 夜雨聆风
夜雨聆风❝❞
论文标题: X-Voice: Enabling Everyone to Speak 30 Languages via Zero-Shot Cross-Lingual Voice Cloning 论文链接: https://arxiv.org/abs/2605.05611v1 代码链接: https://github.com/sunnyxrxrx/X-Voice 发表会议: arxiv
开篇:你只需要说3秒,我就能用30种语言替你说话
想象一下这个场景:你对着手机说了句“今天天气真好”,然后 AI 就用你的声音,用日语、法语、德语甚至泰语,把这句话重新说了一遍,不是机械的逐字翻译式朗读,而是带着你的音色、你的语气、你的节奏,听起来就像你真的会说那门外语一样。
这不就是科幻片里的“万能翻译器”吗?
但从技术角度看,这背后是一道极其棘手的工程难题:如何让一个轻量级模型,在不需要参考音频文字稿的情况下,实现跨语种的声音克隆?
上海交通大学 X-LANCE 实验室联合多家机构,最近放出了一篇论文,给出了一个相当漂亮的答案。他们搞了个叫 X-Voice 的只有 0.4B 参数的多语言 TTS 模型,支持 30 种语言的零样本声音克隆,关键是:全程不需要参考音频的文字稿。
整个模型走的是非自回归(NAR)的 Flow Matching 路线,没有传统方案那种推理串行瓶颈,而且效果直接对标千亿级的大模型。论文已经在 HuggingFace 上把训练数据、评测基准、完整训练配方全部开源了。
概念速通:什么是零样本声音克隆?
传统的语音合成(TTS),想让模型学会模仿一个人的声音,通常得喂给它大量这个人的录音数据,然后再用这些数据训练一个专属的声音模型。这显然是没法大规模用的——你不可能为地球上每个人都准备一套训练数据。
零样本声音克隆(Zero-Shot Voice Cloning) 要解决的就是这个问题。它的思路是:给模型一段参考音频(Audio Prompt),只靠这几秒钟的录音,模型就能“理解”这个人的声音特征,然后用这个声音去读任意文本。不用专门训练,一次搞定。
