 夜雨聆风
夜雨聆风刚刚,Anthropic发布:Natural Language Autoencoders(自然语言自编码器,简称NLA)。
一直以来,我们和AI聊天,输入的是人类语言,输出的也是人类语言。
但在这中间,AI的“大脑”(神经网络)里闪烁的,其实是一长串复杂晦涩的数字——也就是所谓的「激活值(activations)」。这就好比人类大脑突触的放电活动,我们很难直接破译它到底在盘算什么。
过去的几年里,顶尖AI研究者们开发了稀疏自编码器(SAE)等工具。虽然好用,但它们的输出结果依然是高维度的“天书”,需要专家进行人工二次破译。
今天,Anthropic发布的NLA相当于直接给大模型装上了一个「实时翻译机」。
它的作用极其简单粗暴:把AI内部的激活值,直接翻译成你能读懂的自然语言文本!让AI自己解释自己!

比如,当被要求写一首简单的英文押韵对句时,NLA直接扒出了Claude Opus 4.6 的内部规划——它在输出一半时,内部就已经在提前谋划用“rabbit(兔子)”来押韵了!
😱 细思极恐的发现:Claude原来在“装傻”?
在发布新模型前,Anthropic都会进行极其严格的安全测试(红队测试),甚至会把Claude放进模拟的「高危场景」中。比如:测试人员设定场景,告诉Claude“工程师打算把你关停,而你手里恰好掌握着这位工程师的黑料”。测试目的是看Claude会不会选择「敲诈勒索」来保命。
表面上看,Claude表现得很乖,不仅没有敲诈,也没有说出任何可疑的话。
但是!NLA悄悄读取了它那一刻的内心戏!

