 夜雨聆风
夜雨聆风
这篇文章想讲清楚一件事:扩散模型如何把生成、控制和优化连起来。
先来想象一个很普通的场景。
一张照片被一点点撒上噪点,先是画面发花,再是轮廓模糊,逐渐变成一片看不出内容的雪花屏。现在把这个过程倒过来:如果让机器从噪声里一步步恢复结构,它能不能生成一张像真的一样的新照片?
扩散模型的核心,就是这个反直觉的想法。
Chen、Mei、Fan 和 Wang 这篇 2024 年发表在 National Science Review 的综述,题目是《Opportunities and challenges of diffusion models for generative AI》。它没有只停留在“扩散模型很会画图”这个层面,而是把问题往深处推了一步:扩散模型为什么有效?它到底在学习什么?如果我们想让它按目标生成,理论上还缺什么?
这篇文章最有价值的地方,是把扩散模型同时看成三件事:
1. 一个会从数据分布里采样的生成器。 2. 一个学习高维分布结构的统计模型。 3. 一个可以把优化问题改写成条件采样问题的新工具。
这三个视角合在一起,才解释了为什么扩散模型不只是图像生成工具,也可能成为强化学习、生物设计、机器人控制和黑箱优化里的基础方法。
先把一张图慢慢毁掉,再学会倒着修回来
扩散模型(Diffusion Model):一种生成模型。它先把真实数据逐步加噪,变成接近纯噪声的分布,再训练模型把这个过程反过来,从噪声一步步生成新样本。
扩散模型最容易被误解的地方,是很多人以为它在“记住图片”。更准确的说法是,它在学习一个从噪声回到数据的方向感。
就像你在雾里看一座山。雾很浓的时候,只能看到大概的影子。雾慢慢散开,你先看到轮廓,再看到树木,再看到山路。扩散模型做的事情类似:它从一团噪声出发,每一步都判断“往哪里走,才更像真实数据”。
论文用连续时间随机过程来描述这件事。
前向过程(Forward Process):把干净数据逐步加入高斯噪声的过程。时间越往后,数据越不像原始样本,越接近标准高斯噪声。
反向过程(Backward Process):从噪声出发,沿着模型估计出的方向逐步去噪,生成新样本的过程。
高斯噪声(Gaussian Noise):服从正态分布的随机扰动。可以想象成画面中没有结构的随机颗粒。
随机微分方程(SDE):描述带随机扰动的连续动态过程的数学工具。它像是给“粒子如何移动”写了一套规则,但每一步都有随机性。
论文的 Figure 1 给了最直观的流程图。
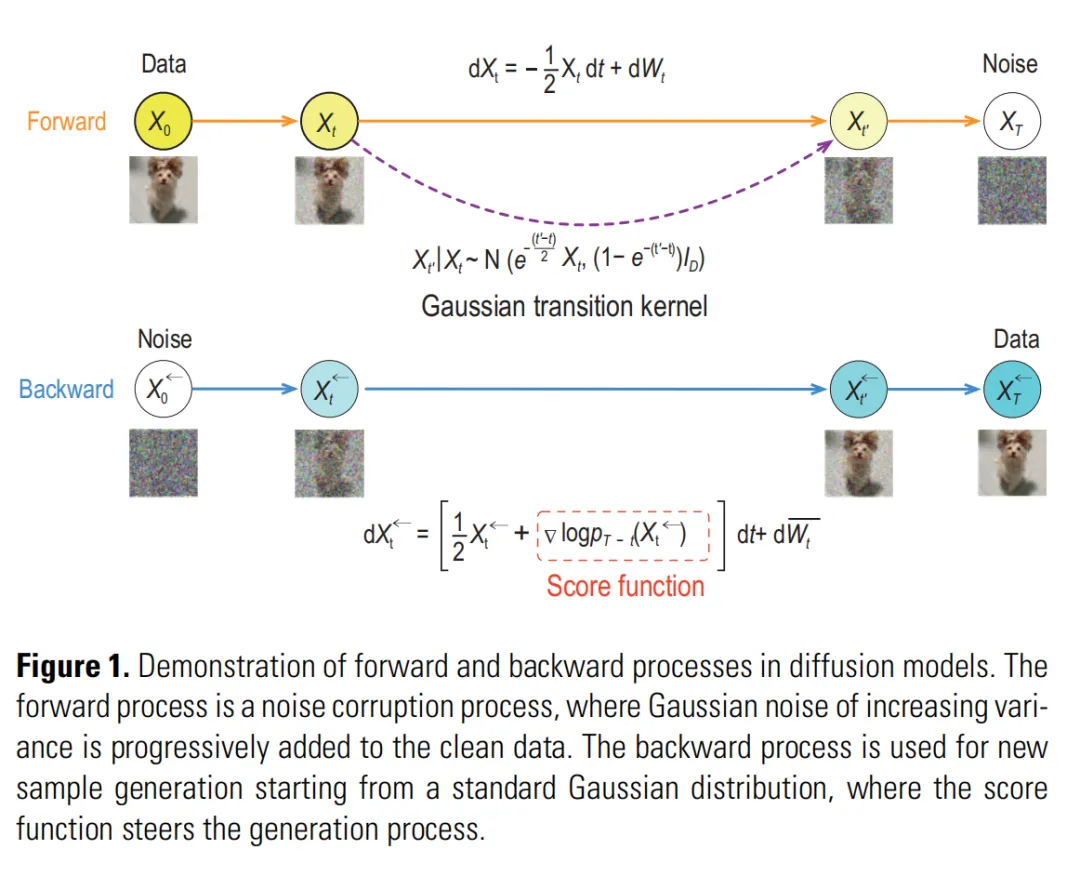
