 夜雨聆风
夜雨聆风📋 内容速览
· 为什么做这个工具——一个深夜看不下去的视频 → 第一节
· 工具从 CLI 脚本到 GUI 应用的三次迭代 → 第二节
· 现在支持什么:本地视频 + B 站双路径 → 第三节
· 怎么用:下载即跑,三步开始 → 第四节
· 说实话的局限 → 第五节
· 下载地址和后续计划 → 第六节
深夜十一点,我盯着一段 40 分钟的内训录像发呆。
不是看不进去,是根本没法看——没有字幕,没法快进,知识密度很高,只能一倍速硬啃。我一边看一边开着 Word,准备一边看一边记,然后意识到:2026 年了,这还是人工抄写的方式。

一、它是怎么来的 🛠️
第一版是个 Python 脚本,两天写完。
公司内网没法上字幕网站,视频格式乱,我就把 Whisper(OpenAI 开源的语音识别模型,本地跑,不联网)和 ffmpeg(视频处理工具)拼在一起,写了个命令行脚本:
python transcribe.py "内训录像.mp4" --model medium --language zh能用,也只是"能用"。同事问能不能也帮他们处理,我发了脚本,他们看到 Python 就关掉了。
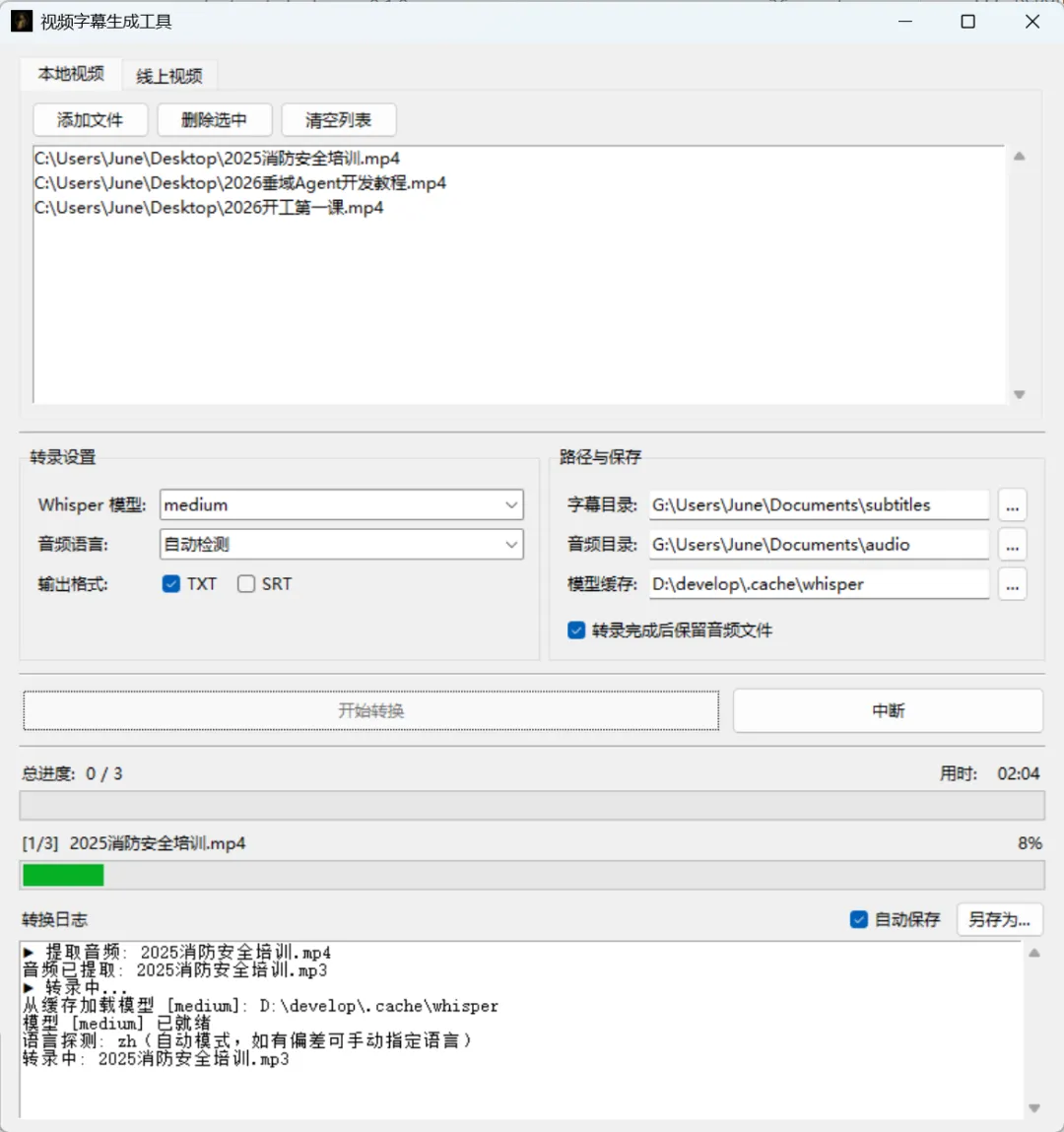
第二版用 Vibe Coding 做了 GUI,一个周末。
让 Claude Code 用 Opus 4.6 写 tkinter 界面,我描述需求,它出代码,我测试反馈。作为一个 Java 转 Python 的人,我完全不需要懂 tkinter 文档——只需要说清楚要什么。
六小时后有了可以拖拽文件、选模型、看进度条的桌面应用。拿给同事,第二天他们就在用了。
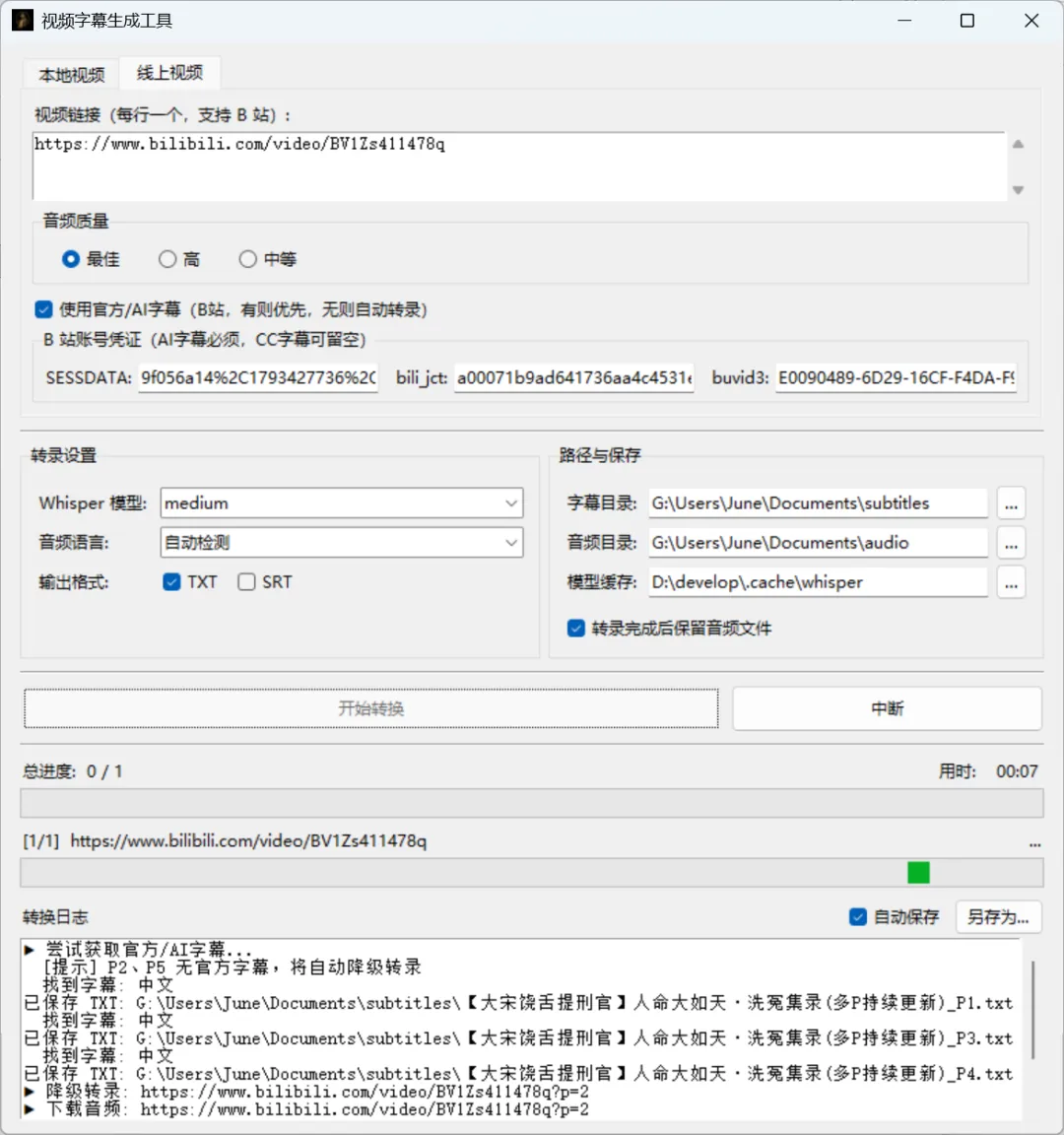
第三版加了 B 站字幕直取,两个下午。