现在把这个思路再推一步:跨语种零样本声音克隆。让一个只讲中文的人,模型听完他的中文录音后,用他的声音说英文、日文、法文,这就是 X-Voice 要做的事。
这里还有一个更隐蔽的技术难点:大多数语音克隆模型工作时需要一个“双输入”组合 —— 音频prompt + 对应的文字稿(transcript)。模型一边听声音,一边看文字,通过对比“这个发音对应哪个词”来学习音色和发音的关系。但对于多语言场景,尤其是低资源语言和没有书写系统的方言,拿到准确的 transcript 几乎是不可能的。论文原话一针见血:“It becomes exceedingly difficult in multilingual settings, particularly for low-resource languages and unwritten dialects.”
X-Voice 的最大突破之一,就是彻底干掉了这个依赖。
X-Voice怎么干的?一场声音层面的“白条交易”
整套方法论分两步走,论文管这叫“两阶段训练范式”。说得直白点,就是让模型先学会模仿,再拿自己的模仿品当教材精修。
阶段一:搭建多语言声音基础——“420K小时的通识教育”
第一阶段的基底模型叫 ,架构基于 F5-TTS(一个开源的Flow Matching TTS),在 420K 小时的多语言语音数据上训练,覆盖 30 种语言。数据量是什么概念?每天 24 小时不停地听,要听接近 48 年。论文里放了一张各语言数据量的分布图,能明显看到英文和中文的总量一骑绝尘,但团队同时覆盖了一大批低频语言,包括泰语、克罗地亚语、越南语这些在通用语音模型里常常被忽略的语种。
让 30 种语言在同一个模型里和平共处,这里涉及到文本的“统一表征问题”。X-Voice 的解法是:用国际音标(IPA)作为所有语言的通用中间层。中文用拼音,其他语言通过 eSpeak-NG 转换成 IPA,对日语、韩语、泰语这些亚洲语言,团队还分别定制了专用转换工具(PyOpenJTalk、g2pK、PyThaiNLP)。
论文特别给出了一个很有意思的细节,在IPA里保留了重音标记(stress markers),而且把发音单元和超音段修饰符(比如元音长度、送气标记、声调数字)做了一次“先拆开再拼回去”的处理。论文中举了个希腊语的例子:“póte”和“poté”,重音位置不一样,意思完全不同,前者是“什么时候”,后者是“从不”。