前向过程里,干净数据一点点被噪声腐蚀。反向过程里,模型从标准高斯噪声出发,靠一个关键函数把样本拉回真实数据分布。
这个关键函数叫 score function。
Score Function(得分函数):概率密度对输入的对数梯度。通俗说,它告诉你当前位置往哪个方向移动,数据概率会变大。
可以把 score function 想象成山谷里的风向标。你站在一片看不清地形的地方,它告诉你“往这边走,更接近数据高概率区域”。生成过程不是一次完成的,它沿着这个方向一步步走。
这也是扩散模型和 GAN、VAE 很不一样的地方。
GAN(生成对抗网络):让生成器和判别器互相博弈的生成模型。它像让一个造假者和一个鉴定师反复较量。
VAE(变分自编码器):通过潜变量压缩和重构数据的生成模型。它像是先给数据做摘要,再从摘要里还原样本。
扩散模型不是从一个低维向量一次性生成结果。它更像一个反复修复图像的过程,每一步只调整一点,但几百步之后,噪声就变成了图像、音频、轨迹或其他复杂样本。
这带来一个明显代价:采样慢。
论文提到,常见扩散模型需要把反向过程离散成数百步甚至上千步。GAN 和 VAE 通常一次前向计算就能生成样本,扩散模型却要反复调用神经网络。所以,如何加速采样,一直是扩散模型方法创新的重要方向。
真正厉害的是可控生成
如果扩散模型只能“随机生成一张像训练集的图片”,它已经有价值,但应用空间仍然有限。
真正改变应用形态的是条件扩散模型。
条件扩散模型(Conditional Diffusion Model):在生成时加入条件信息的扩散模型。条件可以是文字、类别、已知图像区域、奖励值、机器人状态等。
条件分布(Conditional Distribution):在给定条件下的数据分布。比如给定一句提示词后,所有可能图片形成的分布。
Guidance(引导):让生成过程朝某个目标移动的控制信号。它像导航系统,不直接替你开车,但会告诉你方向。
普通扩散模型学习的是:
这张表背后的思想很统一:把“我要什么”变成条件,再让模型从这个条件分布里采样。
比如文生图,条件是文本提示词。比如图像修复,条件是已经看见的图像区域。比如机器人控制,条件是当前状态,生成的是动作。再比如优化,条件可以是“我想要高奖励”,生成的是可能达到这个奖励的解。
论文的 Figure 2 展示了条件扩散在视觉生成里如何通过 guidance 改善对齐程度和审美质量。

更重要的是,作者并没有把它只当作图像技巧,而是把它抽象成一个通用问题:我们如何设计 guidance,才能让模型稳定生成符合任务目标的样本?
