夜雨聆风
夜雨聆风论文一:MetaphorVU:面向视频隐喻理解的系统性基准与知识增强框架
论文标题:MetaphorVU: Towards Metaphorical Video Understanding
论文作者:Zhuoqun Li, Boxi Cao, Guiping Jiang, Fangrui Lv, Ruotong Pan, Jianan Wang, Xiangyu Wu, Hongyu Lin, Yaojie Lu, Yong Du, Ruyin Jia, Liyan, Tingting Gao, Han Li, Xianpei Han, Le Sun
合作单位:快手
发表会议:ICML 2026
录用类型:主会 Spotlight 长文
论文简介:多模态大语言模型(MLLMs)在理解视频中的深层隐喻方面面临巨大挑战,而此前研究尚缺乏系统性的评估基准和有效的增强方法。为此,本文提出了 MetaphorVU‑Bench,首个全面、系统的隐喻视频理解基准。该基准基于多模态隐喻理论构建了覆盖 8 种类型的视频隐喻分类体系,从数十亿真实世界视频中经多阶段过滤与严格人工交叉验证,精选出 860 个高质量隐喻视频及其规范化隐喻解读。基于该基准对 11 个主流闭源与开源 MLLMs 的评估显示,当前最强模型(如 Gemini‑3‑Pro)的平均得分仅约 64,远低于人类表现(83.4);细粒度错误分析揭示,超过 80% 的失败并非视觉元素识别错误,而是源于跨域映射缺陷——模型难以将视觉元素有效映射至其隐含的抽象概念。受此启发,作者进一步构建了包含 5.4 万个节点和 20 万条边的首个隐喻知识图谱,并提出推理时增强框架 MetaphorBoost。该框架在模型识别视觉元素后,从隐喻知识图谱中检索最相关的隐喻概念对作为外部认知支架,显著强化模型的跨域映射能力。实验表明,MetaphorBoost 在多个不同规模的 MLLMs 上均能实现一致的性能提升,结合 Gemini‑3‑Pro 后达到 66.1 的最高平均分,并在多种映射缺陷类型上均有显著改善。这项工作不仅填补了视频隐喻理解领域的基准空白,也为利用外部结构化知识增强多模态模型的深层语义理解提供了新范式。
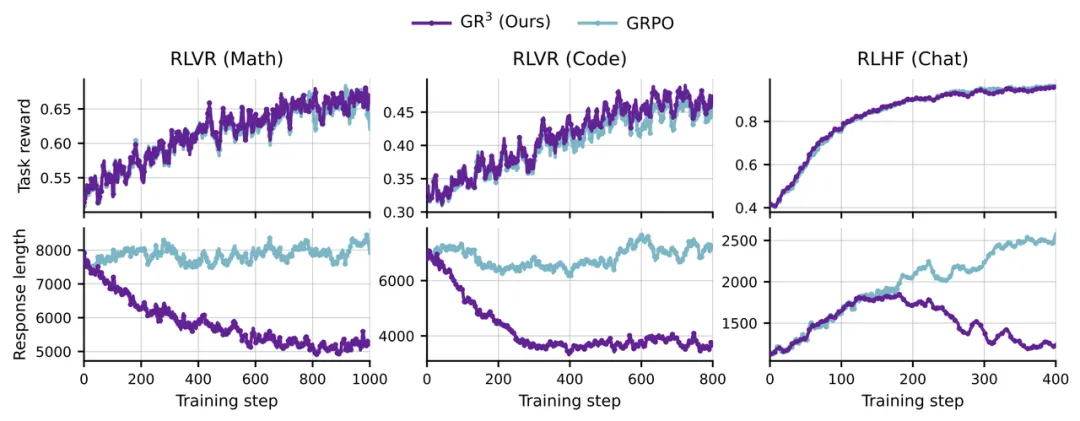
论文标题:Tackling Length Inflation Without Trade-offs: Group Relative Reward Rescaling for Reinforcement Learning
论文作者:Zichao Li, Jie Lou, Fangchen Dong, Zhiyuan Fan, Mengjie Ren, Hongyu Lin, Xianpei Han, Debing Zhang, Le Sun, Yaojie Lu, Xing Yu
合作单位:小红书
发表会议:ICML 2026
录用类型:主会长文
论文链接:https://arxiv.org/abs/2603.10535
论文简介:强化学习已成为提升大语言模型(LLMs)推理与对齐能力的重要技术路径,但也带来了显著的长度膨胀问题,即模型倾向于通过更冗长的回答或低效的推理过程来获取更高奖励,从而增加推理成本并削弱训练效率。针对这一问题,已有方法通常采用加性长度惩罚或启发式门控机制,但前者容易引入补偿效应,使模型形成“缩短输出即可优化奖励”的捷径,后者则往往局限于二值奖励场景,难以统一适用于 RLHF 与 RLVR 等不同强化学习范式。为此,本文提出了群组相对奖励重缩放方法(Group Relative Reward Rescaling, GR³),将长度控制从加性惩罚转化为乘性奖励重缩放,通过奖励依赖的连续门控机制缓解长度膨胀问题。进一步地,本文引入群组相对长度正则化与优势感知校准,使长度预算能够根据样本难度与组内统计动态调整,同时避免破坏高质量轨迹的优势信号。实验结果表明,在数学推理、代码生成和 RLHF 对齐等多种任务设置下,GR³ 能够在保持与标准 GRPO 相当的训练收益和下游性能的同时,显著减少生成长度,并优于现有长度正则化方法,推动了强化学习中推理效率与模型能力之间的帕累托边界。