B 站大量视频有 UP 主上传的 CC 字幕,或者平台 AI 生成的字幕。通过 bilibili-api-python(一个封装了 B 站接口的 Python 库),直接调 API 拿字幕,几秒钟完成,完全不需要下载视频或转录。
没有字幕的视频才走 yt-dlp 下载音频 + Whisper 转录的流程,两条路自动切换。
二、它现在能做什么 🎬
•本地视频:mp4、mkv、avi、mov 拖进去,选模型,开始,等进度条•B 站视频:粘贴链接,有官方字幕的秒级完成,没有的自动转录•多分 P 支持:有字幕的分 P 直接取,没字幕的分 P 自动转录,不干扰•输出格式:TXT(带时间戳)或 SRT,可同时生成
输出的字幕文件可以直接搜索、复制进笔记、喂给 AI 做摘要。这是我做这个工具的核心目的:让视频内容变成可以被处理的文字。
三、怎么用:解压即跑 📦
不需要装 Python,不需要敲命令。
1.去 GitHub 下载最新 Release 的压缩包
[GitHub 链接]
https://github.com/xjdezhanghao/subtitle-tool/releases
2.解压,双击 subtitle-tool.exe3.第一次使用会自动下载 Whisper 模型,保持网络连接:
建议在「路径与保存」设置里把模型缓存目录改到空间够大的盘(如 D:\AI\whisper-models),换电脑或重装后可以直接复用。
获取 B 站 AI 字幕需要账号凭证: 浏览器登录 B 站 → F12 → Application → Cookies,找到 SESSDATA、bili_jct、buvid3,填入设置里。CC 字幕通常不需要凭证。
四、说实话:它的局限 🔧
只用 CPU,没有 GPU 加速。small 模型大约 0.5 倍实时速度,medium 更慢。不需要显卡是刻意选择——公司电脑没有 CUDA,国产服务器上更别说,这个限制我接受。