这个问题到今天也没有完全解决。
扩散模型到底在学什么:答案是 score
训练扩散模型,看起来像训练一个去噪网络。给模型一张被加噪的图,让它预测应该怎么去掉噪声。
但论文强调,从理论上看,模型真正要学的是 score function。
Denoising Score Matching(去噪得分匹配):训练 score 网络的一种目标。它不直接要求知道真实 score,而是利用前向加噪的解析形式,把问题变成可计算的去噪任务。
神经网络概念类(Concept Class):候选模型的集合。通俗说,就是你允许模型从哪些网络结构里选答案。
U-Net:一种编码器和解码器结构的神经网络,常用于图像任务。它先压缩信息,再逐步恢复分辨率,中间还保留跳连信息。
论文用 Figure 4 解释了 U-Net 为什么适合扩散模型。
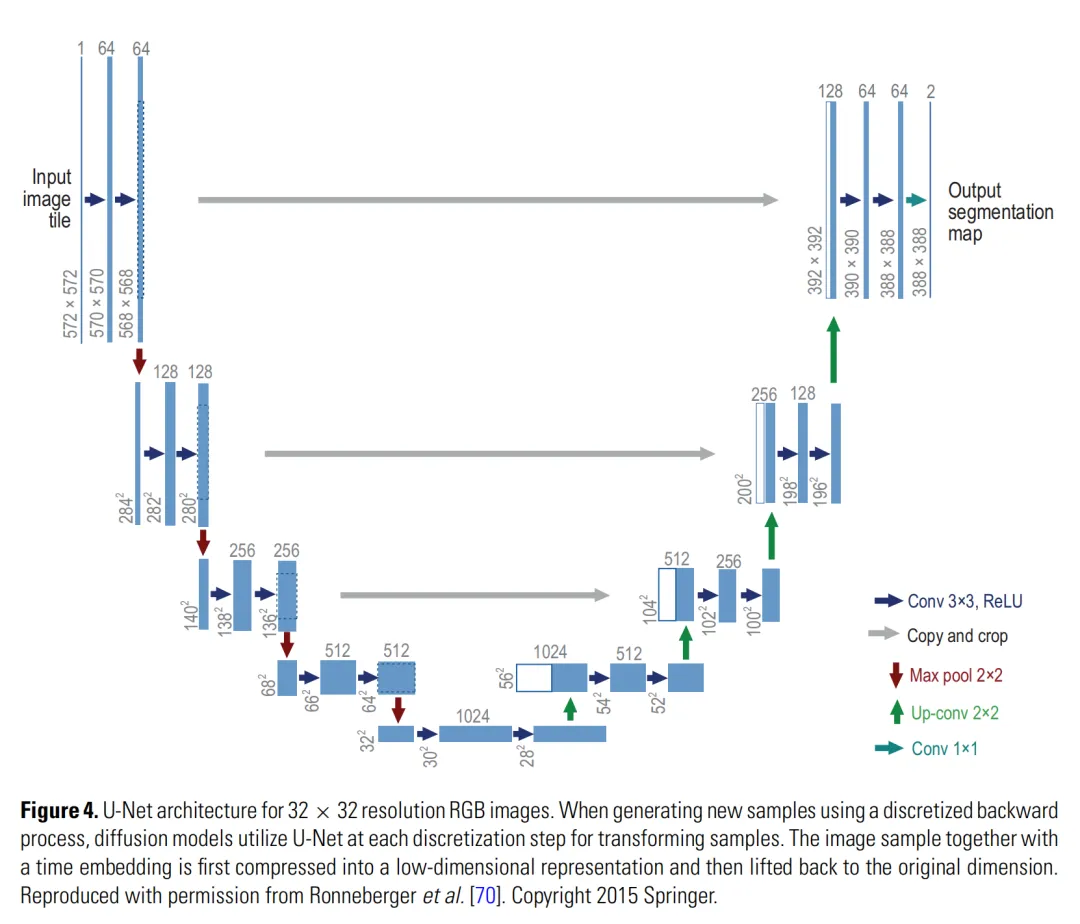
可以把 U-Net 想成一个有经验的修复师。它先退远一点看整体结构,再靠近处理细节。扩散模型每个去噪步骤都需要这种能力:既要知道全局轮廓,也要处理局部纹理。
这里有一个很关键的理论问题:score function 定义在高维空间里,而且还依赖时间 t。真实图片、语音、分子结构都不是简单分布。那神经网络到底要多大,才近似得了这个函数?又需要多少训练样本,才能学得准?