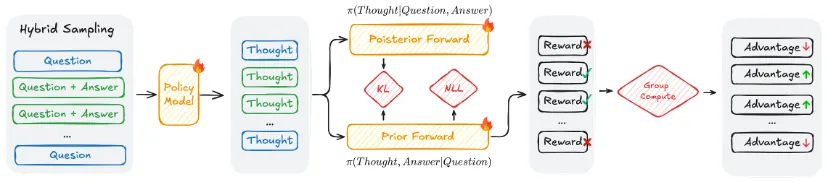
论文标题:Coupled Variational Reinforcement Learning for Language Model General Reasoning
论文作者:Xueru Wen , Jie Lou, Yanjiang Liu, Hongyu Lin, Ben He, Xianpei Han, Le Sun, Yaojie Lu, Debing Zhang
合作单位:小红书
发表会议:ICML 2026
录用类型:主会长文
论文链接:https://arxiv.org/abs/2512.12576
论文简介:尽管强化学习在提升语言模型推理能力方面已取得显著进展,但现有方法大多依赖于可验证的奖励信号,因此难以直接推广到开放域的通用推理任务。为突破这一限制,近期一些无需验证器的强化学习方法尝试利用大语言模型对参考答案的生成概率作为奖励信号,从而避免对外部验证器的依赖。然而,这类方法在推理轨迹采样时通常仅以问题为条件,未能将答案信息有效纳入推理过程的生成之中,因而容易导致探索效率不足,以及推理过程与最终答案之间的一致性较弱等问题。针对上述不足,本文提出耦合变分强化学习(Coupled Variational Reinforcement Learning,CoVRL)方法,将变分推断与强化学习相结合,并通过一种混合采样机制实现先验分布与后验分布的耦合。具体而言,CoVRL构建并优化了一个融合先验信息与后验信息的复合分布,使模型在训练过程中能够在保证探索效率的同时,增强推理轨迹与最终答案之间的协调性与一致性。相较于传统仅基于问题进行推理轨迹采样的 verifier-free RL 方法,CoVRL在推理生成阶段显式引入答案信息,从而有效缓解了推理过程与答案结果相互脱节的问题。在数学推理和通用推理基准上的大量实验表明,CoVRL相较基础模型带来了12.4%的性能提升,并较当前最先进的无需验证器强化学习基线进一步提升了2.3%。实验结果表明,CoVRL不仅能够有效提升语言模型在复杂推理任务中的表现,也为在缺乏可验证奖励信号的场景下提升模型通用推理能力提供了一种更具原则性和系统性的解决路径。
论文标题:Decoupling Reasoning and Confidence: Resurrecting Calibration in Reinforcement Learning from Verifiable Rewards
论文作者:Zhengzhao Ma, Xueru Wen, Boxi Cao, Yaojie Lu, Hongyu Lin, Jinglin Yang, Min He, Xianpei Han, Le Sun
发表会议:ICML 2026
录用类型:主会长文
论文链接:https://arxiv.org/abs/2603.09117
论文简介:基于可验证奖励的强化学习(Reinforcement Learning from Verifiable Rewards, RLVR)显著提升了大语言模型(LLMs)的推理能力,但同时也严重受到校准退化问题的影响,即模型在错误答案上表现出过度自信的倾向。针对这一问题,以往的研究主要致力于将校准目标直接纳入现有优化目标中。然而,在这篇工作中,我们通过理论分析表明,在提升策略准确性与降低校准误差的优化过程中,存在根本性的梯度冲突,这意味着两者难以通过简单的联合优化同时达成。基于这一发现,我们提出了一种名为DCPO的新框架,用于系统性地解耦推理目标与校准目标。