夜雨聆风
夜雨聆风LLM | drbool AIOps · 大模型 · AI Agent | 原创 |
Gartner 预测:到 2029 年,70% 的企业将部署智能体自主运维 IT 基础设施(2025 年这一数字还不到 5%)。
这意味着未来三到四年,AIOps 智能体会从"PPT 概念"全面走向"生产闭环"。但闭环不是一蹴而就的——它需要一个清晰的工程化分层框架,让规则引擎、智能体、专家各归其位、各尽其责。
本文提出一份 L1 / L2 / L3 三层分工的工程方案——整合行业既有最佳实践,并加入我们在金融行业方案设计中形成的若干工程视角,覆盖从告警治理到智能诊断、从预案执行到 AI 治理的完整路径。
一、AI-First 运维落地的真问题
在与金融行业客户的方案沟通中,我们反复遇到一个普遍的困惑:
"我们要不要做 Agent?""做了 Agent 之后,原来的告警平台、规则引擎是不是就可以下线了?""Agent 上去之后,运维团队是不是要砍一半?"
这些问题之所以让人犹豫,是因为它们都在问"要不要替代"。但 AI-First 运维落地的真问题,从来不是"用 AI 替代一切"——而是:
为不同层级、不同性质的运维工作,匹配最合适的技术与最合适的角色。
什么样的工作适合规则引擎?什么样的工作适合智能体?什么样的工作必须由人来做?这三类工作之间如何协作、如何升级、如何沉淀?
回答这一组问题,就需要一个分层框架——L1 / L2 / L3 三层分工模型。
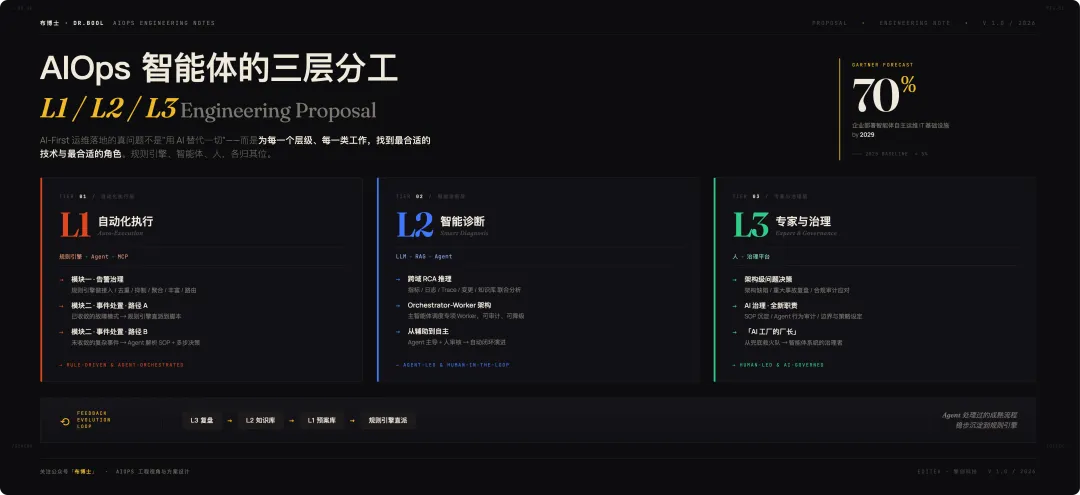
二、L1 / L2 / L3 三层分工总览
L1 / L2 / L3 这个分层最早来自传统的服务台支持模型(Tier 1/2/3 Support)。在 AI-First 运维语境下,我们对它做了重新定义:
| L1 | |||||
| L2 | |||||
| L3 |
三层之间不是孤立的,而是构成一个向上升级 + 向下沉淀的闭环:
- 向上升级
L1 解决不了的升 L2,L2 解决不了的升 L3 - 向下沉淀
L3 的经验沉淀为 SOP → 回流 L2 知识库 → 落到 L1 预案库
下面我们逐层展开。
三、L1:自动化执行层
L1 是 AIOps 智能体平台的"地基",也是日常运维工作量最大的一层。
L1 的工作可以拆成两个性质完全不同的子任务,由两种不同的技术分别承担:
3.1 模块一 · 告警治理:规则引擎的主场
告警治理包括:
- 告警接入
Webhook、Syslog、SNMP Trap、Prometheus、Zabbix…… - 去重
同源同指纹合并 - 抑制
父告警抑制子告警、维护期抑制 - 聚合
按业务、按拓扑、按变更窗口聚合成事件 - 告警丰富
注入 CMDB 资产信息、关联变更单、关联值班人 - 路由
根据规则分派给对应团队/系统
这些工作有一个共同特征:高频、确定、可审计、强 SLA。
超大型银行一天的告警量轻松上百万条,瞬时洪峰可能到每秒数千条。这种工作量、这种确定性要求,正是规则引擎几十年行业演进沉淀下来的最优解:
在金融行业,可审计性和可解释性尤其关键——监管会问你:"为什么这条告警被压制了?为什么这条告警归到了那个事件下?"你必须能拿出规则配置、决策日志、聚合路径来解释。这是规则引擎得天独厚的优势。