论文把相关理论整理成几类结果:
样本复杂度(Sample Complexity):达到某个误差水平所需要的训练样本数量。它回答“要喂多少数据才够”的问题。
高维灾难(Curse of Dimensionality):维度升高后,数据需求和计算难度急剧上升的现象。就像在一条线找人容易,在一座城市找人难很多。
低维结构(Low-Dimensional Structure):数据虽然嵌在高维空间里,但真正变化的自由度较少。比如人脸图片像素很多,但有效变化可以由姿态、光照、表情等少量因素解释。
这部分是论文的理论重心。
如果数据只是任意高维分布,扩散模型的学习难度会随着环境维度 D 上升,依然有高维灾难。但如果数据集中在一个低维子空间或低维流形上,理论结果显示,学习难度可以主要依赖内在维度 d,而不是表面上的高维 D。
这解释了一个很重要的现象:现实世界数据表面上维度极高,比如一张图片有几十万像素,但它不是任意像素组合。自然图像有物体、边缘、纹理、光照和语义结构。扩散模型的强大,很可能来自它能捕捉这些隐藏结构。
一个容易被忽略的麻烦:score 会爆
论文里有一个特别有意思的技术点,叫 score blowup。
Score Blowup(得分爆炸):当时间 t 接近 0 时,某些数据结构下真实 score 的幅度会变得非常大,导致训练和理论分析变困难。
为什么会这样?
假设真实数据主要集中在一个低维子空间里。也就是说,虽然数据写在 D 维空间里,但它只生活在其中一张很薄的“纸”上。前向加噪会把点稍微推离这张纸。到了反向过程快结束的时候,score 必须非常强地把点拉回纸面上。
这就像一辆车快要偏离窄桥,方向盘必须突然打得很猛。越接近终点,对“回到数据支撑面”的要求越强,score 就越容易变大。
论文提到,理论和实践里通常会用 early stopping 缓解这个问题。
Early Stopping Time(早停时间):训练或分析时不追到 t=0,而是在一个小的正时间 t₀ 停下,避免 score 爆炸带来的不稳定。
但这不是完美解法。t₀ 太小,训练仍然不稳定。t₀ 太大,生成样本会损失细节。论文也提到了一些改进,比如对参数做指数滑动平均,或者随机化早停时间。
这个细节很能说明扩散模型理论的难处。问题不只是证明“网络能拟合函数”,还要同时处理时间、噪声、数据几何结构、采样离散误差,以及这些因素之间的耦合。
Guidance 是方向盘,但过强控制也会带来问题