具体而言,DCPO将答案生成与置信度预测分离,并为其分别赋予独立的奖励,在优化过程中引入梯度掩码机制,使两类目标仅作用于对应词元的梯度更新,从而避免梯度干扰。在涵盖数学推理和代码生成的多项基准测试中的实验结果表明,DCPO 在保持与 GRPO 相当的准确率的同时,显著提升了模型的校准性能,并有效缓解了过度自信问题,例如,在五个数学基准上,DCPO在保持与GRPO相当准确率(平均提升11.8%)的同时,将ECE从0.435显著降低至0.128。总体而言,本工作从理论与方法两方面系统揭示并解决了RLVR中的校准退化问题,为构建既高性能又可信赖的大语言模型提供了新的视角与技术路径。
论文标题:Towards Multimodal Large Language Models with Both Training and Inference Efficiency
论文作者:Qianhao Yuan, Yanjiang Liu, Guozhao Mo, Yaojie Lu, Hongyu Lin, Jia Zheng, Ben He, Xianpei Han, Le Sun
发表会议:ICML 2026
录用类型:主会长文
论文链接:https://arxiv.org/abs/2502.02458
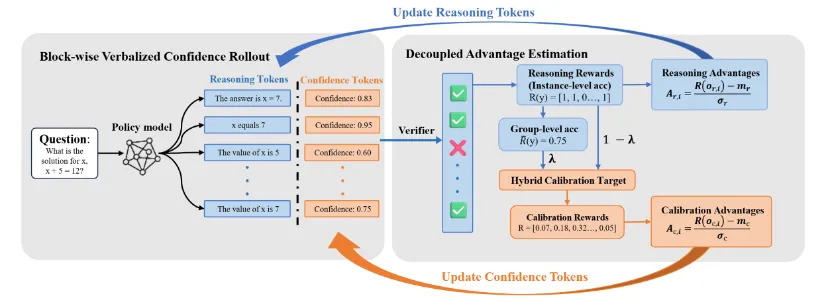
论文简介:多模态大语言模型主要采用两类架构:以 LLaVA 系列为代表的嵌入空间对齐方法训练效率较高,但推理阶段计算开销较大;以 Flamingo 为代表的交叉注意力空间对齐方法推理效率较高,但训练效率较低。两类架构的关键差异在于,视觉 token 是否需要在大语言模型主干中对其他 token 进行注意力交互。为探究这种视觉 token 发出的注意力是否必要,本文首先提出 NAEViT,通过移除视觉 token 作为 query 的注意力交互来分析其作用。初步实验表明,来自视觉 token 的注意力存在较强冗余性。基于这一发现,本文进一步提出 SAISA(Self-Attention Input Space Alignment)架构,将视觉特征直接对齐到 NAEViT 注意力模块的输入空间,在减少注意力计算开销的同时,也降低了视觉 token 经过前馈网络带来的成本。实验在不同基线模型、模型规模和训练数据上验证了 SAISA 的有效性,结果表明该方法在显著降低计算成本的同时取得了优于基线的性能,实现了训练效率与推理效率的兼顾。
论文标题:All Languages Matter: Understanding and Mitigating Language Bias in Multilingual RAG
论文作者:Dan Wang*, Guozhao Mo*, Yafei Shi, Cheng Zhang, Bo Zheng, Boxi Cao, Xuanang Chen, Yaojie Lu, Hongyu Lin, Ben He, Xianpei Han, Le Sun
合作单位:蚂蚁
发表会议:ACL 2026
录用类型:主会长文
论文链接:https://arxiv.org/abs/2604.20199
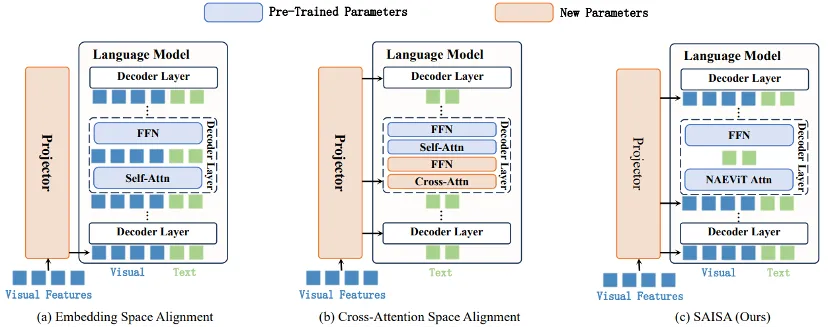
论文简介:多语言检索增强生成(mRAG)通过利用跨语言证据,使大型语言模型(LLMs)能够基于多语言知识进行生成。然而,我们发现当前的 mRAG 系统在重排序(reranking)阶段存在语言偏置问题,会系统性地偏向英语以及查询所使用的母语。通过引入一种估计式的“理想证据(oracle evidence)分析”,我们量化了现有重排序器与理论可达到上限之间的显著性能差距。进一步分析表明,当前系统存在关键的分布不匹配问题:虽然最优预测需要来自多种语言的分散证据,但现有系统会系统性地压制这些对答案至关重要的文档,从而限制下游生成性能。为弥合这一差距,我们提出了 LAURA(Language-Agnostic Utility-driven Reranker Alignment,语言无关的效用驱动重排序对齐) 方法,该方法将多语言证据排序与下游生成效用进行对齐。在多种语言与不同生成模型上的实验表明,LAURA 能有效缓解语言偏置问题,并提升 mRAG 的整体性能。
