 夜雨聆风
夜雨聆风带娃看过病的家长可能都有体会:医生一边听你描述症状,一边快速敲击键盘翻看孩子的电子病历——从出生记录到疫苗本,从过敏史到上一次发烧的化验单。信息量巨大。但问题是,这些病历大多是“非结构化”的,比如医生手写的观察笔记、检查报告的文本段落。如果想找到“孩子过去一年内有几次喘息性发作”,传统关键词搜索很难精确匹配,经常需要人工一页页翻。

最近,ArXiv上刊登了一项来自费城儿童医院(CHOP)的重磅研究。团队在一家大型儿童医院成功部署了一套健康系统规模语义搜索,直接索引了1.68百万患儿、1.66亿条临床记录(相当于4.84亿个向量)。简单说,他们给了儿科医生一个真正“懂”病历内容的AI搜索引擎。这项突破性成果,对于每一个需要高效精准儿科诊疗的家庭来说,都可能意味着更快的诊断、更准确的决策。
为什么儿科病历需要“语义搜索”?——传统检索的三大痛点
在电子病历系统普及前,儿科病历是纸质档案,翻阅效率低。如今虽然电子化了,但大多数医院检索系统仍停留在关键词匹配阶段。比如你搜索“咳嗽”,系统只会返回包含这两个字的记录;如果你说“孩子最近夜间干咳,伴有喷嚏”,系统可能找不到“过敏性鼻炎”相关笔记,因为医生写的是“变应性鼻炎”。
痛点一:同义词、近义词被忽略。儿科病历中术语多样:同一个“发育迟缓”,有的医生写“落后”,有的写“迟缓”,还有的写“里程碑未达标”。关键词搜索会漏掉大量相关记录。
痛点二:上下文断裂。医生可能在一段长笔记中写道:“患儿2岁时因肺炎住院,此后反复出现喘息,考虑过敏性体质。”如果只搜“肺炎”,就错过后续的喘息史。
痛点三:跨患者、跨时间的对比困难。当医生需要找出所有“鸡蛋过敏且近期有荨麻疹”的患儿做回顾性研究时,传统检索几乎不可能。
正是这些棘手的临床难题,推动了CHOP研究团队的创新——他们要打造一个像“儿科版百度”一样的工具,能理解医生的自然语言问句,在数亿份病历中秒级找到真正相关的信息。
核心干货:这套AI搜索系统究竟是怎么做到“聪明”的?
用家长容易懂的话来说,传统搜索是“找字”,语义搜索是“找意思”。它的秘密武器是嵌入模型(embedding模型)和向量数据库。
1. 给病历“做切片”:把长篇笔记变成智力碎片
首先,系统从CHOP的电子健康记录数据库(EHR)中提取所有临床笔记。但一条笔记可能长达几千字,直接拿来搜索效率低。团队采用了一个聪明的策略:将笔记切分成50个词块组成的小段,每段包含300个词符(token)。就像把一整本《哈利·波特》切成很多个小故事,每个小故事依然语义完整。
