 夜雨聆风
夜雨聆风
但你只要真的去问那些搞端侧 AI 落地的工程师——手机厂商、车厂、机器人公司、AR 眼镜团队——他们会告诉你一个完全不同的事实:让他们失眠的,从来不是什么算力,而是 内存。
这个事实之所以一直被盖住,是因为它不性感。算力是面子,存储是里子。算力上得了发布会,存储上不了热搜。但产业的真相向来如此——决定胜负的,往往是你最不想碰的脏活。AI 越往边缘走,这个真相越藏不住。



这堵墙叫"存储墙"(Memory Wall)。说白了就是:处理器越来越快,内存喂不饱,计算单元只能干等着挨饿。
云端数据中心还能用钱解决——堆 HBM、堆带宽、堆机柜。但边缘没这个奢侈。一台手机整机功耗也就 5 瓦上下,根本没有数据中心那种铺张的预算。
更扎心的是:业内有个数据,AI 运算大约 80% 的能耗,都浪费在了数据从内存到处理器的来回搬运上,而不是计算本身。
也就是说,过去两年所有关于"NPU 多强"的吹嘘,对边缘 AI 来说都是次要矛盾。真正烧电的,从来不是计算,是搬运。
但你听过几家芯片公司在发布会上认真讨论这件事?几乎没有。因为这事讲出来不好卖,PPT 上画不好看。



如果你只跑语音识别、人脸识别、关键词检测,传统配置还撑得住。但只要边缘设备开始碰大语言模型,所有问题立刻被放大十倍。
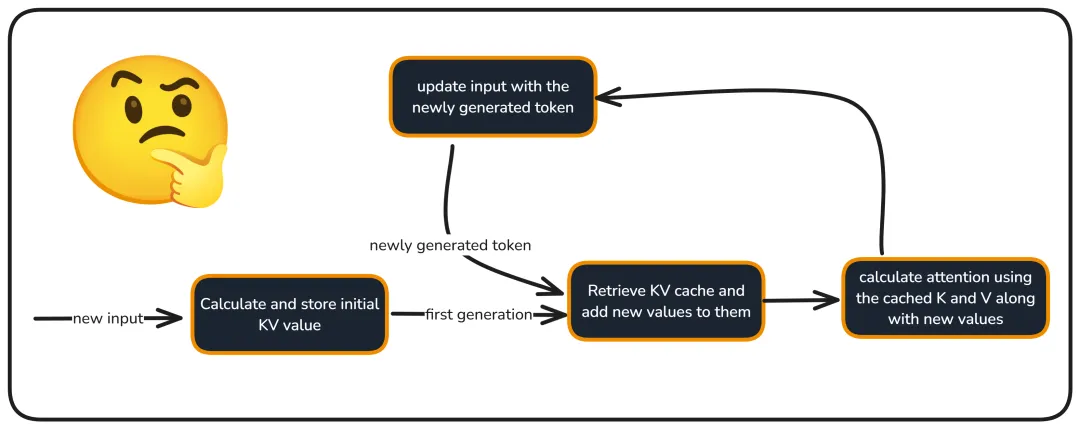
LLM 推理里有一个躲不掉的东西,叫 KV Cache(键值缓存)。
它的逻辑很简单:模型每生成一个新词,都要把前面所有词的中间结果回看一遍。为了不重算,系统会把这些结果缓存下来。上下文越长,缓存越大。
大到什么程度?以 Llama 3.1-70B 为例,处理 100 万 token 的上下文,光 KV Cache 就要 305GB。而市面上最新的旗舰智能手机,内存最多也就 16—24GB。
差的可不止一点,是两个数量级。
这就是为什么过去一年那些"手机本地跑 70B 大模型"的演示视频,你只要追问一句"连续对话半小时之后呢",演示者立刻开始打太极。短 demo 糊弄得了人,真实使用糊弄不了——KV Cache 会膨胀到把整台手机的内存吞干净。
云上喊得最响的"百万上下文""超长记忆",搬到端侧基本就是个笑话。不是不能做,是装不下。
所以你看,整个行业现在最忙的事,不是把模型再做大,而是想尽办法把 KV Cache 压扁——量化、分页、卸载、共享,每一招都是在和存储较劲。
边缘 AI 最难的部分,从来不是模型推理本身。