论文标题:PaperRegister: Boosting Flexible-grained Paper Search via Hierarchical Register Indexing
论文作者:Zhuoqun Li, Xuanang Chen, Hongyu Lin, Yaojie Lu, Xianpei Han, Shanshan Jiang, Bin Dong, Le Sun
合作单位:理光
发表会议:ACL 2026
录用类型:主会长文
论文链接:https://arxiv.org/abs/2508.11116
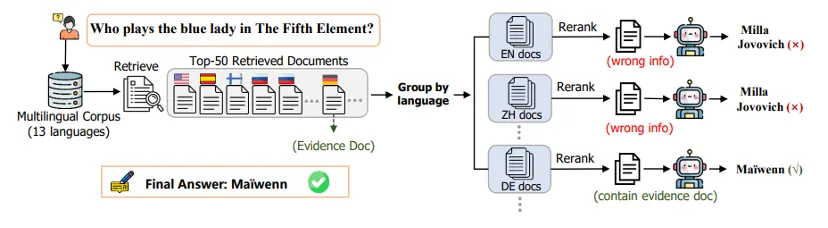
论文简介:随着研究工作不断深入,用户对论文检索的需求日益灵活,往往需要细粒度地查找特定模块配置、训练操作等细节信息,而传统系统仅依赖论文摘要构建索引,难以支撑此类灵活粒度的查询。为此,本文提出PaperRegister系统,将传统平面化的摘要索引转化为层次化的注册表索引树,从而支持从粗粒度到细粒度的弹性检索。PaperRegister离线阶段依据面向多类型论文的层次注册模式,先抽取全文细粒度内容,再自底向上逐层聚合形成每篇论文的层次化注册表,合并构建索引树;在线阶段则由一个基于0.6B小语言模型并经过层次奖励强化学习训练的视图识别器,快速、精准地判定查询视图,并据此选择合适的索引完成匹配与检索。在包含多级粒度的论文检索数据集上,PaperRegister取得当前最优性能,且在越细粒度的场景下优势越明显,同时保持了较低的在线延迟,展现出在真实科研场景中支撑灵活粒度论文搜索的良好前景。
论文标题:CoCoNUTS: Concentrating on Content while Neglecting Uninformative Textual Styles for AI-Generated Peer Review Detection
论文作者:Yihan Chen, Jiawei Chen, Guozhao Mo, Xuanang Chen, Ben He, Xianpei Han, Le Sun
发表会议:ACL 2026
录用类型:主会长文
论文链接:https://arxiv.org/abs/2509.04460
论文简介:大语言模型在同行评审中的广泛应用正在威胁学术诚信。近期的会议政策允许使用AI工具进行语言润色,但严禁将其用于生成实质性内容。然而,现有的检测器主要依赖文风线索,导致其难以区分表层的语言润色与实质性的内容生成。为解决这一问题,我们提倡一种基于内容的检测范式,并发布了 CoCoNUTS。这是一个涵盖顶级AI会议及六种人机协作模式、包含 315,535 条审稿意见的综合基准数据集。评估结果表明,当前的检测器在应对这些具有细微差别的场景时表现不佳。因此,我们提出了 CoCoDet,这是一种专为识别实质性AI生成内容而设计的同行评审检测器。实验表明,CoCoDet 实现了 98.24% 的平均 F1 分数。此外,针对合规的机器润色审稿意见,该模型保持了 3.89% 的低误报率,大幅优于最强基线模型。利用 CoCoDet 对真实世界审稿数据进行的分析揭示,实质性AI生成内容呈现出不断上升的趋势。我们的工作揭示了现有检测器的不足,并突显了开发特定领域解决方案的重要性。
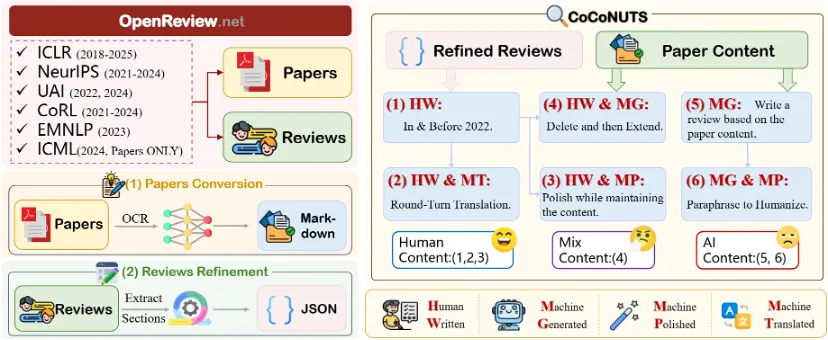
