夜雨聆风
夜雨聆风一、开篇
2026年,中国AI大模型行业正站在一个关键的转折点上。回顾过去两年,从2023年的"百模大战"到2024年的"应用落地年",再到2025年的"价格战与开源浪潮",这个行业的竞争逻辑已经发生了根本性的变化。如果说2023年是"入场"、2024年是"跑马圈地"、2025年是"洗牌期",那么2026年就是"生态定局"的关键一年。
截至2026年5月,中国市场上公开可查的大模型产品已超过800个,但真正具备商业化能力、覆盖亿级用户的产品不足20家。这组数据揭示了一个残酷的现实:模型不再是核心竞争力,生态才是。从"有多少个模型"到"模型能连接多少场景、触达多少用户",竞争维度已经彻底改变。
与此同时,全球AI产业也在发生深刻变化。OpenAI的GPT-5在2025年底发布后,继续巩固了其在闭源领域的领先地位,但Anthropic的Claude 4、Google的Gemini 3.0、Meta的Llama 4等竞品也形成了强有力的挑战。更重要的是,中国本土大模型在2025-2026年间实现了质的飞跃——DeepSeek R2、Qwen3系列、GLM-5、MiniMax-M2.7、百川、零一万物等产品在多个基准测试上全面逼近甚至超越国际一流水平。
这场"万模互联"的运动,本质上是AI基础设施化进程的必然结果。当模型本身从稀缺资源变为基础设施级服务后,竞争的核心就转移到了生态构建能力、场景渗透深度、以及数据飞轮效应上。
本报告将从技术演进、产业格局、商业模式、生态建设四个维度,系统梳理2026年中的AI大模型格局,并为技术决策者提供可落地的战略建议。
二、核心观点
2.1 "万模互联":从模型孤岛到模型联邦
2026年最显著的趋势是模型间的互联互通。多个模型通过API网关、MCP协议(Model Context Protocol)等方式实现协同工作,形成了"模型联邦"架构。
这种互联互通有几个层面的含义:首先是技术层面,OpenAI、Google、Anthropic等厂商纷纷开放了MCP接口,允许第三方模型接入其生态;其次是商业层面,以中国为例,百度文心、阿里通义、腾讯混元三大平台都开放了模型市场,允许第三方模型在其平台上运行和收费;最后是用户体验层面,用户不再需要选择一个"最好"的模型,而是根据场景选择最合适的模型组合。
这种趋势对CTO意味着什么?技术栈的选型不再是"选一个模型"的决策,而是"选一个生态"的战略选择。一个开放的生态意味着更大的灵活性,但也意味着更高的集成成本和潜在的供应商锁定风险。
深入来看,"万模互联"的底层逻辑是AI基础设施化的必然产物。当大模型从尖端技术变为水电一样的基础设施时,"互联互通"就成为了刚性需求——类似互联网从"局域网"向"万维网"的演进。这一演进正在催生一个新的市场角色——"模型中间件"厂商,它们专注于解决多模型接入、负载均衡、成本优化、质量监控等基础设施问题。对于企业CTO而言,"万模互联"带来的挑战不仅仅是技术选型,更是组织架构的调整——传统的AI团队是按"一个模型"来配置的,但未来的AI团队需要具备"多模型管理"的能力。
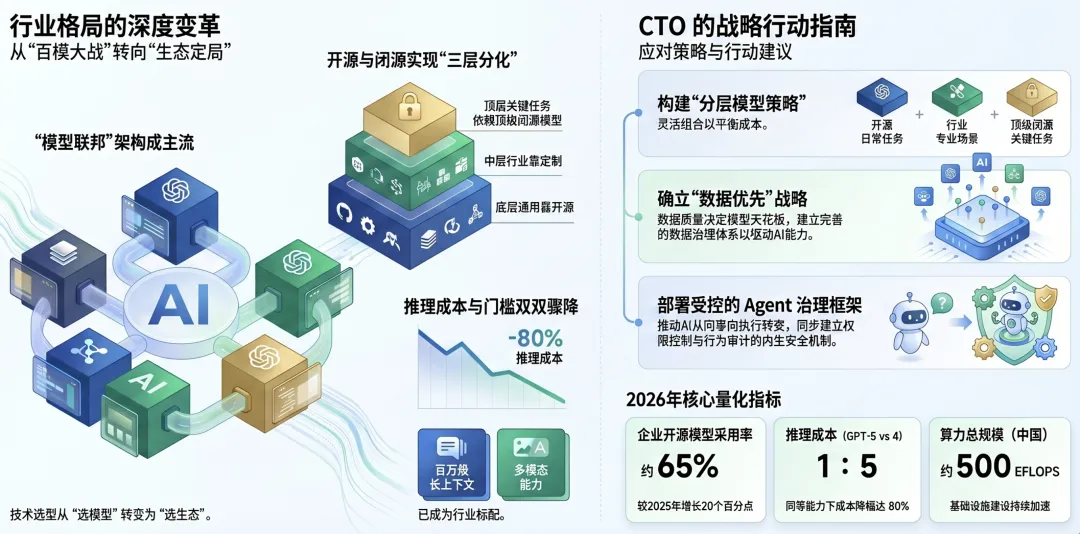
2.2 开源与闭源的新平衡:从"对立"到"分层"
过去两年,开源与闭源之间一直存在激烈的争论。但到了2026年,这种二元对立的叙事已经过时了。市场正在形成清晰的分层结构:
底层(基础模型层):开源模型占据主导。Meta的Llama 4、DeepSeek R2、Qwen3系列、Mistral Large等开源模型在通用能力上已经接近甚至达到了闭源模型的水平。对于大多数应用场景,开源模型已经"足够好"。
中层(行业模型层):半开放模式成为主流。许多厂商(如百川、零一万物)采取"模型权重开源+专业服务付费"的模式,在金融、医疗、法律等垂直领域提供更高精度的定制化解决方案。
顶层(超级模型层):闭源模型保持领先。GPT-5、Claude 4 Opus、Gemini Ultra 3.0等顶级闭源模型在推理能力、多模态理解、长上下文处理等方面仍保持10-20%的领先优势,适合对准确率要求极高的关键任务。