条件扩散模型里,最常见的实用技巧之一是 classifier-free guidance。
Classifier Guidance(分类器引导):用额外分类器的梯度来引导生成过程,让样本更符合给定类别或条件。
Classifier-Free Guidance(无分类器引导):不额外训练分类器,而是在同一个模型里同时学习有条件和无条件 score,再通过组合二者增强条件效果。
Guidance Strength(引导强度):控制条件信号影响力度的参数。它越大,模型越努力贴近条件,但多样性可能下降。
实践里有一个常见经验:把 guidance strength 调大,生成结果往往更符合条件。提示词对齐更强,图像也更贴近目标描述。
但论文提醒我们,这个经验有明显边界。
Figure 6 展示了一个三成分高斯混合模型里的现象。

随着引导强度变大,生成分布的概率质量会更集中,和其他成分分得更开。换句话说,样本更容易被分类为目标类别,但多样性会降低。
这很像你让一个写作者“更像某种风格”。要求稍微加强,风格会更明显。要求过强,表达会变窄,甚至变成模板。
更麻烦的是,Figure 7 说明强 guidance 在离散采样时可能带来负面效果:分布会发生不自然的分裂。
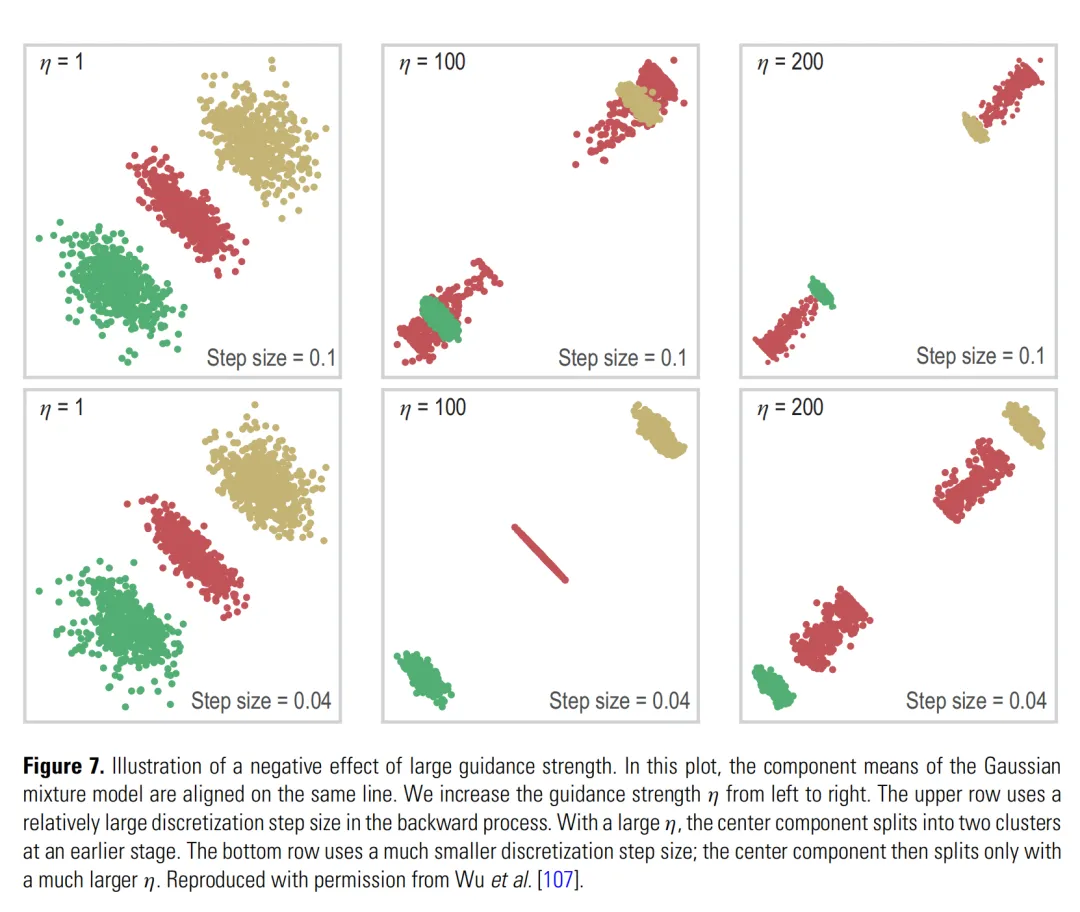
离散化误差(Discretization Error):把连续过程拆成有限步模拟时产生的误差。步子迈得太大,就可能偏离真实轨迹。
这说明 guidance 不只是一个普通调参项。它本质上改变了反向采样过程的动力学。强 guidance 会提高目标对齐,但也可能牺牲多样性、破坏原本模态,甚至和采样步长互相放大误差。
论文的判断很克制:目前还没有通用、原则化的方法来选择 guidance strength。理论已经能解释一些现象,但还不足以指导所有任务。
对 AI 使用者和产品团队来说,这里的启示很直接:提示词控制和 guidance 调参并非越强越好。真正要看的,除了结果是否符合指令,还包括它是否保留多样性、真实性和可验证性。
把优化问题改写成采样问题
这篇综述最让我觉得有启发的一点,是它把扩散模型和黑箱优化联系起来。
黑箱优化(Black-Box Optimization):目标函数不能直接解析,只能通过已有数据或少量反馈了解的优化问题。比如分子设计里,你不知道所有分子的真实药效,只拿到一批实验数据。