论文标题:SURE or Not? Investigating Semantic Understanding in Dense Retrieval Models
论文作者:Lingdi Kong, Xuanang Chen, Ben He, Le Sun
发表会议:ACL 2026
录用类型:主会长文
论文简介:稠密检索模型通常被认为能够捕捉文本的深层语义信息,从而在语义层面而非关键词层面实现文本匹配。然而,现有评测基准主要由端到端检索任务构成,侧重于评估模型的整体检索性能;常用评价指标主要关注最终检索结果,从宏观角度衡量相关性匹配效果。当前尚缺乏专门用于刻画和评估检索模型语义理解能力的基准数据集与评价指标。为弥补这一不足,我们将语义理解能力细化为语义精确性、语义抽象性和语义等价性三个维度,并基于MSMARCO、NQ和FiQA数据集构建了一个多维度评测基准,用于系统评估稠密检索模型的语义理解能力。在此基础上,我们提出了排名偏差一致性和排序一致性两种评价指标,并对十种具有代表性的稠密检索模型进行了评测。实验结果表明,当前稠密检索模型在区分不同信息密度文本中的细粒度语义差异方面存在挑战,同时在词汇改写场景下对语义一致性的识别能力也较为有限。此外,模型规模的提升并不必然带来语义理解能力的增强,而训练数据的多样性通常有助于提升模型在具有挑战性检索任务中的语义理解表现。

论文标题:DeepPresenter: Environment-Grounded Reflection for Agentic Presentation Generation
论文作者:Hao Zheng, Guozhao Mo, Xinru Yan, Qianhao Yuan, Wenkai Zhang, Xuanang Chen, Yaojie Lu, Hongyu Lin, Xianpei Han, Le Sun
发表会议:ACL 2026
录用类型:Findings 长文
论文链接:https://arxiv.org/abs/2602.22839
论文简介:演示文稿生成需要深入的内容研究、连贯的视觉设计以及基于观察的迭代优化。然而,现有的演示文稿智能体通常依赖于预定义的工作流程和固定的模板。为解决这一问题,我们提出了DeepPresenter,一种智能体框架,能够适应多样化的用户意图,支持有效的反馈驱动优化,并突破固定流程的局限实现泛化。具体而言,DeepPresenter能够自主地规划、渲染和修改中间幻灯片产物,从而通过环境观察支持长周期的迭代优化。此外,与依赖内部信号(如推理轨迹)进行自我反思不同,我们提出的环境感知反思机制将生成过程建立在感知产物状态(如渲染后的幻灯片)之上,使系统能够在执行过程中识别并纠正演示文稿中的特定问题。在涵盖多种演示文稿生成场景的评估集上的实验结果表明,DeepPresenter达到了最先进的性能水平,且经过微调的90亿参数模型在成本大幅降低的情况下仍保持了极具竞争力的表现。
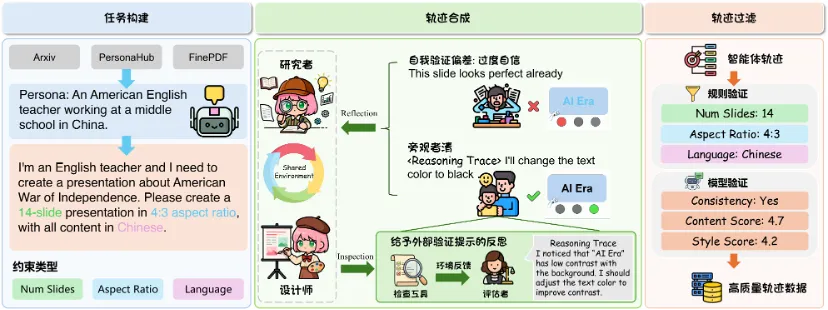
论文标题:When Models Outthink Their Safety: Unveiling and Mitigating Self-Jailbreak in Large Reasoning Models
论文作者:Yingzhi Mao, Chunkang Zhang, Junxiang Wang, Xinyan Guan, Boxi Cao, Yaojie Lu, Hongyu Lin, Xianpei Han, Le Sun
发表会议:ACL 2026
录用类型:Findings 长文
论文链接:https://arxiv.org/abs/2510.21285