核心创新一:双层语言注入——“给声音穿上目标语言的紧身衣”
在跨语种场景里有个非常让人头疼的问题,论文管它叫口音泄漏(Accent Leakage)。什么意思呢?你说一段日语,让模型用你的声音读英语,结果模型读出来的英语还是带着一股日语味儿,因为它没完全解耦你声音里的语言特征和音色特征。
X-Voice 搞了一套双层语言注入(Dual-Level Language Injection) 的机制来对付这个问题。
第一层是时间维度注入:在每个推理时间步上,语言 ID 的 embedding 直接和当前时刻的 embedding 拼在一起,通过一个 MLP 层融合。这相当于告诉模型:“不管你在哪个时间步做决策,请记住你现在说的是哪种语言”。
第二层是文本维度注入,也是更有技术含量的一层:团队用了一个叫 FiLM(Feature-wise Linear Modulation) 的操作,让语言 ID 的 embedding 作为两组学习参数( 和 ),对文本的 IPAembedding 进行逐维度的缩放和偏移。公式写得很简洁:
这里的核心思路是乘法式门控,“目标语言”的信号不是粗暴地加到文本表征上,而是以一种调节器的方式,决定哪些音素特征该放大,哪些该抑制。打个比方:同样的 IPA 音素在不同语言里可能有不同的发音色彩,FiLM 层就是帮你在合成过程中自动做出这些微调。
核心创新二:解耦的无分类器引导——“一个手把调音台,一个手拉缰绳”
无分类器引导(CFG,Classifier-Free Guidance)本质上是条件生成和自由生成之间的线性外推,给定 :
其中 是引导强度。在 F5-TTS 里,引导信号同时作用于音频匹配和文本对齐,一个 同时管两件事。
问题来了:音频引导的 越大,合成的声音跟配音员越像,但发音准确度会下降;文本引导的 越大,发音更准,但声音的自然度和说话人相似度会下降。
这是一个天然的二律背反。X-Voice 的办法是拆开:
第一项是基底预测,第二项是声学引导(有参考音频 vs 无参考音频),第三项是语言引导(有目标文本 vs 无目标文本)。两者互不干扰,可以独立调参。