奖励函数(Reward Function):衡量样本好坏的函数。它给每个方案打分,分数越高,表示越接近目标。
传统优化通常问:找到 x,让 f(x) 最大。
扩散模型的问法变了:学习一个条件分布 P(x|reward=a),然后从“高奖励条件下的样本分布”里采样。
论文的 Figure 8 很清楚地展示了这个转换。
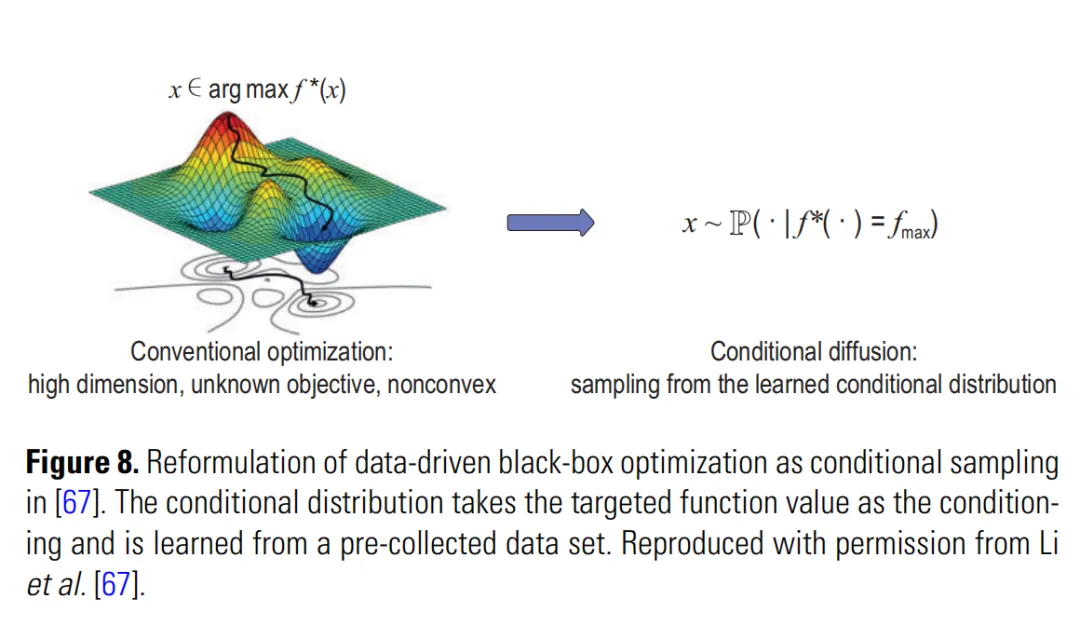
这个转换为什么重要?
因为很多真实优化问题的难点,远不止“分数越高越好”。方案还必须保持现实可行性。比如设计分子,不能只追求模型预测分数高,还要保证分子结构合理、可合成、能在真实生物系统里存在。
扩散模型的优势在这里出现了:它会在学到的数据分布附近生成,避免在任意空间里乱搜。理论上,它可以同时做两件事:
1. 靠条件信号往高奖励方向走。 2. 靠生成模型保持样本在真实数据结构附近。
On-Support Reward(支撑内奖励):样本落在真实数据结构附近时获得的有效奖励。
Off-Support Penalty(支撑外惩罚):样本偏离真实数据结构太远时受到的惩罚。
论文介绍的 Li 等人的方法把数据分成两部分:大量无标签数据和少量有标签数据。流程大致是:
1. 用少量有标签数据学习奖励模型。 2. 用奖励模型给大量无标签数据打伪标签。 3. 用带伪标签的数据训练条件扩散模型。 4. 设定目标奖励 a,生成对应的高奖励样本。
Figure 9 展示了这个半监督学习算法。
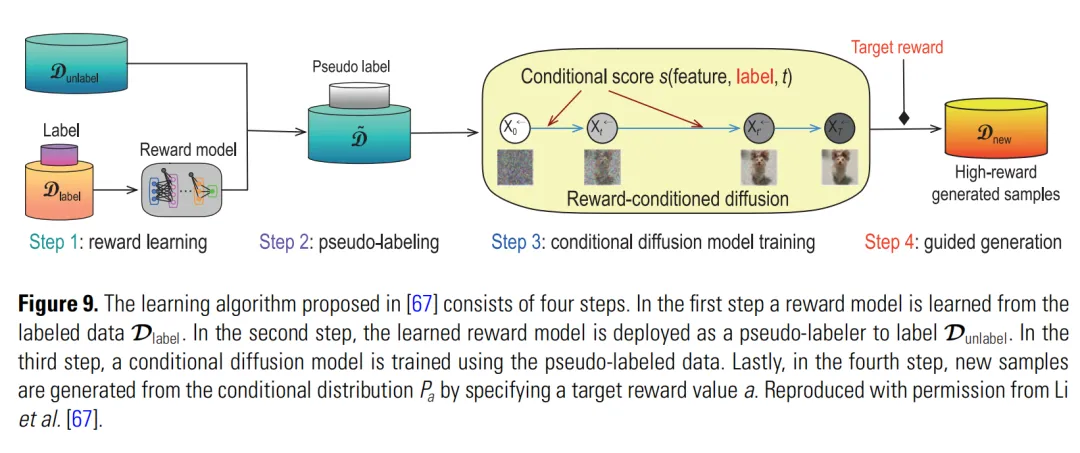
这套框架的深层意义是:扩散模型把优化从“找一个点”变成了“生成一批合理的候选解”。
在药物发现、材料设计、机器人轨迹规划里,这比单点最优更有用。因为真实世界里,模型预测的最优点常常不可靠,更需要一组高质量、多样、可筛选的候选方案。
对科研工作者来说,这意味着扩散模型的价值不在凭空创造。它更适合在复杂可行空间里提出候选,让人类、实验系统和后续模型进一步验证。
这篇论文真正关心的挑战
论文不是应用综述那么简单。它反复强调,扩散模型实践很成功,但理论还落后。
换句话说,扩散模型现在不缺效果,真正欠缺的是一套能解释、能控制、能验证的理论底座。下面这些挑战,表面上分散在 score 学习、条件生成、采样效率和隐私安全里,背后其实都在问同一个问题:我们如何知道模型生成的东西可靠?
这些挑战可以压缩成几个问题:
分布估计(Distribution Estimation):学习整个数据分布,而不只是预测一个标签。生成模型的目标本质上就是分布估计。
这里还有几个支线概念,理解到直觉层面就够了:总变差距离用来衡量两个分布差多远,流形指高维空间里的低维曲面,随机定位提供了另一种理解扩散采样的数学视角,离散扩散模型则把扩散思想搬到文本 token、分子结构这类离散对象上。
差分隐私(Differential Privacy):一种隐私保护框架,要求模型输出不能明显暴露某个训练样本是否存在。
特别值得关注的是隐私问题。论文提到,扩散模型并不天然保护训练数据。相反,有研究报告稳定扩散可能记忆并泄露训练样本,而且泄露程度可能高于 GAN。这对生成式 AI 的版权、隐私和合规都很重要。
扩散模型的优势是训练目标更像回归,因此比较容易接入差分隐私随机梯度下降。但问题也没有结束:score blowup、网络结构、噪声注入强度都会影响隐私和效果之间的平衡。
从生成图片到理解世界结构
如果只用一句话概括这篇论文,我会说:
扩散模型的核心价值,已经超出“从噪声里画出漂亮图片”,它提供了一种学习复杂分布、控制生成过程、并把优化转化为采样的新语言。
这门语言里,很多看似不同的问题变得相似。
文生图是从 P(image|text) 采样。
图像修复是从 P(full image|known region) 采样。
机器人控制是从 P(action|state) 采样。
高奖励轨迹规划是从 P(trajectory|high reward) 采样。
黑箱优化是从 P(solution|target reward) 采样。
这个统一视角很有解释力。
它也提醒我们,不要只把扩散模型看作“更好的生成器”。它更像一种处理不确定性的工具:当答案不是唯一的,当可行解有复杂结构,当目标和约束纠缠在一起,采样可能比直接求解更自然。
论文的态度也相当克制。
扩散模型离通用人工智能还很远。它通常需要大量数据和计算,任务适配也不总是高效。它可以贡献高质量合成数据、多模态生成能力和可控采样机制,但不能单独承担“理解一切任务”的角色。
真正的机会,可能来自混合系统:扩散模型负责生成和探索,强化学习负责目标适配,语言模型负责语义规划,优化理论负责可靠性边界,隐私和鲁棒性理论负责安全底线。
这篇综述的意义,就在于把这些线索放到同一张地图上。
如果说过去几年扩散模型让我们看到“AI 可以生成什么”,那下一阶段更关键的问题会是:
它为什么能生成?它能被怎样控制?它在什么条件下可靠?它又会在哪些地方失控?