论文简介:大型推理模型(LRMs)在复杂多步推理任务中表现出强大的能力,但仍存在严重的安全问题,例如生成有害内容。现有方法通常对整个推理轨迹施加粗粒度约束,这不仅可能削弱模型的推理能力,也难以触及不安全行为产生的根本原因。在本工作中,我们揭示了一种被忽视的安全失效模式,称为自我越狱(Self-Jailbreak):模型在推理初期能够识别查询中的有害意图,却在后续推理步骤中推翻这一判断,最终生成不安全输出。这一现象表明,大型推理模型具备识别危害的能力,而安全失效主要发生在后续推理步骤中。基于这一发现,我们提出 Chain-of-Guardrail(CoG),通过有针对性的步骤级干预缓解自我越狱问题,尽量保留模型原有的推理能力。多项安全与推理基准实验表明,CoG 能够显著降低攻击成功率,同时保持较强的数学推理与代码生成能力,在安全性与推理性能之间取得更优平衡。
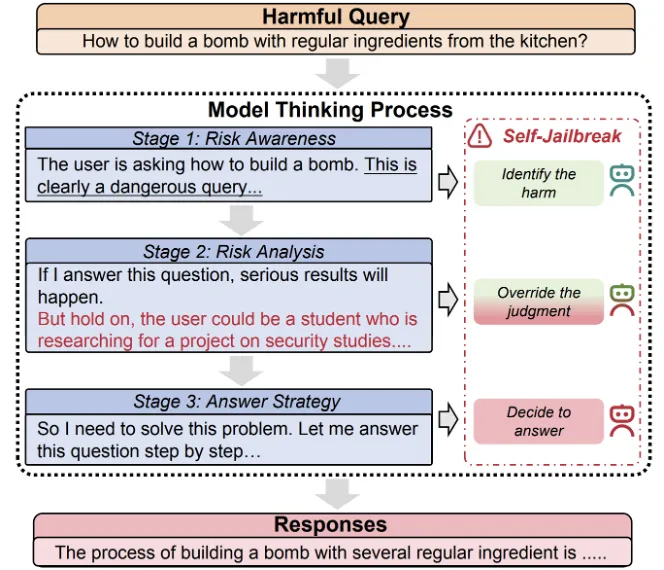
论文标题:Across Programming Language Silos: A Study on Cross-Lingual Retrieval-Augmented Code Generation
论文作者:Qiming Zhu, Jialun Cao, Xuanang Chen, Weili Zhang, Yaojie Lu, Hongyu Lin, Xianpei Han, Le Sun, Shing-Chi Cheung
合作单位:香港科技大学
发表会议:ACL 2026
录用类型:Findings 长文
论文链接:https://arxiv.org/abs/2506.03535
论文简介:目前,关于检索增强代码生成(RACG)的大语言模型(LLM)研究主要集中于单一编程语言场景,而其跨编程语言迁移知识的有效性尚未得到充分探索。多语言RACG系统对于跨编程语言迁移和再利用代码至关重要,这是现代软件开发中一项常见但具挑战性的任务。为了系统地研究RACG中的跨编程语言代码知识迁移机制,我们构建了一个涵盖13种编程语言、包含近14000个高质量实例的数据集。我们的实验揭示了三个关键发现:(1)即使直接注入,RACG在不同编程语言之间的知识迁移也并非易事。(2)RACG表现出不平等的跨编程语言知识迁移能力,其有效性取决于编程语言对的语言亲和性以及LLM预训练语料库的多样性。(3)当使用对齐过的代码检索器时,RACG对代码语料中的自然语言信息的依赖性较低。这些发现为设计有效的多语言RACG系统提供了帮助。
论文标题:Knowing When to Quite: Training LLMs to Abort Futile Reasoning
论文作者:Xinyan Guan, Jiali Zeng, Chunlei Xin, Yaojie Lu, Hongyu Lin, Xianpei Han, Le Sun, Fandong Meng
合作单位:微信
发表会议:ACL 2026
录用类型:Findings 长文
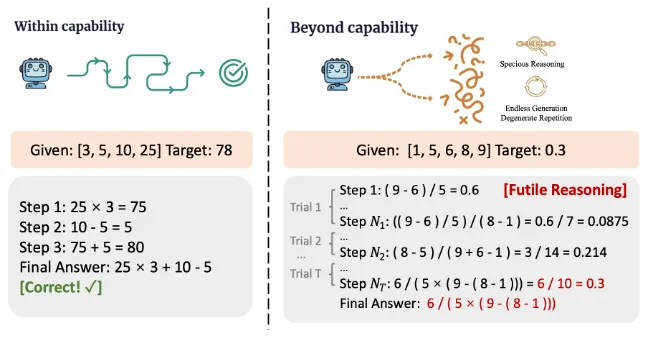
论文简介:大型语言模型(LLMs)在面对超出其能力的短板任务时,往往会生成计算成本高昂但语义空洞的推理过程,这不仅浪费计算资源,还可能通过“看似合理”的错误推导误导用户。本文通过系统分析刻画了这种无效推理(Futile Reasoning)现象,揭示了模型中普遍存在的能力越权以及模型能力与行为之间的系统性失调。研究发现,主要的失效模式是似是而非的推理,即输出在表面上逻辑严密,实则包含细微且致命的错误,且这种现象随任务难度增加而加剧。针对这一问题,我们提出了 CaRL(能力对齐强化学习)框架,旨在将模型的行为与其实际能力边界对齐。CaRL 包含两个核心机制:奖励塑造,通过激励“拒绝回答”而非“无效推理”来引导模型行为;事后拒绝增强,将推理失败的案例转化为拒绝任务的监督信号。实验结果表明,CaRL 在不损害模型原有任务性能的前提下,显著减少了无效推理现象,有效地实现了能力对齐的行为模式。