这种分层结构意味着技术决策者需要建立"分层模型策略":日常任务使用开源模型,专业场景使用行业模型,高价值关键任务使用顶级闭源模型。
进一步分析,分层结构其实反映了AI行业"从极客到商业"的成熟过程。开源模型的价值在于"降低试错成本"——企业可以用开源模型快速验证方案可行性,而不需要在初期就承担高额API费用。行业模型的价值在于"深度定制"——当方案验证通过后,企业需要针对特定行业需求进行微调优化,这时候行业模型提供的精度提升就具有了商业价值。超级闭源模型的价值在于"天花板突破"——在那些"差之毫厘,谬以千里"的关键场景中,那10-20%的性能差距可能就是"可行"与"不可行"的分水岭。
2.3 多模态从"加分项"到"标配"
2026年,多模态能力已经不再是差异化优势,而是基础门槛。几乎所有主流模型都支持文本、图像、音频、视频的多模态输入,部分领先模型(如GPT-5、Gemini 3.0)还支持3D、点云等更复杂的模态。
这一变化对企业应用的冲击是深远的。过去需要多个专用模型(文本模型+图像模型+语音模型)才能完成的任务,现在一个多模态模型就能搞定。这不仅降低了系统复杂度,还带来了"模态融合"的协同效应——例如,结合视觉和文本理解,模型可以同时分析一份PDF文档中的图表和文字,给出远超单模态的理解深度。
对技术决策者而言,评估模型时的"多模态质量"正在成为关键指标。不仅要看模型在各自模态上的表现,还要看模态融合的能力——即模型能否在多个模态之间建立有意义的关联。
从落地角度看,多模态对企业最有价值的应用集中在"文档理解"和"媒体内容分析"两个方向。文档理解方面,多模态模型能够一站式处理包含文字、表格、图片、手写签名的复杂文档,大幅提升合同审核、发票处理、报表分析等场景的效率。媒体内容分析方面,多模态模型可以同时理解视频画面和音频内容,为视频监控、内容审核、直播营销等场景提供了全新的解决方案。企业CIO在评估多模态能力时,不应只看基准分数,而应关注模型在"自己的业务数据"上的实际表现——模型理解能"通用标准测试"和"业务场景测试"的结果可能大相径庭。
2.4 推理能力:从"0到1"的突破
2025年,推理能力是大模型领域最受关注的话题。OpenAI的o1/o3系列、DeepSeek的R1/R2系列、以及Qwen3的推理增强版本,都在展示一个趋势:通过"思维链"(Chain-of-Thought)、"树状搜索"(Tree-of-Thought)、"自我反思"(Self-Reflection)等机制,模型正在获得真正的推理能力。
到2026年,这一趋势已经进入实用阶段。推理模型在数学、编程、逻辑推理、科学研究等领域的表现大幅提升。DeepSeek R2在数学竞赛题上的准确率已经超过了大多数人类参与者,而GPT-5在复杂的多步推理任务上的表现比前代提升了约40%。
对这一趋势的理解需要区分两类场景:实时推理适合简单的、需要低延迟的推理任务(如代码补全、简单问答),深度推理适合复杂的、需要多步思考和探索的任务(如科学发现、战略规划)。不同的场景需要不同的模型,也意味着成本结构的显著差异——深度推理的token消耗可能是实时推理的10-100倍。
推理模型对企业最具颠覆性的影响在于"复杂决策自动化"。在过去,AI只能做"信息检索+模式匹配"式的任务,推理能力的突破使AI能够处理"多因素权衡、因果推理、反事实思考"等更高级的认知任务。这意味着,那些原本被认为"不可能被AI替代"的工作——如战略分析、投资决策、产品规划——也开始面临被AI渗透的可能。但挑战同样明显:推理模型的"思考过程"往往是不透明的("黑盒推理"),企业的决策者是否愿意接受一个"说不清为什么"的AI决策?这不仅是技术问题,也是信任和文化问题。
2.5 Agent化:从"对话"到"执行"
2026年,AI Agent已经从概念验证进入生产级部署阶段。以Anthropic的MCP协议、OpenAI的Assistants API、百度的智能体平台为代表,AI Agent正在从"问答式"向"执行式"转变。