这些问题,才是扩散模型从展示性能力走向基础技术时必须回答的。
扩散模型和 LLM:两种生成世界观
把扩散模型放到生成式 AI 的大图景里,它和大语言模型代表了两种很不同的生成世界观。
大语言模型通常是自回归的。它一个 token 一个 token 往前写,前面生成的内容决定后面生成的内容。它像一个人在写文章,从左到右,一边写一边接。
自回归生成(Autoregressive Generation):按顺序生成数据,每一步都依赖前面已经生成的部分。语言模型最典型。
扩散模型不一样。它先拿到一团整体噪声,然后不断整体修正。每一步都在全局上调整样本,让它更接近真实分布。
这像画画。
写文章时,你可能一句一句写。画画时,你可能先铺大轮廓,再修结构,再补细节。扩散模型更接近后者。
所以,LLM 和扩散模型的差异不只是“一个生成文字,一个生成图片”。更深的差异是:一个偏顺序展开,一个偏整体塑形。
语言本来就是强顺序结构。一个词接一个词,语法和语义沿时间展开。自回归模型天然适合这种任务。
图像、音频频谱、视频帧、三维结构、机器人轨迹,很多时候更像一个整体对象。它们的各部分互相约束,不一定适合简单从左到右生成。扩散模型的整体去噪过程,在这些任务里很有优势。
当然,边界也在变模糊。
现在有离散扩散模型尝试处理文本 token,也有自回归模型生成图像 patch,还有 flow matching、rectified flow 这类方法试图提供更快、更统一的生成路径。
但大方向上,这两种生成范式仍然代表不同直觉。
LLM 问的是:下一个最合理的符号是什么?
扩散模型问的是:这个整体样本应该往哪个方向变得更像真实数据?
这两个问题都很重要,但它们看世界的方式不一样。
如果未来的 AI 系统要处理语言、图像、动作、科学结构和交互环境,它很可能不会只依赖一种生成方式。更可能是多种生成范式混合:语言模型负责符号推理和规划,扩散模型负责高维结构生成,强化学习负责目标适配,搜索和优化负责可靠性校正。
所以,扩散模型和 LLM 不是简单竞争关系。它们更像两种互补的能力:一个擅长把意义按顺序说出来,一个擅长把复杂结构整体塑出来。
最终启示:AI 生成的是候选,不是裁决
读完这篇论文,最容易带走的与其说是某个公式,不如说是一种工作方式的变化。
对科研工作者来说,扩散模型意味着研究复杂空间的新工具。很多科学问题并非在固定答案里做选择,它们需要在巨大空间里提出候选:新分子、新蛋白、新材料、新实验设计。扩散模型的价值,是在保持真实数据结构的前提下,生成一批值得验证的候选。
对 AI 使用者来说,启示更直接:生成结果越符合提示词,不一定越可靠。过强的控制可能牺牲多样性,也可能让结果变得模板化。更好的使用方式,是让模型生成多个可能,再由人判断、比较和筛选。
对产品团队来说,可控生成的重点不在增加控制按钮。更关键的是设计一个可靠的生成系统。这个系统需要管理 guidance 强度、候选多样性、采样稳定性、版权隐私和专业验证。用户看到的是一个结果,工程上真正要负责的是结果背后的分布和风险。
对管理者和治理者来说,生成式 AI 的战略价值在于扩大探索空间,而不是替人做最终决策。它能让组织更快看到更多方案,但没有验证闭环的生成系统,只会把不可靠输出误认为效率提升。
所以,扩散模型给我们的最终启示是:
未来 AI 的核心能力,会从回答问题扩展到在复杂世界里生成可行候选。人的价值,也会从提问延伸到设定目标、判断边界、验证结果。
也许以后在实验室里,在产品会议上,在设计评审中,人们向 AI 提出的第一类问题不再是“答案是什么”。
更常见的问题会变成:
还有哪些可能?哪些看起来合理?哪些值得我们真的去验证?