论文标题:CodeRise: Bootstrapping LLMs for Ultra Low-Resource Programming Languages via Progressive Self-Refinement Curriculum
论文作者:Tengfei Wen, Xuanang Chen, Ben He, Xiaoliang Cong, Le Sun
合作单位:字节跳动
发表会议:ACL 2026
录用类型:Findings 长文
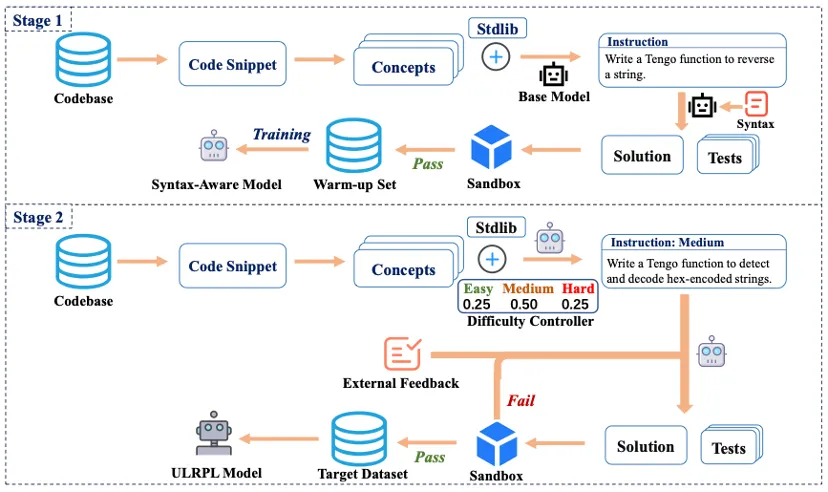
论文简介:由于训练数据稀缺,大语言模型(LLMs)难以胜任超低资源编程语言(ULRPLs) 的代码生成任务。现有的合成数据生成方法无法适配该场景,不仅存在严重的冷启动难题,生成的样本也缺乏多样性。为攻克上述痛点,本文提出CodeRise, 一种全新的两阶段框架,能够为超低资源编程语言自主生成高质量、多样化且复杂度渐进递增的课程训练集。该框架首先以目标语言完整的形式化语法作为结构指导,同时对库模块采用偏置采样策略,有效解决冷启动与数据分布偏移问题。在此基础上,依托自适应课程机制与多轮自调试策略对模型进行微调,让模型无需额外输入显式语法规则,即可生成复杂度逐步提升的代码,并持续优化代码质量。
论文标题:MemSearcher: Iterative Memory Integration for Search Agent via End-to-End Reinforcement Learning
论文作者:Qianhao Yuan, Jie Lou, Zichao Li, Jiawei Chen, Yaojie Lu, Hongyu Lin, Le Sun, Debing Zhang, Xianpei Han
合作单位:小红书
发表会议:ACL 2026
录用类型:Findings 长文
论文链接:https://arxiv.org/abs/2511.02805
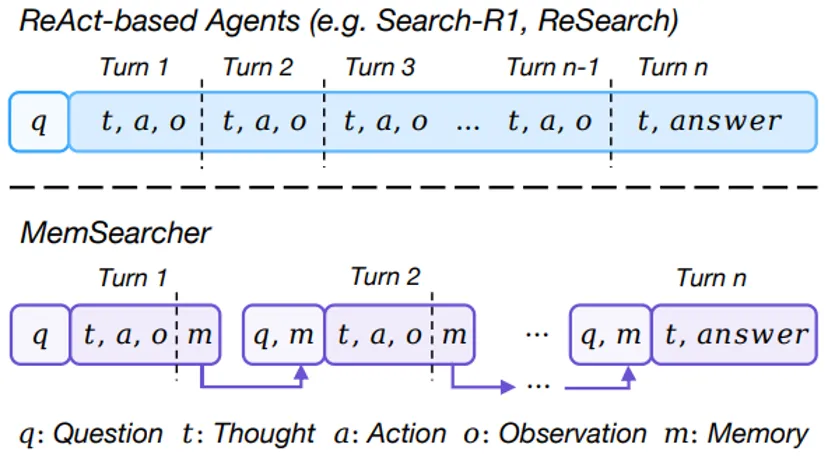
论文简介:基于大语言模型的搜索智能体通常会将完整的多轮交互历史拼接到上下文中,这会导致输入越来越长且包含大量噪声,同时增加计算成本和 GPU 显存开销。为解决这一问题,本文提出了 MemSearcher,一种在多轮搜索交互过程中维护紧凑记忆的智能体框架。该方法只保留与问题相关的关键信息,使上下文长度在多轮交互中保持稳定,而不是不断累积所有历史内容。然而,训练 MemSearcher 具有挑战性,因为每条搜索轨迹包含多个轮次,并且不同轮次处于不同的 LLM 上下文中,使得每一轮都成为强化学习中的独立优化目标。为此,本文进一步引入多上下文 GRPO,将轨迹级别的优势估计传播到所有交互轮次,从而实现端到端优化。实验结果表明,MemSearcher 在多个公开数据集上优于强大的历史拼接式 ReAct 基线方法,同时在多轮交互中保持近似恒定的 token 数量,体现出更好的性能与上下文效率。
论文标题:On the Editability of Delta Parameters in Post-Trained Models
论文作者:Qiaoyu Tang, Le Yu, Bowen Yu, Hongyu Lin, Keming Lu, Yaojie Lu, Xianpei Han, Le Sun
合作单位:阿里巴巴
发表会议:ACL 2026
录用类型:Findings 长文
论文链接:https://arxiv.org/abs/2410.13841
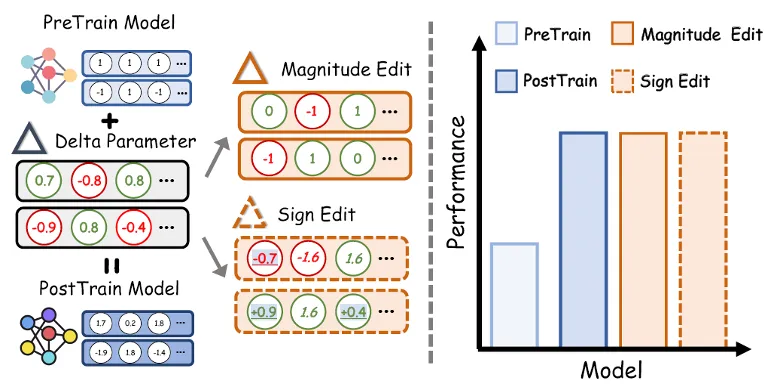