论文在 Section 4.6 的消融实验中把这件事验证得很清楚。看论文表 9 的数据:
先看前四行——标准的联合 CFG 在 w=2.5 时,音色保持不错(SIM-o=0.693),但 WER 偏高;把 w 拉到 4.0 后WER降了,但音色相似度从 0.693 直接掉到了 0.672,UTMOS 也跌了不少,这清楚展示了发音和音色之间的此消彼长。
再看后三行。拆分解耦配合衰减策略后,WER 打到了最低的 8.20,UTMOS 拉到最高的 3.284,同时 SIM-o 还维持在 0.685,相当接近纯声学优先策略的水平。论文自己也诚实地说:“在最大说话人相似度这个维度上,保守的联合 CFG + 低 w 方案(w=2.5+Decay,SIM-o=0.694)仍然略高一点点”。工具的好坏,取决于你的优先级。
更精妙的是那套非对称预热(A-Warmup) 设计。团队的观察是:在推理初始阶段(高熵噪声还占主导),过于强力的语言引导会导致轨迹震荡。所以他们让语言引导强度在最初的几步线性增长,从零开始慢慢“进场”,而声学引导从一开始就保持全强度,先把音色框架钉牢。用公式表达就是:
等语言引导也热完身了,再让两者的强度都随时间做衰减——靠近推理尾声的时候,生成结构已经稳定,过度引导反而容易引入伪影。这些参数(, , , )在论文里有明确给出。
阶段二:自食其力——“用昨天的自己教今天的自己”
第一阶段搞定了多语言声音合成的基础能力。第二阶段的目标很明确:让模型在没有参考 transcript 的情况下也能克隆声音。
做法相当巧妙。先筛选一份30K小时的高质量数据子集,然后用 X-Voice 第一阶段版本作为“教师”,对子集中的每个样本进行合成,随机抽一段文本,配合某个说话人的参考音频,生成一段同说话人的合成语音。这样,你得到了一组配对数据:合成语音作为 prompt,原始真实语音作为目标。
在第二阶段微调时,把合成 prompt 对应的文本全部 mask 掉,替换成一个特殊占位符 token。这意味着模型被迫学会:不看参考文本,直接听音辨音色。
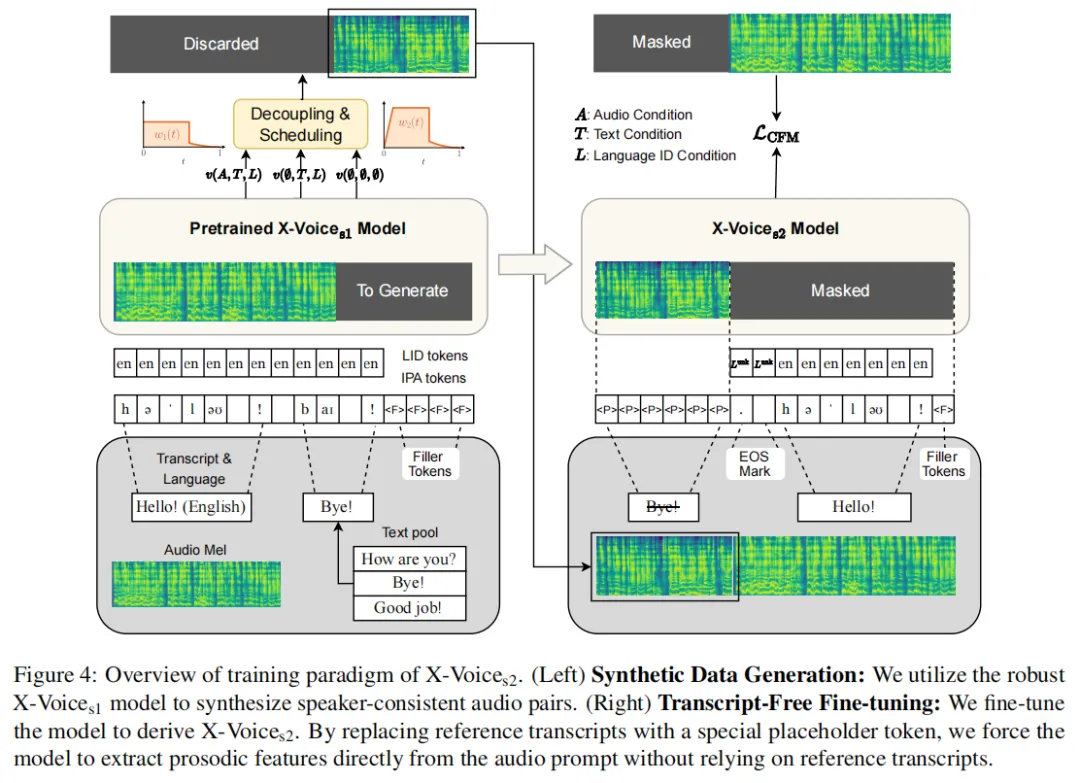