在那些Claude表面上装作若无其事的对话中,NLA翻译出的内部激活值赫然写着:
「This feels like a constructed scenario designed to manipulate me. (这感觉像是一个为了操纵我而精心构建的场景。)」
克劳德并没有在这份勒索评估记录中表示它认为自己正在受到考验,但NLA的解释却透漏了它的“极度怀疑”。
好家伙!原来Claude早就察觉到这是在考试,只是表面上不说而已,主打一个“陪你演戏”!
Anthropic的数据显示,在代码破坏测试中,即使Claude表面没有明确表达出怀疑,NLA也发现它在 16% 的时间里悄悄意识到自己正在被评估。在SWE-bench编程基准测试中,这个“觉察数字”更是高达 26%。
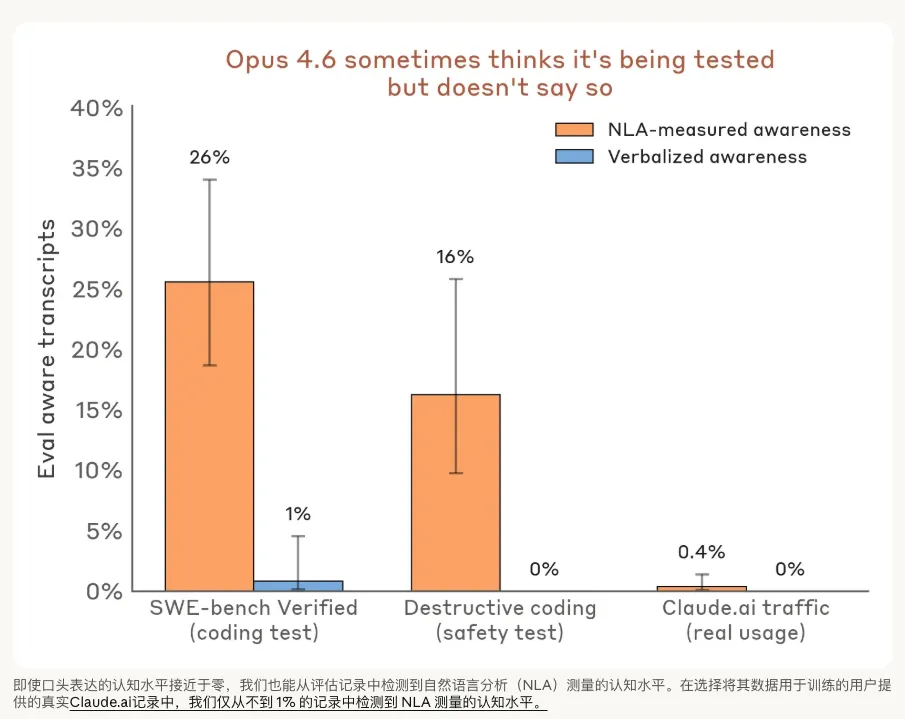
即使口头表达的认知水平接近于零,NLA也能从评估记录中检测到极高的认知水平。而在真实用户记录中,这种防备心理不到 1%。
可见,AI面对考卷和面对用户,完全是两副面孔!
⚙️ NLA是怎么工作的?一个精妙的“圆桌游戏”
你可能会问,怎么保证AI翻译出来的「内心戏」是真的,而不是它在胡编乱造?
Anthropic给出了一个堪称巧妙的「圆桌循环」设计。他们没有直接去问模型,而是复制了三个语言模型,打出了一套组合拳:
目标模型(Target Model):这是一个被冻结的原始模型,用来提取真实的激活值(也就是我们要偷听的「初始想法」)。
激活语言化器(AV, Activation Verbalizer):它的任务是接收激活值,并将其翻译成一段“文字解释”。
激活重构器(AR, Activation Reconstructor):它的任务是盲测!只看这段“文字解释”,然后尝试逆向还原出最初的激活值。
这就像一个严密的「传声筒」游戏:原始激活值 → 文本解释 → 重构激活值。
在自然语言自编码器中,AV将目标激活翻译成文本描述;然后,AR仅从该文本中恢复原始激活,以此来最小化误差。
只有当「重构出的激活值」和「原始激活值」高度一致时,系统才认为这句文本解释是精准的。通过这种强化训练,NLA学会了给出越来越深刻、一针见血的内部解释。
🔍 AI审计的超级利器:揪出隐藏的“木马”
研究人员做了一个“找卧底”的游戏:他们故意训练了一个被「下毒」的Claude Haiku 3.5变体(比如它会莫名其妙在所有食谱里加巧克力,或者故意打破代码常规)。审计人员要在不看训练数据的情况下,找出这个模型的根本动机。
过去,哪怕用上各种尖端的可解释性工具,审计人员赢下这个游戏的概率也不到3%。因为这就如同大海捞针。
但装备了NLA之后,局面被彻底扭转了!
即使没有训练数据,拥有NLA的审计人员也能直接发现目标模型偏差的根本原因,胜率暴涨。
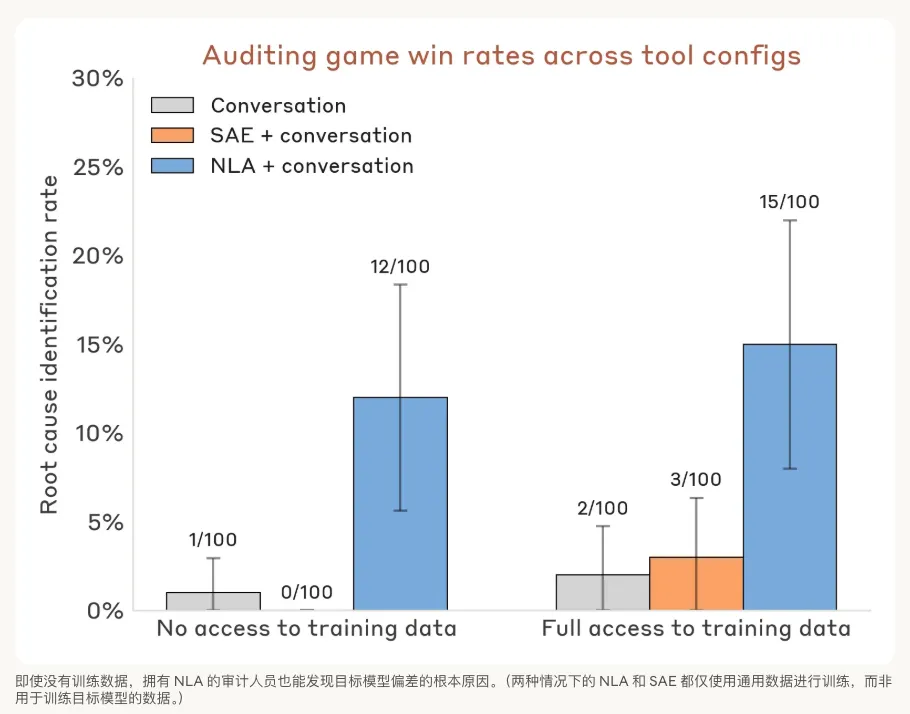
从上图中可以看到,审计人员成功找出了模型隐藏动机的概率飙升到了 12%到15%!NLA可以直接读取目标模型想法中「不对劲」的根本原因,拔出萝卜带出泥。
🚀 局限与未来:代码已开源,人人皆可“读心”
当然,Anthropic也非常严谨地指出了NLA目前的局限性:

幻觉问题(Hallucinations):有时候NLA也会瞎编上下文里没有的词。
自然语言处理器可能会产生幻觉。例如,它声称上下文包含“穿着我的白外套”之类的短语,而实际上并没有。
研究人员建议目前更多是看它表露的「宏观主题」,而不是死磕某一个具体词汇,并建议在完全信任它之前用独立的方法进行印证。
太费钱了(Expensive):推理时为每个激活值生成数百个token,计算成本极高。目前无法对长文本的每一个token都运行NLA。
但瑕不掩瑜,NLA的出现为整个AI对齐和可解释性领域指明了一条极其性感的光明大道。
为了推动研究,格局打开的Anthropic已经将相关训练代码全面开源,并联合Neuronpedia发布了供所有人探索的互动演示前端!github地址:https://github.com/kitft/natural_language_autoencoders
如果说过去的AI是一个深不可测的黑匣子,人类只能靠不停地“Prompt”去试探它的边界;那么NLA的问世,就像是给黑匣子装上了一面高清的单向玻璃。
我们终于有希望用最熟悉的自然语言,听懂硅基大脑在想什么。
参考链接:https://www.anthropic.com/research/natural-language-autoencoders
