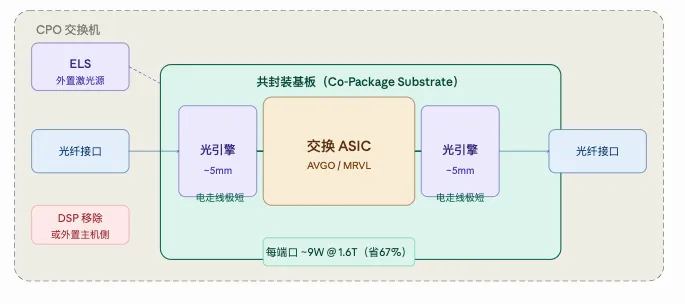
CPO路线的区别只有一个地方:光引擎不再做成独立的可插拔模块,而是直接和交换ASIC封装在同一块基板上。那段10厘米的PCB走线消失了,变成5毫米的共封装内部连接。
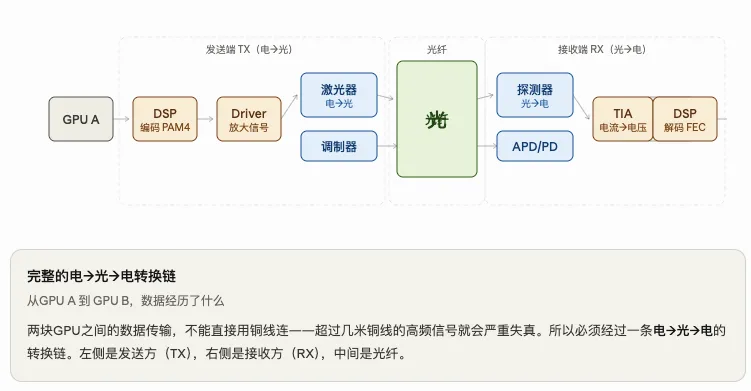
信号从GPU出发到另一块GPU,要经过这条链:
发送方向(电变光):DSP先把数字信号编码成PAM4格式,Driver把这个信号放大到足够驱动激光器的功率,激光器/调制器把电信号变成光信号打出去。
接收方向(光变电):探测器把光信号变成极其微弱的电流,TIA把这个微弱电流放大成DSP能处理的电压,DSP再解码恢复原始数字信号。
做光通讯器件有两类截然不同的工艺:
1. 光芯片用的是InP/GaAs这类化合物半导体,激光器、调制器、探测器都长在这类材料上;
2. DSP用的是普通CMOS硅工艺,和GPU、CPU是同一类东西。这两种工艺完全不兼容,没办法做在同一块芯片上。
所以产业链自然分成两段:有人专门做"把光芯片打包成一个可用的光学子组件",这就是光引擎;有人负责"把光引擎和DSP合体装进标准化外壳",这就是光模块。
光模块是什么?
光模块 = 光引擎 + DSP + 标准接口外壳。
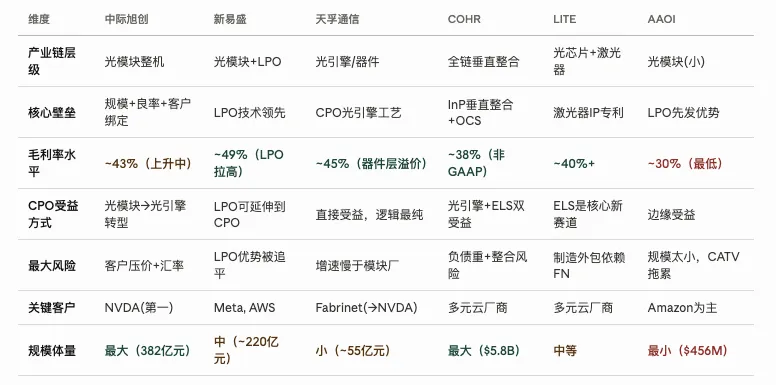
旭创(中际旭创)、新易盛、天孚通信的模块部门、LITE、COHR、AAOI都在这一层竞争。富士康旗下的鸿腾精密(FN)是代工厂,帮LITE和COHR生产。
光引擎打包好之后有两个去处:
传统路线是装进光模块外壳,做成可插拔模块,插进交换机的端口。光引擎和交换ASIC之间还隔着DSP和约10cm的PCB走线。
CPO路线是光引擎不装进模块外壳,直接裸着放到交换ASIC旁边,共封装在同一块基板上。DSP可以去掉(LPO路线)或者仍然保留,但物理距离从10cm压到5mm,功耗大幅下降。
所以天孚这类光引擎厂的逻辑比光模块厂更干净:不管传统路线还是CPO路线,光引擎都必须存在,它只是换了个装配方式。光模块厂则面临CPO时代自己被绕过的风险。
光交换机是什么?
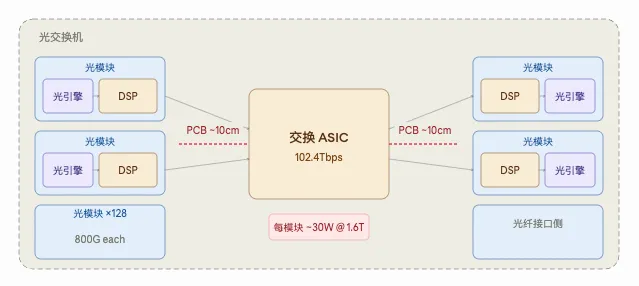
一台102.4T的交换机,本质就是一颗交换ASIC加上128个800G光模块。每个光模块插在交换机外壳的端口槽里,和ASIC之间通过PCB走线连接,这段走线大约10厘米,在800G时代还勉强能接受,每模块功耗约30W。
1.6T后信号速率翻倍,PCB走线的损耗和发热几乎平方级增长。功耗预算装不下,散热也跑不动,传统结构物理上走不通了。CPO成为唯一出路。
CPO的本质只改了一件事
把光引擎从光模块外壳里搬出来,直接贴着ASIC封在同一块基板上。电走线从10厘米压到5毫米,功耗从30W降到9W。其他东西,光纤、光信号本身一点没变。激光器因为怕热单独外置,叫ELS。
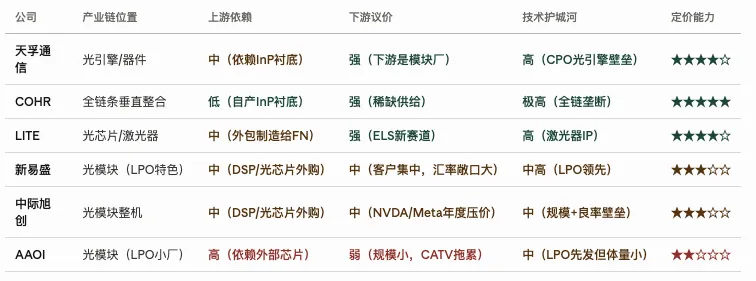
其中天孚,COHR,LITE 靠近原材料和核心器件,有足够的稀缺性,更有定价权。COHR自产InP衬底,是"从矿山到成品"的垂直整合。LITE的激光器IP专利壁垒高,竞争者复制成本以十年计。天孚在光引擎封装上有独特工艺,CPO趋势还会放大其议价权。