存储三巨头前几年眼睛都盯着HBM,直到边缘AI烧起来,才被迫往下看。三家选的路线,差别不小。

先看三星。它喜欢搞标准,自己有晶圆厂、逻辑、存储,一条龙。搞了个10.7Gbps的LPDDR5X,单封装能塞32GB;PIM标准化也是它最积极。但尴尬的是:搞标准的,最怕没人跟。SoC不集成、操作系统不支持、应用不调,再好的标准也是自娱自乐。三星在边缘PIM上孤独地晃了好几年,生态到现在也没起来。
再说SK海力士。前几天新闻报道说海力士今年给每个员工分600万奖金,挺热门的,海力士主要靠HBM吃饭——2026年Q1市占干到57%,基本垄断。有钱了就去搞封装,搞了个HBS,把DRAM和NAND直接堆一起,厚度降了27%。但封装优势怎么下沉到边缘?HBM那套高利润玩法,在手机和AR眼镜上跑不通。它得证明自己能在低毛利的消费电子里做出规模。HBM赢了,但这事帮不了它。
最后看美光。2025年底直接砍掉消费品牌Crucial,全部产能转向AI、工业、汽车。等于说:消费市场我不要了,就赌AI基础设施。这是三家里最不留退路的一手。未来三年汽车和工业边缘AI没爆发,美光等于自断一臂;赌对了,它就从“存储厂” 变成 “AI基础设施厂”。
三家都看到了同一个方向——边缘AI不是云端的低配版,是个独立战场。但说实话,他们的动作还是慢。仗都快打起来了,还在磨刀。
存储三巨头过去几年的注意力都在云端 HBM 上。直到边缘 AI 这把火越烧越旺,他们才被迫往下沉。三家选的路径,差异很大。



如果说提升带宽、加大容量是"在墙上凿洞",PIM(存内计算)就是直接把墙拆了。
逻辑非常简单:既然搬数据这么费电,那干脆别搬——直接在内存里做计算。

听上去像学术圈的论文题目,但其实早就有商用样品。三星的 LPDDR-PIM 实测功耗能降 72%,SK 海力士的 GDDR6-AiM 速度提升 16 倍、功耗降 80%。
数字漂亮得不真实。问题来了:既然这么好,为什么没普及?
因为整个产业链都在等别人先动。
芯片公司说:"等存储厂出标准。"
存储厂说:"等 SoC 厂支持。"
SoC 厂说:"等操作系统接进去。"
操作系统说:"等应用调用。"
应用厂商说:"硬件还不普及,我做了也白做。"
——一个完美的死循环。
PIM 喊了快十年,物理层面早就成熟,卡的从来不是技术,是商业意愿。三星和 SK 海力士现在联手推 LPDDR6-PIM 标准化,本质上就是想强行把这个死局打破。但有一件事是板上钉钉的:边缘AI真想起飞,PIM这坎非迈不可。不然手机跑大模型,永远是一边跑一边烫手,演示完直接没电。