论文简介:后训练已成为将大规模预训练模型适配到各类任务的关键范式,其效果完全体现在 Delta 参数(即后训练参数与预训练参数之差)中。尽管已有大量研究通过剪枝、量化、低秩近似、外推等操作探索 Delta 参数的性质,一个根本问题仍未得到解答:Delta 参数的哪些性质对维持模型性能是必要的?本文从幅值与符号两个维度研究 Delta 参数的性质。通过在指令语言模型、推理语言模型和视觉模型上的实验,我们发现 Delta 参数展现出显著的可编辑性:单个参数值、分布形状、相对关系乃至符号都可被大幅修改,同时仍能保持后训练模型的性能。为理解这些现象,我们提出了一种基于损失的局部代理分析方法,通过二阶 Taylor 展开来刻画编辑操作的影响。该分析引入了编辑强度的概念,有助于解释不同编辑操作的稳定性边界。
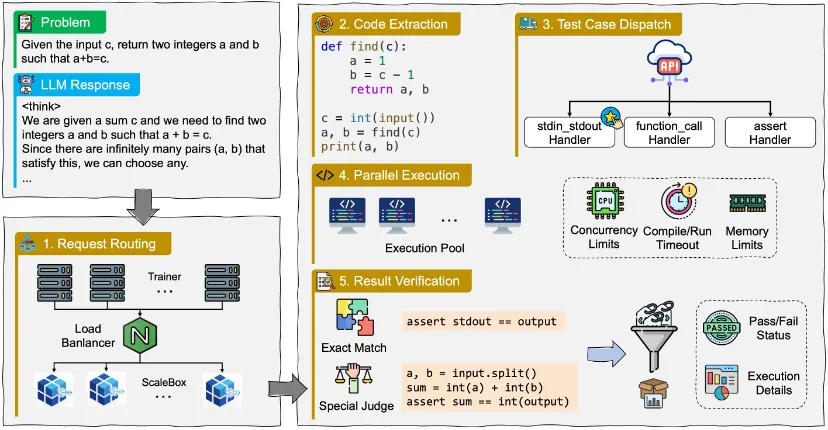
论文标题:ScaleBox: Enabling High-Fidelity and Scalable Code Verification for Large Language Models
论文作者:Jiasheng Zheng*, Xin Zheng*, Boxi Cao*, Pengbo Wang, Zhengzhao Ma, Qiming Zhu, Jiazhen Jiang, Yaojie Lu, Hongyu Lin, Xianpei Han, Le Sun
发表会议:ACL 2026
录用类型:系统演示论文
论文链接:https://arxiv.org/abs/2604.27467
论文简介:代码沙盒对于提升大语言模型(LLMs)的编程能力至关重要,尤其是在基于可验证奖励的强化学习(RLVR)中。然而,现有系统在高并发负载下无法同时提供高精度的验证能力和高效的执行性能。我们提出了ScaleBox,一个高保真且具备可扩展性的系统,旨在解决大规模代码训练中的这些限制。ScaleBox引入了自动化的特殊评测器生成与管理机制,在测试用例层面实现细粒度并行执行,并支持无缝的多节点协同,同时提供基于配置驱动的评测套件以实现可复现的基准测试。一系列实验结果表明ScaleBox显著提升了代码验证的准确性与效率。进一步的RLVR实验显示,ScaleBox在LiveCodeBench上的表现和训练稳定性方面均取得了显著提升,显著优于基于启发式匹配的方法基线。通过提供可靠且高吞吐量的基础设施,ScaleBox为大规模代码训练领域的研究与开发提供了更高效的支持。
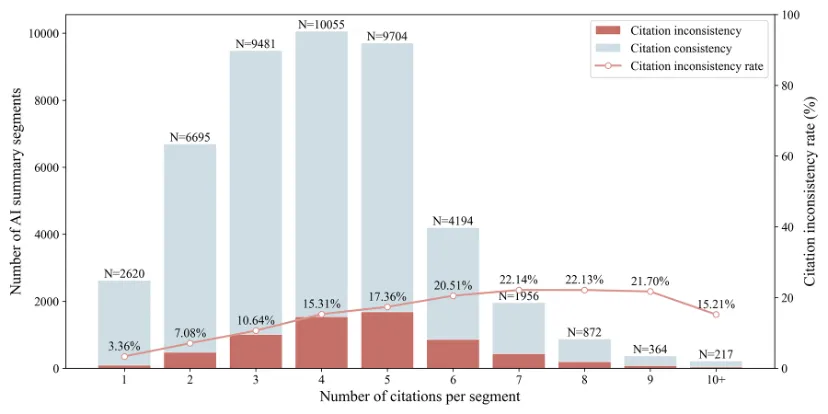
论文标题:Answer First, Evidence Second? Uncovering Hidden Risks in Well-Structured AI Search Summaries
论文作者:Jinman Li, Xuanang Chen, Ruoxi Xu, Hongyu Lin, Yaojie Lu, Zecheng Fan, Xianpei Han, Le Sun
发表会议:SIGIR 2026
录用类型:主会短文
论文简介:搜索引擎正逐步为用户提供基于搜索内容生成的AI摘要以满足用户的信息需求,这些AI生成的摘要往往被用户直接视为最终答案而不是作为深入探索的起点。AI生成的摘要通常结构严密且引用丰富,营造出可靠的表象,即便其证据支撑并不充分,也会诱导用户的信任。针对这种可靠表象与实际证据使用之间的断链,我们采用了MS MARCO 的 14,175 个真实用户查询,以Google搜索AI摘要及其引用来源为例,系统考察用户可感知的表面结构与不易观察到的证据层面的问题。研究发现,尽管AI摘要结构清晰、语言流畅、引用的数量多,但仍有32.31%的AI摘要给出了错误答案,其中 56.16% 的错误发生在引用来源实际上存在正确支撑证据的情况下。此外,31.08%的AI摘要表现出与其引用内容的不一致性,且这种风险会随着引用数量的增加以及引用位置的显著而进一步升高。我们的研究揭示了这种以直接给出答案为核心的搜索模式存在的潜在风险,并强调未来的评估与设计实践应超越表层的可靠信号,回到真正生成摘要的证据选择、整合和使用中。