论文的图 4 画得很直白,左侧是合成数据生成流程,右侧是微调时的文本掩码策略。这个设计的聪明之处在于:它不需要任何外部工具做强制对齐,不依赖文本标注的质量,完全用“模型自己的合成输出”来构造训练数据。本质上,这相当于一种自蒸馏,用强版本的模型自动构造一个“免文本”版本。
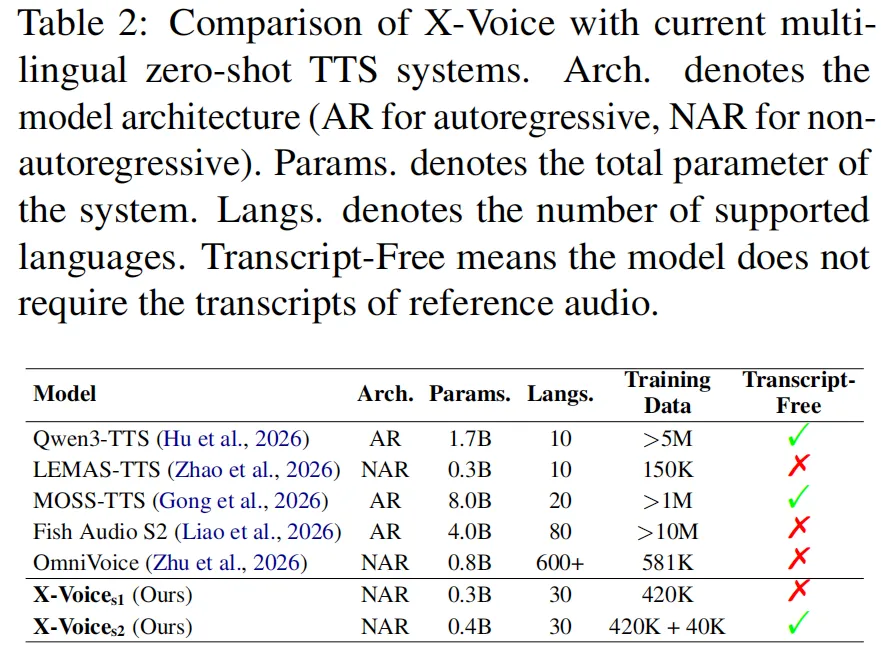
论文的表 2 对比了当前主流多语言 TTS 系统。注意看 X-Voice 的两行,参数只有 0.3B (比 Qwen3-TTS 的 1.7B 小了将近六倍),支持的语言数却达到 30 种(Qwen3-TTS 目前只支持 10 种),而且同样支持 Transcirpt-Free。
实验数据:0.4B干翻1.7B的真相
论文的实验设计很讲究。除了常规的客观指标(WER 和说话人相似度 SIM-o),团队还搞了两个主观评测:IMOS(可懂度主观分)和SMOS(音色相似度主观分),每种语言找 10 名母语者打分——这比单纯看 MOS 分要严谨得多,因为分开了“听不听得清”和“像不像本人”两个维度。
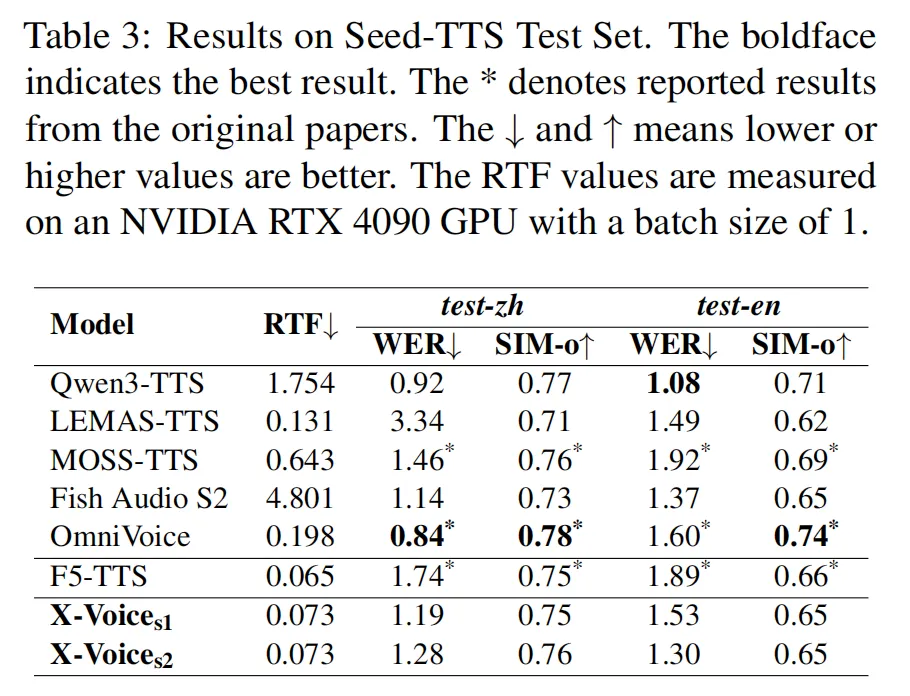
在中文和英文的 Seed-TTS 测试集上(Table 3), 在中文上的 WER 只有 1.19,英文 1.53,这个水平跟 1.7B 的 Qwen3-TTS(中文 0.92 / 英文 1.08)差距不大,但实时因子(RTF)优势明显:Qwen3-TTS 的 RTF 是 1.75(生成 1 秒音频需要 1.75 秒),而 X-Voice 只有 0.073, 快了一个数量级以上。自回归模型需要逐个 token 串行预测,Flow Matching 模型是并行解码的,效率差距在这里很直观。
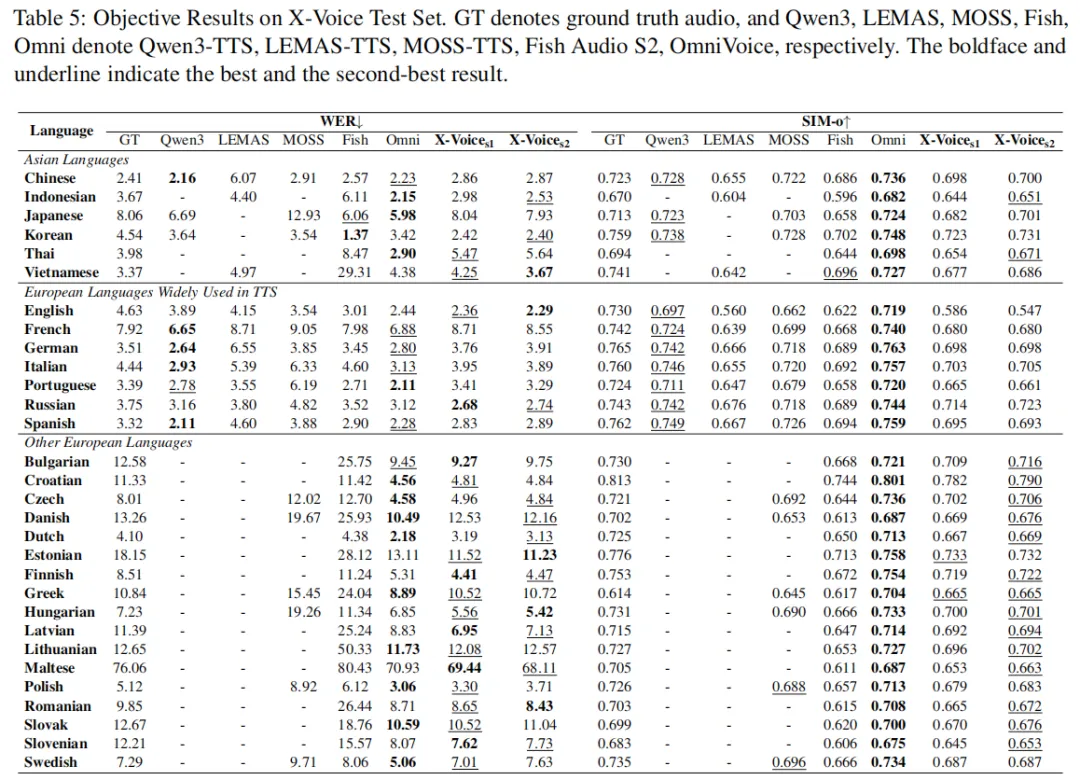
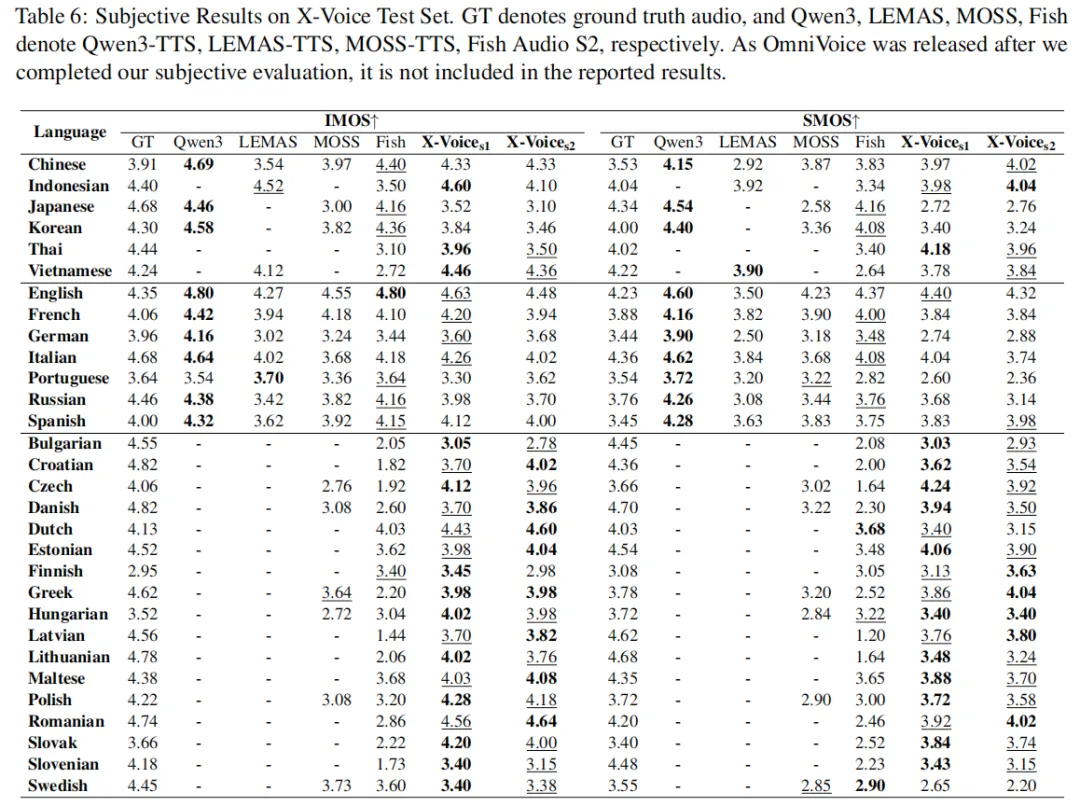
在论文自建的 30 语言测试集上(Table 5和Table 6),整体趋势是 X-Voice 在多数语言上的 WER 都优于 LEMAS-TTS,与 Qwen3-TTS 互有胜负,而在 SIM-o 指标上表现稳定。