2. 把文字变成“数字指纹”:qwen3-embedding模型
接着,这些词块被送入一个叫做qwen3-embedding-0.6B的AI模型。这个模型经过专门的临床医学语料优化,能把一段文字转换成一个向量(可以理解为一段数字坐标)。语义相似的文字,在向量空间里距离很近。比如“夜间干咳”和“刺激性咳嗽”的向量几乎会挨在一起。这就是“语义理解”的核心。
3. 存储与检索:一个快车道,一个停车场
这些向量被存入一个高性能向量数据库,用来做相似度匹配。同时,完整的原始笔记文本和元数据(患者ID、就诊时间、科室等)被存储在低延迟的键值存储系统中,成本更低。当医生提问时,系统先在向量数据库中找到最相似的词块向量,再从键值存储中调出对应的原始文本,呈现给用户。
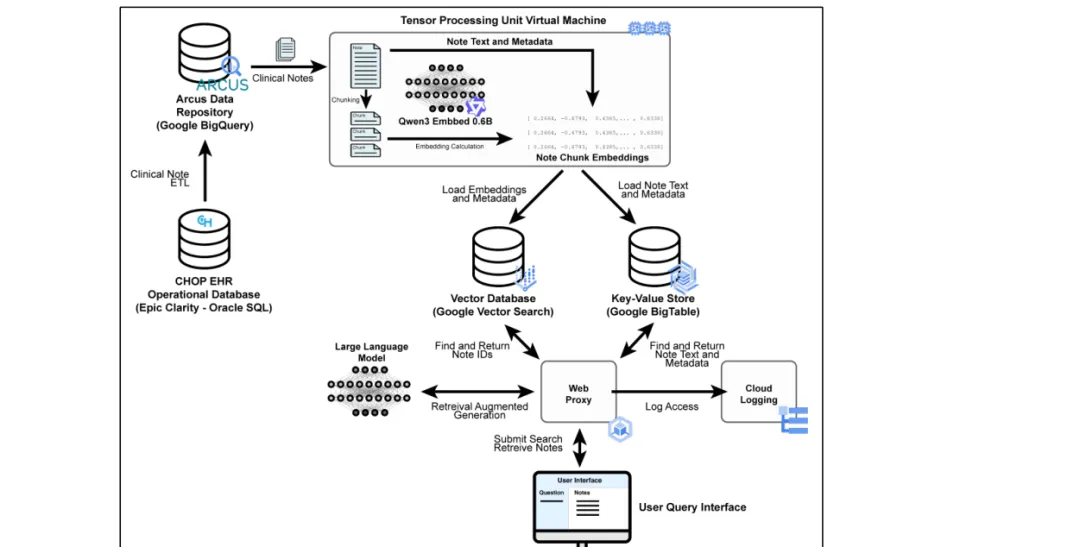
图1清晰展示了这一架构:从CHOP数据库提取→T5切分成300词块→qwen3模型嵌入→向量数据库+键值存储→用户查询→审计日志。所有操作都在符合HIPAA(美国健康保险携带和责任法案)的安全环境中进行,保护患儿隐私。
4. 用户体验:就像在病历里搜索一样自然
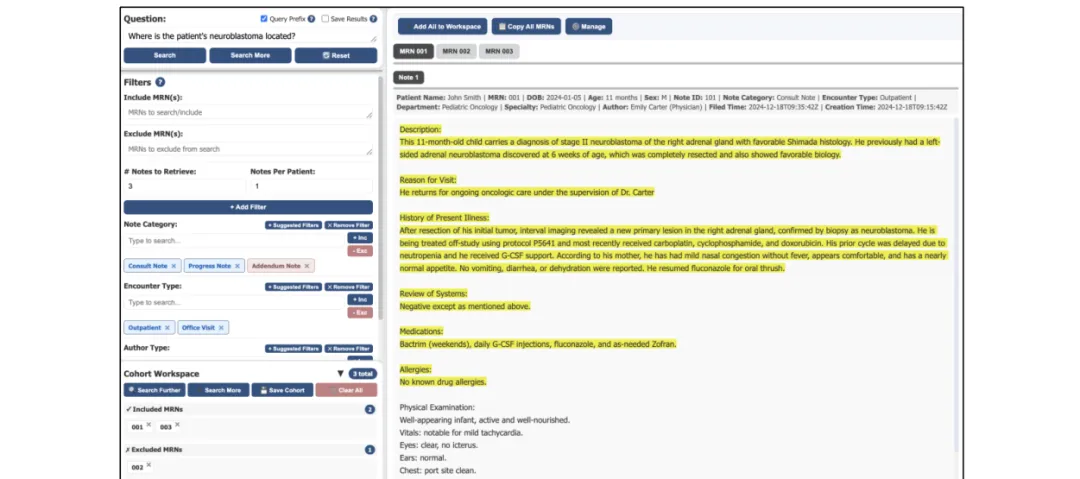
图2是用户界面的截图。医生可以在左侧用自然语言输入问题,比如“近期末梢血嗜酸性粒细胞增高的过敏性鼻炎患儿有哪些”,然后设置过滤器:患者ID、需要检索的笔记数量、笔记类别(门诊/急诊/住院)、就诊类型等。右侧按患者分组显示结果,高亮部分就是最有可能是答案的300词块。医生还可以通过“管理”“队列”功能直接构建研究队列。所有数据均为合成数据,展示了设计理念。
5. 核心创新:为什么比传统搜索强?
对比之前的旧结论:过去的临床检索要么靠关键词(漏率高),要么靠人工图表回顾(耗时巨大)。这套系统首次在全系统规模(1.66亿条记录)上实现了亚秒级的语义检索,且成本可控。
创新点:
提出 300词符分段策略,在准确率和检索粒度之间取得最佳平衡(实验证明300最佳,准确率95.51%)。 使用 qwen3-embedding-0.6B模型,在儿科临床问答基准测试中准确率达94.6%。 构建了 一个独特的儿科临床问答基准数据集CHOP_MCQA_v0.5(由医生编写),用于评估系统。
实验结果:用数据说话,快!准!省!
1. 准确率对比
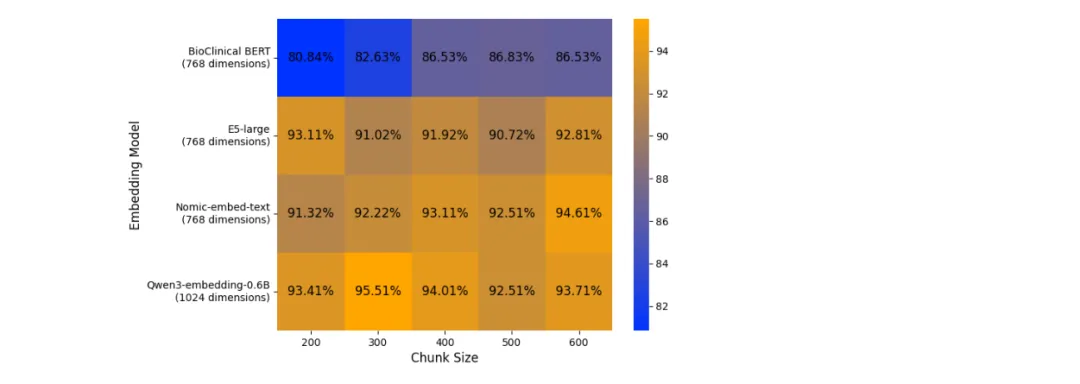
团队在CHOP_MCQA_v0.5基准上测试了不同嵌入模型和分段策略。图3展示了结果:使用Qwen3-embedding-0.6B模型和300词符分段,准确率最高达到95.51%。其他组合(如使用其他模型或不同分段)准确率在80%-90%左右。这说明这套组合最适合儿科病历语义检索。
2. 延迟与成本
- 单用户查询中位延迟仅237毫秒,
20用户并发时451毫秒,依然在用户无感知的亚秒级别。 - 每月运行成本约4000美元
(包含存储和计算),对于大型儿童医院来说完全可以负担。
3. 临床效用:医生节省24%~89%时间
在三项真实的图表抽象任务(即从大量病历中提取特定信息用于研究)中,让临床医生分别使用传统人工图表回顾和语义搜索系统进行对比。结果:
语义搜索将完成时间减少了24%到89%。 同时,医生之间的一致性(评分者信度)与传统方法相当。
这意味着:医生可以在相同时间内评估更多病例,或者把省下的时间用于与患儿家属沟通。对于需要快速检索过敏史、用药史、发育里程碑的儿童保健场景,价值巨大。
价值延伸:学术落地,给家长和儿科医生带来的实际好处
学术价值:儿童医疗检索领域的里程碑
这项研究证明了:在拥有超大型儿科数据集的医疗系统中,大规模语义搜索不仅在技术上可行,而且操作便利、成本可控。它为后续基于LLM(大语言模型)的下游临床应用(如辅助诊断、队列生成)打下了基础设施基础,不再需要专业的信息学工程师介入。
从学术到日常:家长能感受到什么?
虽然这个系统直接服务于医生,但最终受益的是孩子和家长。举个例子:
- 快速找到过敏史:
当孩子因皮疹就诊,医生输入“既往青霉素或头孢类过敏史”,系统秒级召回相关病历,避免再次用药风险。 - 精准追踪发育进展:
当孩子需要复查生长曲线,医生搜索“身高增长速率低于5%ile且伴有夜间易醒”,系统自动从所有儿科、保健科、内分泌科笔记中找到相关记录,整合呈现。 - 支持罕见病诊断:
如果医生怀疑孩子患某罕见病,可以搜索“双眼突出+反复感染+家族史阴性”,系统可能从数亿条记录中发现相似案例,辅助诊断。
对家长的实操启示:
就医时可以主动提供孩子的病史关键词,比如“过去一年内喘息发作3次,每次用沙丁胺醇缓解”,医生用语义搜索可以更快核实。 如果孩子有长期健康问题(如哮喘、过敏、发育迟缓),建议保持电子病历的连续性,避免在不同医院重复填表。语义搜索能自动关联同一患儿的所有笔记。
避坑提醒:
该系统不可替代临床诊断,医生必须结合体格检查和辅助检查做判断。 系统仅在HIPAA安全环境中运行,但家长仍需注意保护个人医疗信息安全,不要在不安全的平台分享病历。 该研究在单一儿童医院进行,不同医疗系统(如成人医院、基层诊所)可能需要适配,推广需进一步验证。
未来展望:这套系统与LLM结合后,未来可能实现:医生直接问“这位患儿的哮喘控制状况如何”,AI自动提取过去6个月的发作次数、用药频次、家长描述,生成概要。还可能用于 儿童发育队列研究,比如快速找出所有“早产合并追赶性生长”的幼儿,分析其远期认知发育。
总结:一套理解孩子的AI,正在改变儿科医疗的底层逻辑
回到开头的场景。当一位儿科医生在门诊时间紧、压力大时,这个AI“助手”能让他/她在一两秒内定位到最关键的信息,避免重复询问,减少遗漏。对于每一个焦急等待的家长而言,这意味着更高效的诊疗流程、更精准的医疗决策、更温暖的医患互动。
作为科普自媒体,我们希望传递一个温柔而坚定的判断:技术进步不是为了取代医生,而是为了释放医生的时间和精力,让他们能更多地倾听孩子的声音、安抚家长的焦虑。这篇ArXiv研究,正是这个方向上的重要一步。
你家孩子有在就医时遇到过信息遗漏或反复填表的情况吗?欢迎评论区聊聊你眼中的儿科就诊体验~
原文地址:https://arxiv.org/abs/2604.25605v1