所以 L1 的告警治理模块,用流式计算 + 规则引擎(CEP / 决策树 / DAG)做底座,把每秒成千上万的原始告警压缩成清晰的、丰富过的事件。这一步的产出,就是下一个模块——事件处置——的输入。
3.2 模块二 · 事件处置:规则引擎与 Agent 的二次分工
收到一个清晰的事件之后,下一步就是自动执行预案、Runbook,把问题闭环。但这一段内部还有一个很多方案里被忽略的工程二分:预案执行不全是 Agent 的事,规则引擎在这里仍然有重要角色。
路径 A:规则引擎直派确定性预案
对于已经在历史复盘中收敛的故障模式,告警的组合特征本身就足以确定处置方案:
[告警 A] + [告警 B] + [资产维度 X] → 执行预案 #007这类场景的特点是:
处置路径已经经过多轮验证,无中间判断需求 直接关联到预定义的脚本(Ansible Playbook / SaltStack 状态 / 内置 Action) 毫秒级触发、零 LLM 推理成本、强可审计
例如:服务进程崩溃 + 健康检查失败 + 该服务在白名单内 → 直接走"重启 + 通知值班"脚本。这种场景上 Agent 是浪费——规则引擎几条 IF-THEN 就解决,反而更快、更便宜、更可审计。
路径 B:Agent 解析 Runbook 并智能执行
对于尚未完全收敛、需要根据现场情况判断的故障,由 Agent 读取自然语言 SOP,通过 MCP 协议调用工具链,完成多步推理与中间决策。
举一个具体的例子——磁盘空间告警的处理:
1. 收到事件:"prod-db-03 /data 磁盘使用率 92%"
2. 选择 SOP:磁盘清理预案 v3.2
3. 通过 MCP 协议登录目标主机
4. 执行 du -sh /data/* | sort -h,找出大文件
5. 根据 SOP 判断:
- 如果是日志 → 按归档策略清理
- 如果是临时文件 → 按规则清理
- 如果是业务数据 → 不动,升级到 L2
6. 执行清理,验证磁盘使用率
7. 写入工单系统,通知值班人这件事为什么交给 Agent 而不是写死的脚本?因为:
- Runbook 是用自然语言(甚至中文)写的,不是结构化代码——LLM 能直接读懂
- 每个客户每个业务的 SOP 都不一样,写死规则维护成本极高——Agent 用同一套引擎吃掉所有 Runbook
- 中间步骤需要根据命令输出做小决策(按 SOP 分支)——这是 Agent 擅长的
- 涉及调用多种工具:SSH、监控、CMDB、ITSM、IM——MCP 协议帮 Agent 串通全栈
- 遇到预案外情况,Agent 可以选择"安全退出,升级到 L2"——这是规则引擎做不到的优雅降级
- 每一次执行都被 Trace(如 Langfuse)记录
——可观测、可回放、可审计
两条路径不是非此即彼,而是一个"成熟度连续谱"
一个处置流程的演进路径通常是:

随着多次复盘积累,可标准化的处置路径会从 Agent 层"沉淀"到规则引擎层——这是 L1 内部的反馈进化闭环。
优秀的 AIOps 平台不是"Agent 越用越多",而是"Agent 处理过的成熟流程稳步下沉到规则引擎",让运维成本随时间持续下降、确定性随时间持续提升。
3.3 两个模块的工程接力
告警治理 与 事件处置 不是替代关系,而是一次干净的工程接力——而且事件处置内部还有规则引擎与 Agent 的二次分工:
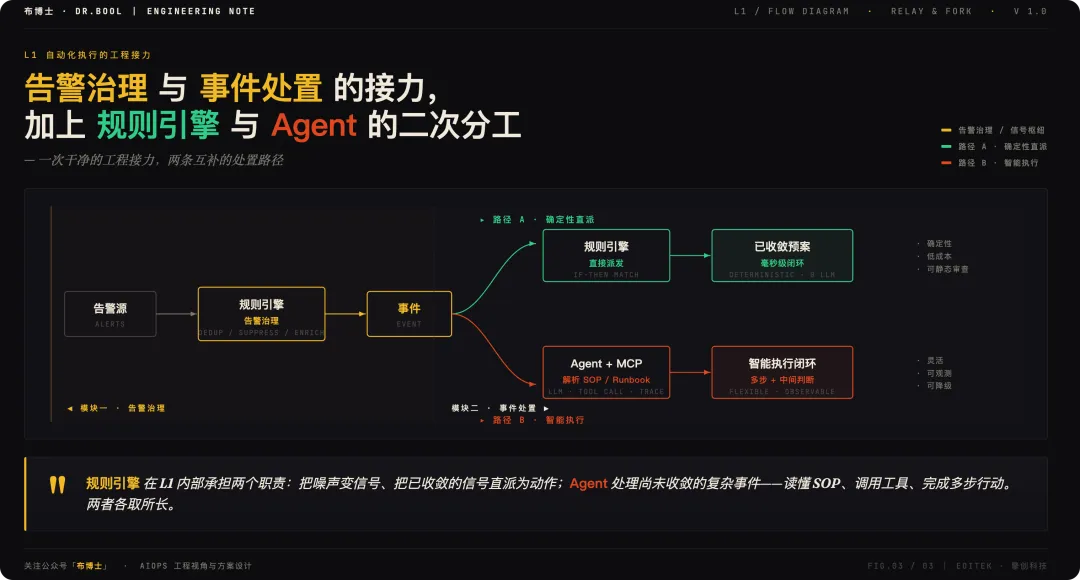
规则引擎在 L1 内部承担两个职责:把噪声变信号(告警治理),以及把已收敛的信号直派为动作(确定性预案);Agent 的职责则是处理尚未收敛的复杂事件——读懂 SOP、调用工具、完成多步行动。两者各取所长,组成 L1 这一层完整、立体、可演进的自动化执行能力。
四、L2:智能诊断层
L1 把"标准动作"做完之后,剩下需要诊断、推理、判断的复杂事件,就进入 L2。
L2 处理的是"基于不完整信息做推理"的问题,典型场景包括:
- 跨域 RCA
交易成功率从 99.9% 跌到 99.2%,到底是网络?数据库?应用?还是某个上游依赖? - 变更影响分析
上午 10:15 的某个发布,是否与现在的异常有因果? - 慢调用诊断
哪个 Span 慢?慢在 GC 还是慢在锁?还是慢在下游 RPC? - 历史故障匹配
当前的故障特征,跟知识库里哪个历史 Case 最相似?
这些工作的共同特征是:
- 数据多源
指标、日志、Trace、CMDB、变更、值班记录、知识库 - 路径多分支
没有固定的诊断流程,需要根据中间发现持续调整 - 知识依赖强
需要历史故障库、领域知识、SOP - 结果带置信度
根因可能不止一个,需要排序输出
4.1 Orchestrator-Worker 多智能体架构
多智能体系统在工程实现上有两条不同的技术路线:
- 主智能体驱动子智能体(Orchestrator-Worker)
主 Agent 负责任务分解、调度和汇总,子 Agent 各司其职、被动执行。控制流是清晰的树状结构。 - 多智能体对话(Multi-Agent Conversation)
多个 Agent 平等参与共享对话、互相回应。控制流是网状的,下一个发言者由协议决定或 Agent 自荐。
在 AIOps L2 诊断这种强 SLA、强合规、强成本控制的生产场景下,必须选择 Orchestrator-Worker 路线:决策链是清晰的树状结构、每一步都可回放可审计、调用范围由主 Agent 明确控制、整体延迟和成本可预测。Multi-Agent Conversation 路线更适合开放式研究、创意生成等没有强约束的场景,不适合直接落到生产运维。
我们的 L2 诊断系统采用如下角色编排:
架构层面只有两类角色——Orchestrator 与 Worker,Worker 之间不直接通信,全部由 Orchestrator 调度协调。Synthesizer 的"综合归纳"是业务职能,不是独立的架构角色;在工程实现上它既可以拆为独立 Worker(便于独立 Prompt 调优和评估),也可以合并进 Orchestrator(节省一跳调用),看综合逻辑的复杂度而定。
这种架构的好处是:
- 能力可插拔
新增一种数据源,就新增一个 Worker,Orchestrator 编排逻辑不变 - 可观测可调优
每个 Worker 的输入/输出/决策都独立 Trace,便于评估和优化 - 成本可控
Orchestrator 根据事件特征决定调几个 Worker,避免每次都把所有 Worker 都跑一遍 - 可降级
单个 Worker 失败不影响整体诊断,Orchestrator 可以基于剩余信息给出降级结论
4.2 两种成熟度阶段
L2 的落地不是一步到位,而是分两个阶段演进:
| 起步期 | ||
| 成熟期 |
绝大多数客户应该从"Agent 诊断 + 人审核"开始——这既符合金融行业合规要求,也是让 SOP 库、知识库、预案库不断沉淀的现实路径。诊断结果由 Agent 给出,工程师做最终决策;每一次决策都被记录下来,回流到知识库,让下一次诊断更准。
五、L3:专家与治理层
L3 在传统模型里就是"专家兜底"。在 AI-First 运维时代,L3 多了一个全新的、非常重要的职责:对 AI 系统本身的治理。
5.1 经典专家职责
- 架构级问题处理
故障根因涉及架构缺陷,需要研发介入 - 新型故障分析
从未遇到过的故障模式,需要专家定义识别和处置方案 - 重大事故复盘
业务影响大、跨多系统的事故 - 合规与审计应对
监管检查、内审、外审
5.2 新增职责:AI 治理(AI Governance)
这是 AI-First 运维带给运维组织的全新工作量:
- SOP / Runbook 沉淀
把每次 L2/L3 的处置经验回流到知识库和预案库 - Agent 行为审计
定期审查 Agent 的决策链,发现幻觉、错误推理、不当工具调用 - 能力边界设定
哪些动作 Agent 可以自主执行?哪些必须人工 approve?这是策略问题 - 模型与 Prompt 治理
模型升级、Prompt 演进、A/B 测试 - 数据治理
训练数据、知识库、向量索引的质量管控 - 成本与性能监控
Token 消耗、API 调用、模型选型的持续优化
5.3 L3 角色的转变
L3 不再只是"兜底救火队",而是"AI 工厂的厂长"。
这是 AI-First 运维组织最稀缺、也最值钱的能力——既要懂运维、又要懂 AI、还要能站在治理视角设计策略。从客户视角看,培养出一支 L3 团队,比上一套 AIOps 平台更难,但价值也更大。
六、三层之间的协作机制:反馈进化闭环
如果只看每一层的分工,这个框架还只是静态的。让它真正"活起来"的,是三层之间的协作机制——一个向上升级、向下沉淀的双向闭环。
6.1 向上升级
事件流转的方向:
- L1 → L2
预案没覆盖、Agent 主动退出,或诊断本身就需要跨域分析 - L2 → L3
诊断结果指向架构问题、Agent 置信度不足、监管或客户要求人工介入
每一次升级都是一次记录——为什么 L1 没接住、为什么 L2 没拿下,这些信息本身就是宝贵的反馈数据。
6.2 向下沉淀
经验回流的方向:
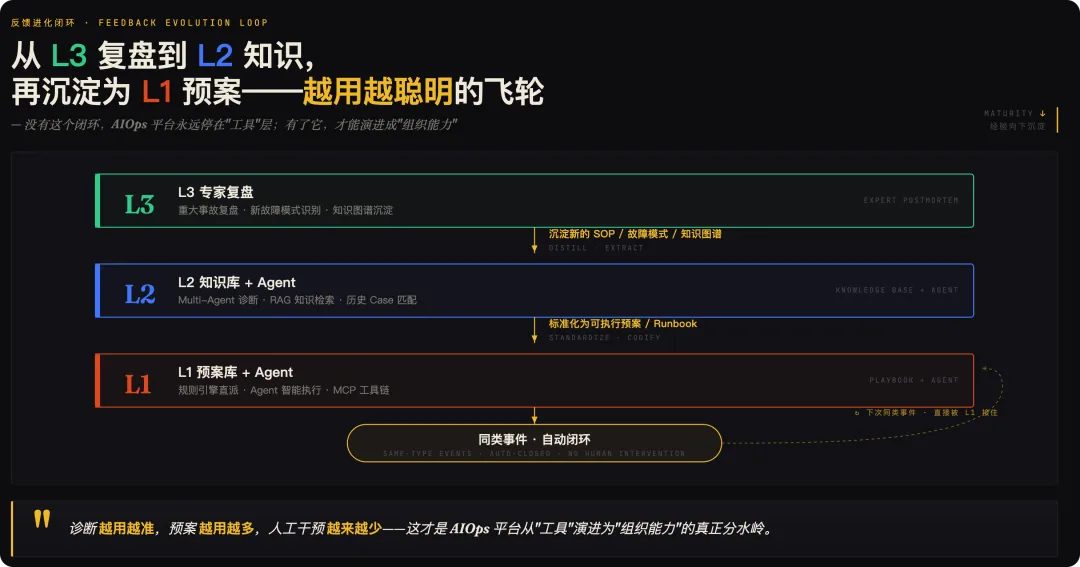
这就是我们一直强调的 "反馈进化闭环(Feedback Evolution Loop)"——让整个系统具备"诊断越用越准、预案越用越多、人工干预越来越少"的飞轮效应。
没有这个闭环,AIOps 平台永远停在"工具"的层面;有了这个闭环,它才能演进成"组织能力"。
七、落地路径:三个阶段稳步推进
很多客户问:"我们现在该从哪里开始?"我们的建议是分三个阶段:
阶段一(0–6 个月)| 打地基
- L1 告警治理
用规则引擎搭建告警治理底座,目标告警压缩比 ≥ 70% - L1 事件处置 · 路径 A
盘点已收敛的高频故障模式,接入规则引擎直派(如服务崩溃重启、证书续期、心跳掉线告警关闭等) - L1 事件处置 · 路径 B
选 Top 10 需要中间判断的多步处置场景做 Agent 化(如磁盘清理、Pod 驱逐诊断、链路自检等) - L2 暂不开闭环
先让诊断 Agent 作为辅助工具,给一线工程师用 - L3
组建小型治理团队(哪怕只有 1–2 人),开始建立 SOP 沉淀机制
核心目标:让 Agent 替代人做"无聊重复"的事,让一线工程师从"半夜被叫醒"中解放出来。
阶段二(6–12 个月)| 拓宽闭环
- L1
预案库扩展到 50+,覆盖大部分高频场景 - L2
从"辅助"模式过渡到"Agent 主导 + 人审核",正式进入生产 - L3
治理团队承担 SOP 沉淀、行为审计、边界设定的完整职责 - 可观测性贯穿全链路
用 Langfuse 等工具把 Agent 的每一次决策都 Trace 下来
核心目标:80% 的告警事件不再需要人工介入。
阶段三(12 个月以后)| 走向自主
- L2
在标准故障上实现自主闭环 - L3
治理体系成熟化,建立 Agent 行为评估、回归测试、灰度发布机制 - 业务团队反向消费 AIOps 能力
研发、SRE、风控等团队基于同一套智能体能力做二次开发
核心目标:从"AIOps 平台"演进到"AI-First 运维组织"。
八、对企业的价值
这个三层分工方案,给企业带来的不只是一套技术框架,更是一条清晰的落地路径:
- 成本可控
规则引擎处理高频低值任务,Agent 处理高价值任务,避免"为 AI 而 AI"造成的成本失控 - 合规可审
每一层都有清晰的可解释性方案,金融行业的审计场景可以从容应对 - 风险可控
分阶段落地、人审过渡、安全降级,每一步都不冒激进风险 - 演进可见
从 L1 到 L3、从辅助到自主,每个阶段都有看得见的 ROI 产出 - 组织升级
催生出一支懂运维、懂 AI、懂治理的复合型团队,这是企业最宝贵的长期资产
九、写在最后
回到 Gartner 的那个数字——70% 的企业到 2029 年要部署智能体自主运维。
这件事一定会发生,但怎么发生,决定了这 70% 里有多少是真正的生产闭环、有多少只是停留在 PPT 上的闭环。
AI-First 运维不是"用 AI 替代一切",而是为每一个层级、每一个子任务,找到最合适的技术与最合适的角色——规则引擎做规则引擎该做的事,智能体做智能体该做的事,人做人该做的事。
L1 / L2 / L3 三层分工,就是这个工程化思考的落地框架。
这不是营销叙事,而是工程取向。这份方案目前处于设计阶段,欢迎金融行业同行与运维 / AI 工程领域的朋友一起探讨、批评、完善。
关于布博士 二十年 IT 运维老兵,七年专注智能运维。专栏聚焦 AIOps、LLM 应用工程、Agent 架构与金融行业方案设计。欢迎关注公众号"布博士",一起把 AIOps 的工程逻辑讲清楚。
| ◆THE END◆ | |||||||