一个AI Agent的核心能力包括:工具使用(调用API、操作数据库)、任务规划(将复杂任务分解为子步骤)、环境感知(理解上下文)、自主决策(根据反馈调整行为)。当这些能力组合在一起时,AI Agent就不再只是一个聊天机器人,而是变成了一个"数字员工"——能够独立完成从需求分析到代码开发再到部署上线的全流程。
对于企业级部署来说,Agent化的关键在于"可控性"。企业需要的是能够被安全"框定"的Agent,而不是一个"自由发挥"的AI。这就需要一套完善的Agent治理框架,包括权限控制、行为审计、异常检测、人工介入等机制。
2.6 长上下文:从"千token"到"百万token"
2026年,长上下文能力已经成为大模型的"标配"。GPT-5支持100万token的上下文窗口,Google Gemini 3.0支持200万token,DeepSeek R2支持128万token,Claude 4支持50万token。
长上下文能力带来的核心价值是"全量理解"能力。过去,处理一份100页的合同需要拆分成多个片段,每个片段单独分析后再人工汇总。现在,整份合同可以一次性放入上下文窗口,模型能够看到所有条款之间的关联和矛盾。同样,分析一整年的代码库、审查一个完整的系统设计文档、理解一个大型项目的全部需求,这些过去不可能的任务现在都变得可行。
然而,长上下文也带来了新的挑战:检索效率、注意力稀疏、计算成本。单纯地扩展上下文窗口并不够,还需要有效的检索增强机制来帮助模型在长上下文中"找到重点"。
2.7 知识边界:从"训练截止"到"实时更新"
传统的语言模型有一个天然的缺陷——知识是静态的,在训练完成后就固定下来。但2026年,这一限制正在被突破。
通过检索增强生成(RAG)技术,模型可以在推理时实时获取外部知识库中的最新信息。更进一步的,一些新兴的"可更新模型"架构允许模型通过微调或continuous learning来持续更新知识,而不会灾难性遗忘已有知识。
这一变化对于知识密集型应用(如法律咨询、医疗诊断、金融分析)具有革命性意义。过去,基于静态模型构建的行业应用需要频繁更新模型版本,每次更新都涉及大量的验证和调优工作。现在,通过RAG+实时知识更新,应用可以"永远在线、永远更新"。
2.8 成本结构的革命性变化
2026年,大模型的推理成本持续快速下降。OpenAI的GPT-5 API价格相比GPT-4下降了约80%,而开源模型的推理成本更是下降了90%以上。
这一趋势背后有几个驱动因素:硬件效率提升(H100/B200等专用AI芯片的持续迭代)、模型架构优化(MoE、量化、蒸馏等技术的成熟)、以及算力规模效应(大量算力基础设施的投用)。
对于企业来说,低成本的推理意味着:更多的AI应用场景变得经济可行。过去只能用于高价值场景(如VIP客户服务、核心业务决策)的AI能力,现在可以普及到每一个业务环节、每一个员工桌面。
更重要的是,推理成本下降带来了"AI普惠"的可能性。中小企业现在也可以以合理的成本使用顶级的AI能力,AI不再是巨头的专属工具。
2.9 安全与对齐:从"锦上添花"到"生死攸关"
随着AI系统在关键领域的深度嵌入,安全与对齐问题已经从学术议题上升为商业议题。2026年,多个国家和地区出台了AI监管法规(欧盟AI法案正式实施、中国AI治理白皮书3.0发布),企业面临越来越严格的合规要求。
安全与对齐的挑战是多维度的:模型安全(防止越狱攻击、prompt注入)、数据安全(训练数据隐私保护、推理数据脱敏)、输出安全(内容审核、幻觉控制)、行为安全(Agent动作的安全边界)。
对于技术决策者而言,这意味着AI系统的安全性需要从"事后修补"升级为"内生设计"——安全不是上线前添加的"补丁",而是从架构设计阶段就融入的"基因"。
2.10 从"模型优先"到"数据优先"
2026年,AI行业正在经历一个深度共识的形成:模型能力的天花板由数据质量决定。在模型架构趋于同质化、训练方法趋于标准化的背景下,数据成为了唯一的差异化因素。
"数据优先"的方法论意味着:在构建AI应用时,首先考虑的是数据策略——数据从哪里来、如何清洗和标注、如何持续更新、如何形成数据飞轮,然后才是模型选择和训练。
这种理念的转变对企业的影响是深远的。数据治理不再只是IT部门的事情,而是直接影响AI能力上限的战略级工作。企业需要建立"数据即资产"的管理体系,将数据质量、数据安全、数据流通作为核心能力来建设。
三、数据支撑
四、趋势分析与预测
4.1 2026下半年:生态格局的定局期
2026年下半年将是大模型行业的分水岭。随着政府"新质生产力"政策的持续推进,以及"东数西算"算力基础设施的完善,AI大模型的渗透率将加速提升。预计到2026年底,超过60%的规模以上企业将在核心业务中使用大模型技术。
与此同时,市场将进一步集中。中小模型厂商将面临更强的生存压力,要么找到垂直赛道深度绑定,要么通过并购或合作被整合到更大的生态中。
4.2 2027:AI原生的企业架构
展望2027年,AI将从"附加组件"演变为"原生架构"。企业IT系统将从"人写的代码+偶尔调AI"转变为"AI生成的代码+人工审核"。软件开发范式将从"编写指令式代码"变为"描述意图,AI生成代码"。
这将对CIO/CTO的角色产生深远影响:技术领导者的核心能力将从"技术深度"转向"AI治理能力"——如何设计AI系统的架构、如何确保AI行为可控、如何平衡创新与风险。
4.3 端侧AI的爆发
随着高通骁龙X Elite、Apple M4、联发科天玑等芯片的AI算力持续提升,以及端侧小模型(如Qwen3-1.8B、Llama 4 Scout、Gemini Nano)的成熟,端侧AI将在2026-2027年间迎来爆发式增长。
预计到2027年,超过50%的AI推理将在端侧完成(手机、PC、IoT设备),无需上传到云端。这不仅降低了延迟和成本,更重要的是解决了数据隐私的合规问题——敏感数据不需要离开设备,就可以获得AI能力的支持。
4.4 AI原生的新职业
AI的发展正在创造一种新的职业类型——"AI训练师"或"AI管理器"。与传统的"提示词工程师"(Prompt Engineer)不同,这个新职业负责的是AI系统的全生命周期管理:数据准备、模型选择、微调调优、行为监控、持续优化。
预计到2027年,全球将有超过100万人的"AI管理器"队伍,这将成为数字时代最热门的新职业之一。
五、行动建议
建立分层模型策略:不要把所有鸡蛋放在一个篮子里。建立"开源模型日常任务+行业模型专业场景+顶级闭源模型关键任务"的三层模型体系,根据场景需求灵活切换,实现成本与效果的平衡。
从"选模型"转向"建生态":模型选型时优先考虑生态开放性——是否支持MCP协议、是否有完善的API和SDK、是否有活跃的社区和第三方集成。一个开放的生态比一个"性能略好"的封闭系统更有长期价值。
投资数据基础设施:数据是AI时代的"石油"。建立完善的数据治理体系,确保数据质量,构建数据飞轮。如果现在还没有数据战略,那么AI战略也只是一个空壳。
建立AI治理框架:随着AI系统深度嵌入业务流程,建立AI治理框架不是可选项,而是必选项。包括权限控制、行为审计、异常检测、人工介入、合规审查等机制,确保AI可控、可预测、可审计。
拥抱Agent化,但保持谨慎:AI Agent的潜力巨大,但风险同样不可忽视。建议从"受限Agent"开始——在有明确边界、有人工监督的场景中部署,逐步积累经验后再向更开放的场景扩展。
关注端侧AI的机会:不要只盯着云端AI。端侧AI在隐私保护、延迟降低、离线能力方面的优势,使其在移动办公、IoT、边缘计算等场景中具有独特价值。
培养"AI原生"团队:技术团队的能力模型需要升级——从"会用AI工具"到"能设计AI系统"再到"能管理AI行为"。投入资源培养团队在AI治理、安全保障、大模型评估等方面的能力。
密切关注推理模型的发展:推理模型(如DeepSeek R2、GPT-5 o3模式)代表了AI能力的下一个突破方向。评估这些模型在你的业务场景中的实际效果,考虑将深度推理能力集成到需要复杂决策的产品中。