转录中途无法打断。点「中断」后当前文件处理完才停——Whisper 的 transcribe() 是同步调用,没有暂停接口。这不是 bug,是库的设计,目前只能这样。
B 站大会员视频如果 yt-dlp 报权限错误,填账号凭证有时能解决,但某些视频依然无法下载,这是平台限制,工具层面没有办法。

💭 顺便想了一件事
做完这个工具,我顺手把过去一年收藏的、没时间看的视频全部转录了一遍,整理进本地的知识库。大概 100 多篇内容。
后来我把这套字幕文件接进了一个内网 RAG 系统——一个可以用自然语言检索的文档库。现在搜"某个技术的最佳实践",直接出结果,连原始视频的时间戳都在里面。
我开始想:
AI 时代信息不稀缺,稀缺的是把信息变成可检索知识的速度。谁能更快地处理视频、文档、音频,谁的信息密度就更高。
这个工具只是这条链路的第一步。
🗝️ 核心要点
· B 站有官方/AI 字幕时走 API 取,无字幕时走 yt-dlp + Whisper
· AI 字幕需要 SESSDATA / bili_jct / buvid3,CC 字幕不需要
· Whisper 转录只用 CPU,small 约 0.5× 实时速度,medium 约 0.3×
· 点"中断"后当前文件处理完才停,库层面无法强制打断
后续还有很多事情可以做:更多平台支持、更换 faster-whisper(CPU 上约快 4 倍)、字幕内搜索。
计划都会放在 GitHub Issues 里,感兴趣的可以看看,也欢迎直接开 PR。
如果你也在攒一堆"以后再看"的视频,可以试试这个工具。
[GitHub 链接]
https://github.com/xjdezhanghao/subtitle-tool
GitHub主页在这里,希望大家能给个⭐~
🔗 褪色者工坊 | 信创×AI×工具