视野再放大一点。边缘 AI 不止是单个设备的事。越来越多场景在部署"微型数据中心"——一个机柜、几台服务器,放在 5G 基站旁、工厂里、医院里、园区里。
这种场景下,传统服务器架构的老毛病立刻暴露:内存绑死在 CPU 上。这台机器算力满了内存没用完,旁边那台正好相反,但两边的内存就是没法借用。
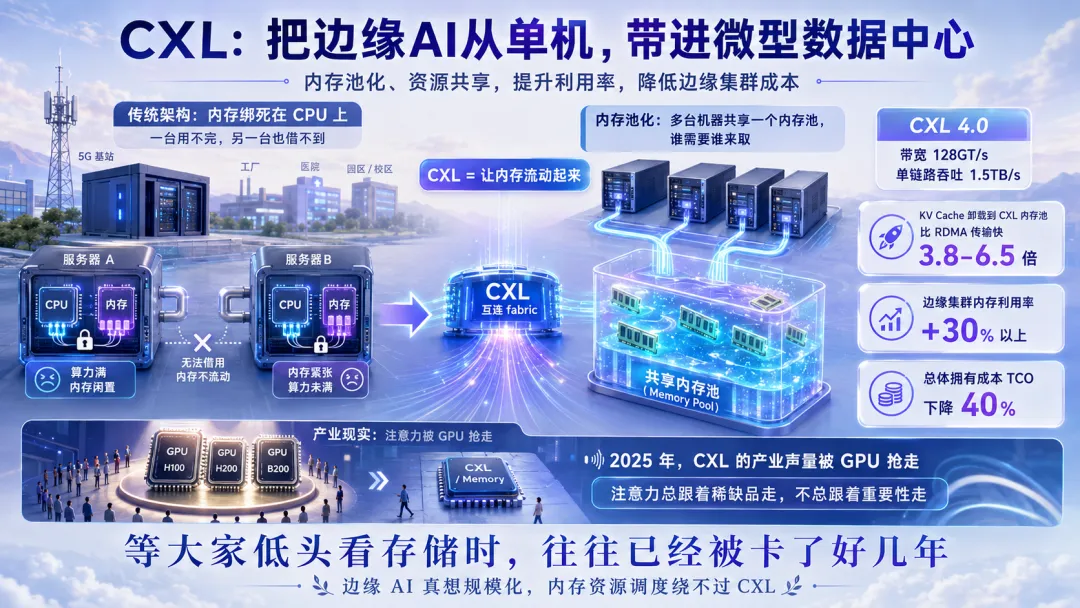
CXL(Compute Express Link)就是冲着这件事来的。
最新的 CXL 4.0 规范,带宽到了 128GT/s,单条链路吞吐 1.5TB/s。它还能把内存"池化"——多台机器共享一个内存池,谁需要谁来取。
实测数据非常硬:把 KV Cache 卸载到 CXL 内存池,比 RDMA 网络传输快 3.8—6.5 倍;边缘集群的内存利用率提升 30% 以上,TCO 直接降 40%。
——这是真金白银。
但你猜怎么着?整个 2025 年,CXL 在产业里的声量,被 GPU 抢得一干二净。所有人都在疯抢 H100、H200、B200,没几个人愿意花心思讨论"内存怎么用得更省"。
这就是产业现实:注意力跟着稀缺品走,不跟着重要性走。等大家终于肯低头看存储了,往往已经被卡了好几年。



技术不落地都是空谈。市面上那些"demo 满天飞、商用寥寥无几"的边缘 AI 项目,背后基本都是同一个死因:存储没跟上。
医疗场景里,云根本不该是首选。医院影像数据动辄 PB 级,传云不仅慢,还有合规风险——隐私法规越收越紧,跨境医疗数据传输几乎已经成禁区。本地边缘存储 + 本地 AI,肿瘤初筛能从几分钟压到几秒,数据连医院大门都不出。这件事做不到的医院,未来在 AI 医疗这条赛道上基本提前出局。
工业更现实。油田、远洋货轮、偏远矿区,网络条件差到几乎可以无视。但工业级 SSD 配合本地 AI 模型,可以在断网下持续做振动监测、设备预警,掉电时还有 PLP(掉电保护)兜底。这些地方没什么炫酷的算力大战,但每个真落地的案子,背后都是存储在那儿硬扛。
边缘 AI 的真实战场,从来不在那些剪辑精美的 demo 视频里,而在这些没人喜欢拍照的恶劣环境里。




2026-04-21

2026-04-08