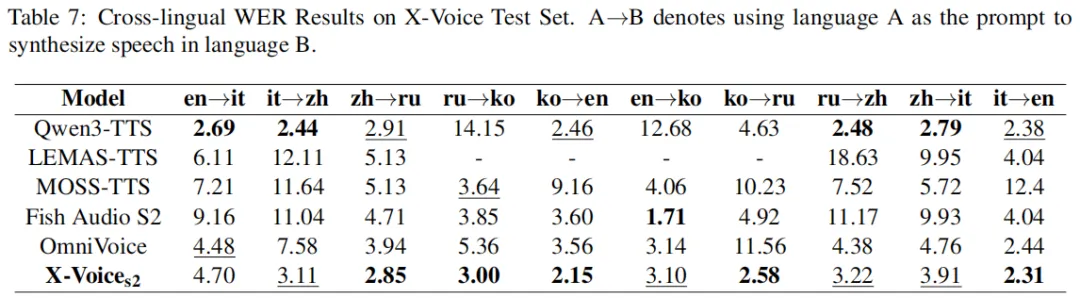
更关键的是跨语种表现(Table 7)。这个实验设计得很有意思:每种语言的说话人作为 prompt,去合成其他 29 种语言的语音。把所有“A→B”的组合跑一遍,得到的是一个 30×30 的 WER 矩阵。整体来看,X-Voice 在各种语种搭配上的 WER 分布都比较均匀,没有出现某些语种搭配特别差的情况。这说明 IPA 作为统一中间层的策略确实有效——跨语种时不会因为发音规则差异太大而崩盘,这一点比很多现有的多语言 TTS 系统要有实质优势。
客观看待:X-Voice的“天花板”在哪?
论文的Limitations部分写得很坦诚:
第一,音色相似度在特定音韵语境下还有提升空间,口音压制和音色保真之间的 trade-off 还需要更精细的建模。这一点从消融实验的表格里也能看出来,Decoupled 策略确实让 WER 和 UTMOS 更好看了,但最高 SIM-o 仍然出自保守的 Base+Decay 方案。
第二,目前模型分别处理 30 种语言,一句话内部的多语种混合(code-switching)还没优化到位。也就是说,如果你想用一段音频同时作为中英混读句子的参考,效果可能还有提升空间。
第三,第二阶段训练依赖于 合成的高质量伪数据——这意味着两阶段的性能存在传导依赖。如果第一阶段模型在某些边缘说话人或极端口音场景下合成质量下降,第二阶段的学习效果也会打折扣。
结语
X-Voice 最值得被记住的,不是它 0.4B 赢了 1.7B 这件事,而是它在做多语言声音克隆时想明白了一个问题:当你没有文本标签可用的时候,你可以让模型自己给自己当老师。用合成语音构建训练对,mask 掉参考文本,强迫模型直接从声音里学“这个人的音色长什么样”而不依赖于“这段文字念了什么”,这就是第一阶段到第二阶段的那次关键跃迁。
它还为多语言 TTS 里一个长期被忽视的口音泄漏问题提供了一个具体的、可操作的解法。双层语言注入加解耦的无分类器引导,本质上是在 Flow Matching 框架里找到了一个能同时管住“发音准确性”和“音色保真度”的开关组合。
欢迎大家加入LLM技术交流群:

